

Modelos de peso aberto agora são fortes o suficiente para cargas de trabalho de produção reais—codificação agentiva, fluxos de trabalho de longo contexto e assistentes que usam ferramentas, sem que você fique preso a um único fornecedor. Dois modelos que aparecem muito em discussões sobre "rápido + capaz" são o GLM-4.7-Flash e o GPT-OSS-20B.
Este blog compara eles sob uma perspectiva prática—qualidade (benchmarks), velocidade/latência e custo—e mostra como executar ambos imediatamente na Novita AI via APIs.
Introdução Básica
Ambos são modelos MoE construídos para alta eficiência, mas com ênfases diferentes:
- GLM-4.7-Flash: Equilíbrio de capacidade e eficiência da classe "30B" (ótimo para fluxos de trabalho de longo contexto).
- GPT-OSS-20B: Modelo de peso aberto da OpenAI otimizado para menor latência / compatibilidade com GPU única e uso de ferramentas.
| GLM-4.7-Flash | GPT-OSS-20B | |
| Desenvolvedor | Z.ai | OpenAI |
| Data de lançamento | 20 de jan. de 2026 | 5 de ago. de 2025 |
| Parâmetros (ativos) | 30B-A3B (MoE) | 21B no total / 3,6B ativos (MoE) |
| Contexto na Novita | 200.000 | 131.072 |
| Preços na Novita | Entrada $0,07/M · Saída $0,40/M | Entrada $0,04/M · Saída $0,15/M |
Comparação de Benchmarks
A figura apresenta resultados em 6 benchmarks: SWE-bench Verified, τ²-Bench, BrowseComp, AIME 25, GPQA, HLE. Esses mesmos números estão listados na página do modelo GLM-4.7-Flash no Hugging Face, que usamos como fonte autoritativa.
| Benchmark | GLM-4.7-Flash | GPT-OSS-20B | Vencedor |
| SWE-bench Verified | 59,2 | 34 | GLM-4.7-Flash |
| τ²-Bench | 79,5 | 47,7 | GLM-4.7-Flash |
| BrowseComp | 42,8 | 28,3 | GLM-4.7-Flash |
| AIME 25 | 91,6 | 91,7 | GPT-OSS-20B (ligeiramente) |
| GPQA | 75,2 | 71,5 | GLM-4.7-Flash |
| HLE | 14,4 | 10,9 | GLM-4.7-Flash |
💡Interpretação
Os benchmarks favorecem majoritariamente o GLM-4.7-Flash—liderando em cinco avaliações—com o AIME 25 sendo essencialmente um empate (91,6 vs 91,7).
- Tarefas agentivas + com muitas ferramentas: O GLM-4.7-Flash lidera claramente no SWE-bench Verified e no τ²-Bench, que estão intimamente ligados a fluxos de trabalho de agentes do mundo real (codificação/terminal, interações de múltiplas etapas).
- Tarefas de navegação: O GLM-4.7-Flash também lidera no BrowseComp, sugerindo um comportamento de navegação/seleção de longo horizonte mais forte em configurações de avaliação.
- Matemática: O AIME 25 é essencialmente um empate (91,6 vs 91,7). Em outras palavras: não escolha apenas com base neste teste.
- QA com muito conhecimento: O GLM-4.7-Flash está à frente no GPQA e no HLE neste conjunto de relatórios.
Comparação de Velocidade e Latência
| Métrica | GPT-OSS-20B | GLM-4.7-Flash |
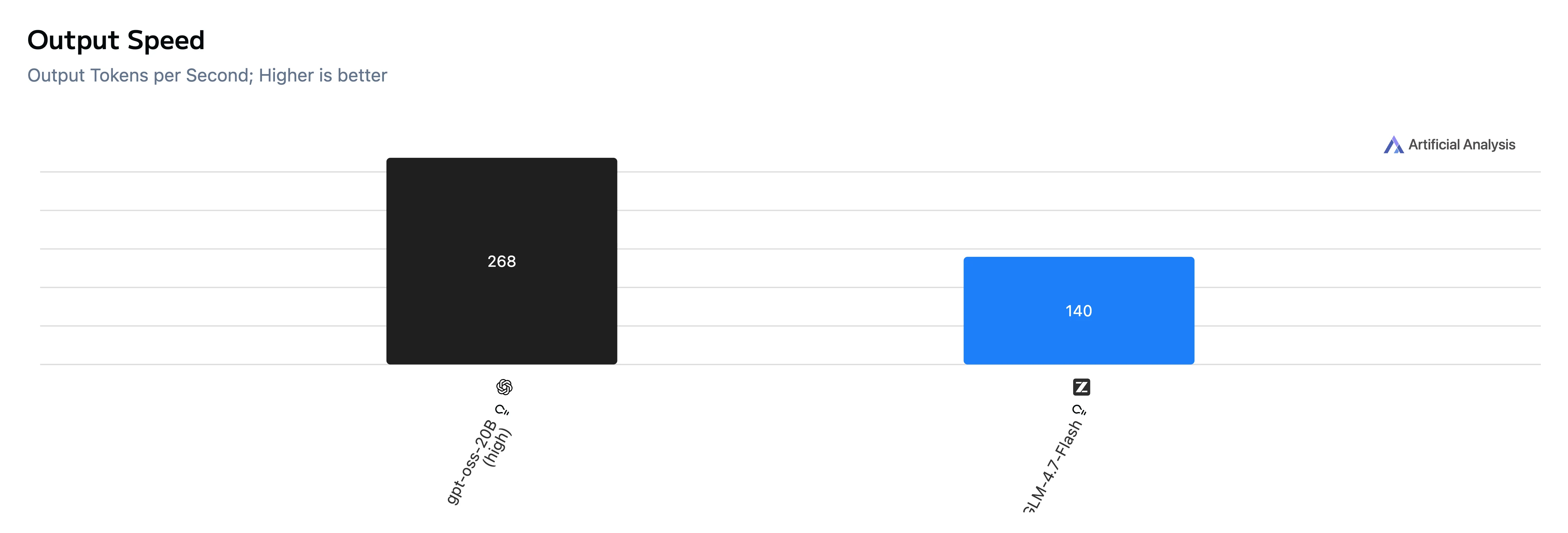
| Velocidade de saída | 268 tok/s | 140 tok/s |
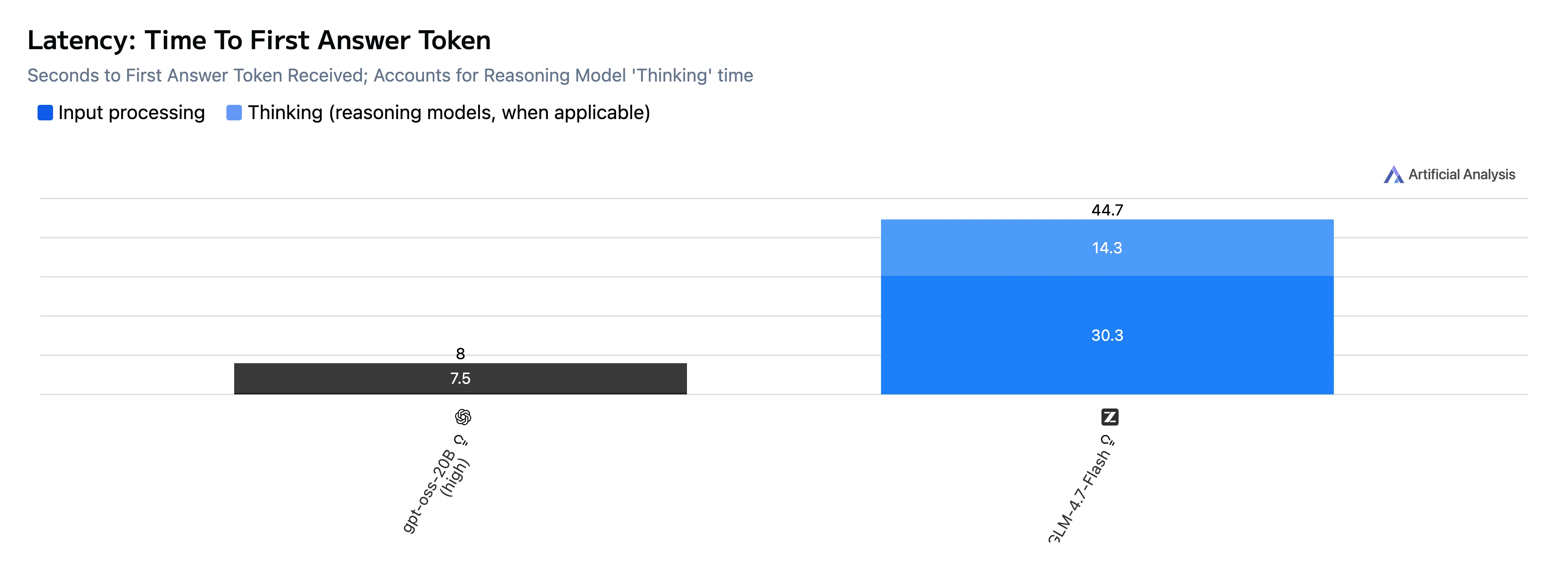
| TTFT (primeiro token de resposta) | 8,0 s | 46,5 s |
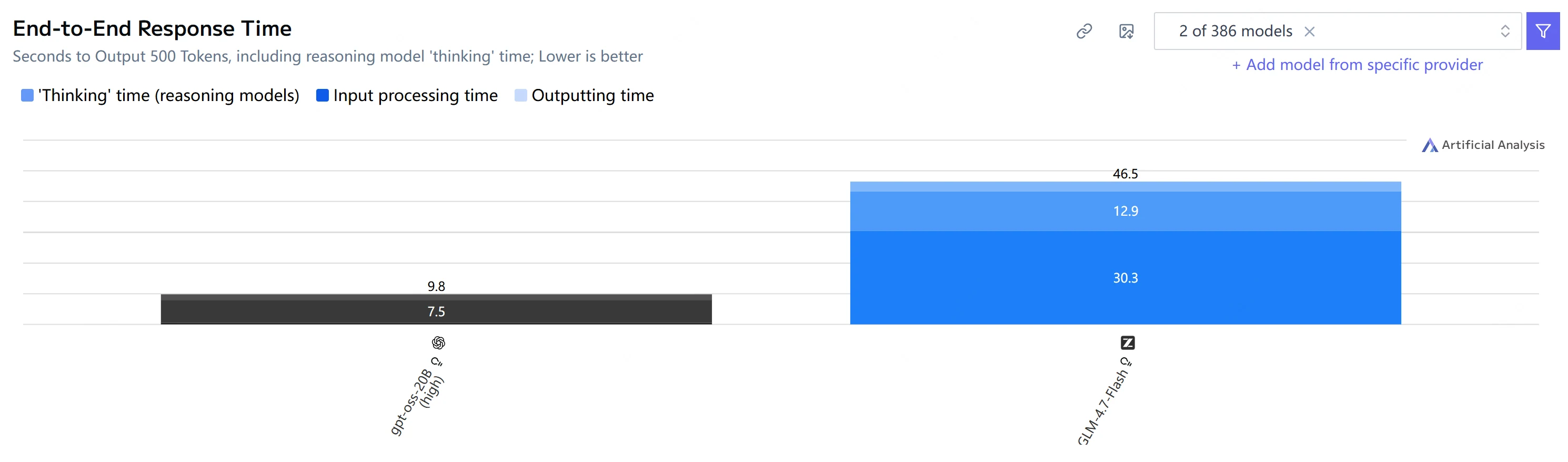
| Tempo de ponta a ponta (500 tokens de saída) |
9,8 s | 46,5 s |
Conclusão: O GPT-OSS-20B é muito mais rápido tanto na geração de tempo até o primeiro token quanto na de ponta a ponta, e também gera tokens mais rapidamente neste conjunto de testes.
Comparação de Custos
| Modelo | Entrada (USD / 1M tokens) | Saída (USD / 1M tokens) | Leitura de cache (USD / 1M tokens) |
| GLM-4.7-Flash (zai-org/glm-4.7-flash) | $0,07 | $0,40 | $0,01 |
| GPT-OSS-20B (openai/gpt-oss-20b) | $0,04 | $0,15 | - |
O GPT-OSS-20B é a escolha mais econômica por token, enquanto o GLM-4.7-Flash custa mais, mas pode valer a pena quando você precisa de desempenho mais forte e capacidade de longo contexto. Se quiser mais detalhes, acesse a Biblioteca de Modelos da Novita AI para ver os preços mais recentes e as especificações dos modelos.
Início Rápido: Experimente Ambos os Modelos Imediatamente no Playground
Se você quiser experimentar a diferença entre o GLM-4.7-Flash e o GPT-OSS-20B imediatamente, a maneira mais rápida é usar o Novita AI Playground—sem código, sem configuração.
No Playground, você pode:
- Alterne modelos instantaneamente entre GLM-4.7-Flash e GPT-OSS-20B
- Use o mesmo prompt para comparar a qualidade da saída, o estilo de raciocínio e a velocidade de resposta
Novita AI Playground
Como Implantar: API, SDK e Integrações de Terceiros
API
Obtenha uma chave de API
- Passo 1: Crie ou faça login na sua conta
Visite [**https://novita.ai**](https://novita.ai) e cadastre-se ou faça login na sua conta existente
- Passo 2: Acesse o Gerenciamento de Chaves
Depois de fazer login, encontre "Chaves de API"

- Passo 3: Crie uma nova chave
Clique no botão "Adicionar Nova Chave".

- Passo 4: Salve sua chave imediatamente
Copie e armazene a chave assim que ela for gerada; geralmente ela é exibida apenas uma vez e não pode ser recuperada posteriormente. Guarde a chave em um local seguro, como um gerenciador de senhas ou notas criptografadas
API compatível com OpenAI (Python)
from openai import OpenAI
client = OpenAI(
api_key="<YOUR_NOVITA_API_KEY>",
base_url="https://api.novita.ai/openai",
)
resp = client.chat.completions.create(
model="zai-org/glm-4.7-flash",
messages=[
{"role": "system", "content": "You are a precise engineering assistant. Output valid JSON when asked."},
{"role": "user", "content": "Summarize the key risks of rolling out feature flags across 20 services."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
SDK
Se você está construindo fluxos de trabalho agentivos (transferências, roteamento, chamadas de ferramentas/funções), pode executar modelos hospedados na Novita dentro do Agents SDK da OpenAI com alterações mínimas:
- Compatibilidade imediata: A Novita expõe uma API compatível com OpenAI, então seu fluxo de trabalho de Agents permanece o mesmo—apenas a URL base/modelo é alterada.
- Pronto para orquestração de agentes: Use roteamento + ferramentas para delegar tarefas mantendo a inferência na Novita.
- Configuração: aponte o SDK para
https://api.novita.ai/openai, definaNOVITA_API_KEY, selecionezai-org/glm-4.7-flash(ouopenai/gpt-oss-20b).
Plataformas de Terceiros
Você também pode usar modelos hospedados na Novita por meio de ecossistemas populares:
- Frameworks de agentes e construtores de apps: Siga os guias de integração passo a passo da Novita para conectar-se a ferramentas populais como Continue, AnythingLLM, LangChain e Langflow.
- Hugging Face Hub: A Novita está listada como um Provedor de Inferência no Hugging Face, então você pode executar modelos suportados por meio do fluxo de trabalho e ecossistema de provedores do Hugging Face.
- API compatível com OpenAI: Os endpoints de LLM da Novita são compatíveis com o padrão de API da OpenAI, facilitando a migração de aplicativos existentes no estilo OpenAI e a conexão com muitas ferramentas compatíveis com OpenAI ( Cline, Cursor , Trae e Qwen Code) .
- API compatível com Anthropic: A Novita também fornece acesso compatível com o SDK da Anthropic para que você possa integrar modelos suportados pela Novita em fluxos de trabalho de codificação agentiva no estilo Claude Code.
- OpenCode: A Novita AI agora está integrada diretamente ao OpenCode como um provedor suportado, então os usuários podem selecionar a Novita no OpenCode sem configuração manual.
Conclusão
- GLM-4.7-Flash é a escolha ideal quando você se importa mais com qualidade agentiva/de codificação e contexto muito longo (200K)—ele lidera em 5/6 benchmarks no gráfico fornecido (o AIME está essencialmente empatado).
- GPT-OSS-20B é a escolha ideal quando você se importa mais com velocidade e custo—é muito mais rápido nos gráficos de latência fornecidos e mais barato nos preços sem servidor da Novita.
Caminho mais rápido: experimente ambos no Novita AI Playground, depois migre para integrações de API / SDK / terceiros dependendo de como você está construindo.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
Perguntas Frequentes
O que é o GLM-4.7-Flash?
O GLM-4.7-Flash é um modelo de linguagem grande de classe 30B do tipo Mistura de Especialistas (MoE), desenvolvido pela Zhipu AI, projetado para oferecer raciocínio forte, desempenho de codificação e agentivo com alta eficiência e baixa latência.
Quanto custa o GLM-4.7-Flash?
Na Novita AI (sem servidor), o GLM-4.7-Flash é precificado em $0,07/M por tokens de entrada, $0,01/M por tokens de leitura em cache e $0,40/M por tokens de saída, tornando-o econômico para cargas de trabalho de grande contexto e alta vazão.
Qual é melhor, GLM-4.7-Flash ou GPT-OSS-20B?
Depende do caso de uso: o GLM-4.7-Flash geralmente tem melhor desempenho em benchmarks agentivos, com muitas ferramentas e do mundo real, enquanto o GPT-OSS-20B pode ser preferido para implantações leves, de baixa latência ou com GPU única.



