

When building reliable AI-driven applications, developers often face a trade-off between deep reasoning capability and practical usability. This article addresses that challenge by comparing DeepSeek V3.1vs Kimi K2 and showing how they complement each other. In practice, a hybrid workflow can be highly effective
Deepseek V3.1 VS Kimi K2: Technical Specifications
| Feature | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Total Parameters | 671B | 1 Trillion |
| Activated per Token | ~37B | ~32B |
| Experts | 257 (8 active/token) | 384 (8 active/token) |
| Context Window | 128K tokens | 128K tokens |
| Architecture | MoE (MLA), Efficient load balancing | MoE + MuonClip optimizer, agentic reinforcement |
| Special Modes | Hybrid inference (Think / Non-Think) | Agentic tasks-focused (Instruct variant) |
Both DeepSeek V3.1 and Kimi K2 introduced their own chat templates to make the models easier to control and integrate in real-world applications:
DeepSeek V3.1 uses special tokens (
<think>/</think>) so developers can explicitly switch between fast direct responses and deeper reasoning,which suits scenarios needing fine-grained control over cost and performance, while Kimi K2 adopts a standard OpenAI-style
messagesformat, offering simple, plug-and-play integration for products and agents.
DeepSeek V3.1 (Non-Thinking vs Thinking)
Non-Thinking Prefix
<|begin▁of▁sentence|>You are DeepSeek V3.1.
<|User|>What is RLHF?
<|Assistant|></think>Thinking Prefix
<|begin▁of▁sentence|>You are DeepSeek V3.1.
<|User|>What is RLHF?
<|Assistant|><think>Kimi K2 (Standard Chat API)
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant."},
{"role": "user", "content": "What is RLHF?"}
]| Dimension | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Prompt Style | Custom format with special tokens <think> / </think> | Standard OpenAI Chat API format |
| Mode Control | Explicit separation of Thinking vs Non-Thinking | No explicit modes; model decides implicitly |
| Multi-turn | Requires manual context stitching with tokens | Simply append messages in array |
| Flexibility | High: developers can force or disable reasoning | Medium: relies on system prompt & parameters |
| Ease of Use | More complex, strict template required | Simple, plug-and-play |
Deepseek V3.1 VS Kimi K2: Benchmark
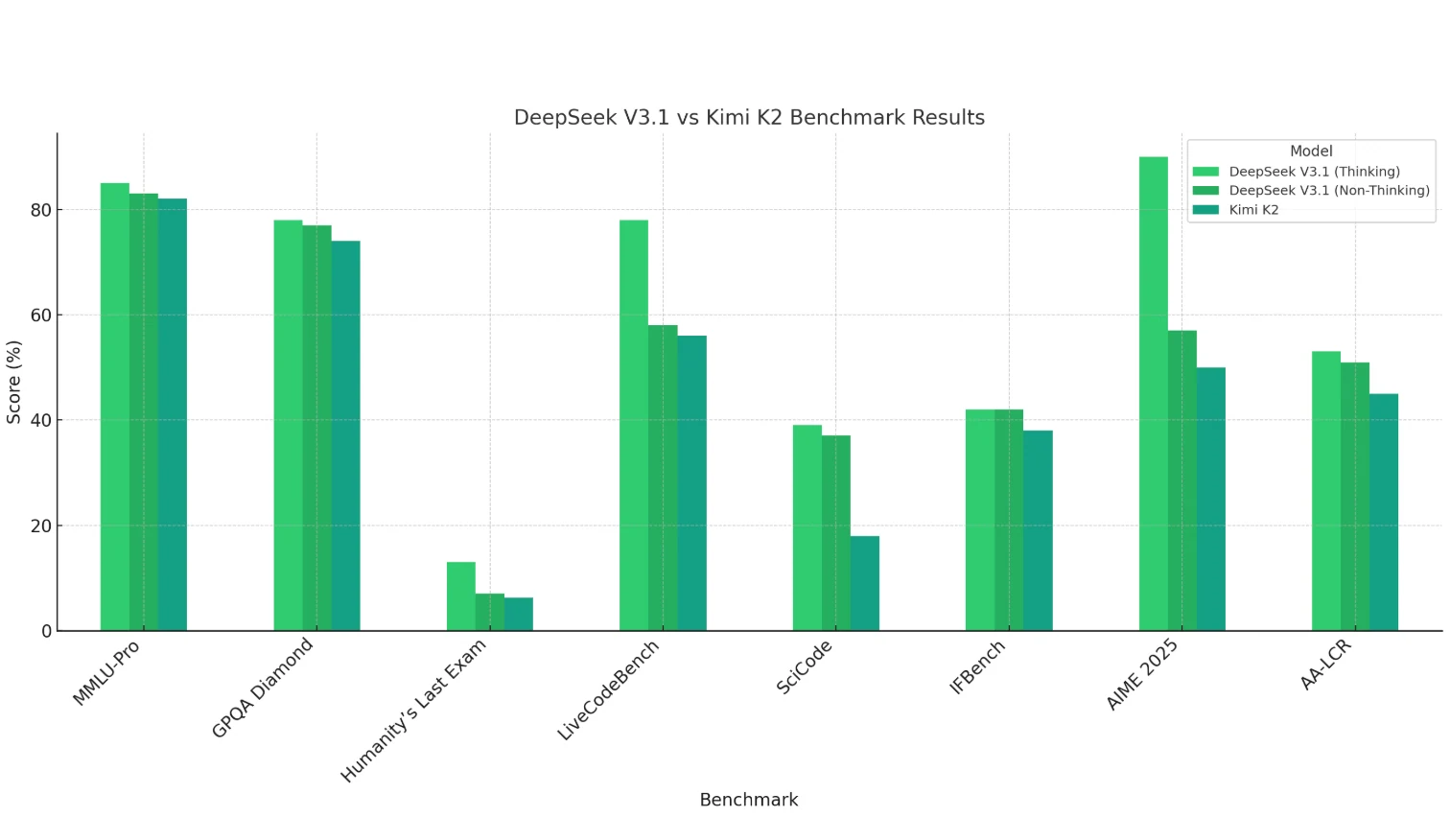
DeepSeek V3.1 (Thinking mode) shows clear advantages in mathematics (AIME 2025), coding (LiveCodeBench, SciCode), and long-context reasoning (AA-LCR), demonstrating strong reasoning and computational capabilities.
Kimi K2 performs somewhat weaker overall—especially in coding and math—but remains competitive in knowledge-based tasks (MMLU, GPQA).
The Non-Thinking mode of DeepSeek V3.1 usually scores slightly lower than the Thinking mode, but still matches or surpasses Kimi K2 in most cases.
Conclusion: DeepSeek V3.1 is better suited for reasoning-intensive and complex tasks, while Kimi K2 leans more toward general knowledge scenarios.
Deepseek V3.1 VS Kimi K2: Speed
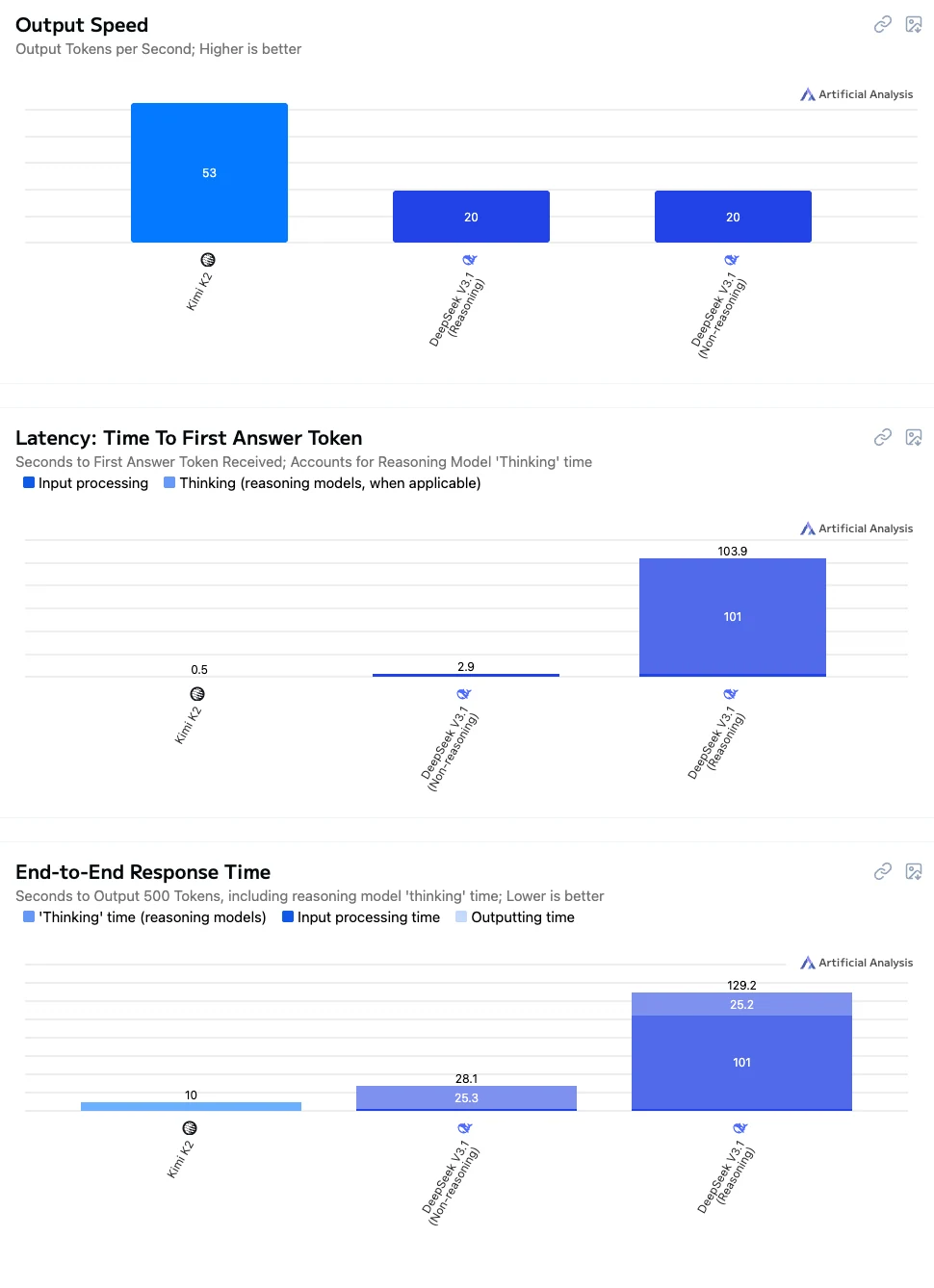
From Artificial analysis
- Kimi K2: Fast speed, low latency, and smooth overall interaction, making it well-suited for real-time conversations, application integration, and educational scenarios.
- DeepSeek V3.1 Non-Thinking: Medium response speed, suitable for tasks that require reasonable accuracy without long waiting times.
- DeepSeek V3.1 Thinking: The slowest in performance but offers the strongest reasoning and complex problem-solving capabilities, making it ideal for high-precision reasoning, complex computations, and research-oriented applications.
Which is Better for Code Related Tasks—DeepSeek V3.1 or Kimi K2?
Task: Implement a safe arithmetic expression evaluator.
Spec
- Function:
evaluate(expr: str) -> int - Supports: integers,
+ - * /, parentheses, spaces, unary+/-(e.g.,-3*(+2)). - Division is integer truncation toward zero (match Python’s
int(a/b)behavior, not floor). - Must detect invalid input and raise
ValueError. - No
eval,ast.literal_eval, or third-party parsers.
Edge cases to handle
- Multiple unary signs:
--5,+-3 - Spaces:
" 1 + ( 2*3 ) " - Precedence & associativity:
2-3-4 == -5,14/3 == 4,-14/3 == -4 - Invalid:
"(1+2","2**3","3//2","2(3)",")1("
Use Deepseek V3.1 in the free playground
Use Kimi K2 in the free playground
Start a Free trail to Test Now!
| Evaluation Dimension | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Correctness | Implements a hand-written tokenizer and recursive-descent parser. Handles multiple unary operators (--5, +-3), precedence and associativity, and division truncation toward zero (manual fix). Potential issues: division handling is overcomplicated; error messages minimal. No built-in test harness. | Uses a regex-based lexer, with explicit token classes (PLUS, MINUS, etc.). Correct truncation via int(a/b). Provides a full test suite in __main__ covering valid and invalid cases. Error handling more elegant (ValueError with message). |
| Code Quality | Low-level manual char scanning. Feels like an “exam-solution” parser: thorough but verbose and harder to maintain. No test harness included. | Cleaner modularization (Lexer, Parser, evaluate). Easier to read due to regex simplification. Provides tests, enabling faster verification. |
| Style & Usability | Strong at raw reasoning, builds everything from scratch. Suitable when fine-grained parsing control is needed. | Optimized for developer experience: concise, tested, production-ready. More practical for immediate integration. |
| Verdict | Strong in reasoning about edge cases and algorithm design. Demonstrates strength in building parsers from scratch, but weaker in polish and ergonomics. | Cleaner, concise, and production-friendly implementation. Slightly less rigorous parsing, but highly usable. |
| Conclusion | Choose DeepSeek V3.1 for robust correctness and algorithmic depth. | Choose Kimi K2 for developer-ready, readable, and tested code. |
1. Building the Overall Framework → DeepSeek V3.1
- Strengths: strong reasoning, rigorous logic—great for laying down the skeleton of complex systems.
- Best for:
- Designing interpreters/compilers, parsers, or DSLs
- Implementing core algorithms and data structures
- Outlining the full execution flow (classes, methods, call hierarchy)
- Outcome: a complete but somewhat verbose draft with the main logic fully in place.
2. Refining Details & Polishing Code → Kimi K2
- Strengths: concise, modular, and developer-friendly—great for cleanup and production-readiness.
- Best for:
- Rewriting verbose logic into more elegant constructs (e.g., regex instead of manual scanning)
- Adding tests, error handling, logging
- Improving naming, modularization, and overall readability
- Outcome: a clean, maintainable, production-ready implementation.
Deepseek V3.1 VS Kimi K2: System Requirements
| Model & Configuration | VRAM Requirement | GPU Needs |
|---|---|---|
| DeepSeek V3.1 (671B) | 1.5 TB VRAM | 8xhH200 can support it |
| Kimi K2 (Quantized) | 250 GB combined | 1x 24GB GPU |
| Kimi K2 (FP8) | 1 TB | single 8xH200 or 6xB200 pod |
How to Access Deepseek V3.1 and Kimi K2 Through Cheap and Stable API?
Novita AI has officially rolled out DeepSeek V3.1 and Kimi K2 APIs, giving developers more flexibility for high-performance AI coding and reasoning tasks. Both models are integrated with Claude Code support, making them directly useful for advanced coding workflows.
DeepSeek V3.1 Metrics
- Input Price: $0.55 per million tokens
- Output Price: $1.66 per million tokens
- Latency: 3.00s
- Throughput: 48.28 TPS
Kimi K2 Metrics
- Input Price: $0.57 per million tokens
- Output Price: $2.30 per million tokens
- Latency: 1.30s
- Throughput: 122.1 TPS
Step 1: Log In and Access the Model Library
Log in to your account and click on the Model Library button.

Try Deepseek V3.1 and Kimi K2 Now!
Step 2: Choose Your Model
Browse through the available options and select the model that suits your needs.
Step 3: Start Your Free Trial
Begin your free trial to explore the capabilities of the selected model.
Step 4: Get Your API Key
To authenticate with the API, we will provide you with a new API key. Entering the “Settings“ page, you can copy the API key as indicated in the image.

Step 5: Install the API
Install API using the package manager specific to your programming language.
After installation, import the necessary libraries into your development environment. Initialize the API with your API key to start interacting with Novita AI LLM. This is an example of using chat completions API for python users.
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<Your API Key>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # or False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Overall, DeepSeek V3.1 excels at reasoning-intensive, math-heavy, and code-related tasks, making it a strong choice when accuracy and logical depth are paramount. Its Thinking mode pushes the limits of complex problem-solving, while Non-Thinking offers a balance of speed and quality. Kimi K2 shines in general knowledge tasks, real-time applications, and seamless integration, thanks to its faster response speed, higher throughput, and plug-and-play API. For developers, a hybrid workflow can be effective: use DeepSeek V3.1 to design and reason through complex frameworks, then rely on Kimi K2 to refine, test, and productionize the implementation.
Frequently Asked Questions
Which model is better for coding tasks?
DeepSeek V3.1 (Thinking mode) is stronger in algorithmic reasoning and edge-case handling, making it ideal for building frameworks and complex parsers. Kimi K2 produces cleaner, more modular code with built-in tests, making it developer-friendly for refinement and integration.
How do the two models differ in performance speed?
Kimi K2 is significantly faster, with lower latency and higher throughput, making it suitable for real-time conversations and educational scenarios. DeepSeek V3.1 is slower, especially in Thinking mode, but delivers stronger reasoning and accuracy for research or computation-heavy use cases.
Which should I choose for general use?
If your priority is robust reasoning and coding accuracy, choose DeepSeek V3.1. If you need speed, smooth integration, and high throughput, choose Kimi K2. Many teams benefit from combining both: DeepSeek for framework design, Kimi for refinement and deployment.
Novita AI is the All-in-one cloud platform that empowers your AI ambitions. Integrated APIs, serverless, GPU Instance — the cost-effective tools you need. Eliminate infrastructure, start free, and make your AI vision a reality.
Recommend Reading
Qwen 3 in RAG Pipelines: All-in-One LLM, Embedding, and Reranking Models
How to access GLM 4.5V for Image Understanding and Visual QA



