

信頼性の高いAI駆動アプリケーションを構築する際、開発者はしばしば深い推論能力と実用的なユーザビリティのトレードオフに直面します。この記事では、DeepSeek V3.1とKimi K2を比較し、それらがどのように相互補完できるかを示すことで、この課題に取り組みます。実際、ハイブリッドワークフローは非常に効果的です。
Deepseek V3.1 VS Kimi K2:技術仕様
| 機能 | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| 総パラメータ数 | 671B | 1兆 |
| トークンあたりの活性化パラメータ数 | 約37B | 約32B |
| エキスパート数 | 257 (トークンあたり8アクティブ) | 384 (トークンあたり8アクティブ) |
| コンテキストウィンドウ | 128Kトークン | 128Kトークン |
| アーキテクチャ | MoE (MLA)、効率的な負荷分散 | MoE + MuonClipオプティマイザー、エージェント強化学習 |
| 特殊モード | ハイブリッド推論 (思考 / 非思考) | エージェントタスク重視 (Instructバリアント) |
DeepSeek V3.1 と Kimi K2 はどちらも独自のチャットテンプレートを導入し、モデルの制御と実世界のアプリケーションへの統合を容易にしています。
DeepSeek V3.1 は特殊トークン(
thinking/response)を使用するため、開発者は高速な直接応答と深い推論を明示的に切り替えることができ、コストとパフォーマンスを細かく制御する必要があるシナリオに適しています。一方、Kimi K2 は標準的なOpenAIスタイルのmessages形式を採用し、製品やエージェントへのプラグアンドプレイ統合を提供します。
DeepSeek V3.1(非思考 vs 思考)
非思考プレフィックス
You are DeepSeek V3.1.
user:RLHFとは何ですか?
assistant response
思考プレフィックス
You are DeepSeek V3.1.
user:RLHFとは何ですか?
assistant thinking
Kimi K2(標準チャットAPI)
messages = [
{"role": "system", "content": "あなたはKimiです。AIアシスタントです。"},
{"role": "user", "content": "RLHFとは何ですか?"}
]
| 次元 | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| プロンプトスタイル | 特殊トークン thinking / response を使用したカスタム形式 |
標準的なOpenAIチャットAPI形式 |
| モード制御 | 思考 と 非思考 の明示的な分離 | 明示的なモードなし。モデルが暗黙的に決定 |
| マルチターン | トークンを使用した手動コンテキストステッチングが必要 | 配列にメッセージを追加するだけ |
| 柔軟性 | 高:開発者が推論を強制または無効化可能 | 中:システムプロンプトとパラメータに依存 |
| 使いやすさ | より複雑、厳格なテンプレートが必要 | シンプル、プラグアンドプレイ |
Deepseek V3.1 VS Kimi K2:ベンチマーク
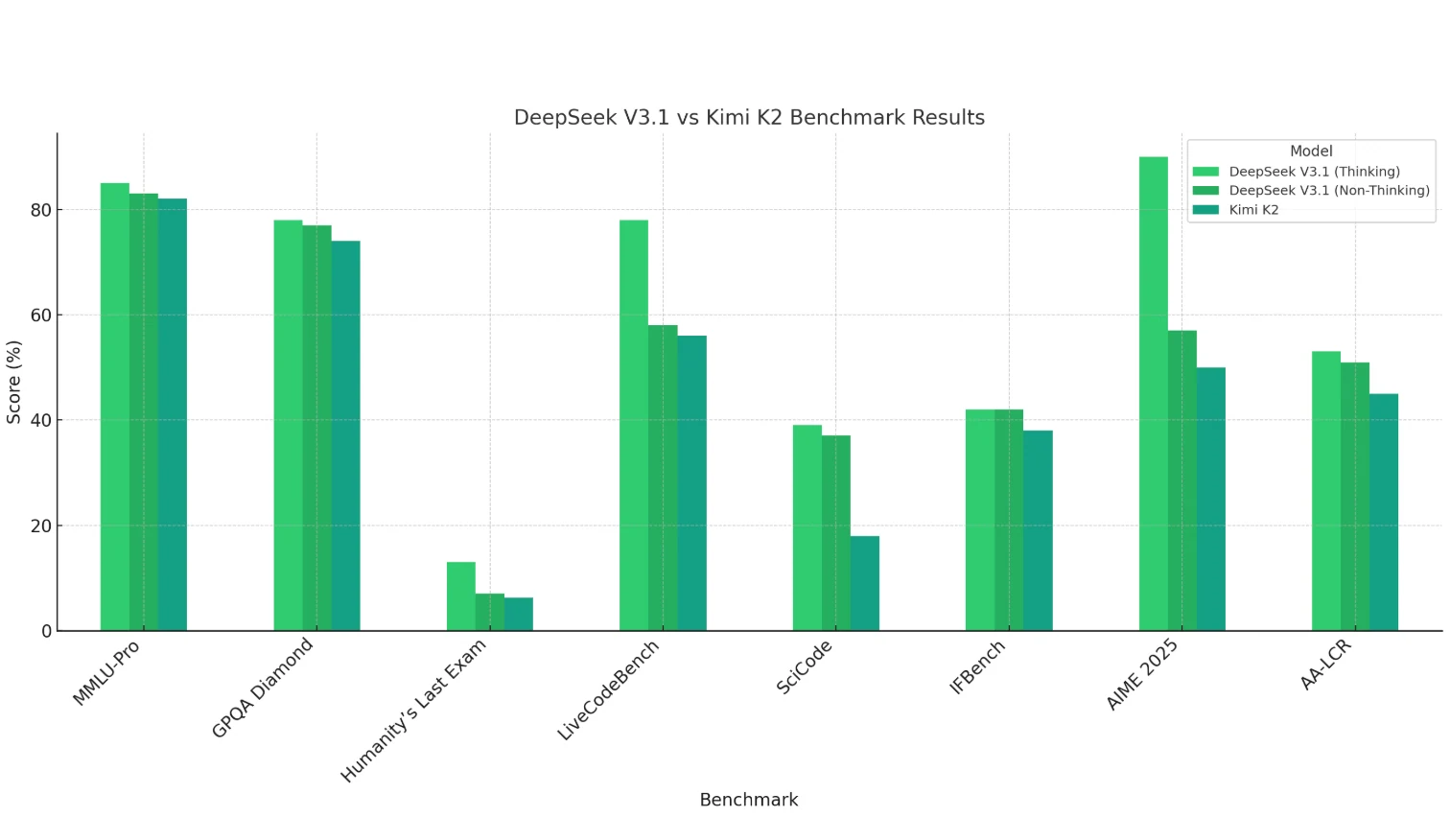
DeepSeek V3.1(思考モード) は、数学(AIME 2025)、コーディング(LiveCodeBench、SciCode)、長文脈推論(AA-LCR)において明らかな優位性を示し、強力な推論および計算能力を発揮します。
Kimi K2 は全体的にやや弱いパフォーマンスを示します。特にコーディングと数学で顕著ですが、知識ベースのタスク(MMLU、GPQA)では競争力を維持しています。
**DeepSeek V3.1の非思考モード ** は通常、思考モードよりわずかに低いスコアですが、ほとんどの場合で Kimi K2 に匹敵するか、それを上回ります。
結論:DeepSeek V3.1は推論集約型で複雑なタスクに適しており、Kimi K2は一般的な知識シナリオにより適しています。
Deepseek V3.1 VS Kimi K2:速度
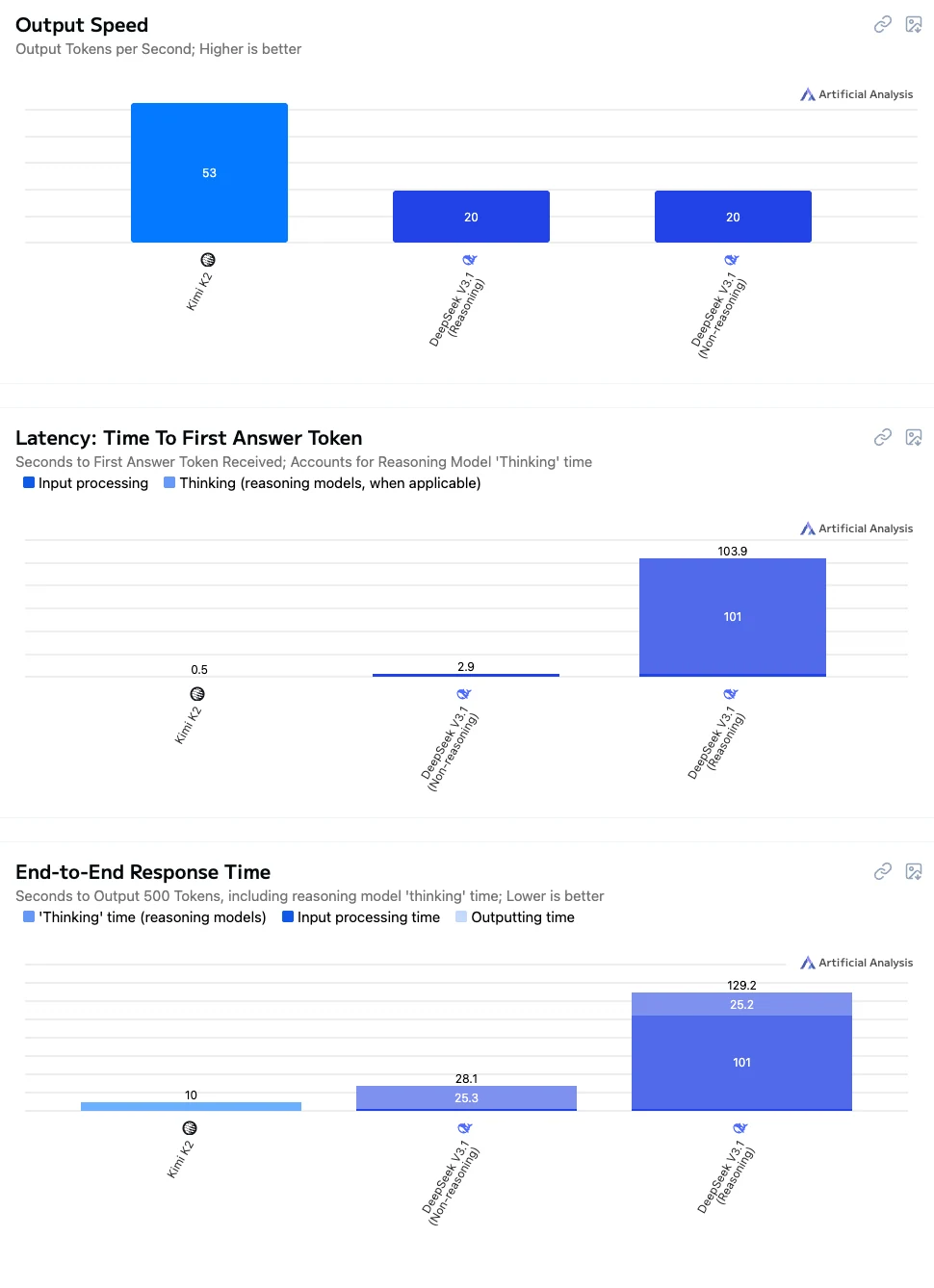
- Kimi K2:高速、低レイテンシ、全体的にスムーズな対話。リアルタイム会話、アプリケーション統合、教育シナリオに適しています。
- DeepSeek V3.1 非思考:中程度の応答速度。長時間待たずに妥当な精度を必要とするタスクに適しています。
- DeepSeek V3.1 思考:パフォーマンスは最も遅いですが、最も強力な推論と複雑な問題解決能力を提供し、高精度な推論、複雑な計算、研究指向のアプリケーションに最適です。
コード関連タスクに適しているのはどちらか? DeepSeek V3.1 か Kimi K2 か?
タスク: 安全な算術式評価器の実装。
仕様
- 関数:
evaluate(expr: str) -> int - サポート:整数、
+ - * /、括弧、スペース、単項+/-(例:-3*(+2))。 - 除算は ゼロ方向への整数切り捨て(Pythonの
int(a/b)の動作に一致、床関数ではない)。 - 無効な入力を検出し、
ValueErrorを発生させる必要がある。 eval、ast.literal_eval、サードパーティのパーサーは使用不可。
処理すべきエッジケース
- 複数の単項記号:
--5、+-3 - スペース:
" 1 + ( 2*3 ) " - 優先順位と結合性:
2-3-4 == -5、14/3 == 4、-14/3 == -4 - 無効なケース:
"(1+2"、"2**3"、"3//2"、"2(3)"、")1("
無料プレイグラウンドでDeepseek V3.1を使用
無料プレイグラウンドでKimi K2を使用
| 評価軸 | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| 正確性 | 手書きのトークナイザーと再帰下降パーサーを実装。複数の単項演算子(--5、+-3)、優先順位と結合性、ゼロ方向への切り捨て除算(手動修正)を処理。潜在的な問題:除算処理が複雑すぎる、エラーメッセージが最小限。組み込みテストハーネスなし。 |
正規表現ベースのレキサーと明示的なトークンクラス(PLUS、MINUSなど)を使用。int(a/b)による正しい切り捨て。__main__に有効ケースと無効ケースをカバーする完全なテストスイートを提供。エラー処理がよりエレガント(メッセージ付きのValueError)。 |
| コード品質 | 低レベルな手動文字スキャン。「試験解答」パーサーのような印象:徹底しているが冗長で保守が難しい。テストハーネスは含まれていません。 | よりクリーンなモジュール化(Lexer、Parser、evaluate)。正規表現による簡略化により読みやすい。テストを提供し、迅速な検証が可能。 |
| スタイルとユーザビリティ | 生の推論に強く、すべてをゼロから構築。細かい解析制御が必要な場合に適しています。 | 開発者体験に最適化:簡潔、テスト済み、プロダクション準備完了。即時統合により実用的。 |
| 評価 | エッジケースとアルゴリズム設計に関する推論に優れている。ゼロからパーサーを構築する強みを示すが、洗練性と人間工学では劣る。 | よりクリーンで簡潔、プロダクション向けの実装。解析はやや厳密さに欠けるが、非常に使いやすい。 |
| 結論 | 堅牢な正確性とアルゴリズムの深さが必要な場合はDeepSeek V3.1を選択。 | 開発者にとって読みやすくテスト済みのコードが必要な場合はKimi K2を選択。 |
1. 全体的なフレームワークの構築 → DeepSeek V3.1
- 強み: 強力な推論、厳密な論理。複雑なシステムの骨格を構築するのに最適。
- 最適な用途:
- インタプリタ/コンパイラ、パーサー、DSLの設計
- コアアルゴリズムとデータ構造の実装
- 完全な実行フロー(クラス、メソッド、呼び出し階層)の概要
- **結果 : ** 完全であるがやや冗長なドラフト。主要なロジックは完全に配置されている。
2. 詳細の洗練とコードの研磨 → Kimi K2
- 強み: 簡潔、モジュール化、開発者にとって使いやすい。クリーンアップとプロダクション準備に最適。
- 最適な用途:
- 冗長なロジックのよりエレガントな構造への書き換え(例:手動スキャンの代わりに正規表現)
- テスト、エラー処理、ロギングの追加
- 命名、モジュール化、全体的な可読性の向上
- **結果 : ** クリーンで保守可能、プロダクション準備完了の実装。
Deepseek V3.1 VS Kimi K2:システム要件
| モデルと構成 | VRAM要件 | 必要なGPU |
|---|---|---|
| DeepSeek V3.1 (671B) | 1.5 TB VRAM | 8xhH200で対応可能 |
| Kimi K2 (量子化) | 250 GB 合計 | 1x 24GB GPU |
| Kimi K2 (FP8) | 1 TB | シングル8xH200または6xB200ポッド |
低価格で安定したAPIを通じてDeepseek V3.1とKimi K2にアクセスするには?
Novita AIは、DeepSeek V3.1 および Kimi K2 のAPIを正式にリリースし、開発者が高性能なAIコーディングおよび推論タスクに対してより柔軟に対応できるようにしました。両モデルは Claude Codeサポート と統合されており、高度なコーディングワークフローに直接活用できます。
DeepSeek V3.1 メトリクス
- 入力価格: 1トークンあたり$0.55
- 出力価格: 1トークンあたり$1.66
- レイテンシ: 3.00秒
- スループット: 48.28 TPS
Kimi K2 メトリクス
- 入力価格: 1トークンあたり$0.57
- 出力価格: 1トークンあたり$2.30
- レイテンシ: 1.30秒
- スループット: 122.1 TPS
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリ ボタンをクリックします。

Deepseek V3.1 と Kimi K2 を今すぐ試す!
ステップ2:モデルを選択
利用可能なオプションを参照し、ニーズに合ったモデルを選択します。
ステップ3:無料トライアルを開始
選択したモデルの機能を探索するために無料トライアルを開始します。
ステップ4:APIキーを取得
APIで認証するために、新しいAPIキーを提供します。「設定」ページに移動し、画像に示されているようにAPIキーをコピーします。

ステップ5:APIをインストール
プログラミング言語に固有のパッケージマネージャーを使用してAPIをインストールします。
インストール後、必要なライブラリを開発環境にインポートします。APIキーを使用してAPIを初期化し、Novita AI LLMとの対話を開始します。これは、Pythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<Your API Key>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # or False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "こんにちは!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
全体として、DeepSeek V3.1 は 推論集約型、数学重視、コード関連タスク ** に優れており、正確性と論理的深度が最も重要な場合に強力な選択肢となります。その思考モードは複雑な問題解決の限界を押し広げ、非思考モードは速度と品質のバランスを提供します。Kimi K2 は、より高速な応答速度、高いスループット、プラグアンドプレイAPIにより、 一般的な知識タスク、リアルタイムアプリケーション、シームレスな統合** で輝きを放ちます。開発者にとっては、ハイブリッドワークフローが効果的です:DeepSeek V3.1 を使用して複雑なフレームワークを設計および推論し、その後 Kimi K2 に頼って実装を洗練、テスト、プロダクション化します。
よくある質問
コーディングタスクにはどちらのモデルが適していますか?
DeepSeek V3.1(思考モード)はアルゴリズム推論とエッジケース処理に優れており、フレームワークや複雑なパーサーの構築に最適です。Kimi K2は、組み込みテストを備えたよりクリーンでモジュール化されたコードを生成するため、洗練と統合用の開発者向けです。
2つのモデルはパフォーマンス速度においてどのように異なりますか?
Kimi K2は大幅に高速で、レイテンシが低くスループットが高いため、リアルタイム会話や教育シナリオに適しています。DeepSeek V3.1は、特に思考モードでは低速ですが、研究や計算負荷の高いユースケースに対して強力な推論と正確性を提供します。
一般的な使用にはどちらを選ぶべきですか?
堅牢な推論とコーディングの正確性 ** が優先事項の場合は、DeepSeek V3.1を選択してください。 速度、スムーズな統合、高いスループット** が必要な場合は、Kimi K2を選択してください。多くのチームは両方を組み合わせることでメリットを得ています:DeepSeekはフレームワーク設計に、Kimiは洗練とデプロイメントに使用します。
Novita AI は、AIの野心を実現するオールインワンのクラウドプラットフォームです。統合API、サーバーレス、GPUインスタンス — 必要なコスト効率の高いツール。今すぐ無料で始めて、AIのビジョンを現実にしましょう。
おすすめの記事
Qwen 3 in RAG Pipelines: All-in-One LLM, Embedding, and Reranking Models
How to access GLM 4.5V for Image Understanding and Visual QA



