

- DeepSeek V3.1 vs Kimi K2 : Spécifications techniques
- DeepSeek V3.1 vs Kimi K2 : Benchmark
- DeepSeek V3.1 vs Kimi K2 : Vitesse
- Quel est le meilleur pour les tâches liées au code—DeepSeek V3.1 ou Kimi K2 ?
- DeepSeek V3.1 vs Kimi K2 : Configuration système requise
- Comment accéder aux API DeepSeek V3.1 et Kimi K2 via une API économique et stable ?
Lors de la création d’applications IA fiables, les développeurs sont souvent confrontés à un compromis entre une capacité de raisonnement approfondie et une utilisabilité pratique. Cet article aborde ce défi en comparant DeepSeek V3.1 et Kimi K2 et en montrant comment ils se complètent. En pratique, un workflow hybride peut être très efficace.
DeepSeek V3.1 vs Kimi K2 : Spécifications techniques
| Caractéristique | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Paramètres totaux | 671B | 1 Billion |
| Activés par token | ~37B | ~32B |
| Experts | 257 (8 actifs/token) | 384 (8 actifs/token) |
| Fenêtre de contexte | 128K tokens | 128K tokens |
| Architecture | MoE (MLA), équilibrage de charge efficace | MoE + optimiseur MuonClip, renforcement agentique |
| Modes spéciaux | Inférence hybride (Penser / Ne pas penser) | Axé sur les tâches agentiques (variante Instruct) |
DeepSeek V3.1 et Kimi K2 ont tous deux introduit leurs propres templates de discussion pour faciliter le contrôle et l’intégration des modèles dans des applications réelles :
DeepSeek V3.1 utilise des tokens spéciaux (
thinking/response) permettant aux développeurs de basculer explicitement entre des réponses directes rapides et un raisonnement plus poussé,ce qui convient aux scénarios nécessitant un contrôle précis du coût et des performances, tandis que Kimi K2 adopte un format standard de type OpenAI (
messages), offrant une intégration simple et prête à l’emploi pour les produits et les agents.
DeepSeek V3.1 (Mode Non-Pensée vs Pensée)
Préfixe Non-Pensée
You are DeepSeek V3.1.
Utilisateur: Qu’est-ce que le RLHF ? Assistant: réponse
**Préfixe Pensée**
You are DeepSeek V3.1.
Utilisateur: Qu'est-ce que le RLHF ?
Assistant: pensée
Kimi K2 (API de discussion standard)
messages = [
{"role": "system", "content": "Tu es Kimi, un assistant IA."},
{"role": "user", "content": "Qu'est-ce que le RLHF ?"}
]
| Dimension | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Style d’invite | Format personnalisé avec tokens spéciaux thinking / response |
Format standard de l’API de discussion OpenAI |
| Contrôle du mode | Séparation explicite des modes Pensée et Non-Pensée | Pas de modes explicites ; le modèle décide implicitement |
| Tours multiples | Nécessite un assemblage manuel du contexte avec des tokens | Ajout simple de messages dans un tableau |
| Flexibilité | Élevée : les développeurs peuvent forcer ou désactiver le raisonnement | Moyenne : repose sur l’invite système et les paramètres |
| Facilité d’utilisation | Plus complexe, template strict requis | Simple, prêt à l’emploi |
DeepSeek V3.1 vs Kimi K2 : Benchmark
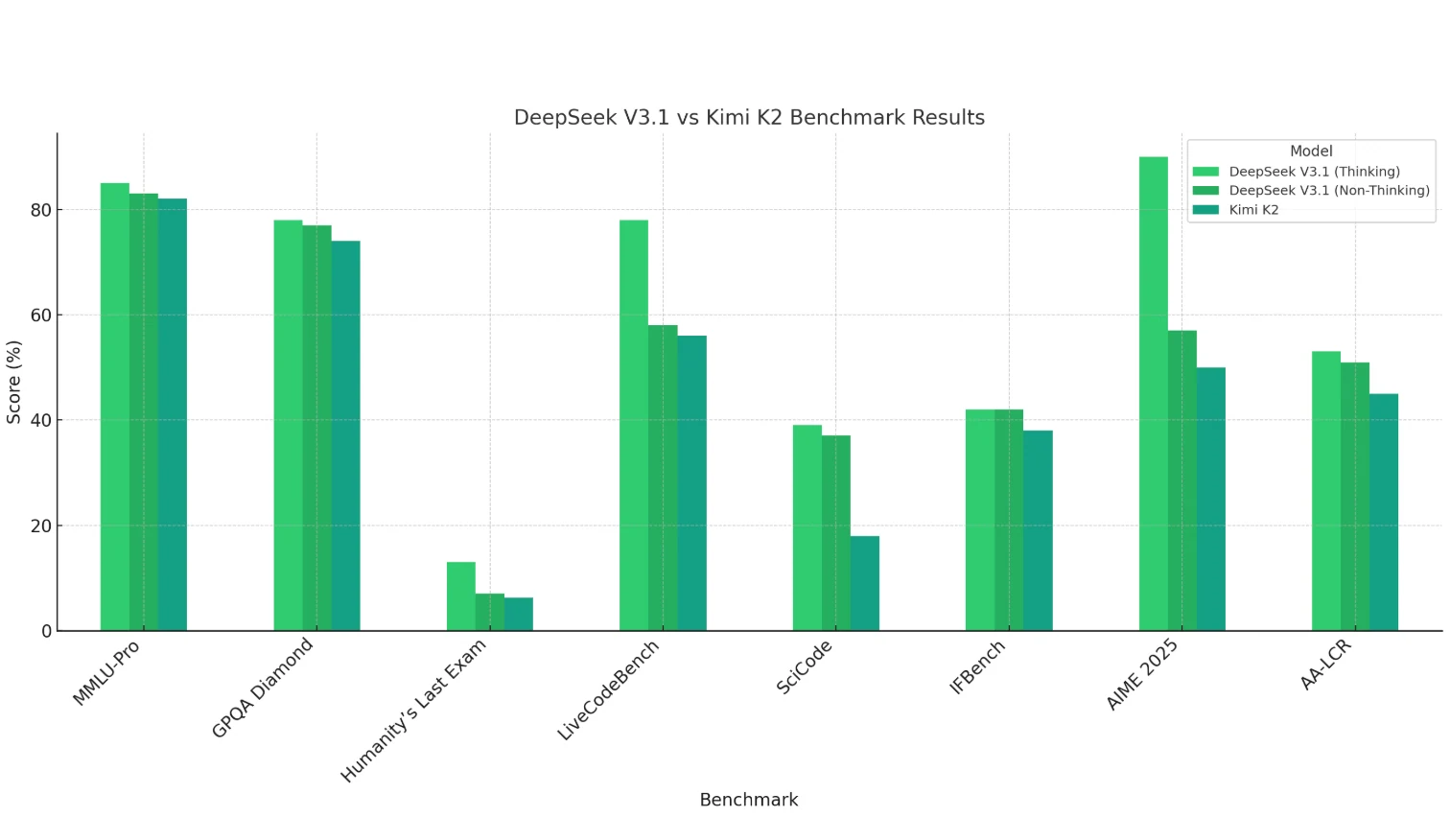
DeepSeek V3.1 (mode Pensée) montre des avantages évidents en mathématiques (AIME 2025), en codage (LiveCodeBench, SciCode) et en raisonnement à long contexte (AA-LCR), démontrant de solides capacités de raisonnement et de calcul.
Kimi K2 est globalement un peu moins performant, surtout en codage et en mathématiques, mais reste compétitif dans les tâches basées sur les connaissances (MMLU, GPQA).
Le mode Non-Pensée de DeepSeek V3.1 obtient généralement des scores légèrement inférieurs au mode Pensée, mais reste comparable ou supérieur à Kimi K2 dans la plupart des cas.
Conclusion : DeepSeek V3.1 est mieux adapté aux tâches intensives en raisonnement et complexes, tandis que Kimi K2 est plus orienté vers les scénarios de connaissances générales.
DeepSeek V3.1 vs Kimi K2 : Vitesse
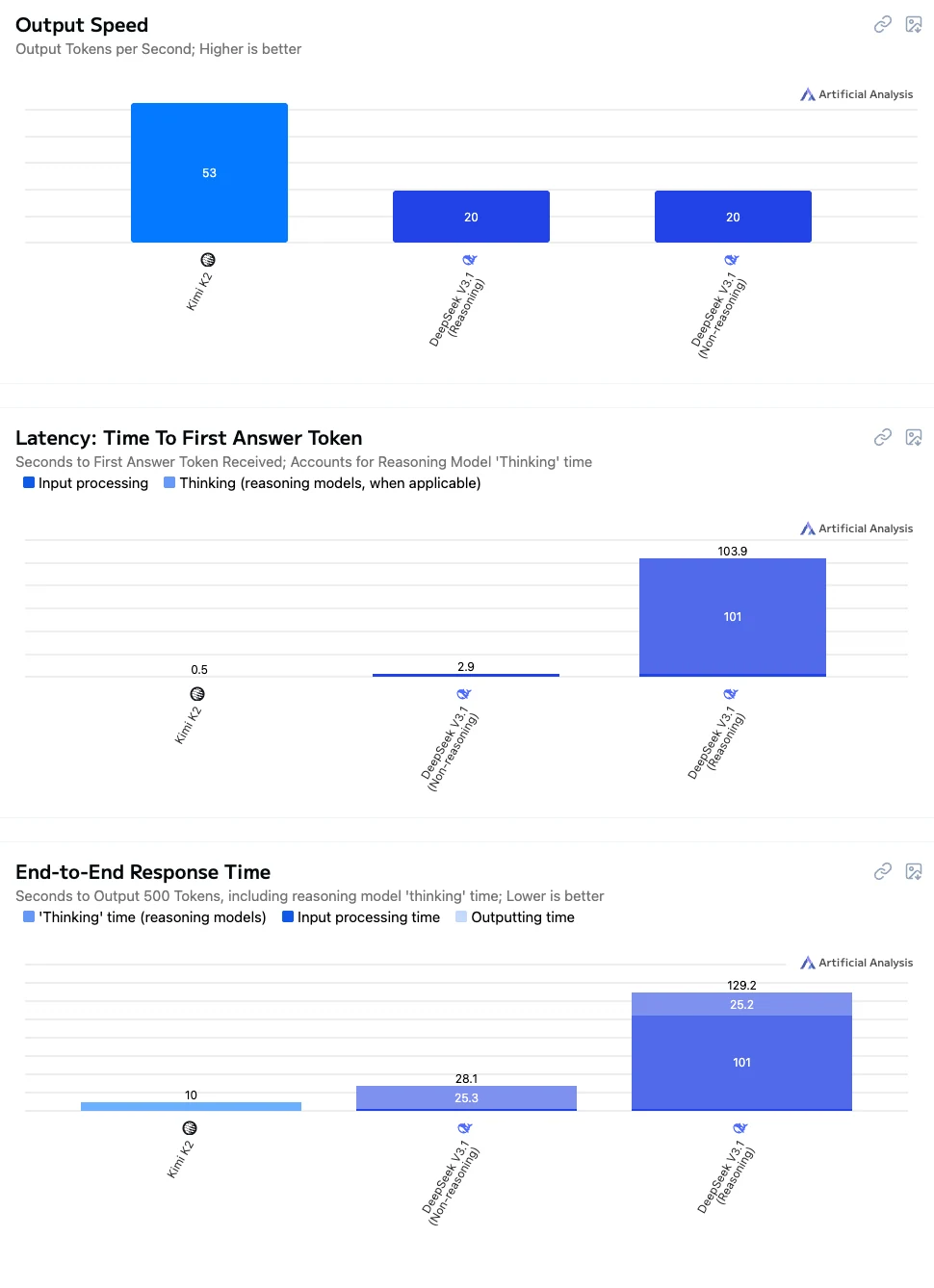
D’après Artificial analysis
- Kimi K2 : Vitesse rapide, faible latence et interaction globale fluide, ce qui le rend bien adapté aux conversations en temps réel, à l’intégration d’applications et aux scénarios éducatifs.
- DeepSeek V3.1 Non-Pensée : Vitesse de réponse moyenne, adapté aux tâches nécessitant une précision raisonnable sans longs temps d’attente.
- DeepSeek V3.1 Pensée : Le plus lent en termes de performances mais offre les capacités de raisonnement et de résolution de problèmes les plus puissantes, idéal pour le raisonnement de haute précision, les calculs complexes et les applications de recherche.
Quel est le meilleur pour les tâches liées au code—DeepSeek V3.1 ou Kimi K2 ?
Tâche : Implémenter un évaluateur d’expressions arithmétiques sécurisé.
Spécifications
- Fonction :
evaluate(expr: str) -> int - Supporte : entiers,
+ - * /, parenthèses, espaces,+/-unaire (ex :-3*(+2)). - La division est une troncature vers zéro (comportement de
int(a/b)en Python, pasfloor). - Doit détecter les entrées invalides et lever une
ValueError. - Pas de
eval,ast.literal_eval, ou analyseurs tiers.
Cas limites à gérer
- Signes unaires multiples :
--5,+-3 - Espaces :
" 1 + ( 2*3 ) " - Précédence et associativité :
2-3-4 == -5,14/3 == 4,-14/3 == -4 - Invalides :
"(1+2","2**3","3//2","2(3)",")1("
Utiliser DeepSeek V3.1 dans le playground gratuit
Utiliser Kimi K2 dans le playground gratuit
Commencez un essai gratuit maintenant !
| Dimension d’évaluation | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Exactitude | Implémente un tokenizer fait main et un analyseur récursif descendant. Gère les opérateurs unaires multiples (--5, +-3), la précédence et l’associativité, et la troncature vers zéro (correction manuelle). Problèmes potentiels : la gestion de la division est trop complexe ; messages d’erreur minimaux. Pas de test intégré. |
Utilise un lexer basé sur des expressions régulières, avec des classes de tokens explicites (PLUS, MINUS, etc.). Troncature correcte via int(a/b). Fournit une suite de tests complète dans __main__ couvrant les cas valides et invalides. Gestion des erreurs plus élégante (ValueError avec message). |
| Qualité du code | Analyse manuelle de bas niveau des caractères. Donne l’impression d’un analyseur “de solution d’examen” : complet mais verbeux et difficile à maintenir. Aucun test inclus. | Modularisation plus propre (Lexer, Parser, evaluate). Plus facile à lire grâce à la simplification par regex. Fournit des tests, permettant une vérification plus rapide. |
| Style et utilisabilité | Fort en raisonnement brut, construit tout à partir de zéro. Convient lorsque un contrôle fin de l’analyse est nécessaire. | Optimisé pour l’expérience développeur : concis, testé, prêt pour la production. Plus pratique pour une intégration immédiate. |
| Verdict | Fort en raisonnement sur les cas limites et la conception d’algorithmes. Démontre une force dans la construction d’analyseurs à partir de zéro, mais plus faible en finition et ergonomie. | Implémentation plus propre, concise et adaptée à la production. Analyse légèrement moins rigoureuse, mais très utilisable. |
| Conclusion | Choisissez DeepSeek V3.1 pour une exactitude robuste et une profondeur algorithmique. | Choisissez Kimi K2 pour un code prêt pour les développeurs, lisible et testé. |
1. Construire la structure globale → DeepSeek V3.1
- Points forts : raisonnement solide, logique rigoureuse—idéal pour poser le squelette de systèmes complexes.
- Meilleur pour :
- Concevoir des interpréteurs/compilateurs, des analyseurs ou des DSL
- Implémenter des algorithmes de base et des structures de données
- Esquisser le flux d’exécution complet (classes, méthodes, hiérarchie d’appels)
- Résultat : une ébauche complète mais quelque peu verbeuse avec la logique principale entièrement en place.
2. Affiner les détails et polir le code → Kimi K2
- Points forts : concis, modulaire et convivial pour les développeurs—idéal pour le nettoyage et la préparation à la production.
- Meilleur pour :
- Réécrire une logique verbeuse en constructions plus élégantes (ex : regex au lieu d’analyse manuelle)
- Ajouter des tests, la gestion des erreurs, la journalisation
- Améliorer le nommage, la modularisation et la lisibilité globale
- Résultat : une implémentation propre, maintenable et prête pour la production.
DeepSeek V3.1 vs Kimi K2 : Configuration système requise
| Modèle et configuration | Besoins en VRAM | GPU nécessaires |
|---|---|---|
| DeepSeek V3.1 (671B) | 1,5 To de VRAM | 8xhH200 peuvent le supporter |
| Kimi K2 (Quantifié) | 250 Go combinés | 1 carte GPU 24 Go |
| Kimi K2 (FP8) | 1 To | Pod unique 8xH200 ou 6xB200 |
Comment accéder aux API DeepSeek V3.1 et Kimi K2 via une API économique et stable ?
Novita AI a officiellement lancé les API DeepSeek V3.1 et Kimi K2, offrant aux développeurs plus de flexibilité pour les tâches de codage et de raisonnement IA haute performance. Les deux modèles sont intégrés avec le support Claude Code, les rendant directement utiles pour les workflows de codage avancés.
Métriques DeepSeek V3.1
- Prix d’entrée : 0,55 $ par million de tokens
- Prix de sortie : 1,66 $ par million de tokens
- Latence : 3,00 s
- Débit : 48,28 TPS
Métriques Kimi K2
- Prix d’entrée : 0,57 $ par million de tokens
- Prix de sortie : 2,30 $ par million de tokens
- Latence : 1,30 s
- Débit : 122,1 TPS
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez DeepSeek V3.1 et Kimi K2 maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.
Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.
Étape 4 : Obtenez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En accédant à la page “Paramètres”, vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec Novita AI LLM. Ceci est un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<Votre clé API>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # ou False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Bonjour !",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
En résumé, DeepSeek V3.1 excelle dans les tâches intensives en raisonnement, mathématiques et liées au code, ce qui en fait un choix solide lorsque la précision et la profondeur logique sont primordiales. Son mode Pensée repousse les limites de la résolution de problèmes complexes, tandis que le mode Non-Pensée offre un équilibre entre vitesse et qualité. Kimi K2 brille dans les tâches de connaissances générales, les applications en temps réel et l’intégration transparente, grâce à sa vitesse de réponse plus rapide, son débit plus élevé et son API prête à l’emploi. Pour les développeurs, un workflow hybride peut être efficace : utilisez DeepSeek V3.1 pour concevoir et raisonner sur des frameworks complexes, puis comptez sur Kimi K2 pour affiner, tester et industrialiser l’implémentation.
Questions fréquentes
Quel modèle est le meilleur pour les tâches de codage ?
DeepSeek V3.1 (mode Pensée) est plus fort en raisonnement algorithmique et en gestion des cas limites, ce qui le rend idéal pour construire des frameworks et des analyseurs complexes. Kimi K2 produit un code plus propre et plus modulaire avec des tests intégrés, ce qui le rend convivial pour les développeurs pour l’affinage et l’intégration.
En quoi les deux modèles diffèrent-ils en termes de vitesse de performance ?
Kimi K2 est significativement plus rapide, avec une latence plus faible et un débit plus élevé, ce qui le rend adapté aux conversations en temps réel et aux scénarios éducatifs. DeepSeek V3.1 est plus lent, surtout en mode Pensée, mais offre un raisonnement et une précision plus solides pour les cas d’utilisation de recherche ou à forte charge de calcul.
Lequel dois-je choisir pour un usage général ?
Si votre priorité est un raisonnement robuste et une précision de codage, choisissez DeepSeek V3.1. Si vous avez besoin de vitesse, d’intégration fluide et de débit élevé, choisissez Kimi K2. De nombreuses équipes bénéficient de la combinaison des deux : DeepSeek pour la conception du framework, Kimi pour l’affinage et le déploiement.
Novita AI est la plateforme cloud tout-en-un qui concrétise vos ambitions IA. API intégrées, serverless, instances GPU—les outils économiques dont vous avez besoin. Éliminez l’infrastructure, commencez gratuitement et faites de votre vision IA une réalité.
Lecture recommandée
Qwen 3 dans les pipelines RAG : LLM, Embedding et Reranking tout-en-un
Comment accéder à GLM 4.5V pour la compréhension d’images et QA visuelle



