

- Deepseek V3.1 vs Kimi K2: Technische Spezifikationen
- Deepseek V3.1 vs Kimi K2: Benchmark
- Deepseek V3.1 vs Kimi K2: Geschwindigkeit
- Welches ist besser für Code-bezogene Aufgaben – DeepSeek V3.1 oder Kimi K2?
- Deepseek V3.1 vs Kimi K2: Systemanforderungen
- Wie erhält man Zugriff auf Deepseek V3.1 und Kimi K2 über eine günstige und stabile API?
Beim Erstellen zuverlässiger KI-gesteuerter Anwendungen stehen Entwickler oft vor einem Zielkonflikt zwischen tiefgehender Denkfähigkeit und praktischer Benutzerfreundlichkeit. Dieser Artikel befasst sich mit dieser Herausforderung, indem er DeepSeek V3.1 und Kimi K2 vergleicht und zeigt, wie sie sich ergänzen. In der Praxis kann ein hybrider Workflow sehr effektiv sein.
Deepseek V3.1 vs Kimi K2: Technische Spezifikationen
| Funktion | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Parameter gesamt | 671B | 1 Billion |
| Aktivierte pro Token | ~37B | ~32B |
| Experten | 257 (8 aktiv/Token) | 384 (8 aktiv/Token) |
| Kontextfenster | 128K Token | 128K Token |
| Architektur | MoE (MLA), effiziente Lastverteilung | MoE + MuonClip-Optimierer, agentisches Reinforcement |
| Spezialmodi | Hybride Inferenz (Denken / Nicht-Denken) | Aufgabenorientiert (Instruct-Variante) |
Sowohl DeepSeek V3.1 als auch Kimi K2 haben eigene Chat-Vorlagen eingeführt, um die Modelle in realen Anwendungen leichter steuern und integrieren zu können:
DeepSeek V3.1 verwendet spezielle Token (
thinking/response), sodass Entwickler explizit zwischen schnellen Direktantworten und tiefergehendem Nachdenken wechseln können,was sich für Szenarien eignet, die eine feinkörnige Kontrolle über Kosten und Leistung erfordern, während Kimi K2 ein Standard-OpenAI-
messages-Format verwendet, das eine einfache Plug-and-Play-Integration für Produkte und Agenten bietet.
DeepSeek V3.1 (Nicht-Denken vs Denken)
Präfix Nicht-Denken
You are DeepSeek V3.1.
<|User|>Was ist RLHF?<|Assistant|>
Präfix Denken
You are DeepSeek V3.1.
<|User|>Was ist RLHF?<|Assistant|>Denken
Kimi K2 (Standard Chat-API)
messages = [
{"role": "system", "content": "Du bist Kimi, ein KI-Assistent."},
{"role": "user", "content": "Was ist RLHF?"}
]
| Dimension | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Eingabeformat | Benutzerdefiniertes Format mit speziellen Token Denken/Antwort |
Standard OpenAI Chat-API-Format |
| Modussteuerung | Explizite Trennung von Denken vs Nicht-Denken | Keine expliziten Modi; Modell entscheidet implizit |
| Mehrere Durchgänge | Manuelle Kontextverknüpfung mit Token erforderlich | Einfaches Anhängen von Nachrichten im Array |
| Flexibilität | Hoch: Entwickler können Denken erzwingen oder deaktivieren | Mittel: Verlässt sich auf System-Prompt und Parameter |
| Benutzerfreundlichkeit | Komplexer, strenges Template erforderlich | Einfach, Plug-and-Play |
Deepseek V3.1 vs Kimi K2: Benchmark
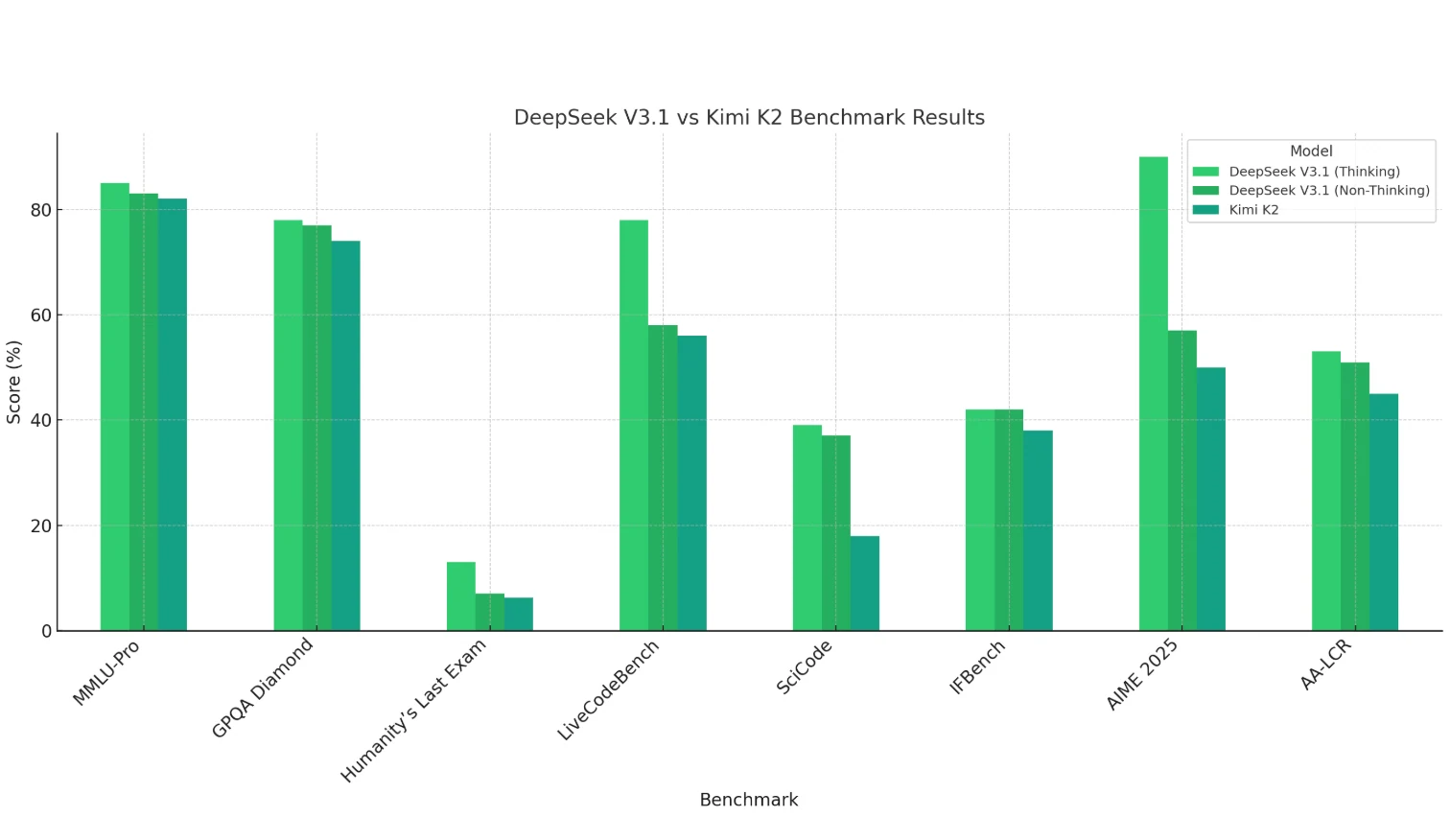
DeepSeek V3.1 (Denkmodus) zeigt deutliche Vorteile in Mathematik (AIME 2025), Programmieren (LiveCodeBench, SciCode) und Langkontext-Denken (AA-LCR) und demonstriert starke Denk- und Rechenfähigkeiten.
Kimi K2 schneidet insgesamt etwas schwächer ab – besonders beim Programmieren und in Mathematik – bleibt aber bei wissensbasierten Aufgaben (MMLU, GPQA) wettbewerbsfähig.
Der Nicht-Denk-Modus von DeepSeek V3.1 erzielt normalerweise etwas niedrigere Werte als der Denkmodus, übertrifft oder erreicht aber in den meisten Fällen Kimi K2.
Fazit: DeepSeek V3.1 eignet sich besser für denkintensive und komplexe Aufgaben, während Kimi K2 eher auf allgemeine Wissensszenarien ausgerichtet ist.
Deepseek V3.1 vs Kimi K2: Geschwindigkeit
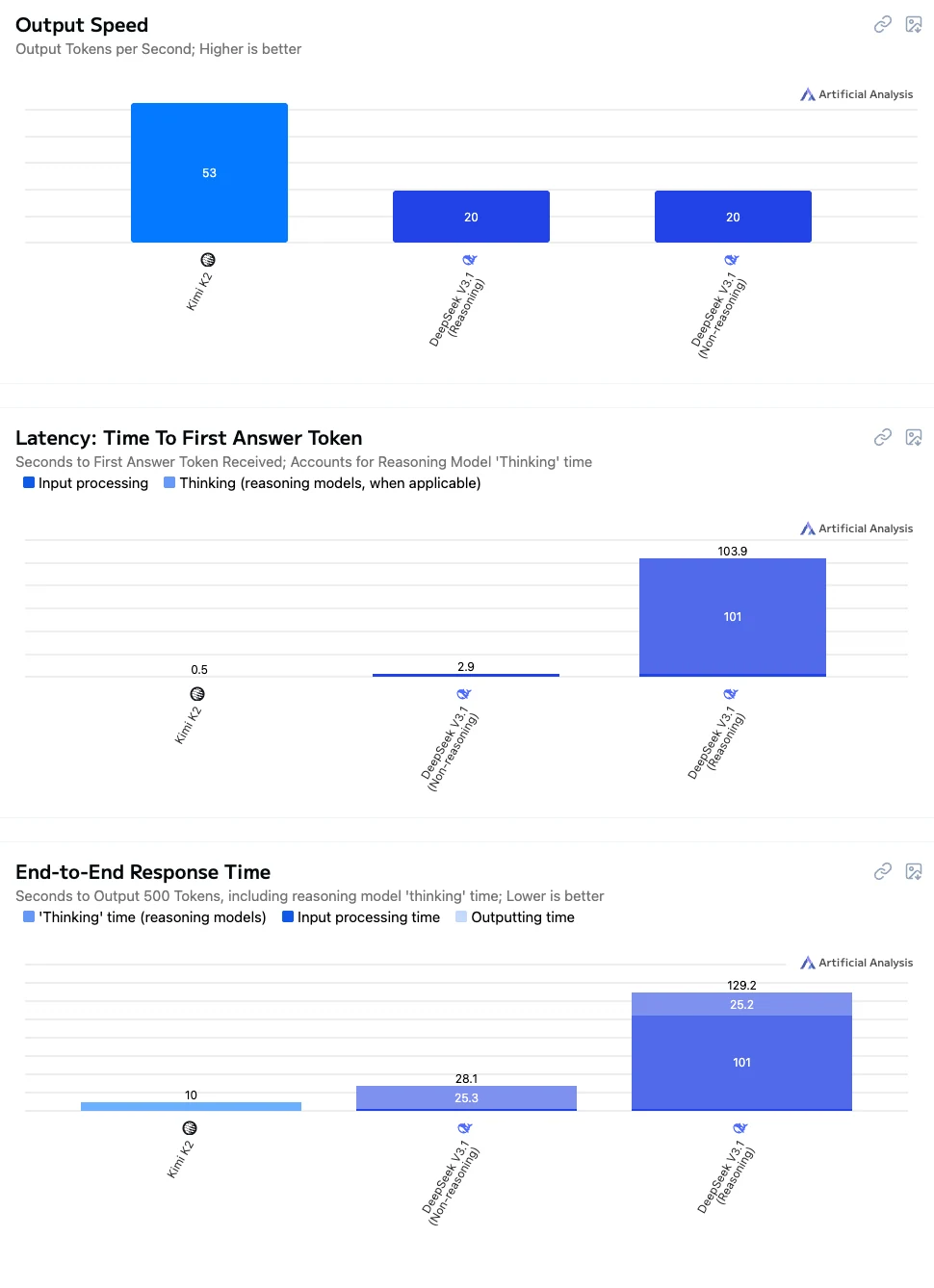
- Kimi K2: Hohe Geschwindigkeit, niedrige Latenz und insgesamt reibungslose Interaktion, gut geeignet für Echtzeitgespräche, Anwendungsintegration und Bildungsszenarien.
- DeepSeek V3.1 Nicht-Denken: Mittlere Antwortgeschwindigkeit, geeignet für Aufgaben, die eine angemessene Genauigkeit ohne lange Wartezeiten erfordern.
- DeepSeek V3.1 Denken: Die langsamste Leistung, aber die stärksten Denk- und Problemlösungsfähigkeiten, ideal für hochpräzises Denken, komplexe Berechnungen und forschungsorientierte Anwendungen.
Welches ist besser für Code-bezogene Aufgaben – DeepSeek V3.1 oder Kimi K2?
Aufgabe: Implementieren Sie einen sicheren arithmetischen Ausdrucksauswerter.
Spezifikation
- Funktion:
evaluate(expr: str) -> int - Unterstützt: Ganzzahlen,
+ - * /, Klammern, Leerzeichen, unäres+/-(z. B.-3*(+2)). - Division ist ganzzahlige Kürzung gegen Null (entspricht Python’s
int(a/b), nichtfloor). - Muss ungültige Eingaben erkennen und
ValueErrorauslösen. - Kein
eval,ast.literal_evaloder Drittanbieter-Parser.
Randfälle, die behandelt werden müssen
- Mehrere unäre Zeichen:
--5,+-3 - Leerzeichen:
" 1 + ( 2*3 ) " - Vorrang & Assoziativität:
2-3-4 == -5,14/3 == 4,-14/3 == -4 - Ungültig:
"(1+2","2**3","3//2","2(3)",")1("
Verwenden Sie Deepseek V3.1 im kostenlosen Playground
Verwenden Sie Kimi K2 im kostenlosen Playground
Starten Sie jetzt eine kostenlose Testversion!
| Bewertungsdimension | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Korrektheit | Implementiert einen handgeschriebenen Tokenizer und rekursiv-absteigenden Parser. Behandelt mehrere unäre Operatoren (--5, +-3), Vorrang und Assoziativität und Divisionskürzung gegen Null (manuelle Korrektur). Mögliche Probleme: Divisionsbehandlung überkompliziert; Fehlermeldungen minimal. Kein eingebauter Testrahmen. |
Verwendet einen regex-basierten Lexer mit expliziten Token-Klassen (PLUS, MINUS, etc.). Korrekte Kürzung via int(a/b). Bietet eine vollständige Testsuite in __main__, die gültige und ungültige Fälle abdeckt. Fehlerbehandlung eleganter (ValueError mit Nachricht). |
| Codequalität | Low-Level manuelle Zeichenabtastung. Fühlt sich wie ein “Prüfungslösungs”-Parser an: gründlich, aber ausführlich und schwerer zu warten. Kein Testrahmen enthalten. | Sauberere Modularisierung (Lexer, Parser, evaluate). Leichter lesbar durch Regex-Vereinfachung. Bietet Tests für schnellere Verifizierung. |
| Stil & Benutzerfreundlichkeit | Stark im rohen Denken, baut alles von Grund auf. Geeignet, wenn eine feinkörnige Parsing-Kontrolle erforderlich ist. | Optimiert für Entwicklererfahrung: prägnant, getestet, produktionsreif. Praktischer für sofortige Integration. |
| Fazit | Stark im Denken über Randfälle und Algorithmusdesign. Zeigt Stärke beim Aufbau von Parser von Grund auf, aber schwächer in Feinschliff und Ergonomie. | Sauberer, prägnanter und produktionsfreundlicher. Etwas weniger rigoroses Parsing, aber hochgradig nutzbar. |
| Schlussfolgerung | Wählen Sie DeepSeek V3.1 für robuste Korrektheit und algorithmische Tiefe. | Wählen Sie Kimi K2 für entwicklerfreundlichen, lesbaren und getesteten Code. |
1. Aufbau des Gesamtgerüsts → DeepSeek V3.1
- Stärken: starkes Denken, strenge Logik – ideal, um das Skelett komplexer Systeme zu erstellen.
- Am besten geeignet für:
- Entwerfen von Interpretern/Compilern, Parsern oder DSLs
- Implementieren von Kernalgorithmen und Datenstrukturen
- Skizzieren des vollständigen Ausführungsflusses (Klassen, Methoden, Aufrufhierarchie)
- Ergebnis: ein vollständiger, aber etwas ausführlicher Entwurf mit vollständiger Hauptlogik.
2. Verfeinern von Details & Polieren von Code → Kimi K2
- Stärken: prägnant, modular und entwicklerfreundlich – ideal für Aufräumarbeiten und Produktionsreife.
- Am besten geeignet für:
- Umschreiben ausführlicher Logik in elegantere Konstrukte (z. B. Regex statt manueller Abtastung)
- Hinzufügen von Tests, Fehlerbehandlung, Logging
- Verbessern von Benennung, Modularisierung und Lesbarkeit
- Ergebnis: eine saubere, wartbare, produktionsreife Implementierung.
Deepseek V3.1 vs Kimi K2: Systemanforderungen
| Modell & Konfiguration | VRAM-Bedarf | GPU-Anforderungen |
|---|---|---|
| DeepSeek V3.1 (671B) | 1,5 TB VRAM | 8xH200 können es unterstützen |
| Kimi K2 (quantisiert) | 250 GB gesamt | 1x 24GB GPU |
| Kimi K2 (FP8) | 1 TB | Single 8xH200 oder 6xB200 Pod |
Wie erhält man Zugriff auf Deepseek V3.1 und Kimi K2 über eine günstige und stabile API?
Novita AI hat offiziell die DeepSeek V3.1- und Kimi K2-APIs eingeführt, die Entwicklern mehr Flexibilität für leistungsstarke KI-Programmier- und Denkaufgaben bieten. Beide Modelle sind in die Claude Code Unterstützung integriert, was sie direkt für erweiterte Codierungs-Workflows nutzbar macht.
DeepSeek V3.1 Metriken
- Eingabepreis: 0,55 USD pro Million Token
- Ausgabepreis: 1,66 USD pro Million Token
- Latenz: 3,00s
- Durchsatz: 48,28 TPS
Kimi K2 Metriken
- Eingabepreis: 0,57 USD pro Million Token
- Ausgabepreis: 2,30 USD pro Million Token
- Latenz: 1,30s
- Durchsatz: 122,1 TPS
Schritt 1: Anmelden und auf die Modellbibliothek zugreifen
Melden Sie sich in Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Testen Sie Deepseek V3.1 und Kimi K2 jetzt!
Schritt 2: Wählen Sie Ihr Modell
Durchsuchen Sie die verfügbaren Optionen und wählen Sie das Modell aus, das Ihren Anforderungen entspricht.
Schritt 3: Starten Sie Ihre kostenlose Testversion
Beginnen Sie Ihre kostenlose Testversion, um die Fähigkeiten des ausgewählten Modells zu erkunden.
Schritt 4: Holen Sie sich Ihren API-Schlüssel
Zur Authentifizierung mit der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Gehen Sie zur Seite „Einstellungen“, um den API-Schlüssel wie im Bild gezeigt zu kopieren.

Schritt 5: Installieren Sie die API
Installieren Sie die API mit dem für Ihre Programmiersprache spezifischen Paketmanager.
Importieren Sie nach der Installation die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit der Interaktion mit Novita AI LLM zu beginnen. Dies ist ein Beispiel für die Verwendung der Chat Completions API für Python-Benutzer.
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<Your API Key>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # or False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Zusammenfassend zeichnet sich DeepSeek V3.1 durch denkintensive, mathematisch schwere und codebezogene Aufgaben aus und ist eine gute Wahl, wenn Genauigkeit und logische Tiefe entscheidend sind. Sein Denkmodus erweitert die Grenzen der komplexen Problemlösung, während der Nicht-Denk-Modus eine Balance zwischen Geschwindigkeit und Qualität bietet. Kimi K2 glänzt bei allgemeinen Wissensaufgaben, Echtzeitanwendungen und nahtloser Integration dank seiner schnelleren Antwortgeschwindigkeit, höherem Durchsatz und Plug-and-Play-API. Für Entwickler kann ein hybrider Workflow effektiv sein: Verwenden Sie DeepSeek V3.1, um komplexe Frameworks zu entwerfen und zu durchdenken, und verlassen Sie sich dann auf Kimi K2, um die Implementierung zu verfeinern, zu testen und produktionsreif zu machen.
Häufig gestellte Fragen
Welches Modell ist besser für Programmieraufgaben?
DeepSeek V3.1 (Denkmodus) ist stärker in algorithmischem Denken und der Behandlung von Randfällen, ideal zum Erstellen von Frameworks und komplexen Parsern. Kimi K2 produziert saubereren, modulareren Code mit eingebauten Tests und ist entwicklerfreundlich für Verfeinerung und Integration.
Wie unterscheiden sich die beiden Modelle in der Leistungsgeschwindigkeit?
Kimi K2 ist deutlich schneller, mit niedrigerer Latenz und höherem Durchsatz, geeignet für Echtzeitgespräche und Bildungsszenarien. DeepSeek V3.1 ist langsamer, besonders im Denkmodus, liefert aber stärkeres Denken und höhere Genauigkeit für forschungs- oder rechenintensive Anwendungsfälle.
Welches sollte ich für den allgemeinen Gebrauch wählen?
Wenn Ihre Priorität robustes Denken und Codierungsgenauigkeit ist, wählen Sie DeepSeek V3.1. Wenn Sie Geschwindigkeit, reibungslose Integration und hohen Durchsatz benötigen, wählen Sie Kimi K2. Viele Teams profitieren von der Kombination beider: DeepSeek für das Framework-Design, Kimi für Verfeinerung und Bereitstellung.
Novita AI ist die All-in-One-Cloud-Plattform, die Ihre KI-Ambitionen unterstützt. Integrierte APIs, serverlos, GPU-Instanz – die kostengünstigen Tools, die Sie brauchen. Verzichten Sie auf Infrastruktur, starten Sie kostenlos und verwirklichen Sie Ihre KI-Vision.
Empfohlene Lektüre
Qwen 3 in RAG-Pipelines: All-in-One LLM, Embedding und Reranking Modelle
Wie man auf GLM 4.5V für Bildverständnis und visuelle Frage-Antwort zugreift



