

안정적인 AI 기반 애플리케이션을 구축할 때 개발자는 종종 **심층 추론 능력 ** 과 **실용적인 사용성 ** 사이에서 절충을 고민합니다. 이 글에서는 DeepSeek V3.1과 Kimi K2를 비교하여 두 모델이 어떻게 서로를 보완하는지 보여줍니다. 실제로 하이브리드 워크플로우는 매우 효과적일 수 있습니다.
Deepseek V3.1 vs Kimi K2: 기술 사양
| 기능 | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| 총 파라미터 수 | 671B | 1조 |
| 토큰당 활성화 파라미터 | ~37B | ~32B |
| 전문가 수 | 257 (토큰당 8개 활성화) | 384 (토큰당 8개 활성화) |
| 컨텍스트 윈도우 | 128K 토큰 | 128K 토큰 |
| 아키텍처 | MoE (MLA), 효율적인 부하 분산 | MoE + MuonClip 최적화 도구, 에이전트 강화 학습 |
| 특수 모드 | 하이브리드 추론 (Thinking / Non-Thinking) | 에이전트 작업 중심 (Instruct 변형) |
DeepSeek V3.1 과 Kimi K2 는 모두 실제 애플리케이션에서 모델을 제어하고 통합하기 쉽도록 자체 채팅 템플릿을 도입했습니다.
DeepSeek V3.1은 특수 토큰(
thinking/response)을 사용하여 개발자가 빠른 직접 응답과 심층 추론 사이를 명시적으로 전환할 수 있도록 합니다. 이는 비용과 성능에 대한 세밀한 제어가 필요한 시나리오에 적합합니다. 반면 Kimi K2는 표준 OpenAI 스타일의messages형식을 채택하여 제품 및 에이전트에 간단한 플러그 앤 플레이 통합을 제공합니다.
DeepSeek V3.1 (Non-Thinking vs Thinking)
Non-Thinking 접두사
You are DeepSeek V3.1.
???What is RLHF?
???response
Thinking 접두사
You are DeepSeek V3.1.
???What is RLHF?
???thinking
Kimi K2 (표준 채팅 API)
messages = [
{"role": "system", "content": "You are Kimi, an AI assistant."},
{"role": "user", "content": "What is RLHF?"}
]
| 측면 | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| 프롬프트 스타일 | 특수 토큰 thinking / response를 사용한 사용자 정의 형식 |
표준 OpenAI Chat API 형식 |
| 모드 제어 | Thinking과 Non-Thinking의 명시적 구분 | 명시적 모드 없음; 모델이 암시적으로 결정 |
| 멀티 턴 | 토큰으로 수동 컨텍스트 연결 필요 | 배열에 메시지만 추가하면 됨 |
| 유연성 | 높음: 개발자가 추론을 강제 또는 비활성화 가능 | 중간: 시스템 프롬프트 및 파라미터에 의존 |
| 사용 편의성 | 더 복잡하고 엄격한 템플릿 필요 | 간단한 플러그 앤 플레이 |
Deepseek V3.1 vs Kimi K2: 벤치마크
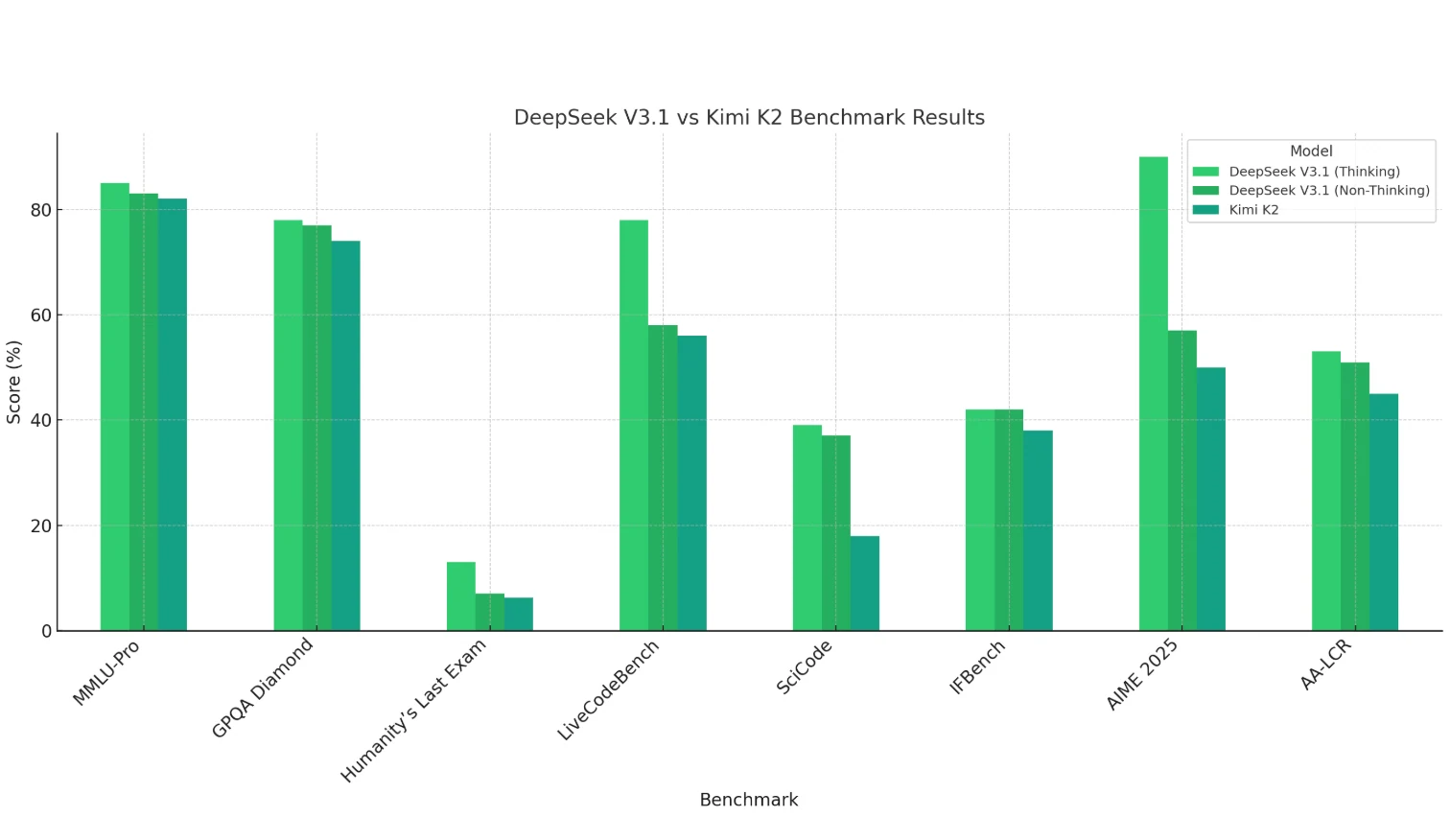
DeepSeek V3.1 (Thinking 모드) 는 수학(AIME 2025), 코딩(LiveCodeBench, SciCode), 긴 컨텍스트 추론(AA-LCR)에서 명확한 우위를 보이며 강력한 추론 및 계산 능력을 입증합니다.
Kimi K2 는 전반적으로 다소 약한 성능을 보입니다. 특히 코딩과 수학에서 그렇지만, 지식 기반 작업(MMLU, GPQA)에서는 경쟁력을 유지합니다.
**DeepSeek V3.1의 Non-Thinking 모드 ** 는 일반적으로 Thinking 모드보다 약간 낮은 점수를 기록하지만, 대부분의 경우 Kimi K2 와 동등하거나 더 나은 성능을 보입니다.
결론: DeepSeek V3.1은 추론 집약적이고 복잡한 작업에 더 적합하며, Kimi K2는 일반 지식 시나리오에 더 적합합니다.
Deepseek V3.1 vs Kimi K2: 속도
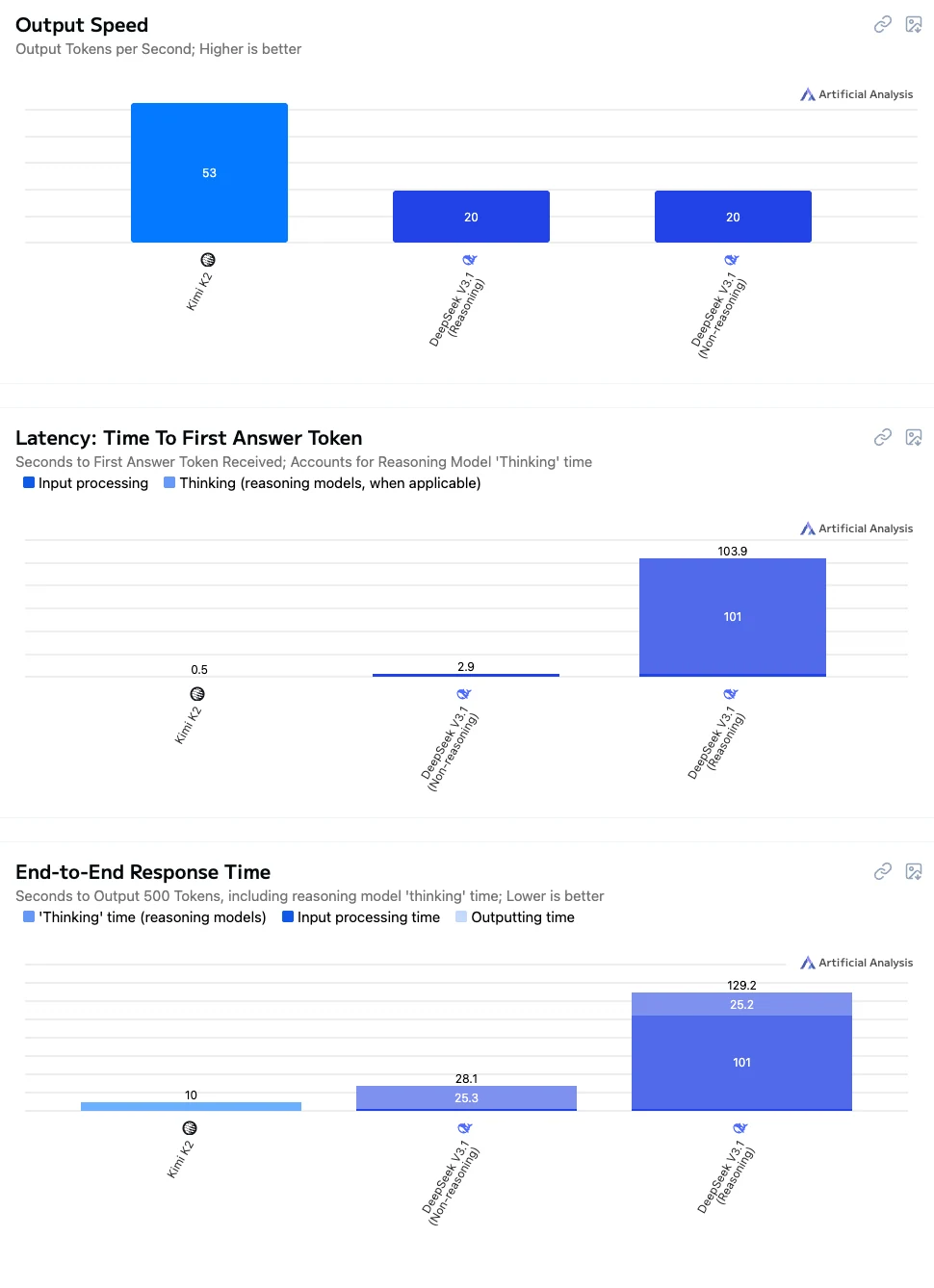
- Kimi K2: 빠른 속도, 낮은 지연 시간, 전반적으로 부드러운 상호작용으로 실시간 대화, 애플리케이션 통합 및 교육 시나리오에 적합합니다.
- DeepSeek V3.1 Non-Thinking: 중간 수준의 응답 속도로, 긴 대기 시간 없이 적절한 정확도가 필요한 작업에 적합합니다.
- DeepSeek V3.1 Thinking: 가장 느린 성능이지만 가장 강력한 추론 및 복잡한 문제 해결 능력을 제공하므로 고정밀 추론, 복잡한 계산 및 연구 중심 애플리케이션에 이상적입니다.
코드 관련 작업에 더 나은 모델은? DeepSeek V3.1 vs Kimi K2
작업: 안전한 산술 표현식 평가기 구현
사양
- 함수:
evaluate(expr: str) -> int - 지원: 정수,
+ - * /, 괄호, 공백, 단항+/-(예:-3*(+2)) - 나눗셈은 0 방향으로의 정수 절삭 (Python의
int(a/b)동작, 내림이 아님) - 잘못된 입력을 감지하고
ValueError를 발생시켜야 함 eval,ast.literal_eval또는 타사 파서 사용 금지
처리해야 할 엣지 케이스
- 여러 단항 부호:
--5,+-3 - 공백:
" 1 + ( 2*3 ) " - 우선순위 및 결합성:
2-3-4 == -5,14/3 == 4,-14/3 == -4 - 잘못된 경우:
"(1+2","2**3","3//2","2(3)",")1("
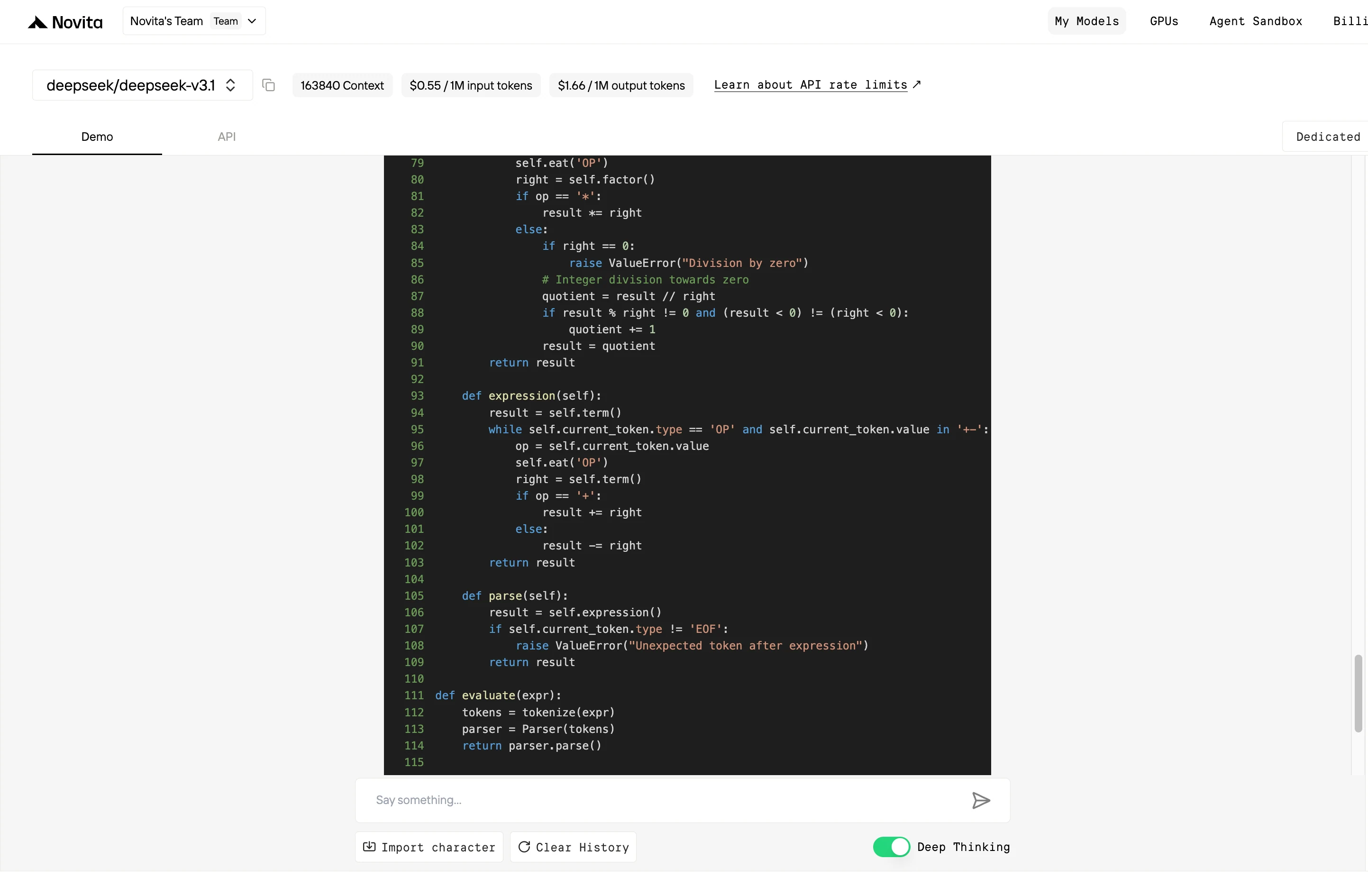
무료 플레이그라운드에서 Deepseek V3.1 사용하기
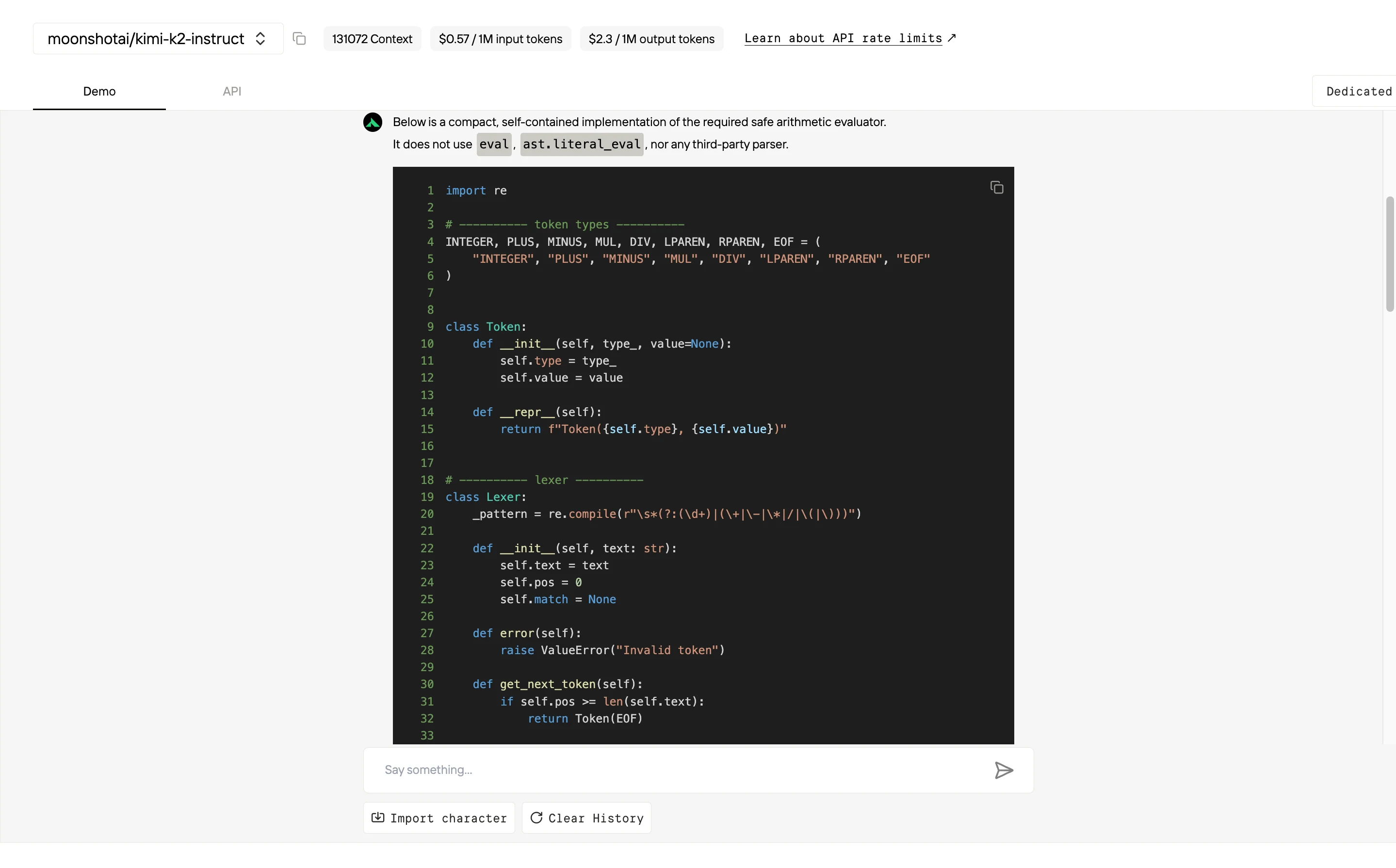
무료 플레이그라운드에서 Kimi K2 사용하기
| 평가 항목 | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| 정확성 | 수동으로 작성된 토크나이저와 재귀 하향 파서 구현. 다중 단항 연산자(--5, +-3), 우선순위 및 결합성, 0 방향 절삭 나눗셈(수동 수정) 처리. 잠재적 문제: 나눗셈 처리가 지나치게 복잡함; 오류 메시지 최소화. 내장 테스트 도구 없음. |
정규식을 사용한 렉서, 명시적 토큰 클래스(PLUS, MINUS 등). int(a/b)를 통한 올바른 절삭. __main__에 유효 및 무효 케이스를 포함한 전체 테스트 스위트 제공. 오류 처리가 더 우아함(메시지 포함 ValueError). |
| 코드 품질 | 저수준 수동 문자 스캐닝. “시험 답안” 스타일 파서처럼 느껴짐: 철저하지만 장황하고 유지보수가 어려움. 테스트 도구 미포함. | 더 깔끔한 모듈화(Lexer, Parser, evaluate). 정규식 단순화로 인해 가독성 향상. 테스트 제공으로 더 빠른 검증 가능. |
| 스타일 및 사용성 | 원시 추론에 강점, 모든 것을 처음부터 구축. 세분화된 파싱 제어가 필요할 때 적합. | 개발자 경험에 최적화: 간결하고, 테스트되었으며, 프로덕션 준비됨. 즉각적인 통합에 더 실용적임. |
| 평가 | 엣지 케이스 및 알고리즘 설계에 대한 추론에 강점. 처음부터 파서를 구축하는 능력에서 강점을 보이지만, 완성도와 사용성은 약함. | 더 깔끔하고 간결하며 프로덕션 친화적인 구현. 약간 덜 엄격한 파싱이지만 사용성이 높음. |
| 결론 | 강력한 정확성과 알고리즘 깊이가 필요하다면 DeepSeek V3.1을 선택하세요. | 개발자 친화적이고 읽기 쉽고 테스트된 코드가 필요하다면 Kimi K2를 선택하세요. |
1. 전체 프레임워크 구축 → DeepSeek V3.1
- 강점: 강력한 추론, 엄격한 논리 — 복잡한 시스템의 골격을 만드는 데 탁월함.
- 최적 대상:
- 인터프리터/컴파일러, 파서 또는 DSL 설계
- 핵심 알고리즘 및 데이터 구조 구현
- 전체 실행 흐름 개요 (클래스, 메서드, 호출 계층 구조)
- **결과 : ** 완전하지만 다소 장황한 초안으로 주요 로직이 완전히 자리잡음.
2. 세부 사항 개선 및 코드 다듬기 → Kimi K2
- 강점: 간결하고 모듈화되어 있으며 개발자 친화적 — 정리 및 프로덕션 준비에 탁월함.
- 최적 대상:
- 장황한 로직을 더 우아한 구조로 재작성 (예: 수동 스캐닝 대신 정규식)
- 테스트, 오류 처리, 로깅 추가
- 명명, 모듈화 및 전반적인 가독성 향상
- **결과 : ** 깔끔하고 유지보수 가능하며 프로덕션에 바로 사용할 수 있는 구현.
Deepseek V3.1 vs Kimi K2: 시스템 요구사항
| 모델 및 구성 | VRAM 요구사항 | 필요 GPU |
|---|---|---|
| DeepSeek V3.1 (671B) | 1.5 TB VRAM | 8xH200 지원 가능 |
| Kimi K2 (양자화) | 250 GB 결합 | 1x 24GB GPU |
| Kimi K2 (FP8) | 1 TB | 단일 8xH200 또는 6xB200 팟 |
저렴하고 안정적인 API로 Deepseek V3.1과 Kimi K2에 접근하는 방법
Novita AI는 DeepSeek V3.1 및 Kimi K2 API를 공식 출시하여 개발자에게 고성능 AI 코딩 및 추론 작업을 위한 더 많은 유연성을 제공합니다. 두 모델 모두 Claude Code 지원과 통합되어 고급 코딩 워크플로우에 직접 사용할 수 있습니다.
DeepSeek V3.1 성능 지표
- 입력 가격: 백만 토큰당 $0.55
- 출력 가격: 백만 토큰당 $1.66
- 지연 시간: 3.00초
- 처리량: 48.28 TPS
Kimi K2 성능 지표
- 입력 가격: 백만 토큰당 $0.57
- 출력 가격: 백만 토큰당 $2.30
- 지연 시간: 1.30초
- 처리량: 122.1 TPS
1단계: 로그인 및 모델 라이브러리 접근
계정에 로그인하고 Model Library 버튼을 클릭하세요.

지금 DeepSeek V3.1과 Kimi K2를 사용해보세요!
2단계: 모델 선택
사용 가능한 옵션을 탐색하고 필요에 맞는 모델을 선택하세요.
3단계: 무료 체험 시작
선택한 모델의 기능을 탐색하려면 무료 체험을 시작하세요.
4단계: API 키 받기
API 인증을 위해 새 API 키를 제공합니다. “Settings” 페이지로 이동하여 이미지에 표시된 대로 API 키를 복사할 수 있습니다.

5단계: API 설치
프로그래밍 언어에 맞는 패키지 관리자를 사용하여 API를 설치하세요.
설치 후 개발 환경에 필요한 라이브러리를 가져옵니다. API 키로 API를 초기화하여 Novita AI LLM과 상호작용을 시작하세요. 다음은 Python 사용자를 위한 채팅 완성 API 사용 예시입니다.
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<Your API Key>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # or False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
전반적으로 DeepSeek V3.1은 **추론 집약적, 수학 중심, 코드 관련 작업 ** 에서 탁월하여 정확성과 논리적 깊이가 중요한 경우 강력한 선택입니다. Thinking 모드는 복잡한 문제 해결의 한계를 뛰어넘는 반면, Non-Thinking은 속도와 품질의 균형을 제공합니다. Kimi K2는 일반 지식 작업, 실시간 애플리케이션 및 원활한 통합 에서 빛을 발하며, 더 빠른 응답 속도, 높은 처리량 및 플러그 앤 플레이 API 덕분입니다. 개발자에게는 하이브리드 워크플로우가 효과적일 수 있습니다: DeepSeek V3.1을 사용하여 복잡한 프레임워크를 설계하고 추론한 다음, Kimi K2를 사용하여 구현을 개선, 테스트 및 프로덕션화하세요.
자주 묻는 질문
코딩 작업에는 어떤 모델이 더 나은가요?
DeepSeek V3.1(Thinking 모드)은 알고리즘 추론 및 엣지 케이스 처리에서 더 강력하여 프레임워크 및 복잡한 파서 구축에 이상적입니다. Kimi K2는 내장 테스트와 함께 더 깔끔하고 모듈화된 코드를 생성하므로 개선 및 통합에 개발자 친화적입니다.
두 모델의 성능 속도는 어떻게 다른가요?
Kimi K2는 훨씬 빠르며, 지연 시간이 낮고 처리량이 높아 실시간 대화 및 교육 시나리오에 적합합니다. DeepSeek V3.1은 특히 Thinking 모드에서 느리지만, 연구 또는 계산 중심 사용 사례에 대해 더 강력한 추론과 정확성을 제공합니다.
일반적인 사용에는 어떤 것을 선택해야 하나요?
**강력한 추론 및 코딩 정확성 ** 이 우선순위라면 DeepSeek V3.1을 선택하세요. 속도, 원활한 통합 및 높은 처리량 이 필요하다면 Kimi K2를 선택하세요. 많은 팀이 둘을 결합하는 것이 유용합니다: DeepSeek은 프레임워크 설계용, Kimi는 개선 및 배포용입니다.
Novita AI는 AI 야망을 실현하는 올인원 클라우드 플랫폼입니다. 통합 API, 서버리스, GPU 인스턴스 — 필요한 비용 효율적인 도구. 인프라를 제거하고, 무료로 시작하며, AI 비전을 현실로 만드세요.
추천 자료
Qwen 3 in RAG Pipelines: All-in-One LLM, Embedding, and Reranking Models
How to access GLM 4.5V for Image Understanding and Visual QA



