

- DeepSeek V3.1 vs Kimi K2: Especificaciones técnicas
- DeepSeek V3.1 vs Kimi K2: Benchmarks
- DeepSeek V3.1 vs Kimi K2: Velocidad
- ¿Cuál es mejor para tareas de programación: DeepSeek V3.1 o Kimi K2?
- DeepSeek V3.1 vs Kimi K2: Requisitos del sistema
- ¿Cómo acceder a DeepSeek V3.1 y Kimi K2 a través de una API económica y estable?
Al construir aplicaciones impulsadas por IA confiables, los desarrolladores a menudo enfrentan una disyuntiva entre la capacidad de razonamiento profundo y la usabilidad práctica. Este artículo aborda ese desafío comparando DeepSeek V3.1 vs Kimi K2 y mostrando cómo se complementan. En la práctica, un flujo de trabajo híbrido puede ser muy efectivo.
DeepSeek V3.1 vs Kimi K2: Especificaciones técnicas
| Característica | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Parámetros totales | 671B | 1 billón |
| Activados por token | ~37B | ~32B |
| Expertos | 257 (8 activos/token) | 384 (8 activos/token) |
| Ventana de contexto | 128K tokens | 128K tokens |
| Arquitectura | MoE (MLA), balanceo de carga eficiente | MoE + optimizador MuonClip, refuerzo agéntico |
| Modos especiales | Inferencia híbrida (Pensar / No pensar) | Enfoque en tareas agénticas (variante Instruct) |
Tanto DeepSeek V3.1 como Kimi K2 introdujeron sus propias plantillas de chat para facilitar el control y la integración en aplicaciones reales:
DeepSeek V3.1 usa tokens especiales (
thinking/response) para que los desarrolladores puedan cambiar explícitamente entre respuestas directas rápidas y razonamiento más profundo,lo que es adecuado para escenarios que necesitan control detallado sobre costo y rendimiento, mientras que Kimi K2 adopta un formato estándar de mensajes tipo OpenAI, ofreciendo integración simple y plug-and-play para productos y agentes.
DeepSeek V3.1 (No pensar vs Pensar)
Prefijo No pensar
You are DeepSeek V3.1.
usuario¿Qué es RLHF?
asistente respuesta
Prefijo Pensar
You are DeepSeek V3.1.
usuario¿Qué es RLHF?
asistente pensamiento
Kimi K2 (API de chat estándar)
mensajes = [
{"role": "system", "content": "Eres Kimi, un asistente de IA."},
{"role": "user", "content": "¿Qué es RLHF?"}
]
| Dimensión | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Estilo de prompt | Formato personalizado con tokens especiales pensamiento / respuesta |
Formato estándar de API de chat de OpenAI |
| Control de modo | Separación explícita de Pensar vs No pensar | Sin modos explícitos; el modelo decide implícitamente |
| Múltiples turnos | Requiere unión manual del contexto con tokens | Simplemente añade mensajes en un array |
| Flexibilidad | Alta: los desarrolladores pueden forzar o deshabilitar el razonamiento | Media: depende del prompt del sistema y los parámetros |
| Facilidad de uso | Más complejo, requiere plantilla estricta | Simple, plug-and-play |
DeepSeek V3.1 vs Kimi K2: Benchmarks
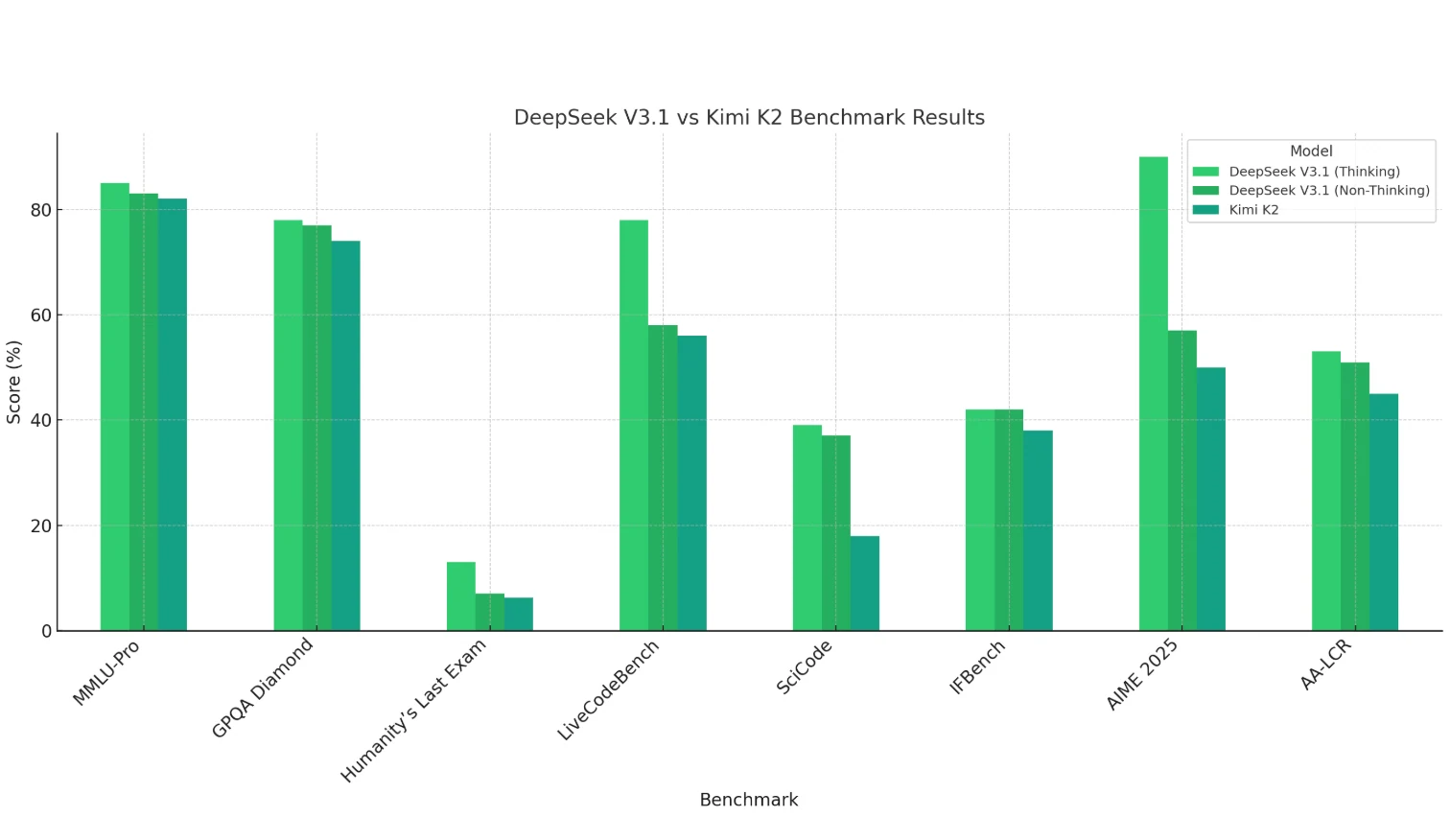
DeepSeek V3.1 (modo Pensar) muestra claras ventajas en matemáticas (AIME 2025), programación (LiveCodeBench, SciCode) y razonamiento de contexto largo (AA-LCR), demostrando sólidas capacidades de razonamiento y computación.
Kimi K2 tiene un rendimiento algo más débil en general, especialmente en programación y matemáticas, pero sigue siendo competitivo en tareas basadas en conocimiento (MMLU, GPQA).
El modo No pensar de DeepSeek V3.1 suele puntuar ligeramente más bajo que el modo Pensar, pero aún así iguala o supera a Kimi K2 en la mayoría de los casos.
*Conclusión: DeepSeek V3.1 es más adecuado para tareas que requieren razonamiento intensivo y complejidad, mientras que Kimi K2 se inclina más hacia escenarios de conocimiento general. *
DeepSeek V3.1 vs Kimi K2: Velocidad
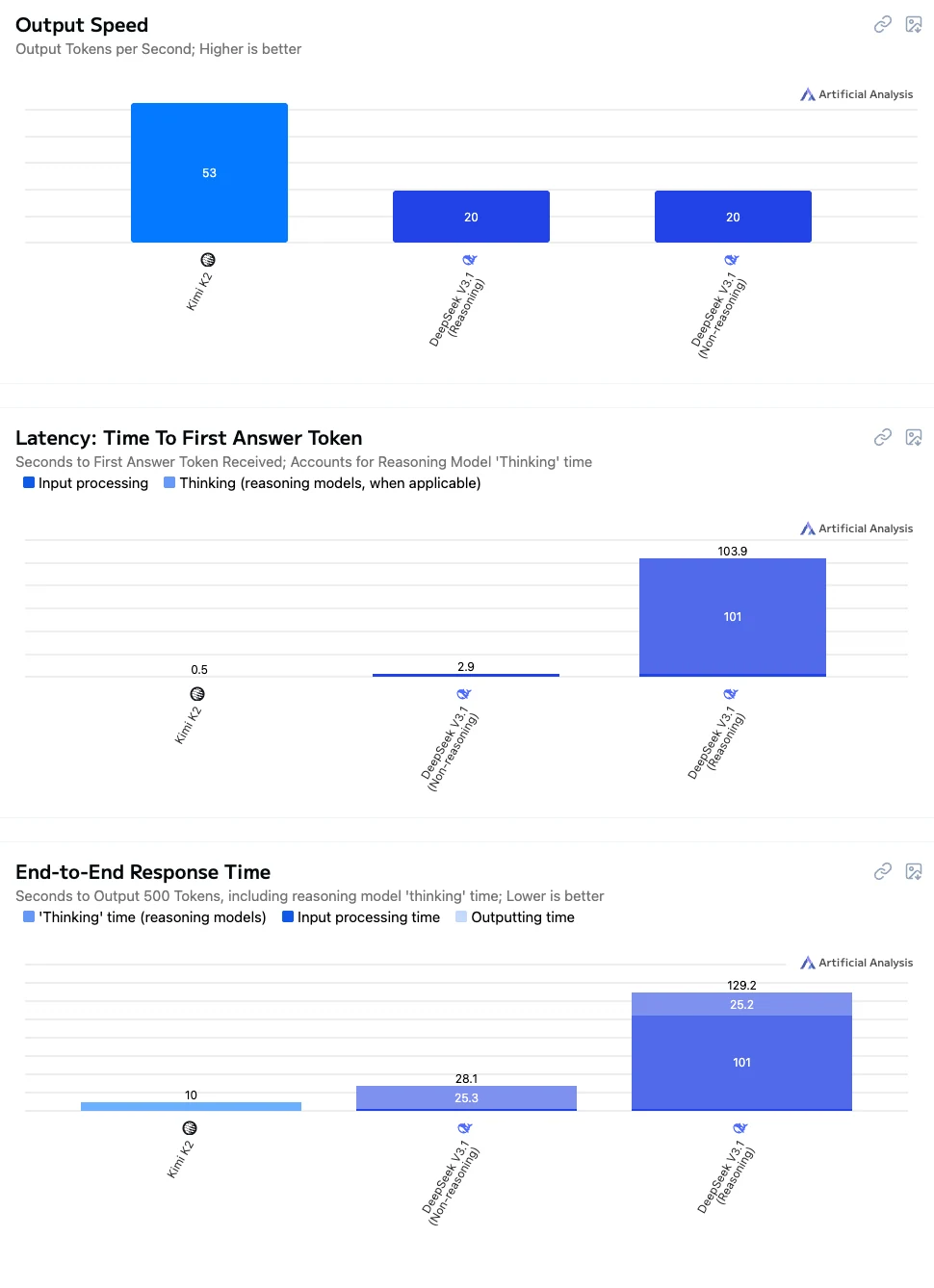
- Kimi K2: Alta velocidad, baja latencia e interacción general fluida, lo que lo hace muy adecuado para conversaciones en tiempo real, integración de aplicaciones y escenarios educativos.
- DeepSeek V3.1 No pensar: Velocidad de respuesta media, adecuado para tareas que requieren una precisión razonable sin tiempos de espera prolongados.
- DeepSeek V3.1 Pensar: El más lento en rendimiento pero ofrece las capacidades de razonamiento y resolución de problemas complejos más sólidas, ideal para aplicaciones de alta precisión de razonamiento, computaciones complejas e investigación.
¿Cuál es mejor para tareas de programación: DeepSeek V3.1 o Kimi K2?
Tarea: Implementar un evaluador seguro de expresiones aritméticas.
Especificación
- Función:
evaluate(expr: str) -> int - Soporta: enteros,
+ - * /, paréntesis, espacios, unarios+/-(ej.,-3*(+2)). - La división es truncamiento de enteros hacia cero (comportamiento de Python
int(a/b), no redondeo hacia abajo). - Debe detectar entrada no válida y lanzar
ValueError. - No se permite
eval,ast.literal_evalni analizadores sintácticos de terceros.
Casos límite a manejar
- Signos unarios múltiples:
--5,+-3 - Espacios:
" 1 + ( 2*3 ) " - Precedencia y asociatividad:
2-3-4 == -5,14/3 == 4,-14/3 == -4 - No válidos:
"(1+2","2**3","3//2","2(3)",")1("
Usar DeepSeek V3.1 en el playground gratuito
Usar Kimi K2 en el playground gratuito
¡Comienza una prueba gratuita ahora!
| Dimensión de evaluación | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| Corrección | Implementa un tokenizador escrito a mano y un analizador descendente recursivo. Maneja múltiples operadores unarios (--5, +-3), precedencia y asociatividad, y truncamiento de división hacia cero (corrección manual). Posibles problemas: el manejo de la división es demasiado complicado; mensajes de error mínimos. Sin conjunto de pruebas integrado. |
Usa un analizador léxico basado en expresiones regulares, con clases de token explícitas (PLUS, MINUS, etc.). Truncamiento correcto usando int(a/b). Proporciona un conjunto completo de pruebas en __main__ que cubre casos válidos e inválidos. Manejo de errores más elegante (ValueError con mensaje). |
| Calidad del código | Escaneo manual de caracteres de bajo nivel. Parece un analizador de “solución de examen”: minucioso pero verboso y difícil de mantener. No incluye conjunto de pruebas. | Modularización más limpia (Lexer, Parser, evaluate). Más fácil de leer debido a la simplificación con expresiones regulares. Proporciona pruebas, lo que permite una verificación más rápida. |
| Estilo y usabilidad | Fuerte en razonamiento puro, construye todo desde cero. Adecuado cuando se necesita un control detallado del análisis sintáctico. | Optimizado para la experiencia del desarrollador: conciso, probado y listo para producción. Más práctico para integración inmediata. |
| Veredicto | Fuerte en razonar sobre casos límite y diseño de algoritmos. Demuestra fortaleza en la construcción de analizadores desde cero, pero más débil en pulido y ergonomía. | Implementación más limpia, concisa y amigable para producción. Análisis sintáctico ligeramente menos riguroso, pero muy utilizable. |
| Conclusión | Elige DeepSeek V3.1 para una corrección robusta y profundidad algorítmica. | Elige Kimi K2 para código listo para desarrolladores, legible y probado. |
1. Construir la estructura general → DeepSeek V3.1
- Fortalezas: razonamiento sólido, lógica rigurosa, ideal para establecer el esqueleto de sistemas complejos.
- Mejor para:
- Diseñar intérpretes/compiladores, analizadores sintácticos o DSL
- Implementar algoritmos centrales y estructuras de datos
- Esbozar el flujo de ejecución completo (clases, métodos, jerarquía de llamadas)
- Resultado: un borrador completo pero algo verboso con la lógica principal completamente implementada.
2. Refinar detalles y pulir el código → Kimi K2
- Fortalezas: conciso, modular y amigable para el desarrollador, ideal para limpieza y preparación para producción.
- Mejor para:
- Reescribir lógica verbosa en construcciones más elegantes (ej., expresiones regulares en lugar de escaneo manual)
- Añadir pruebas, manejo de errores, registro
- Mejorar nombres, modularización y legibilidad general
- Resultado: una implementación limpia, mantenible y lista para producción.
DeepSeek V3.1 vs Kimi K2: Requisitos del sistema
| Modelo y configuración | Requisito de VRAM | Necesidades de GPU |
|---|---|---|
| DeepSeek V3.1 (671B) | 1.5 TB de VRAM | 8xH200 pueden soportarlo |
| Kimi K2 (cuantizado) | 250 GB combinados | 1 GPU de 24 GB |
| Kimi K2 (FP8) | 1 TB | Un solo pod 8xH200 o 6xB200 |
¿Cómo acceder a DeepSeek V3.1 y Kimi K2 a través de una API económica y estable?
Novita AI ha lanzado oficialmente las APIs de DeepSeek V3.1 y Kimi K2, brindando a los desarrolladores más flexibilidad para tareas de programación y razonamiento con IA de alto rendimiento. Ambos modelos están integrados con soporte para Claude Code, lo que los hace directamente útiles para flujos de trabajo de programación avanzados.
Métricas de DeepSeek V3.1
- Precio de entrada: $0.55 por millón de tokens
- Precio de salida: $1.66 por millón de tokens
- Latencia: 3.00s
- Rendimiento: 48.28 TPS
Métricas de Kimi K2
- Precio de entrada: $0.57 por millón de tokens
- Precio de salida: $2.30 por millón de tokens
- Latencia: 1.30s
- Rendimiento: 122.1 TPS
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

¡Prueba DeepSeek V3.1 y Kimi K2 ahora!
Paso 2: Elige tu modelo
Navega entre las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.
Paso 3: Comienza tu prueba gratuita
Inicia tu prueba gratuita para explorar las capacidades del modelo seleccionado.
Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Al ingresar a la página de “Configuración”, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las librerías necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con Novita AI LLM. Este es un ejemplo de uso de la API de completaciones de chat para usuarios de Python.
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<Tu clave de API>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # o False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "¡Hola!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
En resumen, DeepSeek V3.1 destaca en tareas de razonamiento intensivo, matemáticas pesadas y relacionadas con código, lo que lo convierte en una opción sólida cuando la precisión y la profundidad lógica son primordiales. Su modo Pensar lleva al límite la resolución de problemas complejos, mientras que No pensar ofrece un equilibrio entre velocidad y calidad. Kimi K2 brilla en tareas de conocimiento general, aplicaciones en tiempo real e integración sin problemas, gracias a su velocidad de respuesta más rápida, mayor rendimiento y API plug-and-play. Para los desarrolladores, un flujo de trabajo híbrido puede ser efectivo: usa DeepSeek V3.1 para diseñar y razonar a través de marcos complejos, y luego confía en Kimi K2 para refinar, probar y poner en producción la implementación.
Preguntas frecuentes
¿Qué modelo es mejor para tareas de programación?
DeepSeek V3.1 (modo Pensar) es más fuerte en razonamiento algorítmico y manejo de casos límite, lo que lo hace ideal para construir marcos y analizadores sintácticos complejos. Kimi K2 produce código más limpio y modular con pruebas integradas, lo que lo hace amigable para el desarrollador en la refinación e integración.
¿En qué se diferencian los dos modelos en velocidad de rendimiento?
Kimi K2 es significativamente más rápido, con menor latencia y mayor rendimiento, lo que lo hace adecuado para conversaciones en tiempo real y escenarios educativos. DeepSeek V3.1 es más lento, especialmente en modo Pensar, pero ofrece un razonamiento y precisión más sólidos para casos de uso de investigación o computación intensiva.
¿Cuál debería elegir para uso general?
Si tu prioridad es un razonamiento robusto y precisión en la programación, elige DeepSeek V3.1. Si necesitas velocidad, integración fluida y alto rendimiento, elige Kimi K2. Muchos equipos se benefician de combinar ambos: DeepSeek para el diseño del marco, Kimi para la refinación y el despliegue.
Novita AI es la plataforma en la nube integral que impulsa tus ambiciones de IA. APIs integradas, sin servidor, instancias de GPU: las herramientas rentables que necesitas. Elimina la infraestructura, comienza gratis y haz realidad tu visión de IA.
Lectura recomendada
Qwen 3 en pipelines RAG: Modelo LLM, embedding y reranking todo en uno
Cómo acceder a GLM 4.5V para comprensión de imágenes y preguntas visuales
Costo de DeepSeek R1 0528: Comparativa de API, GPU y On-Prem



