

在构建可靠的 AI 驱动应用时,开发者常常需要在深度推理能力和实用易用性之间做出权衡。本文通过比较 DeepSeek V3.1 与 Kimi K2,并展示它们如何互补,来应对这一挑战。在实践中,混合工作流可以非常高效。
DeepSeek V3.1 与 Kimi K2:技术规格
| 特性 | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| 总参数量 | 671B | 1 万亿 |
| 每个 Token 激活量 | 约 37B | 约 32B |
| 专家数量 | 257(每个 Token 激活 8 个) | 384(每个 Token 激活 8 个) |
| 上下文窗口 | 128K tokens | 128K tokens |
| 架构 | MoE (MLA),高效负载均衡 | MoE + MuonClip 优化器,智能体强化 |
| 特殊模式 | 混合推理(思考/非思考) | 专注于智能体任务(指令变体) |
DeepSeek V3.1 和 Kimi K2 都引入了各自的聊天模板,使得模型在实际应用中更易于控制和集成:
DeepSeek V3.1 使用特殊 token(
thinking/response),让开发者可以明确地在快速直接响应和深度推理之间切换,适用于需要细粒度控制成本和性能的场景;而 Kimi K2 采用标准的 OpenAI 风格messages格式,为产品和智能体提供简单、即插即用的集成方式。
DeepSeek V3.1(非思考与思考)
非思考前缀
You are DeepSeek V3.1.
用户:什么是 RLHF?
助手:response
思考前缀
You are DeepSeek V3.1.
用户:什么是 RLHF?
助手:thinking
Kimi K2(标准聊天 API)
messages = [
{"role": "system", "content": "你是 Kimi,一个 AI 助手。"},
{"role": "user", "content": "什么是 RLHF?"}
]
| 维度 | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| 提示风格 | 使用特殊 token thinking / response 的自定义格式 |
标准 OpenAI 聊天 API 格式 |
| 模式控制 | 明确区分 思考 与 非思考 模式 | 无明确模式;模型隐式决定 |
| 多轮对话 | 需要手动拼接 token 来构建上下文 | 只需在数组中追加消息 |
| 灵活性 | 高:开发者可以强制启用或禁用推理 | 中等:依赖于系统提示和参数 |
| 易用性 | 较复杂,需要严格的模板 | 简单,即插即用 |
DeepSeek V3.1 与 Kimi K2:基准测试
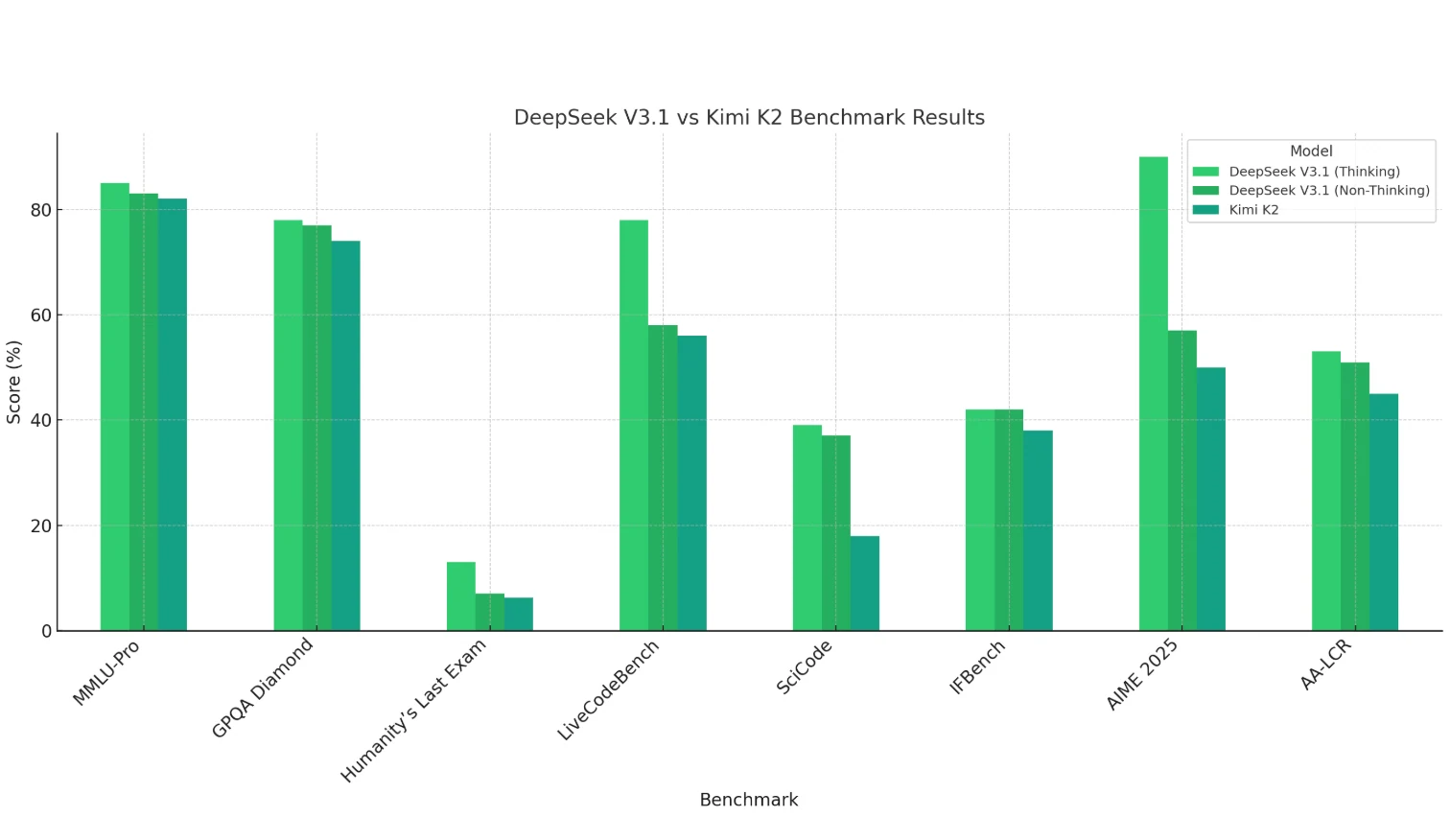
DeepSeek V3.1(思考模式) 在数学(AIME 2025)、编程(LiveCodeBench、SciCode)和长上下文推理(AA-LCR)方面表现出明显优势,展现了强大的推理和计算能力。
Kimi K2 整体表现稍弱——尤其是在编程和数学方面——但在知识型任务(MMLU、GPQA)中仍具竞争力。
**DeepSeek V3.1 的非思考模式 ** 得分通常略低于思考模式,但在大多数情况下仍能匹配或超越 Kimi K2。
结论:DeepSeek V3.1 更适合推理密集型及复杂任务,而 Kimi K2 更偏向通用知识场景。
DeepSeek V3.1 与 Kimi K2:速度
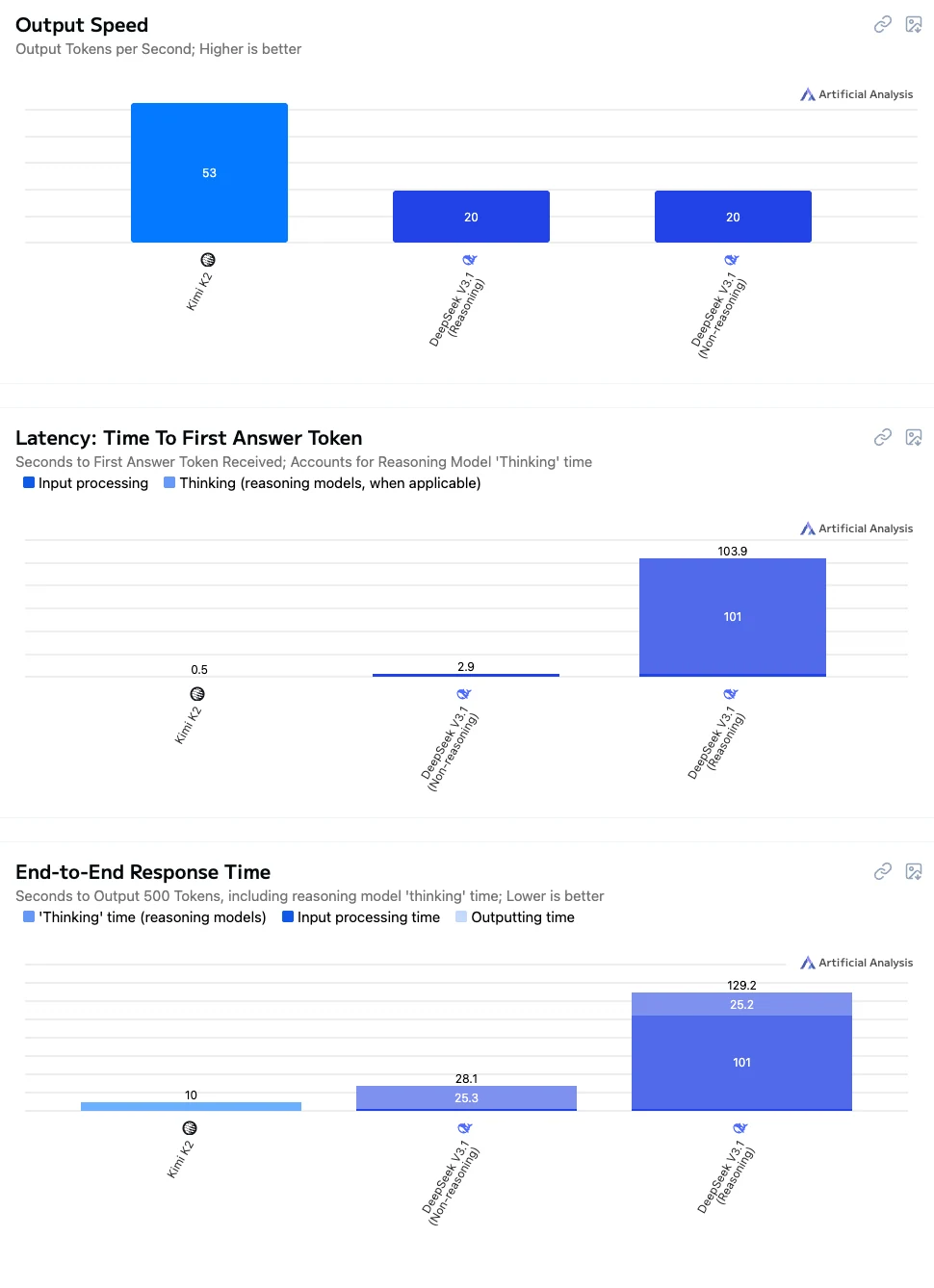
数据来源:Artificial Analysis
- Kimi K2:速度快,延迟低,整体交互流畅,非常适合实时对话、应用集成和教育场景。
- DeepSeek V3.1 非思考:响应速度中等,适合在无需长时间等待的情况下获得合理准确度的任务。
- DeepSeek V3.1 思考:性能最慢,但提供最强的推理和复杂问题解决能力,适用于高精度推理、复杂计算和研究型应用。
编程相关任务——DeepSeek V3.1 和 Kimi K2 哪个更好?
任务: 实现一个安全的算术表达式求值器。
规格说明
- 函数:
evaluate(expr: str) -> int - 支持:整数、
+ - * /、括号、空格、一元+/-(例如-3*(+2))。 - 除法为 向零截断取整(匹配 Python 的
int(a/b)行为,而非向下取整)。 - 必须检测无效输入并抛出
ValueError。 - 禁止使用
eval、ast.literal_eval或第三方解析器。
需要处理的边界情况
- 多个一元符号:
--5、+-3 - 空格:
" 1 + ( 2*3 ) " - 优先级与结合性:
2-3-4 == -5、14/3 == 4、-14/3 == -4 - 无效情况:
"(1+2"、"2**3"、"3//2"、"2(3)"、")1("
在免费 Playground 中使用 DeepSeek V3.1
在免费 Playground 中使用 Kimi K2
| 评估维度 | DeepSeek V3.1 | Kimi K2 |
|---|---|---|
| 正确性 | 实现了一个手写的分词器和递归下降解析器。处理多个一元运算符(--5、+-3)、优先级和结合性以及向零截断除法(手动修复)。潜在问题:除法处理过于复杂;错误信息较少。未包含内置测试框架。 |
使用基于正则表达式的词法分析器,明确定义了 token 类(PLUS、MINUS 等)。通过 int(a/b) 正确实现截断。在 __main__ 中提供了完整的测试套件,覆盖有效和无效情况。错误处理更优雅(带信息的 ValueError)。 |
| 代码质量 | 底层手动字符扫描。像“考试答案”式的解析器:全面但冗长且难以维护。未包含测试框架。 | 模块化更清晰(Lexer、Parser、evaluate)。由于使用正则表达式简化,更易阅读。提供测试,便于快速验证。 |
| 风格与可用性 | 擅长原始推理,从零开始构建所有内容。在需要细粒度解析控制时适用。 | 优化了开发者体验:简洁、经过测试、可投入生产。更适合立即集成。 |
| 结论 | 在推理边界情况和算法设计方面表现强劲。展示了从零构建解析器的能力,但在完善性和易用性上稍弱。 | 实现更简洁、清晰且适合生产。解析稍欠严谨,但高度可用。 |
| 总结 | 选择 DeepSeek V3.1 可确保更强的正确性和算法深度。 | 选择 Kimi K2 可获得开发者友好、可读性强且经过测试的代码。 |
1. 构建整体框架 → DeepSeek V3.1
- 优势:强大的推理能力、严谨的逻辑——非常适合搭建复杂系统的骨架。
- 最适合:
- 设计解释器/编译器、解析器或 DSL
- 实现核心算法和数据结构
- 勾勒完整的执行流程(类、方法、调用层次结构)
- **结果 :一个 ** 完整但略显冗长的初稿,主要逻辑已到位。
2. 完善细节和打磨代码 → Kimi K2
- 优势:简洁、模块化、对开发者友好——非常适合代码清理和生产就绪。
- 最适合:
- 将冗长的逻辑重写为更优雅的结构(例如用正则表达式替代手动扫描)
- 添加测试、错误处理、日志记录
- 改进命名、模块化和整体可读性
- **结果 :一个 ** 干净、可维护、可投入生产的实现。
DeepSeek V3.1 与 Kimi K2:系统要求
| 模型与配置 | VRAM 需求 | GPU 需求 |
|---|---|---|
| DeepSeek V3.1 (671B) | 1.5 TB VRAM | 8×H200 可支持 |
| Kimi K2 (量化版) | 250 GB 合计 | 1×24GB GPU |
| Kimi K2 (FP8) | 1 TB | 单台 8×H200 或 6×B200 集群 |
如何通过廉价稳定的 API 访问 DeepSeek V3.1 和 Kimi K2?
Novita AI 已正式推出 DeepSeek V3.1 和 Kimi K2 的 API,为开发者在高性能 AI 编程和推理任务中提供更多灵活性。这两个模型均已集成 Claude Code 支持,可直接用于高级编码工作流。
DeepSeek V3.1 指标
- 输入价格:每百万 token $0.55
- 输出价格:每百万 token $1.66
- 延迟:3.00 秒
- 吞吐量:48.28 TPS
Kimi K2 指标
- 输入价格:每百万 token $0.57
- 输出价格:每百万 token $2.30
- 延迟:1.30 秒
- 吞吐量:122.1 TPS
第一步:登录并访问模型库
登录您的账户,点击 模型库 按钮。

第二步:选择您的模型
浏览可用选项,选择适合您需求的模型。
第三步:开始免费试用
开始免费试用,探索所选模型的功能。
第四步:获取您的 API 密钥
为了通过 API 进行身份验证,我们将为您提供一个新的 API 密钥。进入“设置”页面,您可以按照图片指示复制 API 密钥。

第五步:安装 API
使用适合您编程语言的包管理器安装 API。
安装完成后,将必要的库导入您的开发环境。使用您的 API 密钥初始化 API,开始与 Novita AI LLM 交互。以下是 Python 用户使用聊天补全 API 的示例。
from openai import OpenAI
base_url = "https://api.novita.ai/openai"
api_key = "<您的 API 密钥>"
model = "deepseek/deepseek-v3.1"
client = OpenAI(
base_url=base_url,
api_key=api_key,
)
stream = True # 或 False
max_tokens = 1000
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": "你好!",
}
],
stream=stream,
extra_body={
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
总体而言,DeepSeek V3.1 在 推理密集型、数学计算和代码相关任务 ** 上表现出色,当准确性和逻辑深度至关重要时,它是一个强有力的选择。其思考模式将复杂问题解决能力推向极限,而非思考模式则在速度和质量之间提供了一个平衡点。Kimi K2 凭借更快的响应速度、更高的吞吐量和即插即用的 API,在 ** 通用知识任务、实时应用和无缝集成 方面表现出色。对于开发者而言,混合工作流可能非常高效:使用 DeepSeek V3.1 来设计和推理复杂框架,然后依靠 Kimi K2 来完善、测试并将实现方案推向生产环境。
常见问题解答
哪个模型更适合编程任务?
DeepSeek V3.1(思考模式)在算法推理和边界情况处理方面更胜一筹,非常适合构建框架和复杂解析器。Kimi K2 能生成更清晰、更模块化的代码,并内置测试,对开发者友好,便于代码完善和集成。
两个模型在性能速度上有什么不同?
Kimi K2 明显更快,延迟更低,吞吐量更高,适合实时对话和教育场景。DeepSeek V3.1 较慢,尤其是在思考模式下,但在研究或计算密集型用例中能提供更强的推理和准确性。
我应该选择哪个进行通用用途?
如果您的首要需求是 **稳健的推理和编程准确性 ,请选择 DeepSeek V3.1。如果您需要 ** 速度、流畅集成和高吞吐量,请选择 Kimi K2。许多团队受益于将两者结合:用 DeepSeek 进行框架设计,用 Kimi 进行代码完善和部署。
Novita AI 是一个全能的云平台,为您的 AI 雄心赋能。集成的 API、无服务器、GPU 实例——您所需的成本效益工具。无需基础设施,免费开始,让您的 AI 愿景成为现实。



