

O DeepSeek-OCR oferece compressão de texto de 10× com 97% de precisão ao tratar imagens como armazenamento compactado de texto. Em vez de processar 1.000 tokens de texto individualmente, ele os processa como uma única imagem usando apenas 100 tokens de visão, reduzindo custos em até 85%.
Agora disponível na Novita AI, o DeepSeek-OCR processa mais de 200.000 páginas por dia por GPU, suporta 100 idiomas e oferece cinco modos de resolução (de 64 a mais de 400 tokens). Ele vai além do OCR tradicional para analisar gráficos em dados estruturados, reconhecer fórmulas químicas, extrair figuras geométricas e permitir gerenciamento inovador de memória para conversas longas.
Experimente agora no Playground da Novita AI →
O que é o DeepSeek-OCR?
O DeepSeek-OCR é um modelo de linguagem visual que trata imagens como armazenamento compactado de texto. Em vez de processar um documento com 1.000 tokens de texto individualmente (o que é computacionalmente caro), o modelo o processa como uma única imagem usando apenas 100 tokens de visão, uma redução de 10× nos custos de processamento.
Arquitetura Principal
O modelo consiste em dois componentes principais:
DeepEncoder (~380M de parâmetros): Um codificador de visão especializado que processa imagens de documento de forma eficiente, usando uma arquitetura serial exclusiva que combina atenção de janela (SAM) e atenção global (CLIP) com uma camada de compressão de 16× entre elas.
Decodificador DeepSeek3B-MoE (570M de parâmetros ativos): Um modelo de linguagem compacto de mistura de especialistas que converte informações visuais compactadas de volta para texto com precisão notável.
Essa arquitetura permite uma eficiência sem precedentes no processamento de documentos, sendo ideal para empresas que lidam com grandes volumes de documentos ou aplicativos que exigem compreensão de contexto longo.
Por que a Compressão Óptica é Importante
O Problema Tradicional
O processamento de texto tradicional em modelos de IA escala quadraticamente: dobrar o comprimento do seu documento pode quadruplicar seus custos. Para empresas que processam milhares de documentos diariamente, isso se torna proibitivamente caro.
A Solução DeepSeek-OCR
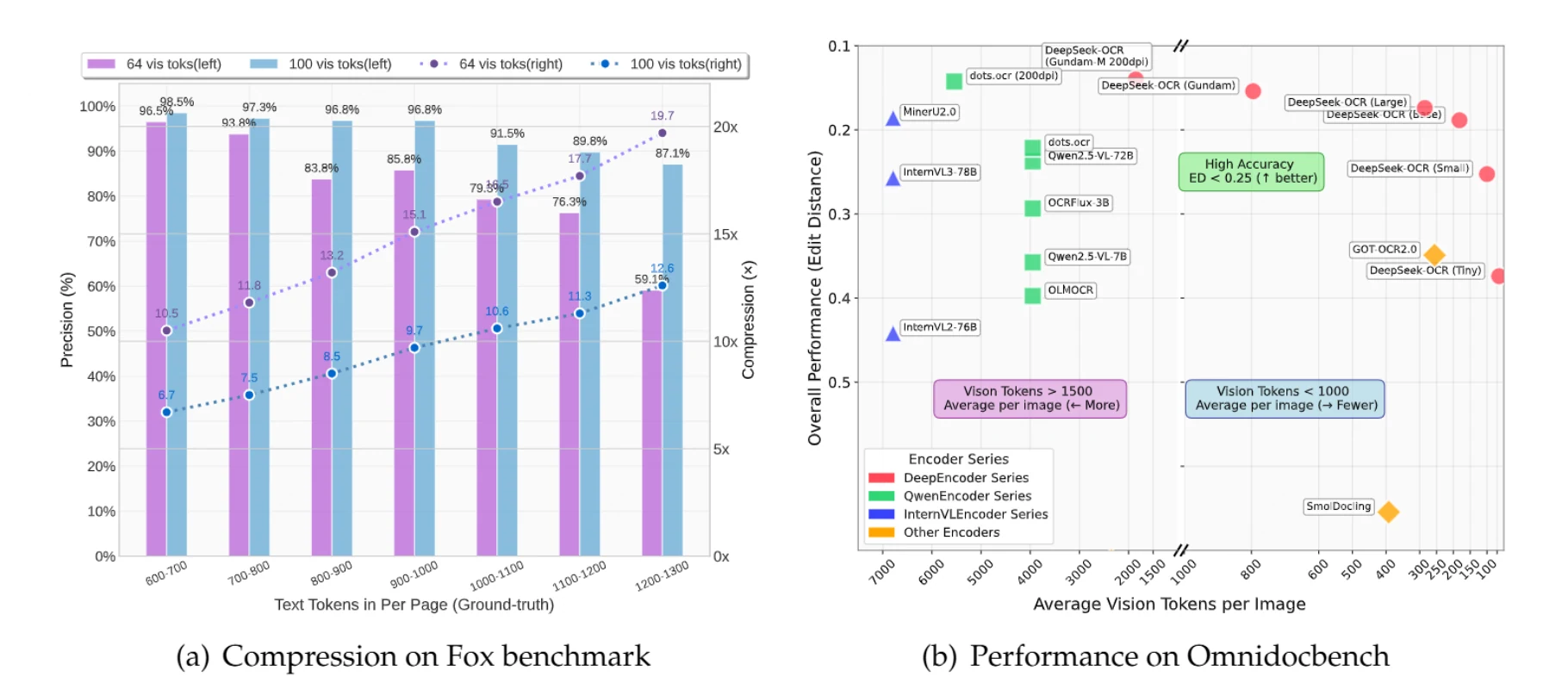
Documentos com até 1.000 tokens de texto podem ser compactados 10× com 97% de precisão. Mesmo com compressão de 20×, a precisão permanece em torno de 60% — geralmente suficiente para muitas aplicações.
Exemplo do Mundo Real:
Um documento contendo 900 tokens de texto tradicionalmente requer 900 tokens para processamento. Com o DeepSeek-OCR usando o modo Pequeno (100 tokens de visão), você obtém compressão de 9,7× com 96,8% de precisão. Para documentos com 1.100 tokens de texto, você obtém compressão de 10,6× com 91,5% de precisão.
Impacto nos Negócios
Custos de API Reduzidos: Até 10× menos tokens processados para documentos típicos significa economias de custo dramáticas: uma empresa que processa 1 milhão de páginas por mês pode economizar mais de $50.000 por ano.
Processamento Mais Rápido: Menos tokens se traduzem diretamente em tempos de resposta mais rápidos, melhorando a experiência do usuário e permitindo aplicativos em tempo real.
Melhor Escalabilidade: Lide com 10× mais documentos com o mesmo investimento em infraestrutura, tornando o crescimento mais previsível e acessível.
Eficiência de Memória: Armazene o histórico de conversas como imagens compactadas, permitindo aplicativos de contexto ultra longo sem requisitos exponenciais de memória.
Desempenho e Benchmarking
Resultados Abrangentes do OmniDocBench
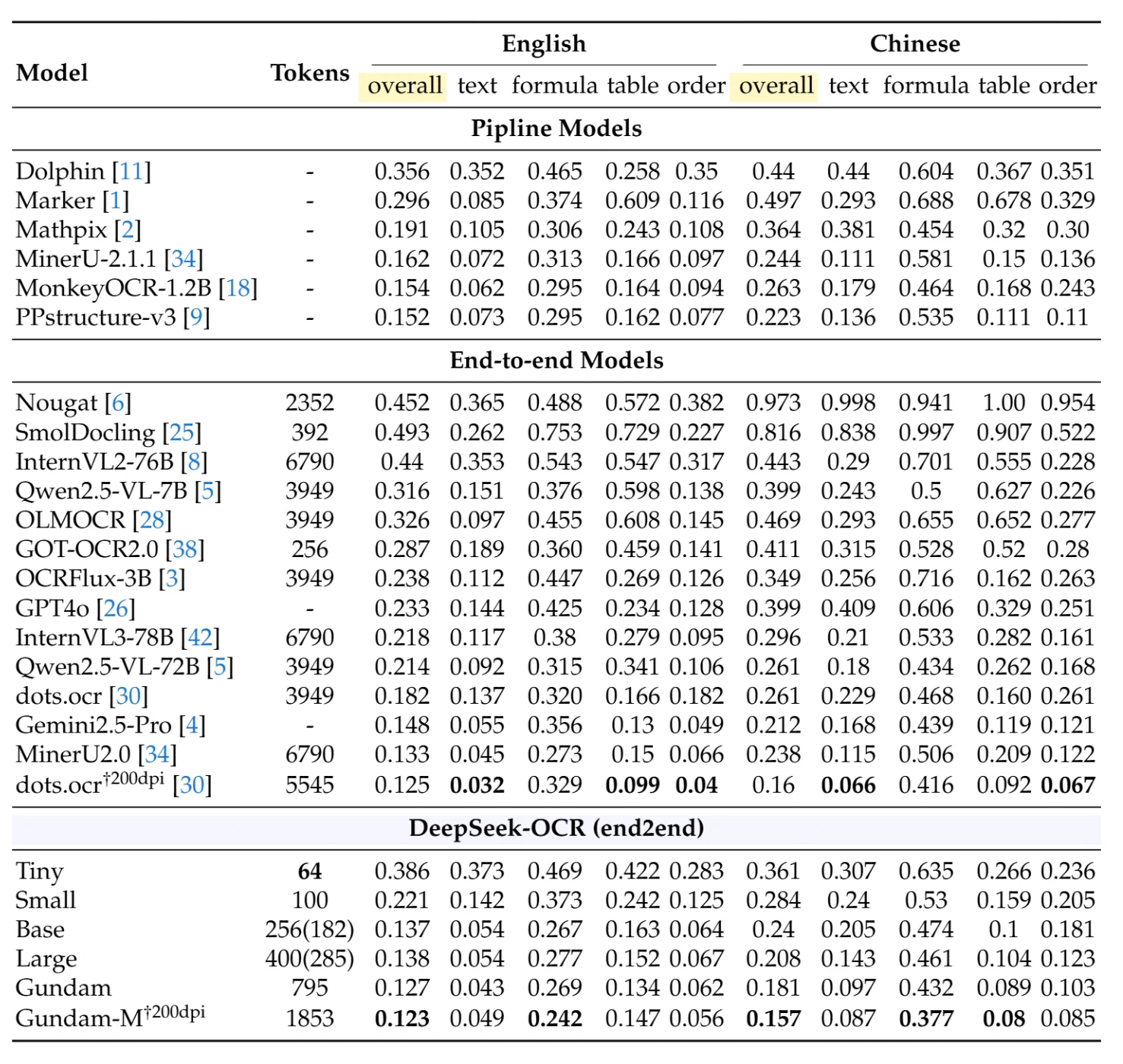
No OmniDocBench, um benchmark abrangente de análise de documentos, o DeepSeek-OCR alcança desempenho excepcional com uso mínimo de recursos. A tabela abaixo mostra comparações detalhadas entre diferentes tipos de documentos e idiomas (distância de edição - menor é melhor):
Destaques Principais:
Modelos de Pipeline (abordagens tradicionais de múltiplas etapas): O modelo de pipeline com melhor desempenho, o PPstructure-v3, alcança 0,152 no geral em inglês e 0,223 em chinês, mas requer infraestrutura complexa de múltiplos modelos.
Modelos de Ponta a Ponta (abordagens de modelo único): Entre os concorrentes, o MinerU2.0 usando 6.790 tokens alcança 0,133 em inglês e 0,238 em chinês. O Qwen2.5-VL-72B com 3.949 tokens obtém 0,214 em inglês e 0,261 em chinês.
Desempenho do DeepSeek-OCR:
- Modo Pequeno (100 tokens): 0,221 no geral em inglês, 0,284 no geral em chinês
- Modo Base (256 tokens): 0,137 no geral em inglês, 0,240 no geral em chinês
- Modo Gundam (795 tokens): 0,127 no geral em inglês, 0,181 no geral em chinês
- Gundam-M a 200dpi (1.853 tokens): 0,123 no geral em inglês, 0,157 no geral em chinês - alcançando resultados de ponta
Conquista Notável: O modo Base do DeepSeek-OCR com apenas 256 tokens supera modelos que usam de 15 a 26× mais tokens. O modo Gundam-M alcança o melhor desempenho geral entre todos os modelos de ponta a ponta, enquanto ainda usa significativamente menos tokens que as abordagens tradicionais.
Desempenho por Categoria
Reconhecimento de Texto: O DeepSeek-OCR (Gundam-M) alcança 0,049 em texto em inglês e 0,087 em texto em chinês, superando até o Gemini2.5-Pro.
Reconhecimento de Fórmulas: Com 0,242 em fórmulas em inglês e 0,377 em fórmulas em chinês, o DeepSeek-OCR demonstra forte capacidade em conteúdo matemático.
Extração de Tabelas: Pontuações de 0,147 em tabelas em inglês e 0,08 em tabelas em chinês mostram extração robusta de dados estruturados.
Capacidades de Produção
Velocidade de Processamento: Uma única GPU A100-40G pode processar mais de 200.000 páginas por dia. Escale para 20 nós (160 GPUs) e você terá 33 milhões de páginas por dia — suficiente para as cargas de trabalho empresariais mais exigentes.
Eficiência de Custo: Para uma empresa que processa 1 milhão de páginas de documento por mês, a diferença é gritante. Modelos tradicionais que exigem 6.000 tokens por página consomem 6 bilhões de tokens no total. O DeepSeek-OCR a 800 tokens por página usa apenas 800 milhões de tokens — uma redução de 87% no uso de tokens e custos associados.
Principais Recursos e Capacidades
1. Suporte a Múltiplos Idiomas
O DeepSeek-OCR suporta quase 100 idiomas, de idiomas principais mundiais (inglês, chinês, espanhol, árabe, hindi) a scripts especializados (tailandês, hebraico, cirílico). Isso elimina a necessidade de serviços de OCR específicos para cada idioma e simplifica operações internacionais.
2. Compreensão Avançada de Documentos
O modelo reconhece muito mais do que apenas texto. Ele analisa gráficos em dados estruturados, extrai fórmulas matemáticas com formatação LaTeX, identifica figuras geométricas com saída SVG e mantém estruturas de tabela, incluindo células mescladas e formatação complexa.
3. Formatos de Saída Flexíveis
Escolha entre extração de texto puro (mais rápida), markdown com formatação preservada, HTML para integração na web ou JSON estruturado para processamento programático. O modo de aterramento (grounding) preserva relações espaciais, garantindo que seus dados extraídos mantenham a estrutura do documento original.
4. Compressão Óptica para Contexto Longo
Armazene o histórico de conversas como imagens compactadas em vez de tokens de texto. Uma conversa de 10 turnos que tradicionalmente consumiria 10.000 tokens pode ser compactada para 1.000 tokens de visão, permitindo aplicativos com janelas de contexto ultra longo a custos sustentáveis.
O Impacto: Aplicativos de chat podem manter o contexto por centenas de turnos de conversa sem aumentos exponenciais de custo, permitindo interações de IA verdadeiramente longas.
Começando na Novita AI
Entendendo os Modos de Resolução
A Novita AI fornece o DeepSeek-OCR com cinco modos de resolução projetados para equilibrar desempenho, velocidade e custo para diferentes casos de uso.
Modos de Resolução Nativos:
Modo Minúsculo (512×512, 64 tokens): Otimizado para documentos simples onde a velocidade máxima é a prioridade. Perfeito para recibos, formulários simples ou tarefas rápidas de extração de texto.
Modo Pequeno (640×640, 100 tokens): O ponto ideal para a maioria das aplicações. Oferece o melhor equilíbrio entre precisão, velocidade e custo. Ideal para documentos empresariais padrão, faturas e relatórios.
Modo Base (1024×1024, 256 tokens): Lida com layouts complexos com proporções preservadas usando preenchimento. Recomendado para contratos, relatórios detalhados e documentos onde o layout é importante.
Modo Grande (1280×1280, 400 tokens): Qualidade máxima para documentos detalhados de alta resolução. Melhor para artigos de pesquisa, documentos técnicos com fórmulas e requisitos de qualidade premium.
Modo de Resolução Dinâmica:
Modo Gundam (n×640×640 + 1×1024×1024, tokens variáveis): Ladrilhamento adaptativo para documentos de ultra-alta resolução. Divide automaticamente imagens grandes em 2 a 9 visualizações locais de 640×640 mais uma visualização global de 1024×1024. Essencial para jornais, revistas e layouts complexos de múltiplas colunas. Para imagens menores que 640×640, ele degrada automaticamente para o modo Base.
Acessando a API do DeepSeek-OCR
A Novita AI fornece uma API REST simples para o DeepSeek-OCR. Para começar, inscreva-se em uma conta da Novita AI e obtenha sua chave de API. O endpoint da API aceita URLs de imagem ou imagens codificadas em base64, juntamente com parâmetros de configuração como modo de resolução, preferência de idioma e formato de saída.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="<Your API Key>",
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
},
{
"type": "text",
"text": "<|grounding|>OCR this image."
}
]
}
],
stream=False,
max_tokens=4096
)
content = response.choices[0].message.content
print(content)
Padrões de Uso Básicos
Para extração de texto simples onde a formatação não importa, use o modo “Free OCR”. Para análise de documentos estruturados que preserva layout, tabelas e formatação, use o modo “grounding” com saída markdown. Para análise avançada de gráficos, fórmulas ou figuras geométricas, use o prompt “Parse the figure”.
Guia de Resolução
Escolhendo o Modo Correto
Para Faturas, Recibos e Formulários Simples: O modo Pequeno (100 tokens) é a melhor escolha. É rápido, econômico e fornece precisão suficiente para extração de dados estruturados. Isso cobre a maioria das necessidades de processamento de documentos empresariais rotineiros.
Para Documentos Empresariais, Relatórios e Contratos: O modo Base (256 tokens) lida bem com layouts complexos e preserva as proporções com preenchimento. É o equilíbrio certo quando a estrutura e a formatação do documento são importantes.
Para Artigos de Pesquisa e Documentos Técnicos: O modo Grande (400 tokens) fornece a precisão necessária para texto denso, fórmulas matemáticas e diagramas técnicos. A contagem de tokens mais alta é justificada pelos requisitos de precisão.
Para Jornais, Revistas e Layouts de Múltiplas Colunas: O modo Gundam (tokens variáveis) é essencial. Seu ladrilhamento adaptativo lida com resolução ultra-alta e layouts complexos de múltiplas colunas que seriam ilegíveis em modos de resolução fixa. Embora use mais tokens, ainda é muito mais eficiente que as abordagens tradicionais.
Insights de Desempenho por Tipo de Documento
Com base nos testes abrangentes do OmniDocBench:
Slides e Documentos Simples: Mesmo o modo Minúsculo (64 tokens) tem um desempenho notável com distância de edição de 0,116 em slides, enquanto o modo Pequeno oferece o melhor custo-benefício. Isso acontece porque os slides de apresentação geralmente têm layouts claros e texto limitado por página.
Livros e Documentos Padrão: O modo Pequeno (100 tokens) oferece excelente custo-benefício com distância de edição de 0,085 para livros. A maioria dos livros contém de 600 a 1.000 tokens de texto por página, bem dentro do ponto ideal de compressão de 10×.
Artigos Acadêmicos: O modo Grande ou o modo Gundam são recomendados, com o Gundam alcançando distância de edição de 0,039 em artigos acadêmicos — superando modelos que usam de 5 a 8× mais tokens.
Jornais: O modo Gundam é essencial, alcançando distância de edição de 0,122 comparado a 0,940 para o modo Minúsculo. Jornais contêm de 4.000 a 5.000 tokens de texto por página com layouts complexos de múltiplas colunas que exigem a abordagem de ladrilhamento adaptativo.
Documentos com Muitas Fórmulas: Para documentos com fórmulas matemáticas, o modo Gundam-M alcança o melhor desempenho com distância de edição de 0,242 em fórmulas em inglês, sendo competitivo com modelos grandes especializados.
Entendendo o Modo Gundam em Detalhe
O modo Gundam funciona criando múltiplas visualizações locais (2 a 9 ladrilhos de 640×640) que capturam regiões detalhadas, mais uma visualização global (1024×1024) que mantém o contexto geral. A contagem total de tokens é calculada como n×100 + 256, onde n é o número de ladrilhos.
Quando usar o Modo Gundam: Use-o para imagens maiores que 1280 pixels em qualquer dimensão, documentos com layouts de múltiplas colunas, conteúdo com mais de 4.000 tokens de texto ou infográficos complexos que precisam de detalhe e contexto.
Exemplo do mundo real: Uma página pequena de jornal pode usar 3 ladrilhos (556 tokens no total), enquanto uma página grande de jornal usa 6 ladrilhos (856 tokens). Compare isso com abordagens tradicionais que exigem mais de 6.000 tokens — você ainda está alcançando compressão de 7 a 10× mesmo nos documentos mais complexos.
Conclusão
O DeepSeek-OCR na Novita AI alcança compressão de 10× com 97% de precisão, reduzindo os custos de processamento de documentos em até 85%, enquanto suporta 100 idiomas e processa mais de 200.000 páginas por GPU por dia.
Os resultados falam por si: Empresas que processam 100.000 documentos mensalmente economizam mais de $50.000 por ano. As velocidades de processamento melhoram de 5 a 10×. A infraestrutura escala linearmente em vez de exponencialmente.
Pronto para transformar seu processamento de documentos?
Comece Gratuitamente no Playground →
Teste o DeepSeek-OCR com seus próprios documentos em minutos. Não é necessário cartão de crédito. Escolha entre cinco modos de resolução, processe documentos em 100 idiomas e experimente a compressão de 10× na prática.
A Novita AI é uma plataforma de nuvem de IA líder que fornece aos desenvolvedores APIs fáceis de usar e infraestrutura de GPU acessível e confiável para construir e escalar aplicativos de IA.



