

DeepSeek-OCR delivers 10× text compression with 97% accuracy by treating images as compressed storage for text. Instead of processing 1,000 text tokens individually, it processes them as a single image using just 100 vision tokens—cutting costs by up to 85%.
Now available on Novita AI, DeepSeek-OCR processes 200,000+ pages per day per GPU, supports 100 languages, and offers five resolution modes (64 to 400+ tokens). It goes beyond traditional OCR to parse charts into structured data, recognize chemical formulas, extract geometric figures, and enable innovative memory management for long conversations.
Try it now in the Novita AI Playground →
What is DeepSeek-OCR?
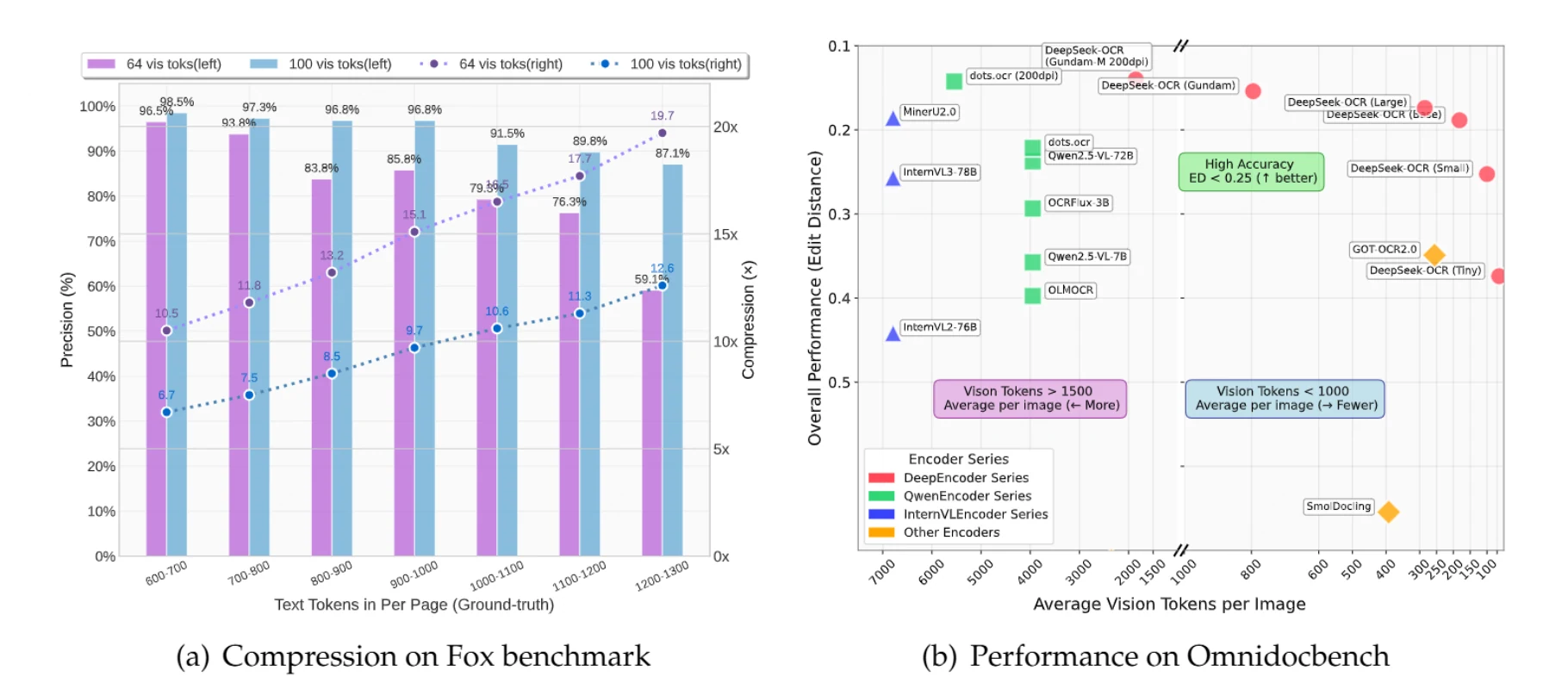
DeepSeek-OCR is a vision-language model that treats images as compressed storage for text. Instead of processing a document with 1,000 text tokens individually (which is computationally expensive), the model processes it as a single image using only 100 vision tokens—a 10× reduction in processing costs.
Core Architecture
The model consists of two key components:
DeepEncoder (~380M parameters): A specialized vision encoder that efficiently processes document images using a unique serial architecture combining window attention (SAM) and global attention (CLIP) with a 16× compression layer between them.
DeepSeek3B-MoE Decoder (570M active parameters): A compact mixture-of-experts language model that converts compressed visual information back to text with remarkable accuracy.
This architecture enables unprecedented efficiency in document processing, making it ideal for businesses handling large volumes of documents or applications requiring long-context understanding.
Why Optical Compression Matters
The Traditional Problem
Traditional text processing in AI models scales quadratically—doubling your document length can quadruple your costs. For businesses processing thousands of documents daily, this becomes prohibitively expensive.
The DeepSeek-OCR Solution
Documents with up to 1,000 text tokens can be compressed 10× with 97% accuracy. Even at 20× compression, accuracy remains around 60%—often sufficient for many applications.
Real-World Example:
A document containing 900 text tokens traditionally requires 900 tokens to process. With DeepSeek-OCR using Small mode (100 vision tokens), you achieve 9.7× compression at 96.8% accuracy. For documents with 1,100 text tokens, you get 10.6× compression at 91.5% accuracy.
Business Impact
Reduced API Costs: Up to 10× fewer tokens processed for typical documents means dramatic cost savings—a business processing 1 million pages monthly could save $50,000+ annually.
Faster Processing: Fewer tokens translate directly to quicker response times, improving user experience and enabling real-time applications.
Better Scalability: Handle 10× more documents with the same infrastructure investment, making growth more predictable and affordable.
Memory Efficiency: Store conversation history as compressed images, enabling ultra-long context applications without exponential memory requirements.
Performance & Benchmarks
Comprehensive OmniDocBench Results
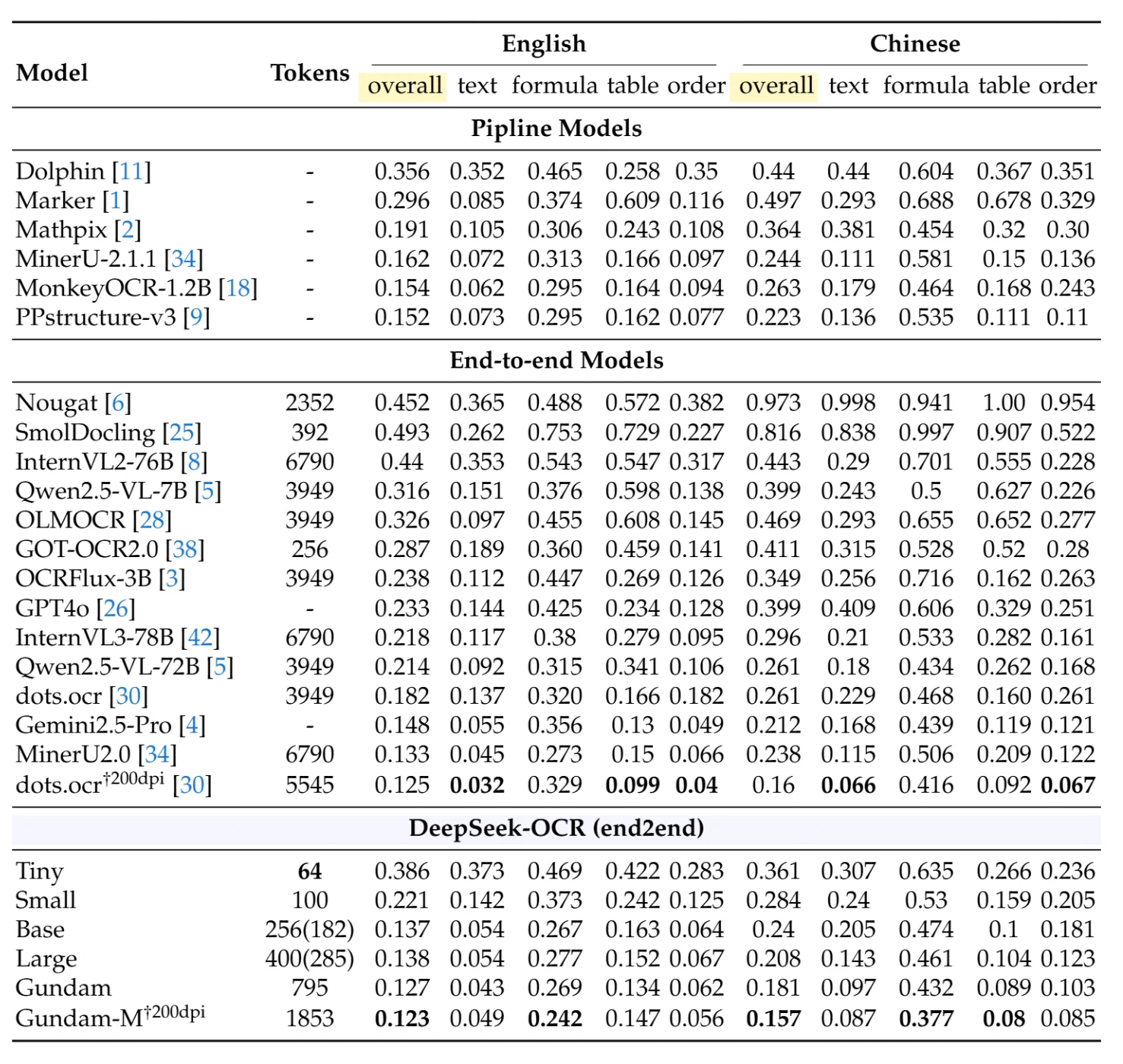
On OmniDocBench, a comprehensive document parsing benchmark, DeepSeek-OCR achieves exceptional performance with minimal resource usage. The table below shows detailed comparisons across different document types and languages (edit distance - lower is better):
Key Highlights:
Pipeline Models (traditional multi-stage approaches): The best performing pipeline model, PPstructure-v3, achieves 0.152 overall on English and 0.223 on Chinese, but requires complex multi-model infrastructure.
End-to-end Models (single-model approaches): Among competitors, MinerU2.0 using 6,790 tokens achieves 0.133 on English and 0.238 on Chinese. Qwen2.5-VL-72B with 3,949 tokens scores 0.214 on English and 0.261 on Chinese.
DeepSeek-OCR Performance:
- Small mode (100 tokens): 0.221 English overall, 0.284 Chinese overall
- Base mode (256 tokens): 0.137 English overall, 0.240 Chinese overall
- Gundam mode (795 tokens): 0.127 English overall, 0.181 Chinese overall
- Gundam-M at 200dpi (1,853 tokens): 0.123 English overall, 0.157 Chinese overall - achieving state-of-the-art results
Remarkable Achievement: DeepSeek-OCR’s Base mode with only 256 tokens outperforms models using 15-26× more tokens. The Gundam-M mode achieves the best overall performance among all end-to-end models while still using significantly fewer tokens than traditional approaches.
Category-Specific Performance
Text Recognition: DeepSeek-OCR (Gundam-M) achieves 0.049 on English text and 0.087 on Chinese text, outperforming even Gemini2.5-Pro.
Formula Recognition: With 0.242 on English formulas and 0.377 on Chinese formulas, DeepSeek-OCR demonstrates strong capability in mathematical content.
Table Extraction: Scores of 0.147 on English tables and 0.08 on Chinese tables show robust structured data extraction.
Production Capabilities
Processing Speed: A single A100-40G GPU can process over 200,000 pages per day. Scale to 20 nodes (160 GPUs) and you’re looking at 33 million pages per day—enough for the most demanding enterprise workloads.
Cost Efficiency: For a business processing 1 million document pages per month, the difference is stark. Traditional models requiring 6,000 tokens per page consume 6 billion tokens total. DeepSeek-OCR at 800 tokens per page uses only 800 million tokens—an 87% reduction in token usage and associated costs.
Key Features & Capabilities
1. Multi-Language Support
DeepSeek-OCR supports nearly 100 languages, from major world languages (English, Chinese, Spanish, Arabic, Hindi) to specialized scripts (Thai, Hebrew, Cyrillic). This eliminates the need for language-specific OCR services and simplifies international operations.
2. Advanced Document Understanding
The model recognizes far more than just text. It parses charts into structured data, extracts mathematical formulas with LaTeX formatting, identifies geometric figures with SVG output, and maintains table structures including merged cells and complex formatting.
3. Flexible Output Formats
Choose between pure text extraction (fastest), markdown with preserved formatting, HTML for web integration, or structured JSON for programmatic processing. The grounding mode preserves spatial relationships, ensuring your extracted data maintains the original document’s structure.
4. Optical Compression for Long Context
Store conversation history as compressed images instead of text tokens. A 10-turn conversation that would traditionally consume 10,000 tokens can be compressed to 1,000 vision tokens, enabling applications with ultra-long context windows at sustainable costs.
The Impact: Chat applications can maintain context over hundreds of conversation turns without exponential cost increases, enabling truly long-form AI interactions.
Getting Started on Novita AI
Understanding Resolution Modes
Novita AI provides DeepSeek-OCR with five resolution modes designed to balance performance, speed, and cost for different use cases.
Native Resolution Modes:
Tiny Mode (512×512, 64 tokens): Optimized for simple documents where maximum speed is priority. Perfect for receipts, simple forms, or quick text extraction tasks.
Small Mode (640×640, 100 tokens): The sweet spot for most applications. Offers the best balance of accuracy, speed, and cost. Ideal for standard business documents, invoices, and reports.
Base Mode (1024×1024, 256 tokens): Handles complex layouts with preserved aspect ratios using padding. Recommended for contracts, detailed reports, and documents where layout matters.
Large Mode (1280×1280, 400 tokens): Maximum quality for high-resolution detailed documents. Best for research papers, technical documents with formulas, and premium quality requirements.
Dynamic Resolution Mode:
Gundam Mode (n×640×640 + 1×1024×1024, variable tokens): Adaptive tiling for ultra-high resolution documents. Automatically splits large images into 2-9 local views at 640×640 plus one global view at 1024×1024. Essential for newspapers, magazines, and complex multi-column layouts. For images smaller than 640×640, it automatically degrades to Base mode.
Accessing the DeepSeek-OCR API
Novita AI provides a simple REST API for DeepSeek-OCR. To get started, sign up for a Novita AI account and obtain your API key. The API endpoint accepts image URLs or base64-encoded images along with configuration parameters like resolution mode, language preference, and output format.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="<Your API Key>",
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
},
{
"type": "text",
"text": "<|grounding|>OCR this image."
}
]
}
],
stream=False,
max_tokens=4096
)
content = response.choices[0].message.content
print(content)Basic Usage Patterns
For simple text extraction where formatting doesn’t matter, use the “Free OCR” mode. For structured document parsing that preserves layout, tables, and formatting, use the “grounding” mode with markdown output. For advanced parsing of charts, formulas, or geometric figures, use the “Parse the figure” prompt.
Resolution Guide
Choosing the Right Mode
For Invoices, Receipts, and Simple Forms: Small mode (100 tokens) is your best choice. It’s fast, cost-effective, and provides sufficient accuracy for structured data extraction. This covers most routine business document processing needs.
For Business Documents, Reports, and Contracts: Base mode (256 tokens) handles complex layouts well and preserves aspect ratios with padding. It’s the right balance when document structure and formatting are important.
For Research Papers and Technical Documents: Large mode (400 tokens) provides the accuracy needed for dense text, mathematical formulas, and technical diagrams. The higher token count is justified by the precision requirements.
For Newspapers, Magazines, and Multi-Column Layouts: Gundam mode (variable tokens) is essential. Its adaptive tiling handles ultra-high resolution and complex multi-column layouts that would be garbled in fixed-resolution modes. While it uses more tokens, it’s still far more efficient than traditional approaches.
Performance Insights by Document Type
Based on the comprehensive OmniDocBench testing:
Slides and Simple Documents: Even Tiny mode (64 tokens) performs remarkably well with 0.116 edit distance on slides, while Small mode offers optimal value. This is because presentation slides typically have clear layouts and limited text per page.
Books and Standard Documents: Small mode (100 tokens) offers excellent value at 0.085 edit distance for books. Most books contain 600-1,000 text tokens per page, well within the 10× compression sweet spot.
Academic Papers: Large mode or Gundam mode are recommended, with Gundam achieving 0.039 edit distance on academic papers—outperforming models using 5-8× more tokens.
Newspapers: Gundam mode is essential, achieving 0.122 edit distance compared to 0.940 for Tiny mode. Newspapers contain 4,000-5,000 text tokens per page with complex multi-column layouts that require the adaptive tiling approach.
Formula-Heavy Documents: For documents with mathematical formulas, Gundam-M mode achieves the best performance with 0.242 edit distance on English formulas, competitive with specialized large models.
Understanding Gundam Mode in Detail
Gundam mode works by creating multiple local views (2-9 tiles at 640×640) that capture detailed regions, plus one global view (1024×1024) that maintains overall context. The total token count is calculated as n×100 + 256, where n is the number of tiles.
When to use Gundam Mode: Use it for images larger than 1280 pixels in any dimension, documents with multi-column layouts, content with 4,000+ text tokens, or complex infographics that need both detail and context.
Real-world example: A small newspaper page might use 3 tiles (556 tokens total), while a large newspaper page uses 6 tiles (856 tokens). Compare this to traditional approaches requiring 6,000+ tokens—you’re still achieving 7-10× compression even on the most complex documents.
Conclusion
DeepSeek-OCR on Novita AI achieves 10× compression with 97% accuracy, cutting document processing costs by up to 85% while supporting 100 languages and processing 200,000+ pages per GPU per day.
The results speak for themselves: Companies processing 100,000 documents monthly save $50,000+ annually. Processing speeds improve 5-10×. Infrastructure scales linearly instead of exponentially.
Ready to transform your document processing?
Start Free in the Playground →
Test DeepSeek-OCR with your own documents in minutes. No credit card required. Choose from five resolution modes, process documents in 100 languages, and experience 10× compression firsthand.
Novita AI is a leading AI cloud platform that provides developers with easy-to-use APIs and affordable, reliable GPU infrastructure for building and scaling AI applications.



