

DeepSeek-OCR erreicht 10-fache Textkomprimierung bei 97 % Genauigkeit, indem es Bilder als komprimierten Speicher für Text nutzt. Statt 1.000 Text-Token einzeln zu verarbeiten, werden diese als einzelnes Bild mit nur 100 Vision-Token verarbeitet – das senkt die Kosten um bis zu 85 %.
Jetzt verfügbar auf Novita AI verarbeitet DeepSeek-OCR über 200.000 Seiten pro Tag und GPU, unterstützt 100 Sprachen und bietet fünf Auflösungsmodi (64 bis 400+ Token). Es geht über herkömmliche OCR hinaus, um Diagramme in strukturierte Daten zu parsen, chemische Formeln zu erkennen, geometrische Figuren zu extrahieren und innovatives Speichermanagement für lange Unterhaltungen zu ermöglichen.
Jetzt im Novita AI Playground ausprobieren →
Was ist DeepSeek-OCR?
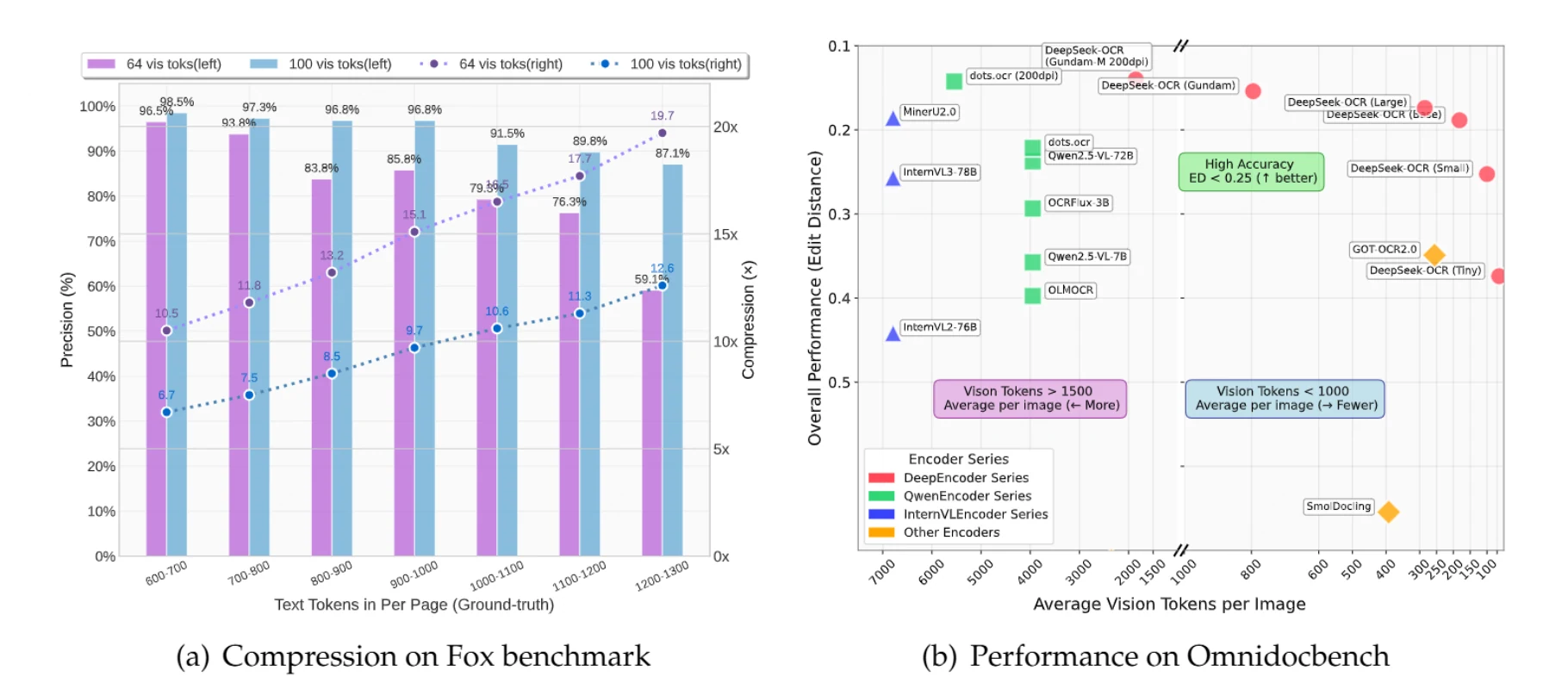
DeepSeek-OCR ist ein Vision-Language-Modell, das Bilder als komprimierten Speicher für Text nutzt. Statt ein Dokument mit 1.000 Text-Token einzeln zu verarbeiten (was rechenintensiv ist), verarbeitet das Modell es als einzelnes Bild mit nur 100 Vision-Token – eine 10-fache Reduzierung der Verarbeitungskosten.
Kernarchitektur
Das Modell besteht aus zwei Schlüsselkomponenten:
DeepEncoder (~380M Parameter): Ein spezialisierter Vision-Encoder, der Dokumentenbilder effizient mithilfe einer einzigartigen seriellen Architektur verarbeitet, die Fenster-Attention (SAM) und globale Attention (CLIP) mit einer 16-fachen Komprimierungsschicht dazwischen kombiniert.
DeepSeek3B-MoE Decoder (570M aktive Parameter): Ein kompaktes Mixture-of-Experts-Sprachmodell, das komprimierte visuelle Informationen mit bemerkenswerter Genauigkeit wieder in Text umwandelt.
Diese Architektur ermöglicht eine beispiellose Effizienz bei der Dokumentenverarbeitung und ist ideal für Unternehmen, die große Mengen an Dokumenten verarbeiten, oder Anwendungen, die ein Langkontext-Verständnis erfordern.
Warum optische Komprimierung wichtig ist
Das herkömmliche Problem
Die herkömmliche Textverarbeitung in KI-Modellen skaliert quadratisch – eine Verdopplung der Dokumentlänge kann die Kosten vervierfachen. Für Unternehmen, die täglich Tausende von Dokumenten verarbeiten, wird dies schnell unerschwinglich teuer.
Die DeepSeek-OCR-Lösung
Dokumente mit bis zu 1.000 Text-Token können mit 97 % Genauigkeit 10-fach komprimiert werden. Selbst bei 20-facher Komprimierung bleibt die Genauigkeit bei etwa 60 % – was für viele Anwendungen oft ausreicht.
Praktisches Beispiel:
Ein Dokument mit 900 Text-Token erfordert bei herkömmlicher Verarbeitung 900 Token für die Verarbeitung. Mit DeepSeek-OCR im Small-Modus (100 Vision-Token) erreichen Sie eine 9,7-fache Komprimierung bei 96,8 % Genauigkeit. Bei Dokumenten mit 1.100 Text-Token erhalten Sie eine 10,6-fache Komprimierung bei 91,5 % Genauigkeit.
Geschäftliche Auswirkungen
Reduzierte API-Kosten: Bis zu 10-fach weniger verarbeitete Token für typische Dokumente bedeuten dramatische Kosteneinsparungen – ein Unternehmen, das monatlich 1 Million Seiten verarbeitet, kann jährlich über 50.000 $ sparen.
Schnellere Verarbeitung: Weniger Token führen direkt zu kürzeren Antwortzeiten, verbessern die Benutzererfahrung und ermöglichen Echtzeitanwendungen.
Bessere Skalierbarkeit: Verarbeiten Sie 10-fach mehr Dokumente mit der gleichen Infrastrukturinvestition, sodass Wachstum vorhersehbarer und erschwinglicher wird.
Speichereffizienz: Speichern Sie den Gesprächsverlauf als komprimierte Bilder, um Anwendungen mit ultralangem Kontext ohne exponentielle Speicheranforderungen zu ermöglichen.
Leistung und Benchmarks
Umfassende OmniDocBench-Ergebnisse
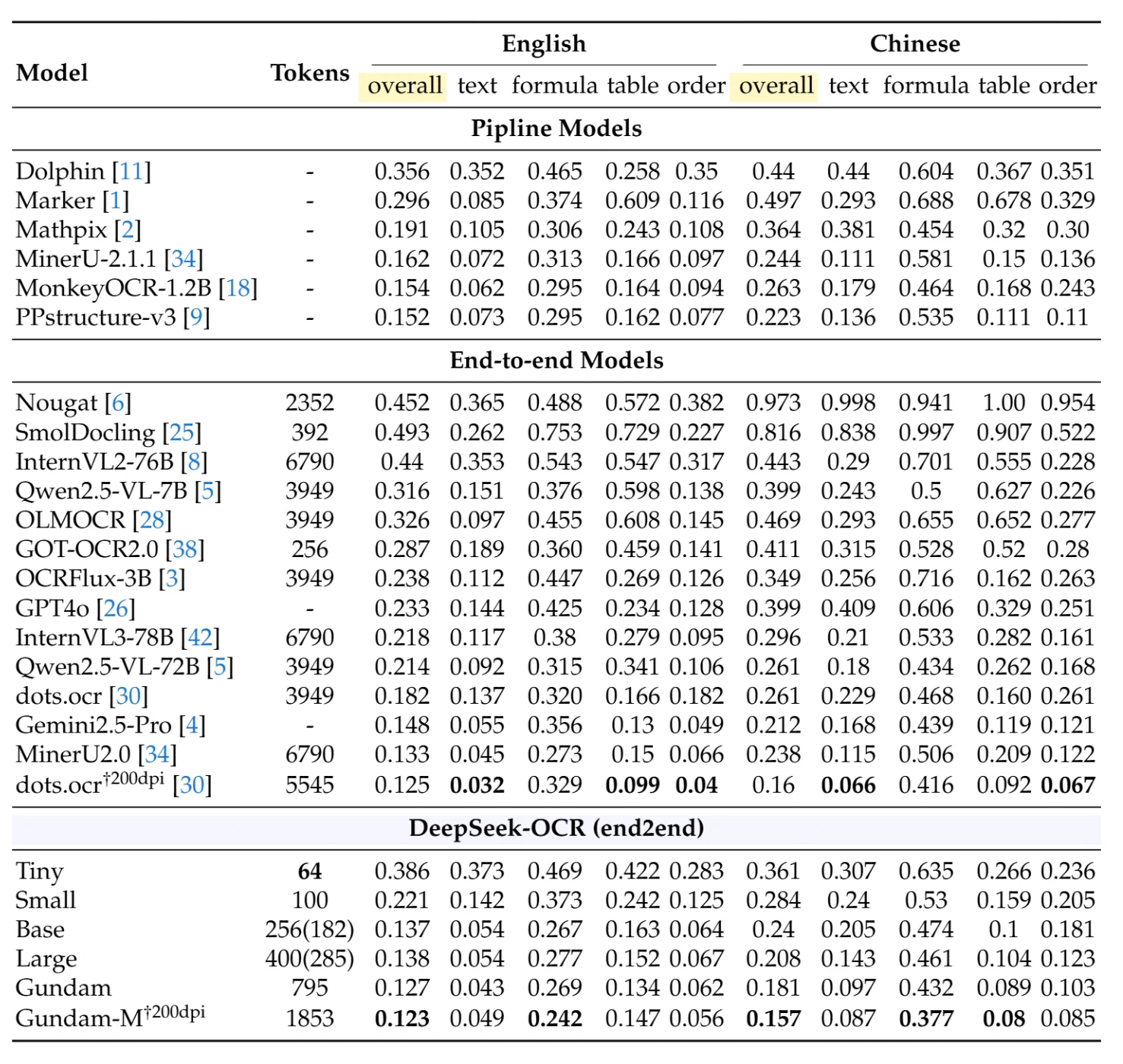
Beim OmniDocBench, einem umfassenden Benchmark für die Dokumentenanalyse, erreicht DeepSeek-OCR mit minimalem Ressourcenaufwand eine außergewöhnliche Leistung. Die folgende Tabelle zeigt detaillierte Vergleiche über verschiedene Dokumenttypen und Sprachen hinweg (Editierdistanz – niedriger ist besser):
Wichtige Highlights:
Pipeline-Modelle (herkömmliche mehrstufige Ansätze): Das bestperformende Pipeline-Modell, PPstructure-v3, erreicht insgesamt 0,152 bei Englisch und 0,223 bei Chinesisch, erfordert aber eine komplexe Multi-Modell-Infrastruktur.
End-to-End-Modelle (Einzelmodell-Ansätze): Unter den Konkurrenten erreicht MinerU2.0 mit 6.790 Token 0,133 bei Englisch und 0,238 bei Chinesisch. Qwen2.5-VL-72B mit 3.949 Token erzielt 0,214 bei Englisch und 0,261 bei Chinesisch.
DeepSeek-OCR-Leistung:
- Small-Modus (100 Token): 0,221 insgesamt bei Englisch, 0,284 insgesamt bei Chinesisch
- Base-Modus (256 Token): 0,137 insgesamt bei Englisch, 0,240 insgesamt bei Chinesisch
- Gundam-Modus (795 Token): 0,127 insgesamt bei Englisch, 0,181 insgesamt bei Chinesisch
- Gundam-M bei 200 dpi (1.853 Token): 0,123 insgesamt bei Englisch, 0,157 insgesamt bei Chinesisch – erreicht state-of-the-art-Ergebnisse
Bemerkenswerte Leistung: Der Base-Modus von DeepSeek-OCR mit nur 256 Token übertrifft Modelle, die 15- bis 26-fach mehr Token verwenden. Der Gundam-Modus erreicht die beste Gesamtleistung unter allen End-to-End-Modellen und verwendet dabei immer noch deutlich weniger Token als herkömmliche Ansätze.
Kategoriespezifische Leistung
Texterkennung: DeepSeek-OCR (Gundam-M) erreicht 0,049 bei englischem Text und 0,087 bei chinesischem Text und übertrifft damit sogar Gemini2.5-Pro.
Formelerkennung: Mit 0,242 bei englischen Formeln und 0,377 bei chinesischen Formeln zeigt DeepSeek-OCR eine starke Leistung bei mathematischen Inhalten.
Tabellenextraktion: Werte von 0,147 bei englischen Tabellen und 0,08 bei chinesischen Tabellen zeigen eine robuste Extraktion strukturierter Daten.
Leistungsfähigkeit im Produktivbetrieb
Verarbeitungsgeschwindigkeit: Eine einzelne A100-40G-GPU kann über 200.000 Seiten pro Tag verarbeiten. Skalieren Sie auf 20 Knoten (160 GPUs), erreichen Sie 33 Millionen Seiten pro Tag – genug für die anspruchsvollsten Unternehmensworkloads.
Kosteneffizienz: Für ein Unternehmen, das monatlich 1 Million Dokumentenseiten verarbeitet, ist der Unterschied enorm. Herkömmliche Modelle, die 6.000 Token pro Seite benötigen, verbrauchen insgesamt 6 Milliarden Token. DeepSeek-OCR mit 800 Token pro Seite verwendet nur 800 Millionen Token – eine 87 %ige Reduzierung der Token-Nutzung und der damit verbundenen Kosten.
Hauptfunktionen und Fähigkeiten
1. Mehrsprachige Unterstützung
DeepSeek-OCR unterstützt fast 100 Sprachen, von großen Weltsprachen (Englisch, Chinesisch, Spanisch, Arabisch, Hindi) bis hin zu spezialisierten Schriften (Thailändisch, Hebräisch, Kyrillisch). Dadurch entfällt die Notwendigkeit für sprachspezifische OCR-Dienste und internationale Betriebsabläufe werden vereinfacht.
2. Fortschrittliches Dokumentenverständnis
Das Modell erkennt weit mehr als nur Text. Es parst Diagramme in strukturierte Daten, extrahiert mathematische Formeln mit LaTeX-Formatierung, identifiziert geometrische Figuren mit SVG-Ausgabe und erhält Tabellenstrukturen einschließlich zusammengeführter Zellen und komplexer Formatierungen.
3. Flexible Ausgabeformate
Wählen Sie zwischen reiner Textextraktion (am schnellsten), Markdown mit erhaltener Formatierung, HTML zur Web-Integration oder strukturiertem JSON zur programmatischen Verarbeitung. Der Grounding-Modus erhält räumliche Beziehungen, sodass Ihre extrahierten Daten die Struktur des Originaldokuments beibehalten.
4. Optische Komprimierung für Langkontexte
Speichern Sie den Gesprächsverlauf als komprimierte Bilder statt als Text-Token. Ein 10-Turn-Gespräch, das bei herkömmlicher Verarbeitung 10.000 Token verbrauchen würde, kann auf 1.000 Vision-Token komprimiert werden, was Anwendungen mit ultralangen Kontextfenstern zu nachhaltigen Kosten ermöglicht.
Die Auswirkung: Chat-Anwendungen können den Kontext über Hunderte von Gesprächsrunden hinweg beibehalten, ohne dass die Kosten exponentiell steigen, was wirklich langformatige KI-Interaktionen ermöglicht.
Erste Schritte auf Novita AI
Auflösungsmodi verstehen
Novita AI bietet DeepSeek-OCR mit fünf Auflösungsmodi, die darauf ausgelegt sind, Leistung, Geschwindigkeit und Kosten für verschiedene Anwendungsfälle auszugleichen.
Native Auflösungsmodi:
Tiny-Modus (512×512, 64 Token): Optimiert für einfache Dokumente, bei denen maximale Geschwindigkeit Priorität hat. Perfekt für Quittungen, einfache Formulare oder schnelle Textextraktionsaufgaben.
Small-Modus (640×640, 100 Token): Der optimale Kompromiss für die meisten Anwendungen. Bietet die beste Balance aus Genauigkeit, Geschwindigkeit und Kosten. Ideal für Standard-Geschäftsdokumente, Rechnungen und Berichte.
Base-Modus (1024×1024, 256 Token): Verarbeitet komplexe Layouts mit erhaltenen Seitenverhältnissen mithilfe von Padding. Empfohlen für Verträge, detaillierte Berichte und Dokumente, bei denen das Layout wichtig ist.
Large-Modus (1280×1280, 400 Token): Maximale Qualität für hochauflösende, detaillierte Dokumente. Am besten geeignet für Forschungsarbeiten, technische Dokumente mit Formeln und Anforderungen an höchste Qualität.
Dynamischer Auflösungsmodus:
Gundam-Modus (n×640×640 + 1×1024×1024, variable Token): Adaptives Kacheln für ultrahochauflösende Dokumente. Teilt große Bilder automatisch in 2 bis 9 lokale Ansichten à 640×640 plus eine globale Ansicht à 1024×1024 auf. Unverzichtbar für Zeitungen, Magazine und komplexe mehrspaltige Layouts. Bei Bildern, die kleiner als 640×640 sind, wechselt er automatisch in den Base-Modus.
Zugriff auf die DeepSeek-OCR-API
Novita AI bietet eine einfache REST-API für DeepSeek-OCR. Um loszulegen, registrieren Sie sich für ein Novita AI-Konto und holen Sie Ihren API-Schlüssel. Der API-Endpunkt akzeptiert Bild-URLs oder base64-kodierte Bilder zusammen mit Konfigurationsparametern wie Auflösungsmodus, Sprachpräferenz und Ausgabeformat.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="<Your API Key>",
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
},
{
"type": "text",
"text": "<|grounding|>OCR this image."
}
]
}
],
stream=False,
max_tokens=4096
)
content = response.choices[0].message.content
print(content)
Grundlegende Nutzungsmuster
Für einfache Textextraktion, bei der die Formatierung keine Rolle spielt, verwenden Sie den Modus „Free OCR“. Für die strukturierte Dokumentenanalyse, die Layout, Tabellen und Formatierungen beibehält, verwenden Sie den „Grounding“-Modus mit Markdown-Ausgabe. Für die erweiterte Analyse von Diagrammen, Formeln oder geometrischen Figuren verwenden Sie den Prompt „Parse the figure“.
Auflösungsleitfaden
Auswahl des richtigen Modus
Für Rechnungen, Quittungen und einfache Formulare: Der Small-Modus (100 Token) ist die beste Wahl. Er ist schnell, kostengünstig und bietet ausreichende Genauigkeit für die Extraktion strukturierter Daten. Damit werden die meisten routinemäßigen Anforderungen an die Geschäftsdokumentenverarbeitung abgedeckt.
Für Geschäftsdokumente, Berichte und Verträge: Der Base-Modus (256 Token) verarbeitet komplexe Layouts gut und erhält die Seitenverhältnisse durch Padding. Er bietet die richtige Balance, wenn Dokumentstruktur und Formatierung wichtig sind.
Für Forschungsarbeiten und technische Dokumente: Der Large-Modus (400 Token) bietet die Genauigkeit, die für dichten Text, mathematische Formeln und technische Diagramme benötigt wird. Die höhere Token-Anzahl ist durch die Präzisionsanforderungen gerechtfertigt.
Für Zeitungen, Magazine und mehrspaltige Layouts: Der Gundam-Modus (variable Token) ist unverzichtbar. Sein adaptives Kacheln verarbeitet ultrahohe Auflösungen und komplexe mehrspaltige Layouts, die in Modi mit fester Auflösung unleserlich wären. Obwohl er mehr Token verwendet, ist er immer noch deutlich effizienter als herkömmliche Ansätze.
Leistungseinblicke nach Dokumenttyp
Basierend auf den umfassenden OmniDocBench-Tests:
Folien und einfache Dokumente: Selbst der Tiny-Modus (64 Token) liefert bei Folien eine bemerkenswert gute Leistung mit einer Editierdistanz von 0,116, während der Small-Modus den optimalen Nutzen bietet. Das liegt daran, dass Präsentationsfolien in der Regel klare Layouts und wenig Text pro Seite haben.
Bücher und Standarddokumente: Der Small-Modus (100 Token) bietet bei Büchern einen ausgezeichneten Nutzen mit einer Editierdistanz von 0,085. Die meisten Bücher enthalten 600 bis 1.000 Text-Token pro Seite, was genau im optimalen Bereich der 10-fachen Komprimierung liegt.
Wissenschaftliche Arbeiten: Es wird der Large-Modus oder der Gundam-Modus empfohlen, wobei Gundam bei wissenschaftlichen Arbeiten eine Editierdistanz von 0,039 erreicht – und damit Modelle übertrifft, die 5- bis 8-fach mehr Token verwenden.
Zeitungen: Der Gundam-Modus ist unverzichtbar und erreicht eine Editierdistanz von 0,122 im Vergleich zu 0,940 für den Tiny-Modus. Zeitungen enthalten 4.000 bis 5.000 Text-Token pro Seite mit komplexen mehrspaltigen Layouts, die den adaptiven Kachelansatz erfordern.
Formelreiche Dokumente: Bei Dokumenten mit mathematischen Formeln erreicht der Gundam-Modus die beste Leistung mit einer Editierdistanz von 0,242 bei englischen Formeln und ist damit mit spezialisierten großen Modellen wettbewerbsfähig.
Der Gundam-Modus im Detail
Der Gundam-Modus funktioniert, indem er mehrere lokale Ansichten (2 bis 9 Kacheln à 640×640) erstellt, die detaillierte Bereiche erfassen, sowie eine globale Ansicht (1024×1024), die den Gesamtkontext beibehält. Die gesamte Token-Anzahl wird als n×100 + 256 berechnet, wobei n die Anzahl der Kacheln ist.
Wann Sie den Gundam-Modus verwenden sollten: Verwenden Sie ihn für Bilder, die in einer Dimension größer als 1280 Pixel sind, Dokumente mit mehrspaltigen Layouts, Inhalte mit 4.000+ Text-Token oder komplexe Infografiken, die sowohl Details als auch Kontext benötigen.
Praktisches Beispiel: Eine kleine Zeitungsseite verwendet möglicherweise 3 Kacheln (insgesamt 556 Token), während eine große Zeitungsseite 6 Kacheln (856 Token) verwendet. Vergleichen Sie dies mit herkömmlichen Ansätzen, die 6.000+ Token benötigen – Sie erreichen immer noch eine 7- bis 10-fache Komprimierung selbst bei den komplexesten Dokumenten.
Fazit
DeepSeek-OCR auf Novita AI erreicht 10-fache Komprimierung bei 97 % Genauigkeit, senkt die Kosten für die Dokumentenverarbeitung um bis zu 85 % und unterstützt dabei 100 Sprachen sowie die Verarbeitung von über 200.000 Seiten pro GPU und Tag.
Die Ergebnisse sprechen für sich: Unternehmen, die monatlich 100.000 Dokumente verarbeiten, sparen jährlich über 50.000 $. Die Verarbeitungsgeschwindigkeiten verbessern sich um das 5- bis 10-fache. Die Infrastruktur skaliert linear statt exponentiell.
Bereit, Ihre Dokumentenverarbeitung zu transformieren?
Kostenlos im Playground starten →
Testen Sie DeepSeek-OCR in wenigen Minuten mit Ihren eigenen Dokumenten. Keine Kreditkarte erforderlich. Wählen Sie aus fünf Auflösungsmodi, verarbeiten Sie Dokumente in 100 Sprachen und erleben Sie 10-fache Komprimierung selbst.
Novita AI ist eine führende KI-Cloud-Plattform, die Entwicklern einfach zu verwendende APIs sowie erschwingliche, zuverlässige GPU-Infrastruktur zum Erstellen und Skalieren von KI-Anwendungen bietet.



