

يقدم DeepSeek-OCR ضغطًا نصيًا 10× مع دقة 97% من خلال معالجة الصور كمساحة تخزين مضغوطة للنص. بدلاً من معالجة 1000 رمز نصي بشكل منفصل، يعالجها كصورة واحدة باستخدام 100 رمز رؤية فقط – مما يخفض التكاليف بنسبة تصل إلى 85%.
متاح الآن على Novita AI، يعالج DeepSeek-OCR أكثر من 200,000 صفحة في اليوم لكل وحدة معالجة رسومية (GPU)، ويدعم 100 لغة، ويوفر خمسة أوضاع دقة (من 64 إلى أكثر من 400 رمز). إنه يتجاوز تقنية OCR التقليدية لتحليل الرسوم البيانية إلى بيانات منظمة، والتعرف على الصيغ الكيميائية، واستخراج الأشكال الهندسية، وتمكين إدارة ذاكرة مبتكرة للمحادثات الطويلة.
جربه الآن في مساحة تجربة Novita AI →
ما هو DeepSeek-OCR؟
DeepSeek-OCR هو نموذج لغة رؤية يعالج الصور كمساحة تخزين مضغوطة للنص. بدلاً من معالجة مستند يحتوي على 1000 رمز نصي بشكل منفصل (وهو ما يستهلك موارد حاسوبية كبيرة)، يعالج النموذج المستند كصورة واحدة باستخدام 100 رمز رؤية فقط – مما يحقق تخفيضًا بنسبة 10× في تكاليف المعالجة.
البنية الأساسية
يتكون النموذج من مكونين رئيسيين:
DeepEncoder (~380M معامل): مشفر رؤية متخصص يعالج صور المستندات بكفاءة باستخدام بنية تسلسلية فريدة تجمع بين انتباه النافذة (SAM) والانتباه العام (CLIP) مع طبقة ضغط 16× بينهما.
DeepSeek3B-MoE Decoder (570M معامل نشط): نموذج لغة مختلط الخبراء مضغوط يحول المعلومات البصرية المضغوطة مرة أخرى إلى نص بدقة ملحوظة.
تتيح هذه البنية كفاءة غير مسبوقة في معالجة المستندات، مما يجعلها مثالية للشركات التي تتعامل مع أحجام كبيرة من المستندات أو التطبيقات التي تتطلب فهمًا لسياق طويل.
لماذا يعد الضغط البصري مهمًا؟
المشكلة التقليدية
تتوسع معالجة النص التقليدية في نماذج الذكاء الاصطناعي بشكل تربيعي – فمضاعفة طول المستند يمكن أن تزيد التكاليف أربع مرات. بالنسبة للشركات التي تعالج آلاف المستندات يوميًا، يصبح هذا مكلفًا بشكل مفرط.
حل DeepSeek-OCR
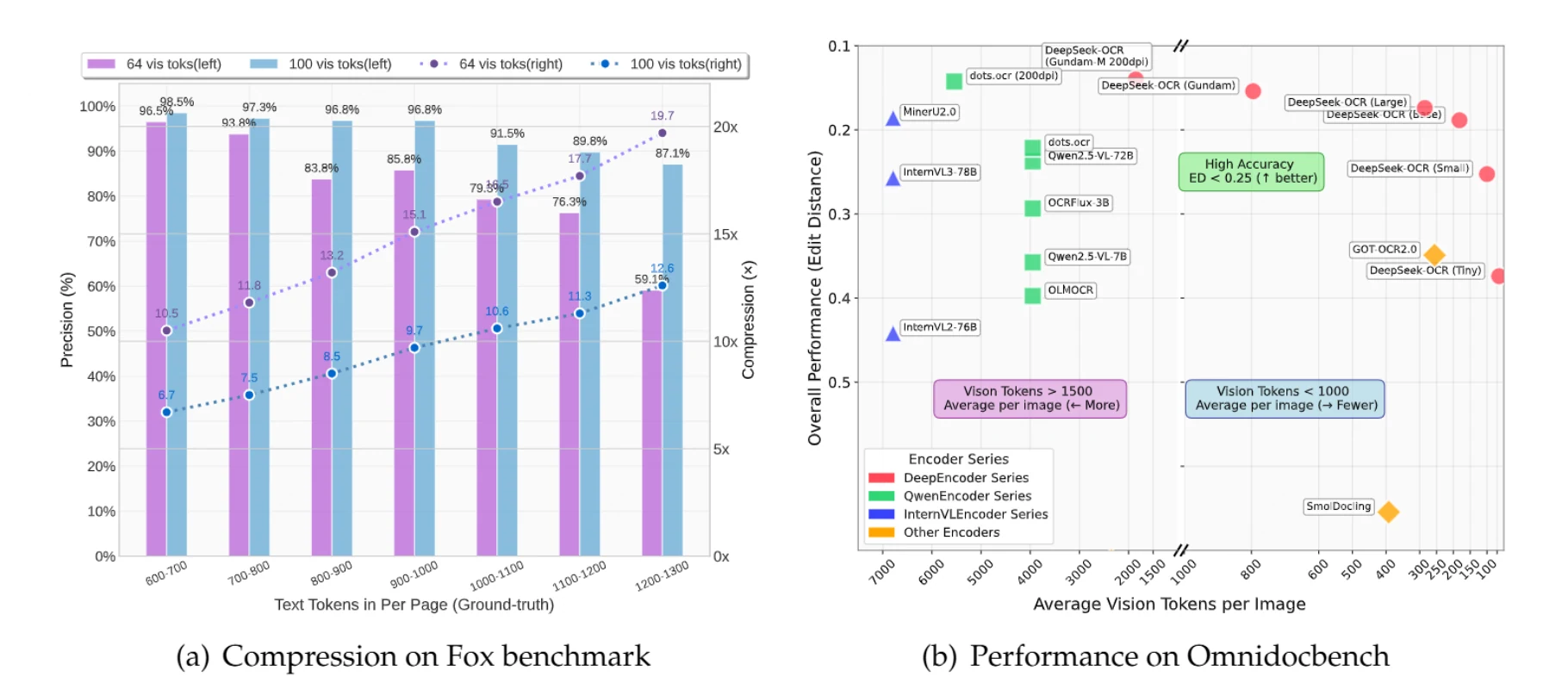
يمكن ضغط المستندات التي تحتوي على ما يصل إلى 1000 رمز نصي بمقدار 10× مع دقة 97%. حتى عند ضغط 20×، تظل الدقة حوالي 60% – وهو ما يكفي غالبًا للعديد من التطبيقات.
مثال واقعي:
المستند الذي يحتوي على 900 رمز نصي يتطلب تقليديًا 900 رمز للمعالجة. مع DeepSeek-OCR باستخدام وضع Small (100 رمز رؤية)، تحصل على ضغط 9.7× بدقة 96.8%. بالنسبة للمستندات التي تحتوي على 1100 رمز نصي، تحصل على ضغط 10.6× بدقة 91.5%.
التأثير على الأعمال
تخفيض تكاليف API: ما يصل إلى 10× رموز أقل تتم معالجتها للمستندات النموذجية يعني توفيرًا كبيرًا في التكاليف – فالأعمال التي تعالج مليون صفحة شهريًا يمكن أن توفر أكثر من 50,000 دولار سنويًا.
معالجة أسرع: الرموز الأقل تترجم مباشرة إلى أوقات استجابة أسرع، مما يحسن تجربة المستخدم ويمكن التطبيقات في الوقت الفعلي.
قابلية توسع أفضل: تعامل مع 10× مستندات إضافية بنفس استثمار البنية التحتية، مما يجعل النمو أكثر قابلية للتنبؤ وبأسعار معقولة.
كفاءة الذاكرة: قم بتخزين سجل المحادثات كصور مضغوطة، مما يمكن التطبيقات ذات السياق فائق الطول دون متطلبات ذاكرة أسية.
الأداء والاختبارات المعيارية
نتائج اختبار OmniDocBench الشامل
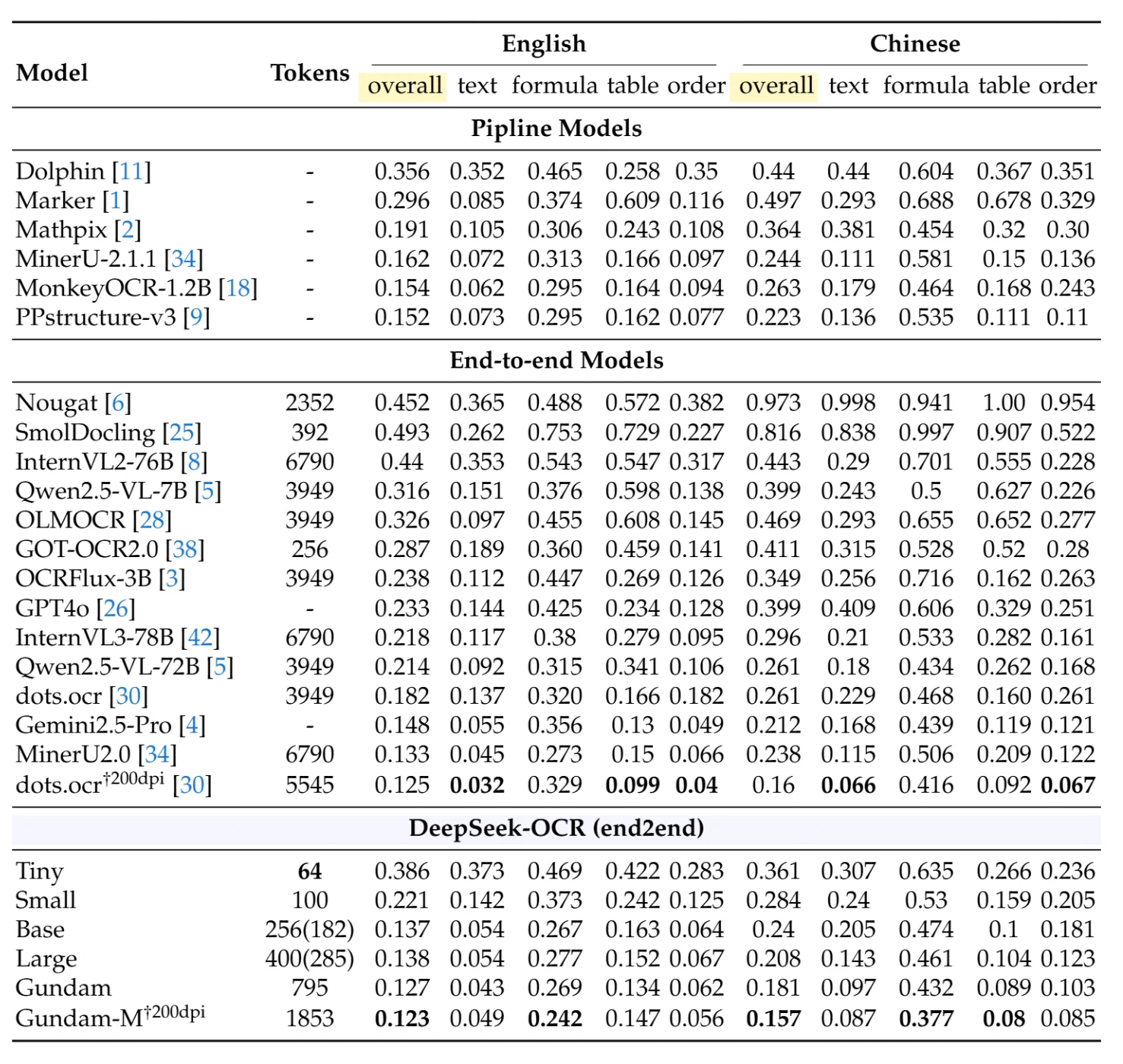
على اختبار OmniDocBench الشامل لتحليل المستندات، يحقق DeepSeek-OCR أداءً استثنائيًا مع استخدام أدنى للموارد. توضح الجدول أدناه مقارنات مفصلة عبر أنواع ولغات مستندات مختلفة (مسافة التحرير – كلما كان أقل كان أفضل):
أبرز النتائج:
نماذج الأنابيب (النهج متعدد المراحل التقليدي): أفضل نموذج أنابيب أداءً، PPstructure-v3، يحقق 0.152 بشكل عام على اللغة الإنجليزية و 0.223 على الصينية، ولكنه يتطلب بنية تحتية متعددة النماذج معقدة.
النماذج من النهاية إلى النهاية (نهج النموذج الفردي): بين المنافسين، يحقق MinerU2.0 الذي يستخدم 6790 رمزًا 0.133 على اللغة الإنجليزية و 0.238 على الصينية. يحقق Qwen2.5-VL-72B الذي يستخدم 3949 رمزًا نتيجة 0.214 على الإنجليزية و 0.261 على الصينية.
أداء DeepSeek-OCR:
- وضع Small (100 رمز): 0.221 بشكل عام على الإنجليزية، 0.284 بشكل عام على الصينية
- وضع Base (256 رمز): 0.137 بشكل عام على الإنجليزية، 0.240 بشكل عام على الصينية
- وضع Gundam (795 رمز): 0.127 بشكل عام على الإنجليزية، 0.181 بشكل عام على الصينية
- وضع Gundam-M بدقة 200dpi (1853 رمز): 0.123 بشكل عام على الإنجليزية، 0.157 بشكل عام على الصينية – يحقق نتائج رائدة على مستوى المجال
إنجاز مذهل: يتفوق وضع Base لـ DeepSeek-OCR الذي يستخدم 256 رمزًا فقط على النماذج التي تستخدم 15-26× رموز إضافية. يحقق وضع Gundam-M أفضل أداء عام بين جميع النماذج من النهاية إلى النهاية بينما لا يزال يستخدم عددًا أقل بكثير من الرموز مقارنة بالنهج التقليدية.
الأداء حسب الفئة
التعرف على النص: يحقق DeepSeek-OCR (وضع Gundam-M) 0.049 على النص الإنجليزي و 0.087 على النص الصيني، متفوقًا حتى على Gemini2.5-Pro.
التعرف على الصيغ: بدرجة 0.242 على الصيغ الإنجليزية و 0.377 على الصيغ الصينية، يظهر DeepSeek-OCR قدرة قوية على المحتوى الرياضي.
استخراج الجداول: تظهر درجات 0.147 على الجداول الإنجليزية و 0.08 على الجداول الصينية قدرة قوية على استخراج البيانات المنظمة.
القدرات الإنتاجية
سرعة المعالجة: يمكن لوحدة معالجة رسومية واحدة من نوع A100-40G معالجة أكثر من 200,000 صفحة في اليوم. مع التوسع إلى 20 عقدة (160 وحدة معالجة رسومية)، ستحصل على 33 مليون صفحة في اليوم – ما يكفي لأعباء العمل المؤسسية الأكثر تطلبًا.
كفاءة التكلفة: بالنسبة لشركة تعالج مليون صفحة مستند شهريًا، الفرق كبير. النماذج التقليدية التي تتطلب 6000 رمز لكل صفحة تستهلك 6 مليارات رمز إجمالاً. DeepSeek-OCR الذي يستخدم 800 رمز لكل صفحة يستهلك فقط 800 مليون رمز – تخفيض بنسبة 87% في استخدام الرموز والتكاليف المرتبطة بها.
الميزات والقدرات الرئيسية
1. دعم متعدد اللغات
يدعم DeepSeek-OCR ما يقرب من 100 لغة، من اللغات العالمية الرئيسية (الإنجليزية، الصينية، الإسبانية، العربية، الهندية) إلى النصوص المتخصصة (التايلاندية، العبرية، السيريلية). هذا يلغي الحاجة إلى خدمات OCR خاصة بكل لغة ويبسط العمليات الدولية.
2. فهم متقدم للمستندات
يتعرف النموذج على أكثر من مجرد نص بكثير. فهو يحلل الرسوم البيانية إلى بيانات منظمة، ويستخرج الصيغ الرياضية بتنسيق LaTeX، ويحدد الأشكال الهندسية مع مخرجات SVG، ويحافظ على هياكل الجداول بما في ذلك الخلايا المدمجة والتنسيقات المعقدة.
3. تنسيقات مخرجات مرنة
اختر بين استخراج نص صرف (الأسرع)، أو markdown مع الحفاظ على التنسيق، أو HTML للتكامل مع الويب، أو JSON منظم للمعالجة البرمجية. يحافظ وضع grounding على العلاقات المكانية، مما يضمن أن بياناتك المستخرجة تحافظ على بنية المستند الأصلي.
4. ضغط بصري للسياقات الطويلة
قم بتخزين سجل المحادثات كصور مضغوطة بدلاً من الرموز النصية. يمكن ضغط محادثة من 10 دورات كانت تستهلك تقليديًا 10,000 رمز إلى 1000 رمز رؤية، مما يمكن التطبيقات ذات نوافذ السياق فائقة الطول بتكاليف مستدامة.
التأثير: يمكن لتطبيقات الدردشة الحفاظ على السياق عبر مئات دورات المحادثة دون زيادة أسية في التكاليف، مما يمكن تفاعلات الذكاء الاصطناعي الطويلة حقًا.
ابدأ الاستخدام على Novita AI
فهم أوضاع الدقة
يوفر Novita AI لـ DeepSeek-OCR خمسة أوضاع دقة مصممة لتحقيق التوازن بين الأداء والسرعة والتكلفة لحالات الاستخدام المختلفة.
أوضاع الدقة الأصلية:
وضع Tiny (512×512، 64 رمز): مُحسّن للمستندات البسيطة حيث تكون السرعة القصوى هي الأولوية. مثالي للإيصالات، النماذج البسيطة، أو مهام استخراج النص السريعة.
وضع Small (640×640، 100 رمز): الخيار الأمثل لمعظم التطبيقات. يقدم أفضل توازن بين الدقة والسرعة والتكلفة. مثالي لمستندات الأعمال القياسية، الفواتير، والتقارير.
وضع Base (1024×1024، 256 رمز): يعالج التخطيطات المعقدة مع الحفاظ على نسبة الأبعاد باستخدام الحشو. موصى به للعقود، التقارير التفصيلية، والمستندات التي يكون فيها التخطيط مهمًا.
وضع Large (1280×1280، 400 رمز): أقصى جودة للمستندات التفصيلية عالية الدقة. الأفضل لأوراق البحث، المستندات التقنية التي تحتوي على صيغ، ومتطلبات الجودة المتميزة.
وضع الدقة الديناميكي:
وضع Gundam (n×640×640 + 1×1024×1024، رموز متغيرة): تقسيم تكيفي للمستندات فائقة الدقة. يقسم الصور الكبيرة تلقائيًا إلى 2-9 طرق عرض محلية بدقة 640×640 بالإضافة إلى طريقة عرض عامة واحدة بدقة 1024×1024. ضروري للصحف، المجلات، والتخطيطات متعددة الأعمدة المعقدة. بالنسبة للصور الأصغر من 640×640، يتحول تلقائيًا إلى وضع Base.
الوصول إلى API الخاص بـ DeepSeek-OCR
يوفر Novita AI API REST بسيطًا لـ DeepSeek-OCR. للبدء، قم بإنشاء حساب على Novita AI واحصل على مفتاح API الخاص بك. تقبل نقطة نهاية API عناوين URL للصور أو الصور المشفرة بـ base64 بالإضافة إلى معلمات التكوين مثل وضع الدقة، تفضيل اللغة، وتنسيق المخرجات.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="<Your API Key>",
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
},
{
"type": "text",
"text": "<|grounding|>OCR this image."
}
]
}
],
stream=False,
max_tokens=4096
)
content = response.choices[0].message.content
print(content)
أنماط الاستخدام الأساسية
لاستخراج النص البسيط حيث لا يهم التنسيق، استخدم وضع “Free OCR”. لتحليل المستندات المنظمة الذي يحافظ على التخطيط والجداول والتنسيق، استخدم وضع “grounding” مع مخرجات markdown. للتحليل المتقدم للرسوم البيانية أو الصيغ أو الأشكال الهندسية، استخدم موجه “Parse the figure”.
دليل الدقة
اختيار الوضع المناسب
للإيصالات، الفواتير، والنماذج البسيطة: وضع Small (100 رمز) هو خيارك الأفضل. إنه سريع، فعال من حيث التكلفة، ويوفر دقة كافية لاستخراج البيانات المنظمة. هذا يغطي معظم احتياجات معالجة مستندات الأعمال الروتينية.
لمستندات الأعمال، التقارير، والعقود: يعالج وضع Base (256 رمز) التخطيطات المعقدة جيدًا ويحافظ على نسبة الأبعاد باستخدام الحشو. إنه التوازن الصحيح عندما تكون بنية المستند والتنسيق مهمين.
لأوراق البحث والمستندات التقنية: يوفر وضع Large (400 رمز) الدقة المطلوبة للنص الكثيف، الصيغ الرياضية، والمخططات التقنية. عدد الرموز الأعلى مبرر بمتطلبات الدقة.
للصحف، المجلات، والتخطيطات متعددة الأعمدة: وضع Gundam (رموز متغيرة) ضروري. يعالج تقسيمه التكيفي الدقة فائقة والتخطيطات متعددة الأعمدة المعقدة التي ستكون غير مقروءة في أوضاع الدقة الثابتة. على الرغم من أنه يستخدم رموزًا أكثر، إلا أنه لا يزال أكثر كفاءة بكثير من النهج التقليدية.
رؤى الأداء حسب نوع المستند
بناءً على اختبارات OmniDocBench الشاملة:
الشرائح والمستندات البسيطة: حتى وضع Tiny (64 رمز) يؤدي أداءً مذهلاً بمسافة تحرير 0.116 على الشرائح، بينما يقدم وضع Small قيمة مثلى. هذا لأن شرائح العروض التقديمية عادة ما يكون لها تخطيطات واضحة ونص محدود لكل صفحة.
الكتب والمستندات القياسية: يقدم وضع Small (100 رمز) قيمة ممتازة بمسافة تحرير 0.085 للكتب. تحتوي معظم الكتب على 600-1000 رمز نصي لكل صفحة، وهو ما يقع تمامًا ضمن النطاق الأمثل لضغط 10×.
الأوراق الأكاديمية: يوصى بوضع Large أو وضع Gundam، حيث يحقق Gundam مسافة تحرير 0.039 على الأوراق الأكاديمية – متفوقًا على النماذج التي تستخدم 5-8× رموز إضافية.
الصحف: وضع Gundam ضروري، حيث يحقق مسافة تحرير 0.122 مقارنة بـ 0.940 لوضع Tiny. تحتوي الصحف على 4000-5000 رمز نصي لكل صفحة مع تخطيطات متعددة الأعمدة المعقدة التي تتطلب نهج التقسيم التكيفي.
المستندات الغنية بالصيغ: بالنسبة للمستندات التي تحتوي على صيغ رياضية، يحقق وضع Gundam-M أفضل أداء بمسافة تحرير 0.242 على الصيغ الإنجليزية، وهو منافس للنماذج الكبيرة المتخصصة.
فهم وضع Gundam بالتفصيل
يعمل وضع Gundam عن طريق إنشاء طرق عرض محلية متعددة (2-9 بلاطات بدقة 640×640) تلتقط المناطق التفصيلية، بالإضافة إلى طريقة عرض عامة واحدة (1024×1024) تحافظ على السياق العام. يتم حساب إجمالي عدد الرموز كـ n×100 + 256، حيث n هو عدد البلاطات.
متى تستخدم وضع Gundam: استخدمه للصور الأكبر من 1280 بكسل في أي بُعد، المستندات ذات التخطيطات متعددة الأعمدة، المحتوى الذي يحتوي على أكثر من 4000 رمز نصي، أو الرسوم البيانية المعقدة التي تحتاج إلى كل من التفاصيل والسياق.
مثال واقعي: قد تستخدم صفحة صحفية صغيرة 3 بلاطات (إجمالي 556 رمز)، بينما تستخدم صفحة صحفية كبيرة 6 بلاطات (856 رمز). قارن هذا بالنهج التقليدية التي تتطلب أكثر من 6000 رمز – لا يزال لديك ضغط 7-10× حتى على المستندات الأكثر تعقيدًا.
الخلاصة
يحقق DeepSeek-OCR على Novita AI ضغطًا 10× بدقة 97%، مما يخفض تكاليف معالجة المستندات بنسبة تصل إلى 85% بينما يدعم 100 لغة ويعالج أكثر من 200,000 صفحة لكل وحدة معالجة رسومية في اليوم.
النتائج تتحدث عن نفسها: الشركات التي تعالج 100,000 مستند شهريًا توفر أكثر من 50,000 دولار سنويًا. تتحسن سرعات المعالجة بمقدار 5-10×. تتوسع البنية التحتية بشكل خطي بدلاً من الأسّي.
مستعد لتحويل معالجة مستنداتك؟
ابدأ مجانًا في مساحة التجربة →
اختبر DeepSeek-OCR مع مستنداتك الخاصة في دقائق. لا يطلب بطاقة ائتمان. اختر من بين خمسة أوضاع دقة، وعالج مستندات بـ 100 لغة، وجرب الضغط 10× بنفسك.
Novita AI هي منصة سحابة ذكاء اصطناعي رائدة توفر للمطورين واجهات برمجة تطبيقات (APIs) سهلة الاستخدام وبنية تحتية لوحدات المعالجة الرسومية (GPU) بأسعار معقولة وموثوقة لبناء وتوسيع نطاق تطبيقات الذكاء الاصطناعي.



