

DeepSeek-OCR 通过将图像视为文本的压缩存储,实现了 10 倍文本压缩,准确率达 97%。它不再分别处理 1,000 个文本令牌,而是将文档作为单个图像处理,仅使用 100 个视觉令牌——成本降低高达 85%。
现在,DeepSeek-OCR 已在 Novita AI 上线,每块 GPU 每天可处理 200,000 页以上,支持 100 种语言,并提供五种分辨率模式(64 至 400+ 令牌)。它的功能超越了传统 OCR,能够将图表解析为结构化数据、识别化学公式、提取几何图形,并为长对话提供创新的记忆管理。
现在就在 Novita AI Playground 中尝试 →
DeepSeek-OCR 是什么?
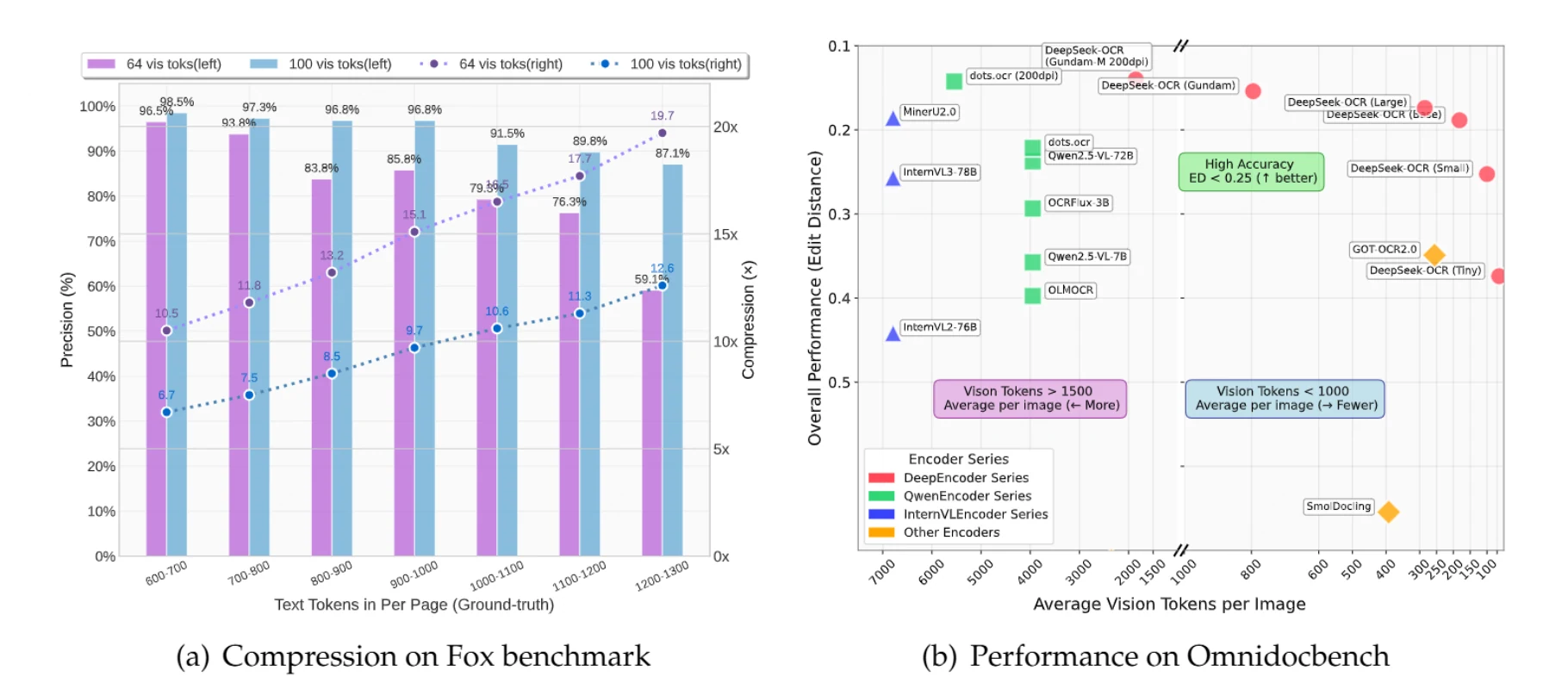
DeepSeek-OCR 是一个视觉语言模型,它将图像视为文本的压缩存储。一个包含 1,000 个文本令牌的文档,传统上需要逐个处理这些令牌(计算成本很高),而该模型将其作为单个图像处理,仅使用 100 个视觉令牌——处理成本降低了 10 倍。
核心架构
该模型由两个关键组件组成:
DeepEncoder(约 3.8 亿参数):一个专门的视觉编码器,采用独特的串行架构,结合了窗口注意力(SAM)和全局注意力(CLIP),并在两者之间加入了一个 16 倍压缩层,能够高效处理文档图像。
DeepSeek3B-MoE 解码器(5.7 亿激活参数):一个紧凑的混合专家语言模型,能够以极高的准确率将压缩后的视觉信息转换回文本。
这种架构在文档处理中实现了前所未有的效率,非常适合处理大量文档的企业,或需要长上下文理解的应用。
为什么光学压缩很重要
传统问题
AI 模型中的传统文本处理呈二次方增长——文档长度翻倍,成本可能增加四倍。对于每天处理数千份文档的企业来说,这变得极其昂贵。
DeepSeek-OCR 的解决方案
包含最多 1,000 个文本令牌的文档可以被压缩 10 倍,准确率仍达 97%。即使在 20 倍压缩下,准确率也保持在 60% 左右——对于许多应用来说已经足够。
实际案例:
一份包含 900 个文本令牌的文档,传统上需要 900 个令牌来处理。使用 DeepSeek-OCR 的小模式(100 个视觉令牌),你可以实现 9.7 倍压缩,准确率 96.8%。对于包含 1,100 个文本令牌的文档,你可以获得 10.6 倍压缩,准确率 91.5%。
商业影响
降低 API 成本:对于典型文档,处理的令牌数量最多可减少 10 倍,从而大幅节省成本——每月处理 100 万页的企业每年可节省超过 5 万美元。
更快的处理速度:令牌数量减少直接带来更快的响应时间,改善用户体验,并支持实时应用。
更好的可扩展性:在相同基础设施投入下,可以处理 10 倍的文档数量,使增长更可预测、更经济。
内存效率:将对话历史存储为压缩图像,实现超长上下文应用,无需指数级的内存需求。
性能与基准测试
全面的 OmniDocBench 结果
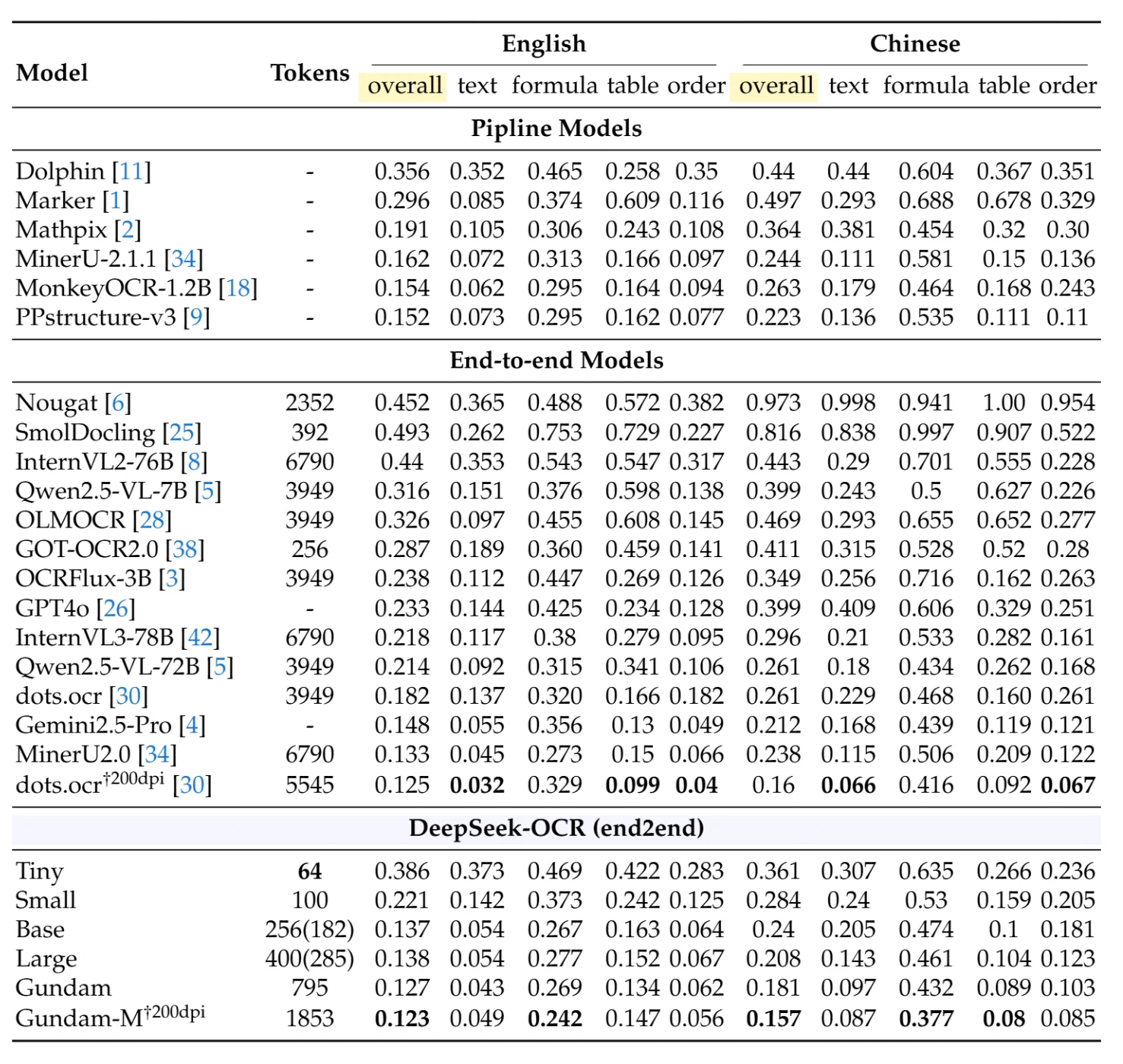
在全面的文档解析基准测试 OmniDocBench 上,DeepSeek-OCR 以最小的资源消耗取得了卓越的性能。下表显示了不同文档类型和语言的详细对比(编辑距离——越低越好):
关键亮点:
管道模型(传统的多阶段方法):性能最好的管道模型 PPstructure-v3 在英文上整体得分为 0.152,在中文上为 0.223,但需要复杂的多模型基础设施。
端到端模型(单模型方法):在竞争对手中,使用 6,790 个令牌的 MinerU2.0 在英文上得分为 0.133,在中文上为 0.238。使用 3,949 个令牌的 Qwen2.5-VL-72B 在英文上得分为 0.214,在中文上为 0.261。
DeepSeek-OCR 性能:
- 小模式(100 令牌):英文整体 0.221,中文整体 0.284
- 基础模式(256 令牌):英文整体 0.137,中文整体 0.240
- 高达模式(795 令牌):英文整体 0.127,中文整体 0.181
- 高达-M 模式,200dpi(1,853 令牌):英文整体 0.123,中文整体 0.157——达到最先进水平
显著成就:DeepSeek-OCR 的基础模式仅使用 256 个令牌,就超越了使用 15-26 倍令牌的模型。高达-M 模式在所有端到端模型中取得了最佳综合性能,同时使用的令牌数仍远少于传统方法。
按类别划分的性能
文本识别:DeepSeek-OCR(高达-M)在英文文本上达到 0.049,在中文文本上达到 0.087,表现优于 Gemini2.5-Pro。
公式识别:DeepSeek-OCR 在英文公式上为 0.242,在中文公式上为 0.377,展示了强大的数学内容处理能力。
表格提取:在英文表格上得分为 0.147,在中文表格上得分为 0.08,展示了稳健的结构化数据提取能力。
生产环境能力
处理速度:单块 A100-40G GPU 每天可处理超过 200,000 页。扩展到 20 个节点(160 块 GPU),每天可处理 3,300 万页——足以满足最苛刻的企业工作负载。
成本效益:对于每月处理 100 万文档页的企业,差异显而易见。传统模型每页需要 6,000 个令牌,总计消耗 60 亿个令牌。DeepSeek-OCR 每页使用 800 个令牌,仅消耗 8 亿个令牌——令牌使用量及相关成本减少了 87%。
主要功能与能力
1. 多语言支持
DeepSeek-OCR 支持近 100 种语言,从主要世界语言(英语、汉语、西班牙语、阿拉伯语、印地语)到特殊文字(泰语、希伯来语、西里尔字母)。这消除了对特定语言 OCR 服务的需求,简化了国际业务运营。
2. 高级文档理解
该模型识别的内容远不止文本。它可以将图表解析为结构化数据,用 LaTeX 格式提取数学公式,以 SVG 输出识别几何图形,并保持表格结构(包括合并单元格和复杂格式)。
3. 灵活的输出格式
选择纯文本提取(最快)、保留格式的 Markdown、用于 Web 集成的 HTML,或用于程序化处理的结构化 JSON。定位模式保持空间关系,确保提取的数据保留原始文档的结构。
4. 用于长上下文的光学压缩
将对话历史存储为压缩图像,而不是文本令牌。一个传统上需要 10,000 个令牌的 10 轮对话,可以压缩到 1,000 个视觉令牌,使具有超长上下文窗口的应用能够以可持续的成本运行。
影响:聊天应用可以在数百轮对话中保持上下文,而不会产生指数级成本增长,从而实现真正的长形式 AI 交互。
在 Novita AI 上快速上手
理解分辨率模式
Novita AI 提供 五种分辨率模式 的 DeepSeek-OCR,旨在平衡不同用例的性能、速度和成本。
原生分辨率模式:
极小模式(512×512,64 令牌):针对速度优先的简单文档进行了优化。非常适合收据、简单表格或快速文本提取任务。
小模式(640×640,100 令牌):大多数应用的最佳选择。在准确率、速度和成本之间提供了最佳平衡。适用于标准的商业文档、发票和报告。
基础模式(1024×1024,256 令牌):通过填充保留宽高比,处理复杂布局。推荐用于合同、详细报告以及布局重要的文档。
大模式(1280×1280,400 令牌):为高分辨率详细文档提供最高质量。最适合研究论文、包含公式的技术文档以及高质量要求。
动态分辨率模式:
高达模式(n×640×640 + 1×1024×1024,可变令牌):针对超高分辨率文档的自适应平铺。自动将大图像分割成 2-9 个 640×640 的局部视图,外加一个 1024×1024 的全局视图。对于报纸、杂志和复杂的多栏布局至关重要。对于小于 640×640 的图像,它会自动降级为基础模式。
访问 DeepSeek-OCR API
Novita AI 为 DeepSeek-OCR 提供了一个简单的 REST API。首先要注册 Novita AI 账户并获取 API 密钥。API 端点接受图像 URL 或 base64 编码的图像,同时还能配置分辨率模式、语言偏好和输出格式等参数。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="<您的 API 密钥>",
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
},
{
"type": "text",
"text": "<|grounding|>OCR 这张图片。"
}
]
}
],
stream=False,
max_tokens=4096
)
content = response.choices[0].message.content
print(content)
基本使用模式
对于格式无关的简单文本提取,使用“自由 OCR”模式。对于需要保留布局、表格和格式的结构化文档解析,使用带有 Markdown 输出的“定位”模式。对于图表、公式或几何图形的高级解析,使用“解析图形”提示。
分辨率指南
选择合适的模式
发票、收据和简单表格:小模式(100 令牌)是最佳选择。它快速、经济高效,并且能为结构化数据提取提供足够的准确率。这涵盖了大多数常规的商业文档处理需求。
商业文档、报告和合同:基础模式(256 令牌)能很好地处理复杂布局,并通过填充保留宽高比。当文档结构和格式很重要时,这是正确的平衡点。
研究论文和技术文档:大模式(400 令牌)为密集文本、数学公式和技术图表提供了所需的准确率。考虑到精度要求,更高的令牌数也是合理的。
报纸、杂志和多栏布局:高达模式(可变令牌)至关重要。它的自适应平铺处理超高分辨率和复杂的多栏布局,这些在固定分辨率模式下会被打乱。虽然它使用了更多令牌,但仍比传统方法高效得多。
按文档类型的性能洞察
基于全面的 OmniDocBench 测试:
幻灯片和简单文档:即使是极小模式(64 令牌)在幻灯片上也表现相当不错,编辑距离为 0.116,而小模式提供了最佳价值。这是因为演示幻灯片通常布局清晰,每页文本有限。
书籍和标准文档:小模式(100 令牌)在书籍上的编辑距离为 0.085,提供了极佳的价值。大多数书籍每页包含 600-1,000 个文本令牌,正好在 10 倍压缩的最佳范围内。
学术论文:建议使用大模式或高达模式,高达模式在学术论文上实现了 0.039 的编辑距离——超越了使用 5-8 倍令牌的模型。
报纸:高达模式必不可少,它实现了 0.122 的编辑距离,而极小模式为 0.940。报纸每页包含 4,000-5,000 个文本令牌,并具有复杂的多栏布局,需要自适应平铺方法。
公式密集型文档:对于包含数学公式的文档,高达-M 模式表现最佳,英文公式编辑距离为 0.242,与专门的超大模型相当。
详细理解高达模式
高达模式通过创建多个局部视图(2-9 个 640×640 的图块)捕捉详细区域,外加一个全局视图(1024×1024)保持整体上下文。总令牌数按 n×100 + 256 计算,其中 n 是图块数量。
何时使用高达模式:当图像在任何维度上大于 1280 像素、文档具有多栏布局、内容包含 4,000+ 文本令牌,或需要同时关注细节和上下文的复杂信息图时使用。
实际例子:一张小报纸可能使用 3 个图块(总共 556 个令牌),而一张大报纸使用 6 个图块(856 个令牌)。相比之下,传统方法需要 6,000+ 个令牌——即使在最复杂的文档上,你依然能实现 7-10 倍的压缩。
结论
Novita AI 上的 DeepSeek-OCR 实现了 10 倍压缩,准确率 97%,将文档处理成本降低高达 85%,同时支持 100 种语言,每块 GPU 每天可处理 200,000 页以上。
结果不言自明: 每月处理 10 万份文档的公司每年节省超过 5 万美元。处理速度提升 5-10 倍。基础设施线性扩展,而非指数级增长。
准备好转变你的文档处理方式了吗?
几分钟内即可用你自己的文档测试 DeepSeek-OCR。无需信用卡。从五种分辨率模式中选择,处理 100 种语言的文档,亲身体验 10 倍压缩。
Novita AI 是一个领先的 AI 云平台,为开发者提供易用的 API 以及经济、可靠的 GPU 基础设施,用于构建和扩展 AI 应用。



