

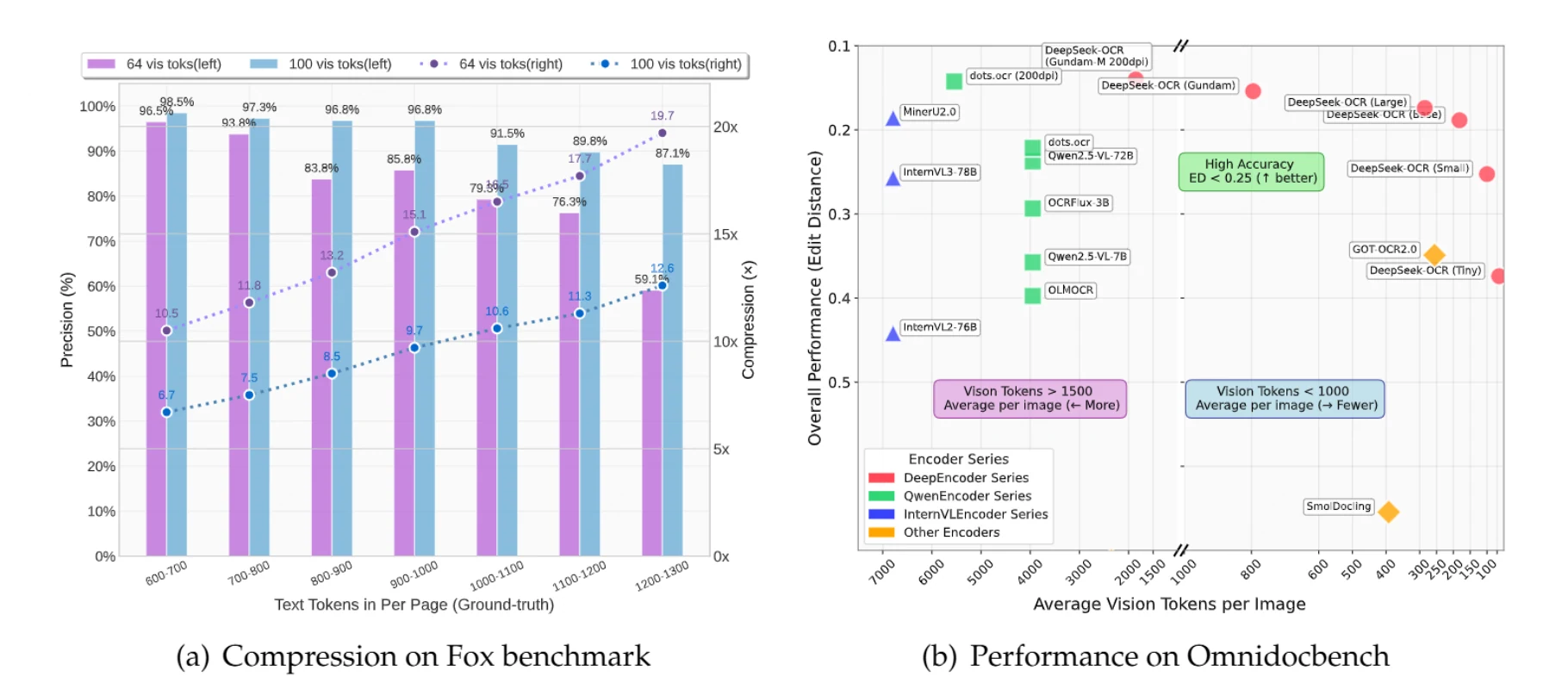
DeepSeek-OCR offre une compression de texte 10× avec 97 % de précision en traitant les images comme un stockage compressé de texte. Au lieu de traiter 1 000 jetons de texte individuellement, il les traite comme une seule image en utilisant seulement 100 jetons visuels, réduisant les coûts jusqu’à 85 %.
Désormais disponible sur Novita AI, DeepSeek-OCR traite plus de 200 000 pages par jour par GPU, prend en charge 100 langues et propose cinq modes de résolution (de 64 à plus de 400 jetons). Il va au-delà de l’OCR traditionnel pour analyser les graphiques en données structurées, reconnaître les formules chimiques, extraire les figures géométriques et permettre une gestion innovante de la mémoire pour les conversations longues.
Essayez-le maintenant dans le playground Novita AI →
Qu’est-ce que DeepSeek-OCR ?
DeepSeek-OCR est un modèle de vision-langage qui traite les images comme un stockage compressé de texte. Au lieu de traiter un document de 1 000 jetons de texte individuellement (ce qui est coûteux en termes de calcul), le modèle le traite comme une seule image en utilisant seulement 100 jetons visuels, soit une réduction de 10× des coûts de traitement.
Architecture de base
Le modèle est composé de deux éléments clés :
DeepEncoder (~380M paramètres) : Un encodeur visuel spécialisé qui traite efficacement les images de documents grâce à une architecture sérielle unique combinant l’attention fenêtrée (SAM) et l’attention globale (CLIP) avec une couche de compression 16× entre les deux.
Décodeur DeepSeek3B-MoE (570M paramètres actifs) : Un modèle de langage compact de type mélange d’experts qui reconvertit les informations visuelles compressées en texte avec une précision remarquable.
Cette architecture permet une efficacité sans précédent dans le traitement des documents, ce qui la rend idéale pour les entreprises traitant de grands volumes de documents ou les applications nécessitant une compréhension de contexte long.
Pourquoi la compression optique est importante
Le problème traditionnel
Le traitement de texte traditionnel dans les modèles d’IA évolue de manière quadratique : doubler la longueur de votre document peut quadrupler vos coûts. Pour les entreprises traitant des milliers de documents par jour, cela devient prohibitivement cher.
La solution DeepSeek-OCR
Les documents contenant jusqu’à 1 000 jetons de texte peuvent être compressés 10× avec 97 % de précision. Même avec une compression 20×, la précision reste d’environ 60 %, ce qui est souvent suffisant pour de nombreuses applications.
Exemple concret :
Un document contenant 900 jetons de texte nécessite traditionnellement 900 jetons pour être traité. Avec DeepSeek-OCR en mode Small (100 jetons visuels), vous obtenez une compression de 9,7× avec 96,8 % de précision. Pour les documents de 1 100 jetons de texte, vous obtenez une compression de 10,6× avec 91,5 % de précision.
Impact commercial
Réduction des coûts d’API : Jusqu’à 10× moins de jetons traités pour les documents typiques signifie des économies de coûts spectaculaires : une entreprise traitant 1 million de pages par mois pourrait économiser plus de 50 000 $ par an.
Traitement plus rapide : Moins de jetons se traduisent directement par des temps de réponse plus courts, améliorant l’expérience utilisateur et permettant des applications en temps réel.
Meilleure scalabilité : Traitez 10× plus de documents avec le même investissement en infrastructure, rendant la croissance plus prévisible et abordable.
Efficacité de la mémoire : Stockez l’historique des conversations sous forme d’images compressées, permettant des applications à contexte ultra-long sans exigences de mémoire exponentielles.
Performances et benchmarks
Résultats complets d’OmniDocBench
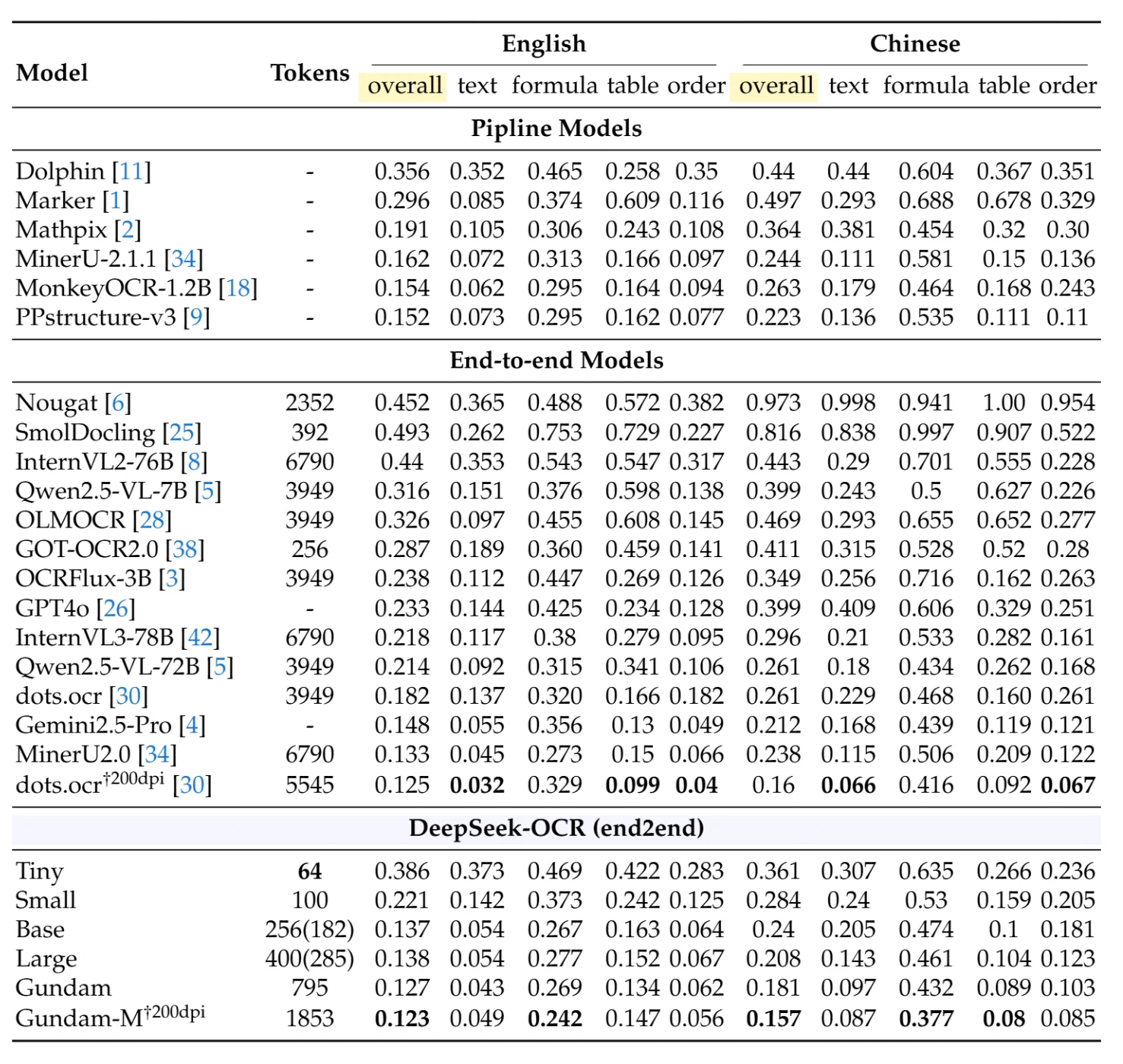
Sur OmniDocBench, un benchmark complet d’analyse de documents, DeepSeek-OCR obtient des performances exceptionnelles avec une utilisation minimale des ressources. Le tableau ci-dessous présente des comparaisons détaillées selon différents types de documents et langues (distance d’édition - plus c’est bas, mieux c’est) :
Points clés :
Modèles Pipeline (approches multi-étapes traditionnelles) : Le meilleur modèle pipeline, PPstructure-v3, obtient un score global de 0,152 en anglais et 0,223 en chinois, mais nécessite une infrastructure multi-modèles complexe.
Modèles de bout en bout (approches mono-modèle) : Parmi les concurrents, MinerU2.0 utilisant 6 790 jetons obtient 0,133 en anglais et 0,238 en chinois. Qwen2.5-VL-72B avec 3 949 jetons obtient un score de 0,214 en anglais et 0,261 en chinois.
Performances de DeepSeek-OCR :
- Mode Small (100 jetons) : 0,221 global en anglais, 0,284 global en chinois
- Mode Base (256 jetons) : 0,137 global en anglais, 0,240 global en chinois
- Mode Gundam (795 jetons) : 0,127 global en anglais, 0,181 global en chinois
- Gundam-M à 200 ppp (1 853 jetons) : 0,123 global en anglais, 0,157 global en chinois - obtient des résultats de pointe
Réalisation remarquable : Le mode Base de DeepSeek-OCR avec seulement 256 jetons surpasse les modèles utilisant 15 à 26× plus de jetons. Le mode Gundam-M obtient les meilleures performances globales parmi tous les modèles de bout en bout tout en utilisant toujours considérablement moins de jetons que les approches traditionnelles.
Performances par catégorie
Reconnaissance de texte : DeepSeek-OCR (Gundam-M) obtient 0,049 sur le texte anglais et 0,087 sur le texte chinois, surpassant même Gemini2.5-Pro.
Reconnaissance de formules : Avec 0,242 sur les formules anglaises et 0,377 sur les formules chinoises, DeepSeek-OCR démontre une forte capacité sur le contenu mathématique.
Extraction de tableaux : Les scores de 0,147 sur les tableaux anglais et 0,08 sur les tableaux chinois montrent une extraction robuste de données structurées.
Capacités de production
Vitesse de traitement : Un seul GPU A100-40G peut traiter plus de 200 000 pages par jour. À l’échelle de 20 nœuds (160 GPU), vous obtenez 33 millions de pages par jour, de quoi répondre aux charges de travail enterprise les plus exigeantes.
Efficacité des coûts : Pour une entreprise traitant 1 million de pages de documents par mois, la différence est frappante. Les modèles traditionnels nécessitant 6 000 jetons par page consomment 6 milliards de jetons au total. DeepSeek-OCR à 800 jetons par page n’utilise que 800 millions de jetons, soit une réduction de 87 % de l’utilisation des jetons et des coûts associés.
Fonctionnalités et capacités clés
1. Prise en charge multilingue
DeepSeek-OCR prend en charge près de 100 langues, des langues mondiales majeures (anglais, chinois, espagnol, arabe, hindi) aux écritures spécialisées (thaï, hébreu, cyrillique). Cela élimine le besoin de services OCR spécifiques à une langue et simplifie les opérations internationales.
2. Compréhension avancée des documents
Le modèle reconnaît bien plus que du simple texte. Il analyse les graphiques en données structurées, extrait les formules mathématiques avec formatage LaTeX, identifie les figures géométriques avec sortie SVG et maintient les structures de tableaux incluant les cellules fusionnées et la mise en forme complexe.
3. Formats de sortie flexibles
Choisissez entre l’extraction de texte pur (la plus rapide), le markdown avec mise en forme préservée, le HTML pour l’intégration web ou le JSON structuré pour le traitement programmatique. Le mode grounding préserve les relations spatiales, garantissant que vos données extraites conservent la structure du document d’origine.
4. Compression optique pour les contextes longs
Stockez l’historique des conversations sous forme d’images compressées au lieu de jetons de texte. Une conversation de 10 tours qui consommerait traditionnellement 10 000 jetons peut être compressée en 1 000 jetons visuels, permettant des applications avec des fenêtres de contexte ultra-longues à des coûts durables.
L’impact : Les applications de chat peuvent maintenir le contexte sur des centaines de tours de conversation sans augmentation exponentielle des coûts, permettant des interactions IA véritablement longues.
Commencer sur Novita AI
Comprendre les modes de résolution
Novita AI propose DeepSeek-OCR avec cinq modes de résolution conçus pour équilibrer performance, vitesse et coût pour différents cas d’usage.
Modes de résolution natifs :
Mode Tiny (512×512, 64 jetons) : Optimisé pour les documents simples où la vitesse maximale est la priorité. Parfait pour les reçus, les formulaires simples ou les tâches d’extraction de texte rapide.
Mode Small (640×640, 100 jetons) : Le juste milieu pour la plupart des applications. Offre le meilleur équilibre entre précision, vitesse et coût. Idéal pour les documents d’entreprise standard, les factures et les rapports.
Mode Base (1024×1024, 256 jetons) : Gère les mises en page complexes avec des rapports d’aspect préservés grâce au remplissage. Recommandé pour les contrats, les rapports détaillés et les documents où la mise en page est importante.
Mode Large (1280×1280, 400 jetons) : Qualité maximale pour les documents détaillés haute résolution. Idéal pour les articles de recherche, les documents techniques avec des formules et les exigences de qualité premium.
Mode de résolution dynamique :
Mode Gundam (n×640×640 + 1×1024×1024, jetons variables) : Découpage adaptatif pour les documents ultra-haute résolution. Divise automatiquement les grandes images en 2 à 9 vues locales de 640×640 plus une vue globale de 1024×1024. Essentiel pour les journaux, les magazines et les mises en page multi-colonnes complexes. Pour les images de moins de 640×640, il passe automatiquement en mode Base.
Accéder à l’API DeepSeek-OCR
Novita AI propose une API REST simple pour DeepSeek-OCR. Pour commencer, inscrivez-vous sur un compte Novita AI et obtenez votre clé API. Le point d’accès de l’API accepte des URL d’images ou des images encodées en base64 ainsi que des paramètres de configuration comme le mode de résolution, la préférence de langue et le format de sortie.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="<Your API Key>",
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
},
{
"type": "text",
"text": "<|grounding|>OCR this image."
}
]
}
],
stream=False,
max_tokens=4096
)
content = response.choices[0].message.content
print(content)
Modèles d’utilisation de base
Pour une extraction de texte simple où la mise en forme n’a pas d’importance, utilisez le mode « Free OCR ». Pour une analyse de document structurée qui préserve la mise en page, les tableaux et la mise en forme, utilisez le mode « grounding » avec sortie markdown. Pour une analyse avancée de graphiques, de formules ou de figures géométriques, utilisez l’invite « Parse the figure ».
Guide de résolution
Choisir le bon mode
Pour les factures, les reçus et les formulaires simples : Le mode Small (100 jetons) est votre meilleur choix. Il est rapide, rentable et offre une précision suffisante pour l’extraction de données structurées. Il couvre la plupart des besoins de traitement de documents d’entreprise courants.
Pour les documents d’entreprise, les rapports et les contrats : Le mode Base (256 jetons) gère bien les mises en page complexes et préserve les rapports d’aspect grâce au remplissage. C’est le bon équilibre lorsque la structure et la mise en forme du document sont importantes.
Pour les articles de recherche et les documents techniques : Le mode Large (400 jetons) offre la précision nécessaire pour les textes denses, les formules mathématiques et les diagrammes techniques. Le nombre de jetons plus élevé est justifié par les exigences de précision.
Pour les journaux, les magazines et les mises en page multi-colonnes : Le mode Gundam (jetons variables) est essentiel. Son découpage adaptatif gère les résolutions ultra-élevées et les mises en page multi-colonnes complexes qui seraient illisibles dans les modes de résolution fixes. Même s’il utilise plus de jetons, il reste bien plus efficace que les approches traditionnelles.
Informations sur les performances par type de document
Sur la base des tests complets d’OmniDocBench :
Diapositives et documents simples : Même le mode Tiny (64 jetons) obtient des résultats remarquables avec une distance d’édition de 0,116 sur les diapositives, tandis que le mode Small offre une valeur optimale. Cela s’explique par le fait que les diapositives de présentation ont généralement des mises en page claires et peu de texte par page.
Livres et documents standard : Le mode Small (100 jetons) offre une excellente valeur avec une distance d’édition de 0,085 pour les livres. La plupart des livres contiennent 600 à 1 000 jetons de texte par page, ce qui se situe parfaitement dans la fourchette optimale de compression 10×.
Articles académiques : Le mode Large ou le mode Gundam sont recommandés, le mode Gundam obtenant une distance d’édition de 0,039 sur les articles académiques, surpassant les modèles utilisant 5 à 8× plus de jetons.
Journaux : Le mode Gundam est essentiel, obtenant une distance d’édition de 0,122 contre 0,940 pour le mode Tiny. Les journaux contiennent 4 000 à 5 000 jetons de texte par page avec des mises en page multi-colonnes complexes qui nécessitent l’approche de découpage adaptatif.
Documents avec beaucoup de formules : Pour les documents contenant des formules mathématiques, le mode Gundam-M obtient les meilleures performances avec une distance d’édition de 0,242 sur les formules anglaises, compétitif avec les grands modèles spécialisés.
Comprendre le mode Gundam en détail
Le mode Gundam fonctionne en créant plusieurs vues locales (2 à 9 tuiles de 640×640) qui capturent les régions détaillées, plus une vue globale (1024×1024) qui maintient le contexte global. Le nombre total de jetons est calculé comme n×100 + 256, où n est le nombre de tuiles.
Quand utiliser le mode Gundam : Utilisez-le pour les images de plus de 1280 pixels dans n’importe quelle dimension, les documents avec des mises en page multi-colonnes, le contenu avec plus de 4 000 jetons de texte ou les infographies complexes qui ont besoin à la fois de détails et de contexte.
Exemple concret : Une petite page de journal peut utiliser 3 tuiles (556 jetons au total), tandis qu’une grande page de journal utilise 6 tuiles (856 jetons). Comparez cela aux approches traditionnelles nécessitant plus de 6 000 jetons : vous obtenez toujours une compression de 7 à 10× même sur les documents les plus complexes.
Conclusion
DeepSeek-OCR sur Novita AI atteint une compression 10× avec 97 % de précision, réduisant les coûts de traitement des documents jusqu’à 85 % tout en prenant en charge 100 langues et en traitant plus de 200 000 pages par GPU par jour.
Les résultats parlent d’eux-mêmes : Les entreprises traitant 100 000 documents par mois économisent plus de 50 000 $ par an. Les vitesses de traitement s’améliorent de 5 à 10×. L’infrastructure évolue de manière linéaire au lieu d’exponentielle.
Prêt à transformer votre traitement de documents ?
Commencez gratuitement dans le playground →
Testez DeepSeek-OCR avec vos propres documents en quelques minutes. Aucune carte de crédit requise. Choisissez parmi cinq modes de résolution, traitez des documents dans 100 langues et découvrez par vous-même la compression 10×.
Novita AI est une plateforme cloud IA leader qui fournit aux développeurs des API faciles à utiliser et une infrastructure GPU abordable et fiable pour construire et mettre à l’échelle des applications IA.



