

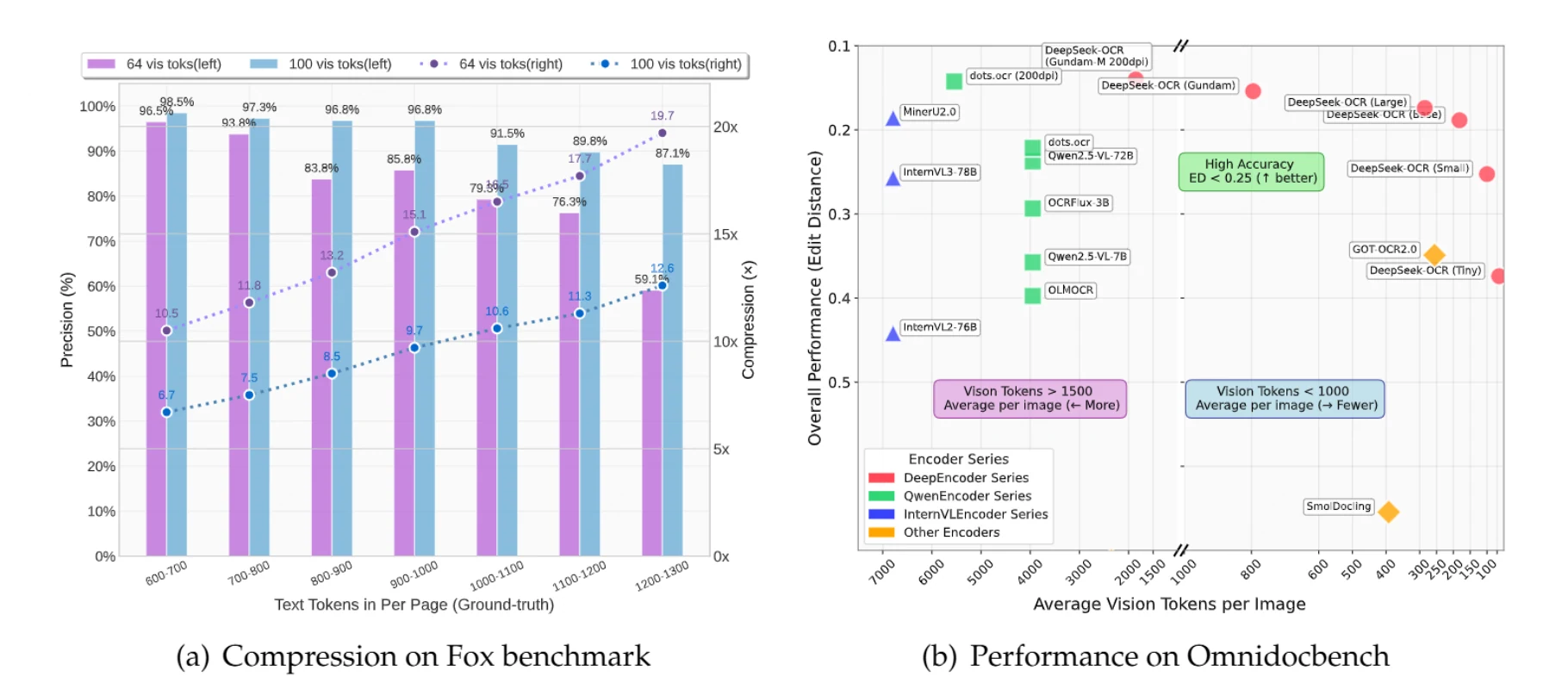
DeepSeek-OCR обеспечивает 10-кратное сжатие текста с точностью 97%, обрабатывая изображения как сжатое хранилище для текста. Вместо обработки 1000 текстовых токенов по отдельности модель обрабатывает их как единое изображение, используя всего 100 визионных токенов — что снижает затраты до 85%.
Теперь доступный на Novita AI, DeepSeek-OCR обрабатывает более 200 000 страниц в день на один GPU, поддерживает 100 языков и предлагает пять режимов разрешения (от 64 до более чем 400 токенов). Он выходит за рамки традиционного OCR: парсит диаграммы в структурированные данные, распознает химические формулы, извлекает геометрические фигуры и обеспечивает инновационное управление памятью для длинных диалогов.
Попробуйте прямо сейчас в песочнице Novita AI →
Что такое DeepSeek-OCR?
DeepSeek-OCR — это визуально-языковая модель, которая рассматривает изображения как сжатое хранилище для текста. Вместо обработки документа с 1000 текстовых токенов по отдельности (что вычислительно затратно), модель обрабатывает его как единое изображение, используя всего 100 визионных токенов — 10-кратное сокращение вычислительных затрат.
Основная архитектура
Модель состоит из двух ключевых компонентов:
DeepEncoder (~380 млн параметров): Специализированный визионный энкодер, который эффективно обрабатывает изображения документов, используя уникальную последовательную архитектуру, сочетающую оконное внимание (SAM) и глобальное внимание (CLIP) с 16-кратным слоем сжатия между ними.
Декодер DeepSeek3B-MoE (570 млн активных параметров): Компактная языковая модель смеси экспертов, которая преобразует сжатую визуальную информацию обратно в текст с высокой точностью.
Эта архитектура обеспечивает беспрецедентную эффективность при обработке документов, что делает её идеальной для бизнеса, работающего с большими объемами документов, или приложений, требующих понимания длинного контекста.
Почему важно оптическое сжатие
Традиционная проблема
Традиционная обработка текста в моделях ИИ масштабируется квадратично: удвоение длины документа может учетверить ваши затраты. Для бизнеса, обрабатывающего тысячи документов ежедневно, это становится неподъемно дорогим.
Решение DeepSeek-OCR
Документы объемом до 1000 текстовых токенов можно сжать в 10 раз с точностью 97%. Даже при 20-кратном сжатии точность остается на уровне около 60% — чего часто достаточно для многих приложений.
Реальный пример:
Документ, содержащий 900 текстовых токенов, при традиционном подходе требует 900 токенов для обработки. При использовании DeepSeek-OCR в режиме Small (100 визионных токенов) вы получаете 9,7-кратное сжатие с точностью 96,8%. Для документов с 1 100 текстовыми токенами вы получаете 10,6-кратное сжатие с точностью 91,5%.
Влияние на бизнес
Снижение затрат на API: Обработка до 10 раз меньшего количества токенов для типовых документов означает значительную экономию — бизнес, обрабатывающий 1 миллион страниц в месяц, может сэкономить более $50 000 в год.
Более быстрая обработка: Меньшее количество токенов напрямую приводит к более быстрому времени отклика, улучшая пользовательский опыт и позволяя работать с приложениями в реальном времени.
Улучшенная масштабируемость: Обрабатывайте в 10 раз больше документов при тех же вложениях в инфраструктуру, что делает рост более предсказуемым и доступным.
Эффективность использования памяти: Сохраняйте историю диалогов в виде сжатых изображений, что позволяет создавать приложения с ультрадлинным контекстом без экспоненциальных требований к памяти.
Производительность и бенчмарки
Итоги комплексного тестирования на OmniDocBench
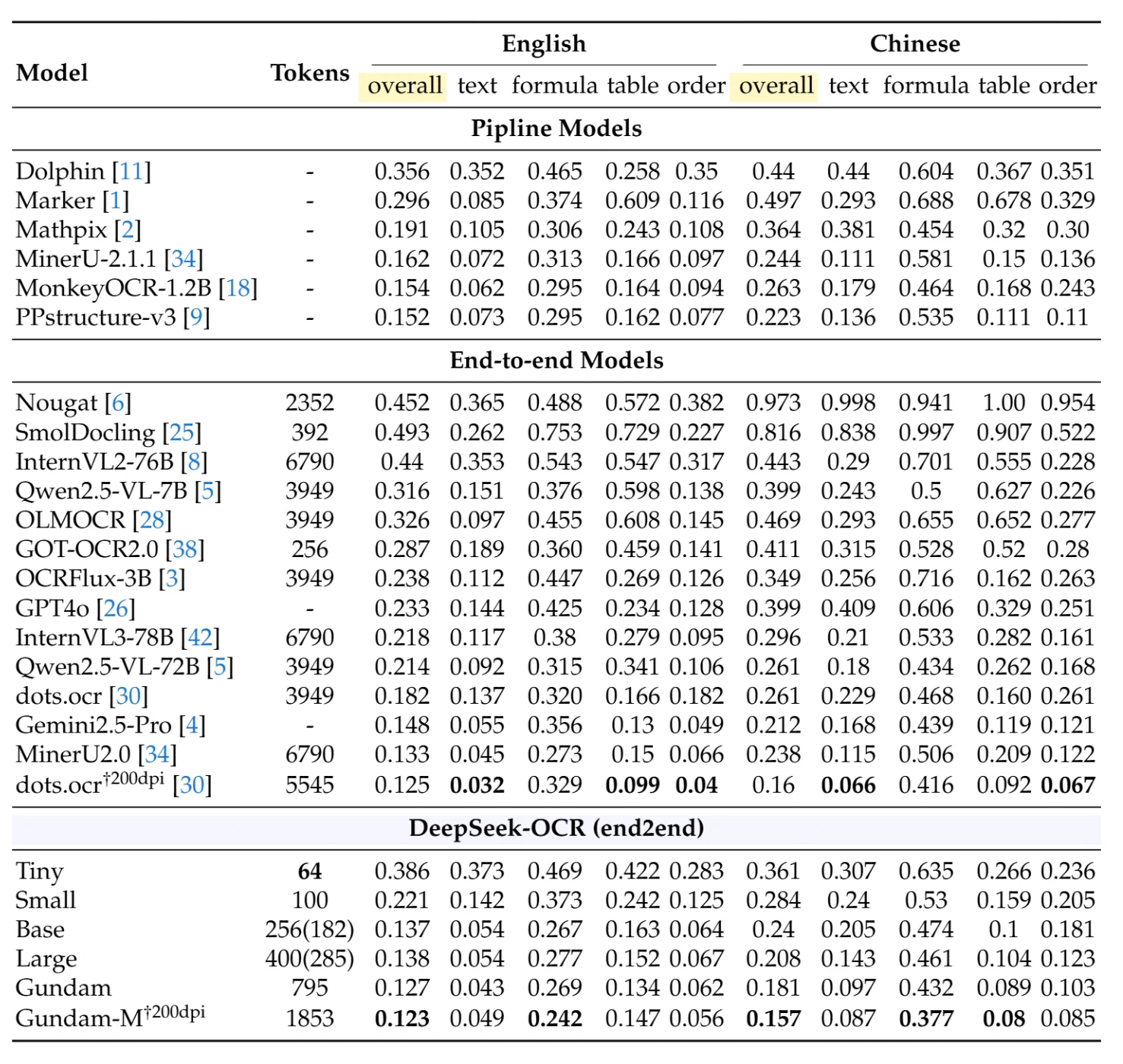
На OmniDocBench — комплексном бенчмарке для парсинга документов — DeepSeek-OCR показывает исключительную производительность при минимальном использовании ресурсов. В таблице ниже приведены детальные сравнения по разным типам документов и языкам (редакционное расстояние — чем ниже, тем лучше):
Ключевые особенности:
Конвейерные модели (традиционные многоэтапные подходы): Лучшая из конвейерных моделей, PPstructure-v3, достигает общего показателя 0,152 для английского и 0,223 для китайского языка, но требует сложной многомодельной инфраструктуры.
Модели end-to-end (одномодельные подходы): Среди конкурентов MinerU2.0, использующая 6 790 токенов, достигает 0,133 для английского и 0,238 для китайского. Qwen2.5-VL-72B с 3 949 токенами получает 0,214 для английского и 0,261 для китайского.
Производительность DeepSeek-OCR:
- Режим Small (100 токенов): общий показатель 0,221 для английского, 0,284 для китайского
- Режим Base (256 токенов): общий показатель 0,137 для английского, 0,240 для китайского
- Режим Gundam (795 токенов): общий показатель 0,127 для английского, 0,181 для китайского
- Gundam-M при 200 dpi (1 853 токена): общий показатель 0,123 для английского, 0,157 для китайского — достижение передовых результатов
Замечательное достижение: Режим Base DeepSeek-OCR всего с 256 токенами превосходит модели, использующие в 15–26 раз больше токенов. Режим Gundam-M достигает лучшей общей производительности среди всех end-to-end моделей, при этом используя значительно меньше токенов, чем традиционные подходы.
Производительность по отдельным категориям
Распознавание текста: DeepSeek-OCR (режим Gundam-M) достигает 0,049 для английского текста и 0,087 для китайского текста, превосходя даже Gemini2.5-Pro.
Распознавание формул: С показателями 0,242 для английских формул и 0,377 для китайских формул DeepSeek-OCR демонстрирует высокую эффективность в работе с математическим контентом.
Извлечение таблиц: Показатели 0,147 для английских таблиц и 0,08 для китайских таблиц свидетельствуют о надежном извлечении структурированных данных.
Производственные возможности
Скорость обработки: Один GPU A100-40G может обрабатывать более 200 000 страниц в день. При масштабировании до 20 узлов (160 GPU) вы получаете 33 миллиона страниц в день — достаточно для самых требовательных корпоративных нагрузок.
Эффективность затрат: Для бизнеса, обрабатывающего 1 миллион страниц документов в месяц, разница очевидна. Традиционные модели, требующие 6 000 токенов на страницу, потребляют в общей сложности 6 миллиардов токенов. DeepSeek-OCR при 800 токенов на страницу использует только 800 миллионов токенов — сокращение на 87% использования токенов и связанных с ними затрат.
Ключевые функции и возможности
1. Поддержка множества языков
DeepSeek-OCR поддерживает почти 100 языков — от основных мировых языков (английский, китайский, испанский, арабский, хинди) до специализированных письменностей (тайский, иврит, кириллица). Это исключает необходимость в OCR-сервисах для отдельных языков и упрощает международные операции.
2. Продвинутое понимание документов
Модель распознает гораздо больше, чем просто текст. Она парсит диаграммы в структурированные данные, извлекает математические формулы с форматированием LaTeX, идентифицирует геометрические фигуры с выводом в SVG и сохраняет структуру таблиц, включая объединенные ячейки и сложное форматирование.
3. Гибкие форматы вывода
Вы можете выбрать между чистым извлечением текста (самый быстрый), markdown с сохраненным форматированием, HTML для веб-интеграции или структурированным JSON для программной обработки. Режим grounding сохраняет пространственные соотношения, гарантируя, что извлеченные данные сохраняют структуру исходного документа.
4. Оптическое сжатие для длинного контекста
Сохраняйте историю диалогов в виде сжатых изображений вместо текстовых токенов. Диалог из 10 реплик, который при традиционном подходе потребляет 10 000 токенов, можно сжать до 1000 визионных токенов, что позволяет создавать приложения с ультрадлинными окнами контекста при устойчивых затратах.
Влияние: Чат-приложения могут сохранять контекст на протяжении сотен реплик диалога без экспоненциального роста затрат, что позволяет реализовать по-настоящему длинные взаимодействия с ИИ.
Начало работы на Novita AI
Понимание режимов разрешения
Novita AI предоставляет DeepSeek-OCR с пятью режимами разрешения, разработанными для баланса производительности, скорости и стоимости для разных сценариев использования.
Встроенные режимы разрешения:
Режим Tiny (512×512, 64 токена): Оптимизирован для простых документов, где приоритетом является максимальная скорость. Идеально подходит для чеков, простых форм или задач быстрого извлечения текста.
Режим Small (640×640, 100 токенов): Оптимальный выбор для большинства приложений. Обеспечивает лучший баланс точности, скорости и стоимости. Идеально подходит для стандартных бизнес-документов, счетов и отчетов.
Режим Base (1024×1024, 256 токенов): Обрабатывает сложные макеты с сохранением пропорций с использованием дополнения (padding). Рекомендуется для контрактов, детализированных отчетов и документов, где важна структура макета.
Режим Large (1280×1280, 400 токенов): Максимальное качество для детализированных документов с высоким разрешением. Лучший выбор для научных работ, технических документов с формулами и задач, требующих премиального качества.
Динамический режим разрешения:
Режим Gundam (n×640×640 + 1×1024×1024, переменное количество токенов): Адаптивная разбивка на плитки для документов с ультравысоким разрешением. Автоматически разделяет большие изображения на 2–9 локальных фрагментов размером 640×640 плюс один глобальный фрагмент 1024×1024. Необходим для газет, журналов и сложных многоколоночных макетов. Для изображений размером меньше 640×640 режим автоматически переключается на Base.
Доступ к API DeepSeek-OCR
Novita AI предоставляет простой REST API для DeepSeek-OCR. Для начала работы зарегистрируйте аккаунт на Novita AI и получите ваш API-ключ. Эндпоинт API принимает URL изображений или изображения в кодировке base64, а также конфигурационные параметры, такие как режим разрешения, предпочтительный язык и формат вывода.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="<Your API Key>",
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
},
{
"type": "text",
"text": "<|grounding|>OCR this image."
}
]
}
],
stream=False,
max_tokens=4096
)
content = response.choices[0].message.content
print(content)
Основные шаблоны использования
Для простого извлечения текста, когда форматирование не важно, используйте режим «Free OCR». Для структурированного парсинга документов с сохранением макета, таблиц и форматирования используйте режим «grounding» с выводом в markdown. Для продвинутого парсинга диаграмм, формул или геометрических фигур используйте запрос «Parse the figure».
Руководство по выбору разрешения
Выбор подходящего режима
Для счетов, чеков и простых форм: Режим Small (100 токенов) — лучший выбор. Он быстрый, экономичный и обеспечивает достаточную точность для извлечения структурированных данных. Он покрывает большинство потребностей в обработке стандартных бизнес-документов.
Для бизнес-документов, отчетов и контрактов: Режим Base (256 токенов) хорошо справляется со сложными макетами и сохраняет пропорции с использованием дополнения. Это оптимальный баланс, когда важны структура и форматирование документа.
Для научных работ и технических документов: Режим Large (400 токенов) обеспечивает точность, необходимую для плотного текста, математических формул и технических диаграмм. Большее количество токенов оправдано требованиями к точности.
Для газет, журналов и многоколоночных макетов: Необходим режим Gundam (переменное количество токенов). Его адаптивная разбивка на плитки справляется с ультравысоким разрешением и сложными многоколоночными макетами, которые в режимах с фиксированным разрешением были бы искажены. Хотя он использует больше токенов, он все равно гораздо эффективнее традиционных подходов.
Анализ производительности по типам документов
На основе комплексного тестирования на OmniDocBench:
Слайды и простые документы: Даже режим Tiny (64 токена) показывает отличные результаты с редакционным расстоянием 0,116 на слайдах, а режим Small предлагает оптимальную эффективность. Это связано с тем, что слайды презентаций обычно имеют четкий макет и ограниченное количество текста на страницу.
Книги и стандартные документы: Режим Small (100 токенов) предлагает отличную эффективность с редакционным расстоянием 0,085 для книг. Большинство книг содержат 600–1 000 текстовых токенов на страницу, что полностью попадает в оптимальный диапазон 10-кратного сжатия.
Научные работы: Рекомендуются режим Large или Gundam, при этом Gundam достигает редакционного расстояния 0,039 на научных работах — превосходя модели, использующие в 5–8 раз больше токенов.
Газеты: Необходим режим Gundam, который достигает редакционного расстояния 0,122 против 0,940 для режима Tiny. Газеты содержат 4 000–5 000 текстовых токенов на страницу со сложными многоколоночными макетами, которые требуют адаптивной разбивки на плитки.
Документы с большим количеством формул: Для документов с математическими формулами режим Gundam-M достигает лучшей производительности с редакционным расстоянием 0,242 для английских формул, что конкурирует со специализированными крупными моделями.
Подробное описание режима Gundam
Режим Gundam работает путем создания нескольких локальных фрагментов (2–9 плиток размером 640×640), которые захватывают детализированные области, плюс один глобальный фрагмент (1024×1024), который сохраняет общий контекст. Общее количество токенов рассчитывается по формуле n×100 + 256, где n — количество плиток.
Когда использовать режим Gundam: Используйте его для изображений, размер которых по любой стороне превышает 1280 пикселей, документов с многоколоночными макетами, контента с более чем 4 000 текстовых токенов или сложных инфографик, для которых нужны как детали, так и общий контекст.
Реальный пример: Маленькая страница газеты может использовать 3 плитки (всего 556 токенов), а большая страница газеты — 6 плиток (856 токенов). Сравните это с традиционными подходами, требующими более 6 000 токенов — вы все равно получаете 7–10-кратное сжатие даже на самых сложных документах.
Заключение
DeepSeek-OCR на Novita AI обеспечивает 10-кратное сжатие с точностью 97%, сокращая затраты на обработку документов до 85%, при поддержке 100 языков и обработке более 200 000 страниц на GPU в день.
Результаты говорят сами за себя: Компании, обрабатывающие 100 000 документов в месяц, экономят более $50 000 в год. Скорость обработки увеличивается в 5–10 раз. Инфраструктура масштабируется линейно, а не экспоненциально.
Готовы трансформировать обработку ваших документов?
Начните бесплатно в песочнице →
Протестируйте DeepSeek-OCR на ваших собственных документах за несколько минут. Кредитная карта не требуется. Выберите один из пяти режимов разрешения, обрабатывайте документы на 100 языков и лично испытайте 10-кратное сжатие.
Novita AI — ведущая облачная ИИ-платформа, которая предоставляет разработчикам простые в использовании API и доступную, надежную GPU-инфраструктуру для создания и масштабирования ИИ-приложений.



