

DeepSeek-OCR 透過將圖片作為文字的壓縮儲存媒介,實現 10 倍文字壓縮與 97% 準確率。傳統方式需要個別處理 1,000 個文字權杖(token),而它僅用 100 個視覺權杖即可將相同內容作為單張圖片處理,最多可降低 85% 的成本。
現在已上線 Novita AI,DeepSeek-OCR 單張 GPU 每日可處理 超過 20 萬頁文件,支援 100 種語言,並提供五種解析度模式(權杖數從 64 到 400+ 不等)。它超越了傳統 OCR 的功能,可將圖表解析為結構化數據、辨識化學公式、提取幾何圖形,並支援長對話的創新記憶體管理。
什麼是 DeepSeek-OCR?
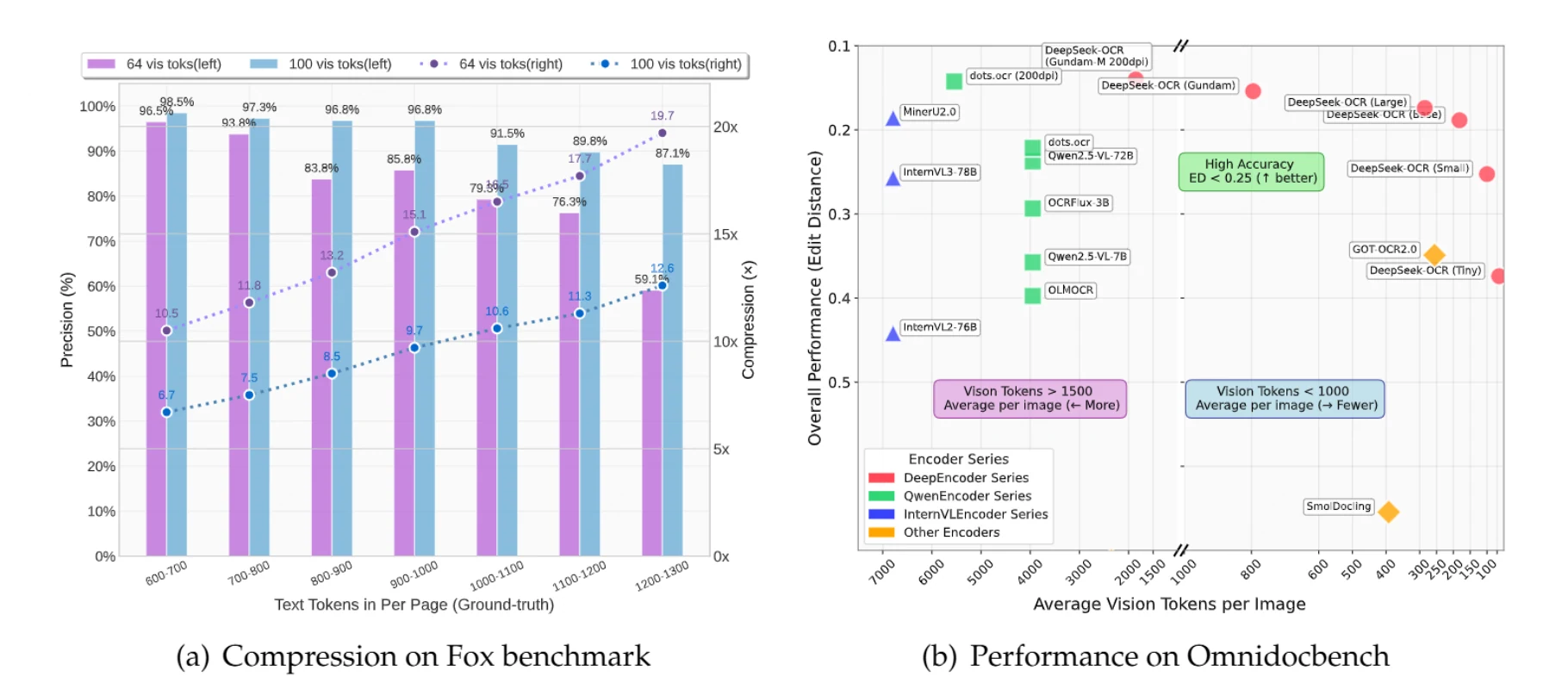
DeepSeek-OCR 是一款視覺語言模型,將圖片作為文字的壓縮儲存媒介。傳統方式個別處理含有 1,000 個文字權杖的文件運算成本極高,而該模型僅用 100 個視覺權杖即可將文件作為單張圖片處理,實現處理成本 降低 10 倍。
核心架構
該模型由兩個核心元件組成:
DeepEncoder(約 3.8 億個參數):這是一款專用視覺編碼器,採用獨特的串行架構高效處理文件圖片,結合了窗口注意力機制(SAM)與全局注意力機制(CLIP),兩者之間設有 16 倍壓縮層。
DeepSeek3B-MoE 解碼器(5,700 萬個活躍參數):這是一款緊湊的混合專家語言模型,能將壓縮後的視覺資訊以極高準確率轉換回文字。
這項架構實現了前所未有的文件處理效率,非常適合處理大量文件的企業,或需要長上下文理解能力的應用場景。
為什麼光學壓縮至關重要
傳統方案的痛點
AI 模型的傳統文字處理成本呈二次曲線增長——文件長度翻倍,成本就會翻四倍。對於每日處理數千份文件的企業而言,這種成本幾乎難以承受。
DeepSeek-OCR 的解決方案
長度在 1,000 個文字權杖以內的文件,可實現 10 倍壓縮且保持 97% 的準確率。即使壓縮倍率達到 20 倍,準確率仍能維持在 60% 左右,足以滿足多數應用場景的需求。
實際案例:
一份含有 900 個文字權杖的文件,傳統方式需要消耗 900 個權杖來處理。使用 DeepSeek-OCR 的小型模式(100 個視覺權杖)時,可實現 9.7 倍壓縮,準確率達 96.8%。而對於含有 1,100 個文字權杖的文件,則可實現 10.6 倍壓縮,準確率達 91.5%。
商業價值
降低 API 成本:一般文件處理所需的權杖數量最多可減少 10 倍,意味著可大幅節省成本——每月處理 100 萬頁文件的企業,每年可節省超過 5 萬美元。
更快的處理速度:權杖數量減少直接對應更短的回應時間,提升使用者體驗,並支援即時應用場景。
更優的擴展性:以相同的基礎設施投入即可處理 10 倍數量的文件,讓業務成長更具預測性、成本更低。
更高的記憶體效率:可將對話歷史記錄以壓縮圖片的形式儲存,實現超長上下文應用,且不會產生指數級增長的記憶體需求。
效能與基準測試
綜合 OmniDocBench 測試結果
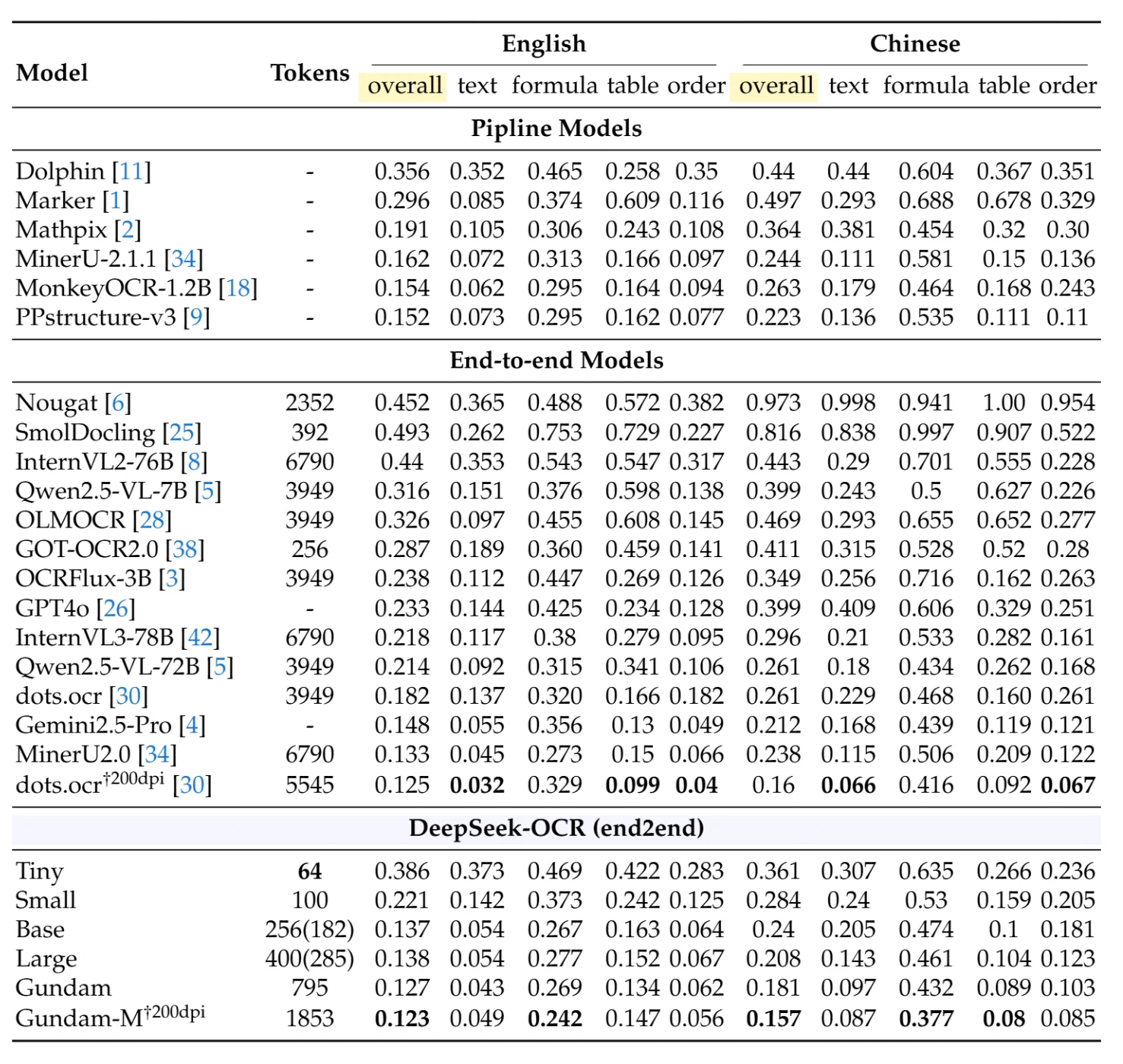
在綜合文件解析基準測試 OmniDocBench 中,DeepSeek-OCR 以極低的資源消耗實現了卓越效能。下表展示了不同文件類型與語言的詳細對比(編輯距離越低越好):
重點摘要:
管線式模型(傳統多階段方案):表現最佳的管線式模型 PPstructure-v3,英文整體得分為 0.152,中文為 0.223,但需要複雜的多模型基礎設施支援。
端到端模型(單模型方案):競爭對手中,使用 6,790 個權杖的 MinerU2.0 英文得分為 0.133,中文為 0.238;使用 3,949 個權杖的 Qwen2.5-VL-72B 英文得分為 0.214,中文得分為 0.261。
DeepSeek-OCR 效能表現:
- 小型模式(100 個權杖):英文整體得分 0.221,中文整體得分 0.284
- 基礎模式(256 個權杖):英文整體得分 0.137,中文整體得分 0.240
- Gundam 模式(795 個權杖):英文整體得分 0.127,中文整體得分 0.181
- 200dpi 下的 Gundam-M 模式(1,853 個權杖):英文整體得分 0.123,中文整體得分 0.157——達到業界領先水準
卓越成就:DeepSeek-OCR 的基礎模式僅使用 256 個權杖,表現卻優於使用 15-26 倍權杖的其他模型。Gundam-M 模式則在所有端到端模型中實現了最佳整體效能,且使用的權杖數量仍遠少於傳統方案。
分類別效能表現
文字辨識:DeepSeek-OCR(Gundam-M 模式)英文文字辨識得分達 0.049,中文達 0.087,表現甚至優於 Gemini2.5-Pro。
公式辨識:英文公式辨識得分達 0.242,中文達 0.377,展現了 DeepSeek-OCR 在數學內容處理上的強勁能力。
表格提取:英文表格提取得分達 0.147,中文達 0.08,展現了其穩健的結構化數據提取能力。
生產環境能力
處理速度:單張 A100-40G GPU 每日可處理超過 20 萬頁文件。擴展至 20 個節點(共 160 張 GPU)時,每日可處理 3,300 萬頁文件,足以應對最嚴峻的企業工作量需求。
成本效益:對於每月處理 100 萬頁文件的企業而言,差異極為明顯。傳統模型每頁需要 6,000 個權杖,總共消耗 60 億個權杖;而 DeepSeek-OCR 每頁僅需 800 個權杖,總共僅消耗 8 億個權杖,權杖使用量與相關成本 降低 87%。
核心功能與特性
1. 多語言支援
DeepSeek-OCR 支援將近 100 種語言,涵蓋全球主要語言(英語、中文、西班牙語、阿拉伯語、印地語)以及特殊文字系統(泰語、希伯來語、西里爾字母等)。這無需再使用針對特定語言的 OCR 服務,簡化了國際業務的操作流程。
2. 進階文件理解能力
該模型的能力遠不止文字辨識:可將圖表解析為結構化數據、提取帶有 LaTeX 格式的數學公式、識別並輸出 SVG 格式的幾何圖形,還能保留包含合併儲存格與複雜格式的表格結構。
3. 彈性的輸出格式
可選擇純文字提取(速度最快)、保留格式的 Markdown、適用於網頁整合的 HTML,或適用於程式化處理的結構化 JSON。grounding 模式會保留空間對應關係,確保提取的數據維持原文件的結構。
4. 適用於長上下文的光學壓縮
可將對話歷史記錄以壓縮圖片的形式儲存,而非傳統的文字權杖。傳統方式下 10 輪對話會消耗 10,000 個權杖,使用此技術後可壓縮至 1,000 個視覺權杖,以可負擔的成本實現超長上下文視窗的應用場景。
影響:聊天應用程式可維持數百輪對話的上下文,且成本不會呈指數級增長,實現真正的長篇 AI 互動體驗。
在 Novita AI 上快速上手
了解解析度模式
Novita AI 為 DeepSeek-OCR 提供了 五種解析度模式,針對不同使用場景平衡效能、速度與成本。
原生解析度模式:
微型模式(512×512,64 個權杖):針對速度優先的簡單文件優化,非常適合收據、簡單表單或快速文字提取任務。
小型模式(640×640,100 個權杖):多數應用場景的最佳選擇,在準確率、速度與成本之間實現最佳平衡,非常適合標準商業文件、發票與報告。
基礎模式(1024×1024,256 個權杖):透過填充保留長寬比,可處理複雜排版,推薦用於合約、詳細報告或排版重要的文件。
大型模式(1280×1280,400 個權杖):適用於高解析度詳細文件,能實現最高品質,非常適合學術論文、包含公式的技術文件,或對品質要求極高的場景。
動態解析度模式:
Gundam 模式(n×640×640 + 1×1024×1024,權杖數可變):針對超高解析度文件的適應性切片技術,會自動將大圖片分割為 2-9 個 640×640 的局部視圖,加上一個 1024×1024 的全局視圖。非常適合報紙、雜誌與複雜的多欄排版文件。對於解析度小於 640×640 的圖片,會自動降級為基礎模式。
存取 DeepSeek-OCR API
Novita AI 為 DeepSeek-OCR 提供了簡易的 REST API。開始使用前,請註冊 Novita AI 帳號並取得您的 API 金鑰。API 端點接受圖片網址或 base64 編碼的圖片,以及解析度模式、語言偏好、輸出格式等配置參數。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="<Your API Key>",
)
response = client.chat.completions.create(
model="deepseek/deepseek-ocr",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/image.png"
}
},
{
"type": "text",
"text": "<|grounding|>OCR this image."
}
]
}
],
stream=False,
max_tokens=4096
)
content = response.choices[0].message.content
print(content)
基本使用模式
若只需提取文字且不要求保留格式,可使用「Free OCR」模式;若需要保留排版、表格與格式的結構化文件解析,請使用搭配 Markdown 輸出的「grounding」模式;若需要進階解析圖表、公式或幾何圖形,請使用「Parse the figure」提示詞。
解析度選擇指南
選擇適合的模式
發票、收據與簡單表單:小型模式(100 個權杖)是最佳選擇,速度快、成本低,且能提供足夠的結構化數據提取準確率,可滿足多數常規商業文件處理需求。
商業文件、報告與合約:基礎模式(256 個權杖)能良好處理複雜排版,並透過填充保留長寬比,在文件結構與格式重要的場景下能實現最佳平衡。
學術論文與技術文件:大型模式(400 個權杖)能提供密集文字、數學公式與技術圖表所需的準確率,更高的權杖消耗符合精度的要求。
報紙、雜誌與多欄排版文件:Gundam 模式(權杖數可變)是必選方案,其適應性切片技術能處理超高解析度與複雜多欄排版,這類文件在固定解析度模式下會出現排版混亂。雖然它消耗的權杖較多,但效率仍遠高於傳統方案。
不同文件類型的效能分析
基於綜合 OmniDocBench 測試結果:
簡報與簡單文件:即使是微型模式(64 個權杖),在簡報上的編輯距離也僅有 0.116,表現優異;小型模式則性價比最高。這是因為簡報通常排版清晰,每頁文字數量有限。
書籍與標準文件:小型模式(100 個權杖)在書籍處理上的編輯距離為 0.085,性價比極高。多數書籍每頁含有 600-1,000 個文字權杖,正好處於 10 倍壓縮的最佳區間內。
學術論文:推薦使用大型模式或 Gundam 模式,其中 Gundam 模式在學術論文上的編輯距離僅有 0.039,表現優於使用 5-8 倍權杖的其他模型。
報紙:Gundam 模式是必選方案,在報紙處理上的編輯距離為 0.122,遠優於微型模式的 0.940。報紙每頁含有 4,000-5,000 個文字權杖,且排版複雜多欄,需要適應性切片技術才能處理。
包含大量公式的文件:對於包含數學公式的文件,Gundam-M 模式表現最佳,英文公式編輯距離僅有 0.242,與專用大型模型相比毫不遜色。
深入了解 Gundam 模式
Gundam 模式的工作原理是建立多個局部視圖(2-9 個 640×640 的切片)來捕捉細節區域,再加上一個 1024×1024 的全局視圖來保留整體上下文。總權杖數計算方式為 n×100 + 256,其中 n 為切片數量。
Gundam 模式適用場景:當圖片任一維度解析度大於 1280 像素、文件為多欄排版、內容含有 4,000 個以上文字權杖,或需要同時保留細節與上下文的複雜資訊圖表時,請使用此模式。
實際案例:一張小型報紙頁面可能使用 3 個切片(總共 556 個權杖),而大型報紙頁面使用 6 個切片(總共 856 個權杖)。與傳統方案需要 6,000 個以上權杖相比,即使是最複雜的文件,仍能實現 7-10 倍的壓縮率。
總結
Novita AI 上的 DeepSeek-OCR 實現了 10 倍壓縮與 97% 準確率,在支援 100 種語言、單張 GPU 每日可處理超過 20 萬頁文件的同時,最多可降低 85% 的文件處理成本。
成效有目共睹:每月處理 10 萬份文件的企業,每年可節省超過 5 萬美元。處理速度提升 5-10 倍,基礎設施擴展方式從指數級變為線性。
準備好轉型您的文件處理流程了嗎?
幾分鐘內即可使用您自己的文件測試 DeepSeek-OCR,無需提供信用卡。可從五種解析度模式中選擇,支援 100 種語言的文件處理,親身體驗 10 倍壓縮的優勢。
Novita AI 是領先的 AI 雲端平台,為開發者提供易於使用的 API 與高性價比、可靠的 GPU 基礎設施,協助建構與擴展 AI 應用。



