

- O que é o MiniMax M3?
- O que mudou agora que o M3 está disponível no Novita AI?
- Especificações da API Novita e ID do modelo
- Como usar o MiniMax M3 no Novita AI
- Principais capacidades para desenvolvedores
- Benchmarks e notas de avaliação
- Notas de preços e verificações de custo
- MiniMax M3 vs MiniMax M2.7, M2 e M1
- Onde o MiniMax M3 se encaixa
- Quando o MiniMax M3 pode não ser a escolha certa
- FAQ
- Artigos recomendados
O MiniMax M3 está disponível no Novita AI como minimax/minimax-m3. Isso torna o lançamento mais do que apenas uma ficha técnica de modelo: os desenvolvedores podem testar o M3 através da API compatível com OpenAI do Novita e ver como ele se comporta em tarefas como revisão de grandes bases de código, fluxos de trabalho agenticos com muitas ferramentas, planejamento de contexto longo e entrada multimodal que exigem uma resposta textual.
O que é o MiniMax M3?
O MiniMax M3 é um modelo mais recente da série M da MiniMax, voltado para codificação, raciocínio agentico, uso de ferramentas, trabalho com contexto longo e compreensão de entrada multimodal. No Novita AI, ele está disponível como o modelo de chat serverless minimax/minimax-m3.
O motivo para testá-lo é simples: o M3 oferece muito espaço para carregar o contexto do projeto e pode ler texto, imagens e vídeo, retornando texto. Essa combinação é útil quando uma tarefa possui mais de um tipo de evidência: arquivos fonte, logs, capturas de tela, notas de design ou um breve vídeo de demonstração do produto.
Para os usuários, o limite prático é simples: use o M3 para entender entradas mistas e devolver análises baseadas em texto, planos, explicações ou sugestões de código. Ele não é um gerador de imagens nem de vídeos. Teste-o com seus próprios critérios de aceitação antes de usar sua saída em produção.
O que mudou agora que o M3 está disponível no Novita AI?
O MiniMax M3 está disponível no Novita AI como minimax/minimax-m3. Você pode acessar a página do modelo MiniMax-M3 para ver a listagem ativa e, em seguida, chamá-lo através do endpoint de completions de chat compatível com OpenAI do Novita.
Para um primeiro teste, use o ID do modelo, URL base, endpoint, modalidades suportadas, limites de contexto e saída abaixo e execute a pequena requisição Python ou curl na seção “Como usar”.
Se sua stack já utiliza o padrão do SDK da OpenAI, você geralmente pode começar alterando a URL base, a chave da API e a string do modelo. Antes de implantar em produção, execute as mesmas verificações que você faria para qualquer migração de modelo: latência, uso de tokens, comportamento das ferramentas e custo em sua própria carga de trabalho.
Especificações da API Novita e ID do modelo
| ID do modelo Novita | minimax/minimax-m3 |
| Nome de exibição do modelo | MiniMax-M3 |
| Tipo de modelo | Chat |
| Tamanho do contexto | 1.000.000 tokens |
| Saída máxima | 131.072 tokens |
| Modalidades de entrada | Texto, imagem, vídeo |
| Modalidades de saída | Texto |
| Recursos suportados | Serverless, chamada de funções, saídas estruturadas, raciocínio |
| URL base compatível com OpenAI | https://api.novita.ai/openai |
| Endpoint de chat | /v1/chat/completions |
Use a página do modelo Novita para a listagem atual do MiniMax-M3 e consulte a referência da API quando precisar de detalhes sobre campos de requisição, autenticação ou parâmetros.
Como usar o MiniMax M3 no Novita AI
Use este caminho rápido quando quiser testar o MiniMax M3 através da API compatível com OpenAI do Novita.
Passo 1: Abra a documentação da API LLM do Novita
Comece com o guia da API LLM do Novita para o padrão de integração. Mantenha a Referência da API de Criar Completion de Chat por perto para campos de requisição, formato de resposta e parâmetros opcionais.
Passo 2: Prepare sua chave de API, URL base e ID do modelo
Para a primeira chamada, você precisa de três valores: sua chave de API do Novita, a URL base compatível com OpenAI https://api.novita.ai/openai e o ID do modelo minimax/minimax-m3. Mantenha a chave da API em uma variável de ambiente ou gerenciador de segredos, em vez de codificá-la no código da aplicação.
Passo 3: Execute uma requisição de teste em Python
Aqui está um exemplo mínimo em Python usando o padrão do SDK da OpenAI:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="minimax/minimax-m3",
messages=[
{
"role": "system",
"content": "Você é um assistente sênior de engenharia de software. Seja preciso e cite incertezas.",
},
{
"role": "user",
"content": "Revise este plano de migração e identifique os principais riscos de implementação.",
},
],
max_tokens=1200,
temperature=0.2,
)
print(response.choices[0].message.content)
Passo 4: Teste a mesma requisição com curl
Aqui está a mesma ideia com curl:
curl "https://api.novita.ai/openai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_NOVITA_API_KEY" \
-d '{
"model": "minimax/minimax-m3",
"messages": [
{
"role": "system",
"content": "Você é um assistente sênior de engenharia de software. Seja preciso e cite incertezas."
},
{
"role": "user",
"content": "Revise este plano de migração e identifique os principais riscos de implementação."
}
],
"max_tokens": 1200,
"temperature": 0.2
}'
Passo 5: Avalie com uma tarefa de codificação realista
Para a primeira avaliação, resista à tentação de pedir um aplicativo completo. Em vez disso, dê ao M3 uma tarefa pequena, mas realista: cinco arquivos relevantes, um teste com falha e um pedido para explicar a falha antes de propor a menor correção segura. Isso é um sinal melhor para qualidade de raciocínio, localidade do código e se o contexto longo está ajudando.
Principais capacidades para desenvolvedores
A maneira útil de ler as especificações do M3 não é como uma lista de verificação de grandes números. Cada capacidade aponta para um tipo diferente de carga de trabalho:
- Contexto de 1M de tokens: útil quando a tarefa precisa de mais do que um prompt e um arquivo, como revisão de repositório, longos históricos de issues, logs, especificações ou planos de migração. É menos útil se a tarefa for uma pergunta curta de codificação onde modelos menores já se saem bem.
- Chamada de funções e saídas estruturadas: vale a pena testar para agentes que precisam chamar ferramentas, retornar resultados no formato JSON ou passar trabalho para outro serviço. Esses recursos não tornam um agente confiável por si só; eles apenas fornecem a mecânica para testar fluxos de trabalho com muitas ferramentas adequadamente.
- Entrada de texto, imagem e vídeo: útil quando o trabalho de engenharia inclui evidências visuais: capturas de tela de UI, gravações de fluxo de trabalho, diagramas de arquitetura ou demonstrações de produto. Como a saída é texto, os melhores usos são explicação, depuração, sumarização, classificação e planejamento de implementação.
- Suporte a raciocínio: mais valioso quando você pede ao M3 para comparar opções, encontrar riscos ou explicar por que uma correção é mais segura que outra. Para tarefas simples de extração ou roteamento, o orçamento extra de raciocínio pode não valer o custo.
O teste prático é se essas capacidades reduzem etapas no seu fluxo de trabalho. Se elas apenas tornam um prompt mais impressionante, use um modelo menor ou mais barato. Se elas permitem que o modelo mantenha o estado relevante do projeto, inspecione o contexto visual e retorne decisões estruturadas, o M3 é um candidato melhor.
Benchmarks e notas de avaliação
A MiniMax reporta resultados fortes do M3 em benchmarks de codificação, terminal, navegação e agenticos. Use o gráfico de benchmark abaixo como ponto de partida baseado em fontes e, em seguida, compare o M3 com seus próprios prompts, repositórios, ferramentas e metas de custo no Novita AI.
O gráfico de benchmark oficial da MiniMax mostra o M3 com SWE Bench Pro 59,0, Terminal Bench 2.1 66,0, VIBE V2 50,1, SVG-Bench 63,7, KernelBench Hard 28,8, BrowseComp 83,5, GDPval-rubrics 74,7, BankerToolBench 76,1, MCP Atlas 74,2 e OSWorld-verified 70,0. Esses são pontuações reportadas pela MiniMax, portanto, trate-as como sinais de avaliação, não como garantia de desempenho em produção.
Para codificação agentica, construa um pequeno conjunto de avaliação antes de mudar o tráfego. Acompanhe a taxa de tarefas resolvidas, precisão das chamadas de ferramentas, comportamento de repetição, custo por tarefa resolvida e modos de falha em seus próprios repositórios.
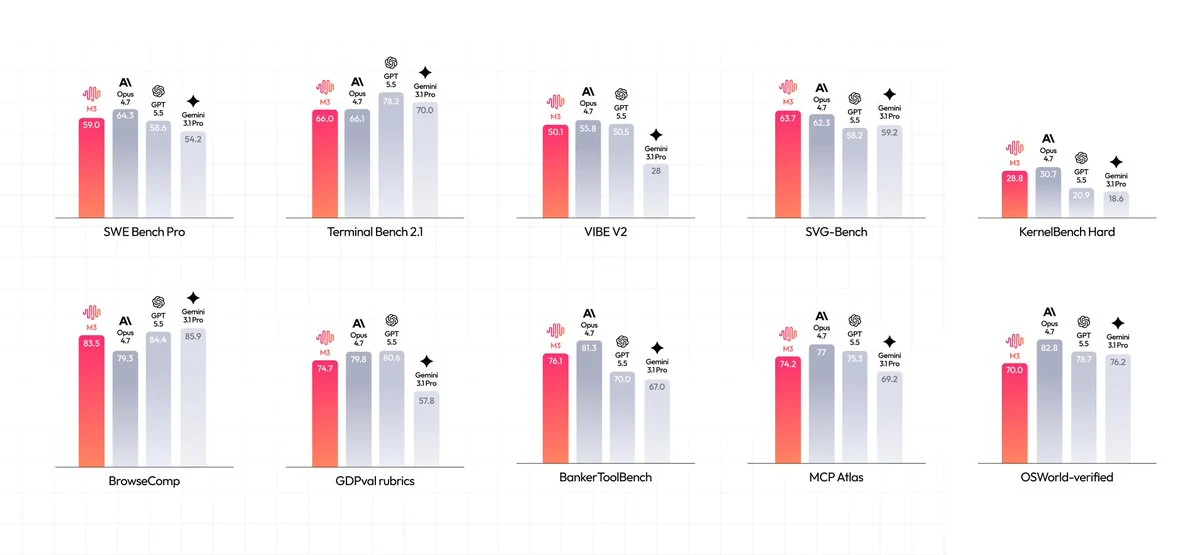
Fonte: Gráfico de benchmark oficial da MiniMax. As pontuações são reportadas pela MiniMax e devem ser validadas em sua própria carga de trabalho antes do uso em produção.
Notas de preços e verificações de custo
A API de listagem de modelos ativos do Novita, consultada em 1º de junho de 2026, retorna campos de preços brutos para minimax/minimax-m3: entrada 3000 e saída 12000. Interpretados como USD por 1M de tokens, esses campos correspondem a US$ 0,30 por milhão de tokens de entrada e US$ 1,20 por milhão de tokens de saída. Verifique a página do modelo Novita e o painel da conta antes do uso em produção, pois os preços exibidos podem mudar.
Para estimativas de produção no Novita AI, use a página do modelo ativo e o painel da conta como fonte da verdade e calcule a partir dos tokens reais de entrada, saída, comportamento de leitura de cache e taxa de repetição.
Evite atalhos amplos como “20% do Claude Sonnet”. Para uma comparação útil, use as taxas atuais da página do modelo Novita ou do painel da conta e estime com base em sua própria mistura de tokens, comprimento de saída, repetições e meta de latência.
MiniMax M3 vs MiniMax M2.7, M2 e M1
Se você já leu o artigo MiniMax M2.7 no Novita AI, a principal diferença é o escopo. O M2.7 cobria um modelo anterior de codificação agentica com uma janela de contexto de 204.800 tokens. O M3 eleva o teto para uma janela de contexto de 1M de tokens, adiciona entrada multimodal e traz uma cobertura mais ampla reportada pela MiniMax em benchmarks de codificação e agenticos.
Comparado com M2.7 e M2.5, escolha o M3 quando precisar testar estados de projeto maiores, fluxos de trabalho com muitas ferramentas ou raciocínio multimodal. Comparado com o MiniMax M1 no Novita AI, o M3 é menos sobre contexto longo como manchete e mais sobre aplicar esse contexto a tarefas de codificação, navegação, terminal e agentes.
Onde o MiniMax M3 se encaixa
Um teste prático é a revisão de grandes bases de código. Dê ao M3 um resumo de funcionalidade, os arquivos fonte relevantes, logs, saída de teste com falha e notas de implementação anteriores. Em seguida, peça para identificar a menor alteração segura, ou os principais riscos a resolver antes que alguém comece a editar o código.
Ele também se encaixa em testes para assistentes de codificação agenticos: pesquisar arquivos, planejar mudanças, chamar ferramentas e retornar resultados estruturados. O suporte a chamada de funções e saídas estruturadas do Novita ajuda aqui, mas o verdadeiro teste é como o M3 se comporta quando uma ferramenta falha, o contexto é ruidoso ou a ação correta é parar e pedir esclarecimentos.
Para equipes de produto e engenharia, o ângulo multimodal também vale a pena ser testado. O M3 pode ler capturas de tela de UI, inspecionar gravações de fluxo de trabalho, extrair tarefas de implementação de diagramas de arquitetura ou transformar feedback visual de QA em tickets mais claros.
Quando o MiniMax M3 pode não ser a escolha certa
Escolha o M3 para fluxos de trabalho de desenvolvedor onde contexto longo, uso de ferramentas ou entrada multimodal podem reduzir o tempo de revisão. Use um modelo menor quando o trabalho for extração simples, perguntas e respostas curtas ou roteamento. Em produção, mantenha testes de aceitação e revisão humana em tarefas onde erros são caros.
Se sua equipe precisar de evidências de benchmark independentes antes de adotar um modelo, execute uma avaliação no Novita AI com repositórios, prompts, loops de ferramentas, metas de latência e restrições de orçamento representativos. Isso dará uma resposta mais clara do que comparar números de página de lançamento.
FAQ
O MiniMax M3 está disponível no Novita AI?
Sim. A página de modelo ativo do Novita lista o MiniMax-M3, e o endpoint de modelos compatíveis com OpenAI retorna minimax/minimax-m3 como um modelo de chat ativo.
Qual ID de modelo devo usar?
Use minimax/minimax-m3 com a API LLM compatível com OpenAI do Novita.
Qual é o tamanho do contexto do MiniMax M3 no Novita?
O Novita lista o MiniMax-M3 com um tamanho de contexto de 1.000.000 tokens e máximo de 131.072 tokens de saída.
O MiniMax M3 gera imagens ou vídeos?
Nenhuma afirmação verificada do Novita neste artigo suporta geração de saída de imagem ou vídeo. O conjunto de modalidades verificado é entrada de texto, imagem e vídeo com saída de texto.
Como devo avaliar o MiniMax M3 para agentes de codificação?
Teste-o em tarefas realistas: pesquisa em repositórios, testes com falha, longos históricos de issues, chamadas de ferramentas, saídas estruturadas e contexto ruidoso. Acompanhe a taxa de tarefas resolvidas, qualidade das chamadas de ferramentas, custo, latência e recuperação de falhas, em vez de confiar apenas em números de benchmark publicados.



