

- Qu’est-ce que MiniMax M3 ?
- Qu’est-ce qui change maintenant que M3 est disponible sur Novita AI ?
- Spécifications de l’API Novita et ID du modèle
- Comment utiliser MiniMax M3 sur Novita AI
- Capacités clés pour les développeurs
- Repères et notes d’évaluation
- Notes de tarification et vérifications des coûts
- MiniMax M3 vs MiniMax M2.7, M2, et M1
- Où se situe MiniMax M3
- Quand MiniMax M3 peut ne pas être le bon choix
- FAQ
- Articles recommandés
MiniMax M3 est désormais disponible en direct sur Novita AI sous le nom minimax/minimax-m3. Cela rend ce lancement plus qu’une simple fiche technique de modèle : les développeurs peuvent essayer M3 via l’API compatible OpenAI de Novita et voir comment il se comporte sur la revue de code de grande base, les workflows agentiques lourds en outils, la planification avec contexte long, et les tâches d’entrée multimodale qui nécessitent une réponse textuelle.
Qu’est-ce que MiniMax M3 ?
MiniMax M3 est un modèle plus récent de la série M de MiniMax, conçu pour le codage, le raisonnement agentique, l’utilisation d’outils, le travail en contexte long et la compréhension d’entrées multimodales. Sur Novita AI, il est proposé en tant que modèle de chat serverless minimax/minimax-m3.
La raison de le tester est simple : M3 vous offre beaucoup d’espace pour transporter le contexte du projet, et il peut lire du texte, des images et des vidéos tout en renvoyant du texte. Cette combinaison est utile lorsqu’une tâche comporte plusieurs types de preuves : fichiers source, journaux, captures d’écran, notes de conception, ou une courte démonstration produit.
Pour les utilisateurs, la limite pratique est simple : utilisez M3 pour comprendre des entrées mixtes et renvoyer des analyses, plans, explications ou suggestions de code à base de texte. Ce n’est ni un générateur d’images ni un générateur de vidéos. Testez-le avec vos propres critères d’acceptation avant d’utiliser sa sortie en production.
Qu’est-ce qui change maintenant que M3 est disponible sur Novita AI ?
MiniMax M3 est disponible sur Novita AI sous le nom minimax/minimax-m3. Vous pouvez ouvrir la page du modèle MiniMax-M3 pour la fiche en direct, puis l’appeler via le point de terminaison de chat completions compatible OpenAI de Novita.
Pour un premier test, utilisez l’ID du modèle, l’URL de base, le point de terminaison, les modalités prises en charge, les limites de contexte et de sortie ci-dessous, puis exécutez la petite requête Python ou curl dans la section « Comment faire ».
Si votre pile utilise déjà le modèle OpenAI SDK, vous pouvez généralement commencer par modifier l’URL de base, la clé API et la chaîne de modèle. Avant un déploiement en production, effectuez les mêmes vérifications que vous feriez pour toute migration de modèle : latence, utilisation des tokens, comportement des outils et coût sur votre propre charge de travail.
Spécifications de l’API Novita et ID du modèle
| ID du modèle Novita | minimax/minimax-m3 |
| Nom d’affichage du modèle | MiniMax-M3 |
| Type de modèle | Chat |
| Longueur de contexte | 1 000 000 tokens |
| Sortie maximale | 131 072 tokens |
| Modalités d’entrée | Texte, image, vidéo |
| Modalités de sortie | Texte |
| Fonctionnalités prises en charge | Serverless, appel de fonction, sorties structurées, raisonnement |
| URL de base compatible OpenAI | https://api.novita.ai/openai |
| Point de terminaison de chat | /v1/chat/completions |
Utilisez la page du modèle Novita pour la fiche actuelle de MiniMax-M3, et consultez la référence API lorsque vous avez besoin de détails sur les champs de requête, l’authentification ou les paramètres.
Comment utiliser MiniMax M3 sur Novita AI
Utilisez ce chemin rapide lorsque vous souhaitez tester MiniMax M3 via l’API compatible OpenAI de Novita.
Étape 1 : Ouvrir la documentation de l’API LLM de Novita
Commencez par le guide de l’API LLM de Novita pour le modèle d’intégration. Gardez la référence de l’API Créer une complétion de chat à portée de main pour les champs de requête, le format de réponse et les paramètres optionnels.
Étape 2 : Préparer votre clé API, l’URL de base et l’ID du modèle
Pour un premier appel, vous avez besoin de trois valeurs : votre clé API Novita, l’URL de base compatible OpenAI https://api.novita.ai/openai, et l’ID du modèle minimax/minimax-m3. Conservez la clé API dans une variable d’environnement ou un gestionnaire de secrets plutôt que de la coder en dur dans le code de l’application.
Étape 3 : Exécuter une requête de test en Python
Voici un exemple Python minimal utilisant le modèle OpenAI SDK :
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="minimax/minimax-m3",
messages=[
{
"role": "system",
"content": "You are a senior software engineering assistant. Be precise and cite uncertainty.",
},
{
"role": "user",
"content": "Review this migration plan and identify the top implementation risks.",
},
],
max_tokens=1200,
temperature=0.2,
)
print(response.choices[0].message.content)
Étape 4 : Tester la même requête avec curl
Voici la même idée avec curl :
curl "https://api.novita.ai/openai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_NOVITA_API_KEY" \
-d '{
"model": "minimax/minimax-m3",
"messages": [
{
"role": "system",
"content": "You are a senior software engineering assistant. Be precise and cite uncertainty."
},
{
"role": "user",
"content": "Review this migration plan and identify the top implementation risks."
}
],
"max_tokens": 1200,
"temperature": 0.2
}'
Étape 5 : Évaluer avec une tâche de codage réaliste
Pour la première évaluation, résistez à la tentation de demander une application entière. Donnez plutôt à M3 une tâche petite mais réaliste : cinq fichiers pertinents, un test qui échoue, et une demande d’explication de l’échec avant de proposer la correction la plus petite et la plus sûre. C’est un meilleur indicateur pour la qualité du raisonnement, la localisation du code, et si le contexte long est vraiment utile.
Capacités clés pour les développeurs
La façon utile de lire la fiche technique de M3 n’est pas comme une liste de grands chiffres. Chaque capacité correspond à un type de charge de travail différent :
- Contexte de 1M tokens : utile lorsque la tâche nécessite plus qu’une invite et un fichier, comme la revue de dépôt, les longs historiques de problèmes, les journaux, les spécifications ou les plans de migration. C’est moins utile si la tâche est une question de codage courte où les modèles plus petits fonctionnent déjà bien.
- Appel de fonction et sorties structurées : à tester pour les agents qui doivent appeler des outils, renvoyer des résultats au format JSON, ou passer du travail à un autre service. Ces fonctionnalités ne rendent pas un agent fiable par elles-mêmes ; elles vous donnent simplement les mécanismes pour tester correctement les workflows lourds en outils.
- Entrée texte, image et vidéo : utile lorsque le travail d’ingénierie comprend des preuves visuelles : captures d’écran d’interface, enregistrements de flux de travail, diagrammes d’architecture ou démonstrations produit. Comme la sortie est du texte, les meilleures applications sont l’explication, le débogage, la synthèse, la classification et la planification d’implémentation.
- Support du raisonnement : le plus précieux lorsque vous demandez à M3 de comparer des options, de trouver des risques ou d’expliquer pourquoi une correction est plus sûre qu’une autre. Pour des tâches simples d’extraction ou de routage, le budget de raisonnement supplémentaire peut ne pas valoir le coût.
Le test pratique est de savoir si ces capacités réduisent les étapes dans votre workflow. Si elles ne font que rendre une invite plus impressionnante, utilisez un modèle plus petit ou moins cher. Si elles permettent au modèle de conserver l’état pertinent du projet, d’inspecter le contexte visuel et de renvoyer des décisions structurées, alors M3 est un meilleur candidat.
Repères et notes d’évaluation
MiniMax rapporte des résultats solides pour M3 sur les benchmarks de codage, terminal, navigation et agentique. Utilisez le graphique de benchmarks ci-dessous comme point de départ basé sur des sources, puis comparez M3 avec vos propres invites, dépôts, outils et objectifs de coût sur Novita AI.
Le graphique officiel des benchmarks MiniMax montre M3 à SWE Bench Pro 59.0, Terminal Bench 2.1 66.0, VIBE V2 50.1, SVG-Bench 63.7, KernelBench Hard 28.8, BrowseComp 83.5, GDPval-rubrics 74.7, BankerToolBench 76.1, MCP Atlas 74.2, et OSWorld-verified 70.0. Ce sont des scores rapportés par MiniMax, traitez-les donc comme des signaux d’évaluation plutôt qu’une garantie de performance en production.
Pour le codage agentique, construisez un petit ensemble d’évaluation avant de basculer le trafic. Suivez le taux de résolution de tâches, la précision des appels d’outils, le comportement de réessai, le coût par tâche résolue et les modes d’échec sur vos propres dépôts.
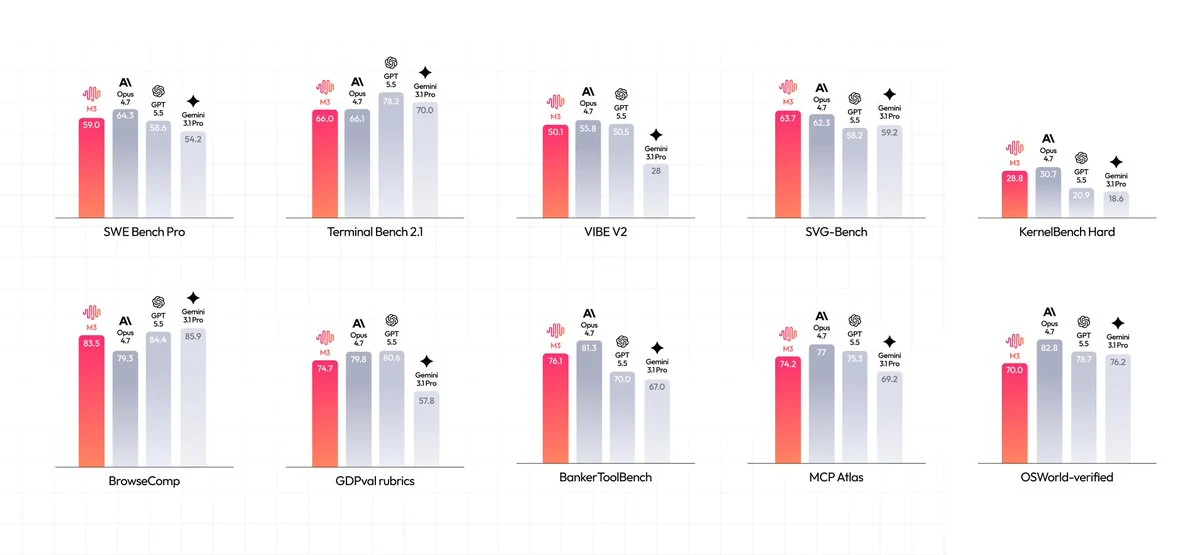
Source : graphique officiel des benchmarks MiniMax. Les scores sont rapportés par MiniMax et doivent être validés sur votre propre charge de travail avant utilisation en production.
Notes de tarification et vérifications des coûts
L’API live de liste de modèles de Novita, vérifiée le 1er juin 2026, renvoie les champs de prix bruts pour minimax/minimax-m3 : input 3000 et output 12000. Interprété comme USD par million de tokens, ces champs correspondent à 0,30 $ par million de tokens en entrée et 1,20 $ par million de tokens en sortie. Vérifiez la page du modèle Novita et le tableau de bord de votre compte avant utilisation en production, car les prix affichés peuvent changer.
Pour les estimations en production sur Novita AI, utilisez la page du modèle en direct et le tableau de bord du compte comme source de vérité, puis calculez à partir des tokens d’entrée réels, des tokens de sortie, du comportement de lecture du cache et du taux de réessai.
Évitez les raccourcis larges comme « 20 % de Claude Sonnet ». Pour une comparaison utile, utilisez les tarifs actuels de la page du modèle Novita ou du tableau de bord du compte et estimez par rapport à votre propre mix de tokens, longueur de sortie, réessais et objectif de latence.
MiniMax M3 vs MiniMax M2.7, M2, et M1
Si vous avez déjà lu l’article MiniMax M2.7 sur Novita AI, la principale différence est le périmètre. M2.7 couvrait un modèle de codage agentique précédent avec une fenêtre de contexte de 204 800 tokens. M3 élève le plafond à une fenêtre de contexte de 1M tokens, ajoute l’entrée multimodale et apporte une couverture plus large rapportée par MiniMax sur les benchmarks de codage et agentiques.
Comparé à M2.7 et M2.5, choisissez M3 lorsque vous avez besoin de tester des états de projet plus grands, des workflows lourds en outils ou un raisonnement multimodal. Comparé à MiniMax M1 sur Novita AI, M3 est moins axé sur le contexte long comme titre d’accroche et plus sur l’application de ce contexte aux tâches de codage, navigation, terminal et agent.
Où se situe MiniMax M3
Un test pratique est la revue de code de grande base. Donnez à M3 un brief de fonctionnalité, les fichiers source pertinents, les journaux, la sortie de test échouée et les notes d’implémentation précédentes. Demandez-lui ensuite d’identifier le plus petit changement sûr, ou les principaux risques à résoudre avant que quiconque commence à éditer le code.
Il a également sa place dans les tests d’assistants de codage agentiques : rechercher des fichiers, planifier des modifications, appeler des outils et renvoyer des résultats structurés. Le support des appels de fonction et des sorties structurées de Novita aide ici, mais le vrai test est le comportement de M3 lorsqu’un outil échoue, que le contexte est bruité ou que la bonne décision est de s’arrêter et de demander des éclaircissements.
Pour les équipes produit et ingénierie, l’angle multimodal mérite également d’être testé. M3 peut lire des captures d’écran d’interface, inspecter des enregistrements de flux de travail, extraire des tâches d’implémentation à partir de diagrammes d’architecture ou transformer des retours visuels de QA en tickets plus clairs.
Quand MiniMax M3 peut ne pas être le bon choix
Choisissez M3 pour les workflows de développeur où le contexte long, l’utilisation d’outils ou l’entrée multimodale peut réduire le temps de revue. Utilisez un modèle plus petit lorsque la tâche est simple extraction, Q&A court ou routage. En production, gardez des tests d’acceptation et une relecture humaine pour les tâches où les erreurs coûtent cher.
Si votre équipe a besoin de preuves de benchmark indépendantes avant d’adopter un modèle, effectuez une évaluation sur Novita AI avec des dépôts, invites, boucles d’outils, objectifs de latence et contraintes budgétaires représentatifs. Cela vous donnera une réponse plus claire que de comparer uniquement les chiffres des pages de lancement.
FAQ
MiniMax M3 est-il disponible sur Novita AI ?
Oui. La page live du modèle Novita liste MiniMax-M3, et le point de terminaison des modèles compatibles OpenAI renvoie minimax/minimax-m3 comme modèle de chat actif.
Quel ID de modèle dois-je utiliser ?
Utilisez minimax/minimax-m3 avec l’API LLM compatible OpenAI de Novita.
Quelle longueur de contexte MiniMax M3 prend-il en charge sur Novita ?
Novita liste MiniMax-M3 avec une longueur de contexte de 1 000 000 tokens et un maximum de 131 072 tokens de sortie.
MiniMax M3 génère-t-il des images ou des vidéos ?
Aucune affirmation vérifiée dans ce brouillon ne prend en charge la génération d’images ou de vidéos en sortie. L’ensemble de modalités vérifié est entrée texte, image et vidéo avec sortie texte.
Comment évaluer MiniMax M3 pour des agents de codage ?
Testez-le sur des tâches réalistes : recherche dans un dépôt, tests en échec, longs historiques de problèmes, appels d’outils, sorties structurées et contexte bruité. Suivez le taux de résolution de tâches, la qualité des appels d’outils, le coût, la latence et la reprise après échec plutôt que de vous fier uniquement aux chiffres de benchmarks publiés.



