

- ¿Qué es MiniMax M3?
- ¿Qué cambió ahora que M3 está disponible en Novita AI?
- Especificaciones de API de Novita e ID del modelo
- Cómo usar MiniMax M3 en Novita AI
- Capacidades clave para desarrolladores
- Evaluaciones comparativas y notas de evaluación
- Notas de precios y comprobaciones de coste
- MiniMax M3 vs MiniMax M2.7, M2 y M1
- Dónde encaja MiniMax M3
- Cuándo MiniMax M3 puede no ser la elección correcta
- Preguntas frecuentes
- Artículos recomendados
MiniMax M3 está disponible en Novita AI como minimax/minimax-m3. Esto hace que el lanzamiento sea más que otra ficha técnica de modelo: los desarrolladores pueden probar M3 a través de la API compatible con OpenAI de Novita y ver cómo se comporta en revisión de grandes bases de código, flujos de trabajo de agentes con muchas herramientas, planificación de contexto largo y tareas de entrada multimodal que necesitan una respuesta de texto.
¿Qué es MiniMax M3?
MiniMax M3 es un modelo más nuevo de la serie M de MiniMax, orientado a codificación, razonamiento agéntico, uso de herramientas, trabajo con contexto largo y comprensión de entrada multimodal. En Novita AI, está disponible como el modelo de chat sin servidor minimax/minimax-m3.
La razón para probarlo es simple: M3 te da mucho espacio para llevar el contexto del proyecto, y puede leer texto, imágenes y video mientras devuelve texto. Esa combinación es útil cuando una tarea tiene más de un tipo de evidencia: archivos fuente, registros, capturas de pantalla, notas de diseño o un breve recorrido del producto.
Para los usuarios, el límite práctico es simple: utiliza M3 para comprender entradas mixtas y devolver análisis basados en texto, planes, explicaciones o sugerencias de código. No es un generador de imágenes ni de video. Pruébalo con tus propios criterios de aceptación antes de usar su salida en producción.
¿Qué cambió ahora que M3 está disponible en Novita AI?
MiniMax M3 está disponible en Novita AI como minimax/minimax-m3. Puedes abrir la página del modelo MiniMax-M3 para ver la lista en vivo, luego llamarlo a través del endpoint de completaciones de chat compatible con OpenAI de Novita.
Para una primera prueba, usa el ID del modelo, la URL base, el endpoint, las modalidades compatibles, los límites de contexto y salida a continuación, luego ejecuta la pequeña solicitud en Python o curl en la sección Cómo usar.
Si tu stack ya usa el patrón del SDK de OpenAI, normalmente puedes empezar cambiando la URL base, la clave de API y la cadena del modelo. Antes del despliegue en producción, ejecuta las mismas comprobaciones que harías para cualquier migración de modelo: latencia, uso de tokens, comportamiento de herramientas y coste en tu propia carga de trabajo.
Especificaciones de API de Novita e ID del modelo
| ID del modelo en Novita | minimax/minimax-m3 |
| Nombre mostrado del modelo | MiniMax-M3 |
| Tipo de modelo | Chat |
| Longitud de contexto | 1,000,000 tokens |
| Salida máxima | 131,072 tokens |
| Modalidades de entrada | Text, image, video |
| Modalidades de salida | Text |
| Características compatibles | Serverless, function calling, structured outputs, reasoning |
| URL base compatible con OpenAI | https://api.novita.ai/openai |
| Endpoint de chat | /v1/chat/completions |
Usa la página del modelo Novita para la lista actual de MiniMax-M3, y usa la referencia de API cuando necesites campos de solicitud, autenticación o detalles de parámetros.
Cómo usar MiniMax M3 en Novita AI
Usa esta ruta rápida cuando quieras probar MiniMax M3 a través de la API compatible con OpenAI de Novita.
Paso 1: Abre la documentación de la API LLM de Novita
Comienza con la guía de API LLM de Novita para el patrón de integración. Mantén la referencia de API Crear completación de chat cerca para campos de solicitud, formato de respuesta y parámetros opcionales.
Paso 2: Prepara tu clave de API, URL base e ID del modelo
Para una primera llamada, necesitas tres valores: tu clave de API de Novita, la URL base compatible con OpenAI https://api.novita.ai/openai y el ID del modelo minimax/minimax-m3. Mantén la clave de API en una variable de entorno o gestor de secretos en lugar de codificarla en el código de la aplicación.
Paso 3: Ejecuta una solicitud de prueba en Python
Aquí hay un ejemplo mínimo en Python usando el patrón del SDK de OpenAI:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/openai",
api_key="YOUR_NOVITA_API_KEY",
)
response = client.chat.completions.create(
model="minimax/minimax-m3",
messages=[
{
"role": "system",
"content": "You are a senior software engineering assistant. Be precise and cite uncertainty.",
},
{
"role": "user",
"content": "Review this migration plan and identify the top implementation risks.",
},
],
max_tokens=1200,
temperature=0.2,
)
print(response.choices[0].message.content)
Paso 4: Prueba la misma solicitud con curl
Aquí está la misma idea con curl:
curl "https://api.novita.ai/openai/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_NOVITA_API_KEY" \
-d '{
"model": "minimax/minimax-m3",
"messages": [
{
"role": "system",
"content": "You are a senior software engineering assistant. Be precise and cite uncertainty."
},
{
"role": "user",
"content": "Review this migration plan and identify the top implementation risks."
}
],
"max_tokens": 1200,
"temperature": 0.2
}'
Paso 5: Evalúa con una tarea de codificación realista
Para la primera evaluación, resiste la tentación de pedir una aplicación completa. Dale a M3 una tarea pequeña pero realista: cinco archivos relevantes, una prueba fallida y una solicitud para explicar el fallo antes de proponer la corrección más pequeña y segura. Esa es una mejor señal de la calidad del razonamiento, la localidad del código y si el contexto largo está ayudando.
Capacidades clave para desarrolladores
La forma útil de leer las especificaciones de M3 no es como una lista de grandes números. Cada capacidad apunta a un tipo diferente de carga de trabajo:
- Contexto de 1M de tokens: útil cuando la tarea necesita más que un prompt y un archivo, como revisión de repositorios, historiales largos de incidencias, registros, especificaciones o planes de migración. Es menos útil si la tarea es una pregunta de codificación corta donde los modelos más pequeños ya funcionan bien.
- Llamada a funciones y salidas estructuradas: vale la pena probar para agentes que necesitan llamar herramientas, devolver resultados en formato JSON o pasar trabajo a otro servicio. Estas características no hacen que un agente sea confiable por sí mismas; solo te dan los mecanismos para evaluar correctamente flujos de trabajo pesados en herramientas.
- Entrada de texto, imagen y video: útil cuando el trabajo de ingeniería incluye evidencia visual: capturas de pantalla de UI, grabaciones de flujos de trabajo, diagramas de arquitectura o recorridos de producto. Como la salida es texto, los mejores usos son explicación, depuración, resumen, clasificación y planificación de implementación.
- Soporte de razonamiento: más valioso cuando le pides a M3 que compare opciones, encuentre riesgos o explique por qué una corrección es más segura que otra. Para tareas simples de extracción o enrutamiento, el presupuesto adicional de razonamiento puede no valer el coste.
La prueba práctica es si estas capacidades reducen pasos en tu flujo de trabajo. Si solo hacen que un prompt parezca más impresionante, usa un modelo más pequeño o más barato. Si permiten que el modelo mantenga el estado del proyecto relevante, inspeccione el contexto visual y devuelva decisiones estructuradas, M3 es un mejor candidato.
Evaluaciones comparativas y notas de evaluación
MiniMax reporta resultados sólidos de M3 en evaluaciones de codificación, terminal, navegación y agentes. Usa el gráfico de evaluación a continuación como punto de partida respaldado por fuentes, luego compara M3 con tus propios prompts, repositorios, herramientas y objetivos de coste en Novita AI.
El gráfico oficial de evaluaciones de MiniMax muestra M3 con SWE Bench Pro 59.0, Terminal Bench 2.1 66.0, VIBE V2 50.1, SVG-Bench 63.7, KernelBench Hard 28.8, BrowseComp 83.5, GDPval-rubrics 74.7, BankerToolBench 76.1, MCP Atlas 74.2 y OSWorld-verified 70.0. Estos son puntajes reportados por MiniMax, así que trátalos como señales de evaluación, no como una garantía de rendimiento en producción.
Para codificación agéntica, crea un pequeño conjunto de evaluación antes de cambiar el tráfico. Rastrea la tasa de tareas resueltas, precisión de llamadas a herramientas, comportamiento de reintentos, coste por tarea resuelta y modos de fallo en tus propios repositorios.
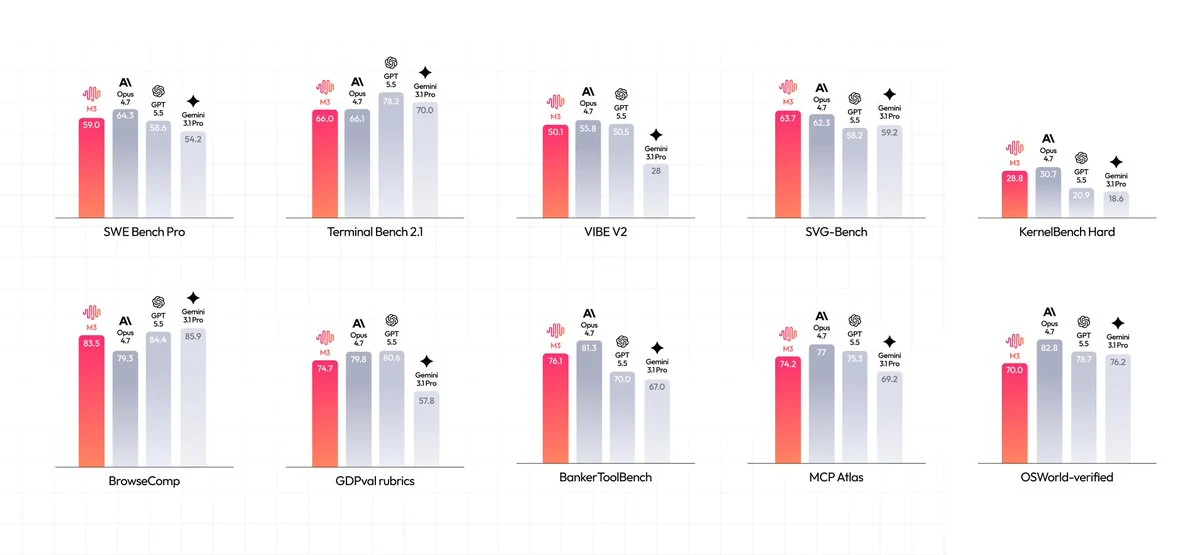
Fuente: Gráfico oficial de evaluaciones de MiniMax. Los puntajes son reportados por MiniMax y deben validarse con tu propia carga de trabajo antes de usar en producción.
Notas de precios y comprobaciones de coste
La API de lista de modelos en vivo de Novita consultada el 1 de junio de 2026 devuelve campos de precios sin procesar para minimax/minimax-m3: entrada 3000 y salida 12000. Interpretados como USD por 1M de tokens, esos campos corresponden a $0.30 por millón de tokens de entrada y $1.20 por millón de tokens de salida. Verifica la página del modelo Novita y el panel de cuenta antes del uso en producción, ya que los precios mostrados pueden cambiar.
Para estimaciones de producción en Novita AI, usa la página del modelo en vivo y el panel de cuenta como fuente de verdad, luego calcula a partir de tokens de entrada reales, tokens de salida, comportamiento de lectura de caché y tasa de reintentos.
Evita atajos amplios como “20% de Claude Sonnet”. Para una comparación útil, usa las tarifas actuales de la página del modelo Novita o del panel de cuenta y estima contra tu propia mezcla de tokens, longitud de salida, reintentos y objetivo de latencia.
MiniMax M3 vs MiniMax M2.7, M2 y M1
Si ya leíste el artículo de MiniMax M2.7 en Novita AI, la principal diferencia es el alcance. M2.7 cubría un modelo de codificación agéntica anterior con una ventana de contexto de 204,800 tokens. M3 eleva el límite a una ventana de contexto de 1M de tokens, añade entrada multimodal y ofrece una cobertura más amplia reportada por MiniMax en evaluaciones de codificación y agentes.
En comparación con M2.7 y M2.5, elige M3 cuando necesites probar estados de proyecto más grandes, flujos de trabajo con muchas herramientas o razonamiento multimodal. En comparación con MiniMax M1 en Novita AI, M3 se trata menos del contexto largo como titular y más de aplicar ese contexto a tareas de codificación, navegación, terminal y agentes.
Dónde encaja MiniMax M3
Una prueba práctica es la revisión de grandes bases de código. Dale a M3 un resumen de funcionalidad, los archivos fuente relevantes, registros, salida de pruebas fallidas y notas de implementación anteriores. Luego pídele que identifique el cambio más pequeño y seguro, o los principales riesgos a resolver antes de que alguien empiece a editar código.
También pertenece a las pruebas de asistentes de codificación agénticos: buscar archivos, planificar cambios, llamar herramientas y devolver resultados estructurados. El soporte de llamada a funciones y salidas estructuradas de Novita ayuda aquí, pero la verdadera prueba es cómo se comporta M3 cuando una herramienta falla, el contexto es ruidoso o el movimiento correcto es detenerse y pedir aclaración.
Para equipos de producto e ingeniería, el ángulo multimodal también vale la pena probarlo. M3 puede leer capturas de pantalla de UI, inspeccionar grabaciones de flujos de trabajo, extraer tareas de implementación de diagramas de arquitectura o convertir comentarios visuales de QA en tickets más claros.
Cuándo MiniMax M3 puede no ser la elección correcta
Elige M3 para flujos de trabajo de desarrollador donde el contexto largo, el uso de herramientas o la entrada multimodal puedan reducir el tiempo de revisión. Usa un modelo más pequeño cuando el trabajo sea extracción simple, preguntas y respuestas cortas o enrutamiento. En producción, mantén pruebas de aceptación y revisión humana en tareas donde los errores sean costosos.
Si tu equipo necesita evidencia de evaluación independiente antes de adoptar un modelo, ejecuta una evaluación en Novita AI contra repositorios representativos, prompts, bucles de herramientas, objetivos de latencia y restricciones de presupuesto. Eso te da una respuesta más limpia que comparar números de páginas de lanzamiento por sí solos.
Preguntas frecuentes
¿Está MiniMax M3 disponible en Novita AI?
Sí. La página del modelo Novita en vivo lista MiniMax-M3, y el endpoint de modelos compatible con OpenAI devuelve minimax/minimax-m3 como un modelo de chat activo.
¿Qué ID de modelo debería usar?
Usa minimax/minimax-m3 con la API LLM compatible con OpenAI de Novita.
¿Qué longitud de contexto soporta MiniMax M3 en Novita?
Novita lista MiniMax-M3 con una longitud de contexto de 1,000,000 de tokens y un máximo de 131,072 tokens de salida.
¿Genera MiniMax M3 imágenes o video?
Ninguna afirmación verificada de Novita en este borrador respalda la generación de salida de imágenes o video. El conjunto de modalidades verificado es entrada de texto, imagen y video con salida de texto.
¿Cómo debería evaluar MiniMax M3 para agentes de codificación?
Pruébalo en tareas realistas: búsqueda en repositorios, pruebas fallidas, historiales largos de incidencias, llamadas a herramientas, salidas estructuradas y contexto ruidoso. Rastrea la tasa de tareas resueltas, calidad de llamadas a herramientas, coste, latencia y recuperación de fallos en lugar de confiar solo en números de evaluaciones publicados.



