

La première série de grands modèles open-source d’OpenAI, GPT-OSS, est disponible. Doté d’une architecture efficace de mélange d’experts (MoE), d’une prise en charge d’une longueur de contexte allant jusqu’à 128k tokens et de performances solides en raisonnement, sciences et codage, il offre de nouvelles opportunités pour les développeurs. Tout le monde peut désormais télécharger et exécuter ce modèle de langage avancé sur son propre matériel. Mais une question clé se pose : Quelle quantité de VRAM avez-vous réellement besoin pour exécuter GPT-OSS ?
Cet article vous expliquera tout :
- Recommandations de GPU : Quelles cartes sont les meilleures, du niveau grand public au niveau centre de données ?
- Optimisation de la VRAM : Comment utiliser la quantification et les nouveaux frameworks pour réduire la consommation de ressources ?
- Options de déploiement : GPU local vs. cloud – quelle solution est la plus rentable ?
- Accès le plus simple : Comment utiliser les services API et éviter les tracas liés au matériel ?
Que vous soyez un développeur indépendant ou une petite équipe, ce guide vous aidera à faire le choix le plus judicieux.
Quelle quantité de VRAM GPT OSS nécessite-t-il ?
GPT OSS est une architecture de modèle de langage large extrêmement efficace et évolutive. Elle utilise ce que l’on appelle le mélange d’experts (MoE), associé à une conception de Transformer autorégressif. Grâce à l’activation éparse, il peut exécuter des modèles très volumineux beaucoup plus rapidement et plus efficacement. Il prend également en charge des contextes extrêmement longs – jusqu’à 128 000 tokens – ce qui lui permet de traiter facilement des documents longs ou des conversations complexes. L’architecture combine l’encodage de position RoPE et bascule entre des fenêtres d’attention globales et locales, ce qui lui permet de gérer à la fois du contenu détaillé et général. GPT OSS est particulièrement performant en matière de raisonnement, de sciences et de codage.
Il est également facile à utiliser car il est directement compatible avec l’API OpenAI et les tokenizers populaires, donc les développeurs peuvent l’intégrer à leurs flux de travail existants sans difficulté. Pour l’entraînement, GPT OSS utilise des ensembles de données massifs et de haute qualité, est entraîné sur de nombreux GPU et utilise l’apprentissage par renforcement pour garantir sa sécurité, sa fiabilité et sa capacité à suivre les instructions.
Autre point intéressant : il prend en charge différents modes de raisonnement, vous permettant de trouver un équilibre entre vitesse, précision et coût selon vos besoins. De plus, GPT OSS est conçu pour l’utilisation d’outils et excelle dans la gestion des formats de dialogue et des rôles, ce qui le rend extrêmement flexible et sûr même pour les applications les plus exigeantes ou complexes.
| Modèle | Couches | Paramètres totaux | Paramètres actifs par token | Nombre total d’experts | Experts actifs par token | Longueur de contexte | Exigence de VRAM pour un seul GPU |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80Go |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16Go |
Conseils pour choisir un GPU pour GPT OSS
- La taille de la VRAM est le critère le plus important :
- Pour GPT-OSS 20B, vous aurez besoin d’un GPU avec au moins 16 Go de mémoire.
- Pour GPT-OSS 120B, vous devrez vous tourner vers un modèle avec au moins 80 Go de VRAM.
- L’architecture du GPU est importante :
Le modèle fonctionne mieux avec les architectures GPU les plus récentes. La documentation officielle indique spécifiquement qu’il est optimisé pour les puces Hopper et Blackwell – comme les H100, H200 et GB200 – donc l’utilisation de l’un de ces modèles vous offrira les meilleures performances. - Logiciels et pilotes :
Les GPU NVIDIA sont généralement le meilleur choix, car leur écosystème CUDA est extrêmement mature et bien pris en charge pour les tâches d’IA. La plupart des grandes bibliothèques d’IA, comme Transformers, Triton ou vLLM, sont profondément optimisées pour CUDA.
GPUs recommandés
Pour GPT-OSS 20B (nécessite au moins 16 Go de VRAM) :
- Cartes grand public ou professionnelles comme :
- NVIDIA RTX 4090 (24 Go)
- NVIDIA RTX 4080 (16 Go)
- NVIDIA RTX 4060 Ti (16 Go)
- NVIDIA RTX 6000 Ada (48 Go, carte professionnelle)
- AMD Radeon RX 7900 XTX (24 Go)
Pour GPT-OSS 120B (nécessite au moins 80 Go de VRAM) :
- Cartes de centre de données comme :
- NVIDIA H100 (80 Go)
- NVIDIA H200 (141 Go)
- NVIDIA A100 (80 Go)
- NVIDIA A800 (80 Go)
Vous pouvez consulter les prix détaillés sur Novita AI !
Comment optimiser l’utilisation de la VRAM pour GPT OSS ?
Utilisez des frameworks d’inférence plus légers :
- Llama.cpp :
Il s’agit d’un moteur d’inférence léger et multiplateforme qui fonctionne à la fois sur CPU et GPU (CUDA, Metal, Vulkan). Il prend en charge des formats quantifiés comme GGUF, qui peuvent réduire considérablement la taille du modèle et diminuer l’utilisation de la mémoire. - vLLM :
Un moteur d’inférence et de déploiement à haut débit. Il est doté de fonctionnalités avancées comme PagedAttention et Flash Attention 3, ce qui le rend extrêmement efficace pour servir des modèles volumineux.
Tirez parti des kernels avancés et de la quantification :
- Flash Attention :
Il s’agit d’une implémentation d’attention efficace qui peut grandement réduire l’utilisation de la mémoire et accélérer les calculs, en particulier lorsque vous travaillez avec des séquences longues. - Précision mixte et quantification (mxfp4) :
GPT-OSS prend en charge le format flottant 4 bits mxfp4. Lorsqu’il est utilisé avec des kernels Triton sur des GPU Hopper ou Blackwell, vous bénéficiez d’une utilisation de VRAM extrêmement faible et de vitesses d’inférence très élevées. - Kernel MoE MegaBlocks :
Il s’agit d’un kernel optimisé pour les modèles de mélange d’experts (MoE), qui permet d’améliorer l’efficacité sur les GPU qui n’ont pas d’architecture Hopper.
Installez et optimisez via la bibliothèque transformers :
La recommandation officielle est d’utiliser la bibliothèque transformers, qui regroupe de nombreuses de ces optimisations. Pour des performances optimales, vous pouvez installer PyTorch et Triton spécifiquement pour CUDA 12.8 :
# Upgrade the basic libraries
pip install --upgrade accelerate transformers kernels
# (Optional) For best performance with CUDA 12.8 and Triton 3.4, install this version of PyTorch
pip install torch==2.8.0 --index-url https://download.pytorch.org/whl/test/cu128
GPU cloud : un choix judicieux pour les petits développeurs
Étant donné que le coût et la complexité de l’exécution locale peuvent être assez élevés, la plupart des développeurs préfèrent en réalité utiliser des services de GPU cloud.
Quand choisir un GPU local
- Vous disposez d’un budget important et pouvez vous permettre de dépenser des dizaines, voire des centaines de milliers de dollars d’investissement initial.
- Vous avez des besoins à long terme et à charge élevée pour l’entraînement ou l’inférence.
- Vous avez des exigences strictes en matière de confidentialité des données et ne pouvez pas laisser les données quitter votre propre environnement.
- Vous souhaitez un contrôle total sur le matériel, les logiciels et le réseau.
Quand choisir un GPU cloud
- Vous êtes sensible aux coûts et souhaitez éviter les gros achats de matériel et la maintenance continue – payez simplement à l’usage.
- Vos besoins sont flexibles, peut-être que vous êtes encore en phase d’expérimentation, ou que votre charge de travail évolue au fil du temps.
- Vous souhaitez un accès instantané aux GPU les plus récents et les plus puissants, comme les H100 ou H200, sans attendre les processus d’achat.
- Vous ne voulez pas avoir à gérer des installations de pilotes compliquées, la configuration de l’environnement ou la maintenance physique.
Comment accéder à GPT OSS sur un GPU cloud comme Novita AI ?
Étape 1 : Créer un compte
Si vous êtes nouveau sur Novita AI, commencez par créer un compte sur notre site web. Une fois inscrit, rendez-vous dans l’onglet « GPUs » pour explorer les ressources disponibles et commencer votre parcours.

Essayez les GPU haute performance de Novita AI
Étape 2 : Explorer les modèles et les serveurs GPU**
Commencez par sélectionner un modèle correspondant aux besoins de votre projet, comme PyTorch, TensorFlow ou CUDA. Choisissez la version adaptée à vos besoins, comme PyTorch 2.2.1 ou CUDA 11.8.0. Sélectionnez ensuite la configuration de serveur GPU A100, qui offre des performances puissantes pour gérer des charges de travail exigeantes avec une VRAM, une RAM et une capacité de disque importantes.

Étape 3 : Personnalisez votre déploiement
Après avoir sélectionné un modèle et un GPU, personnalisez vos paramètres de déploiement en ajustant des paramètres comme la version du système d’exploitation (par exemple CUDA 11.8). Vous pouvez également modifier d’autres configurations pour adapter l’environnement aux besoins spécifiques de votre projet.
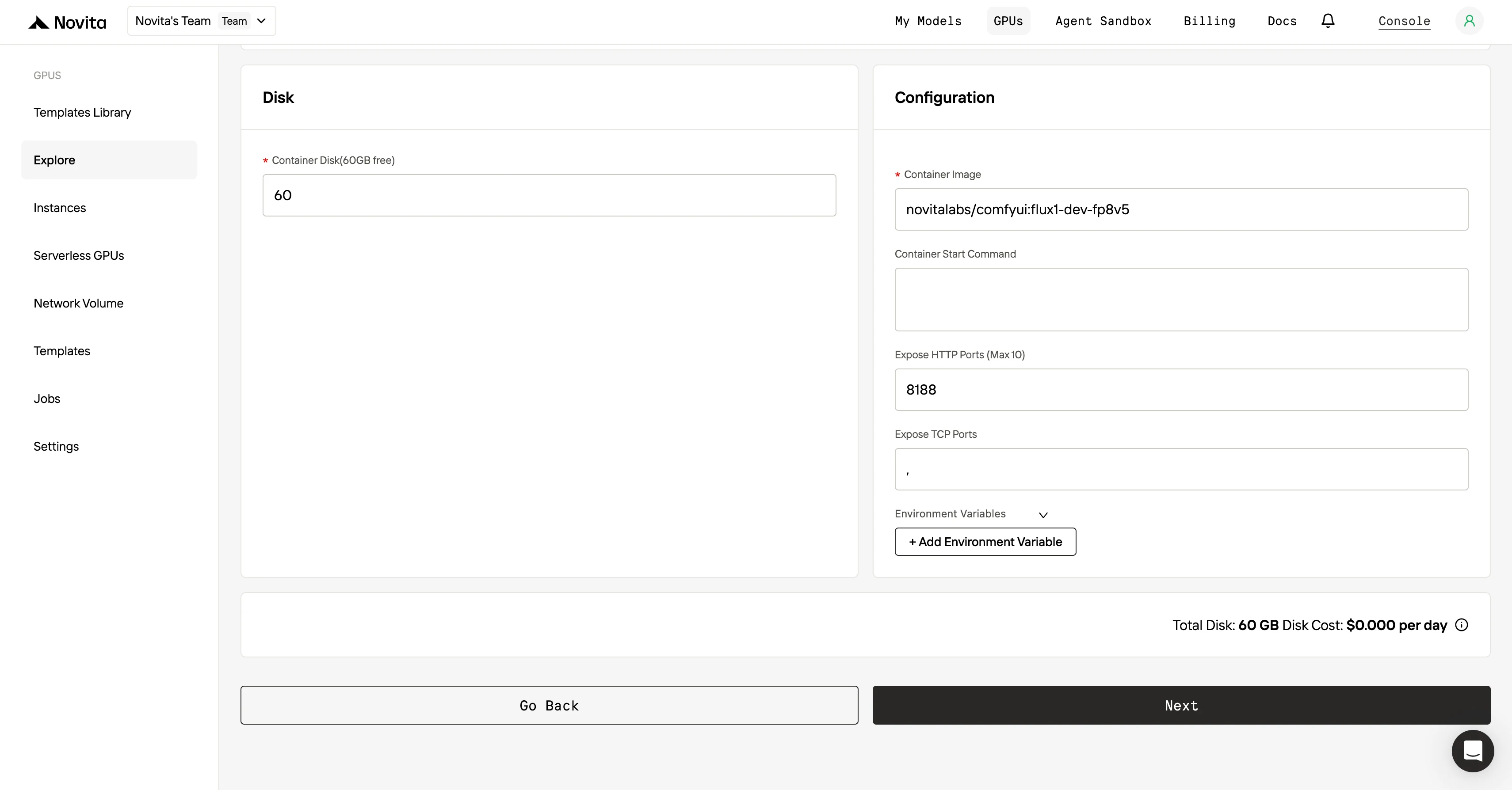
Étape 4 : Lancer une instance**
Une fois que vous avez finalisé le modèle et les paramètres de déploiement, cliquez sur « Lancer l’instance » pour configurer votre instance GPU. Cela lancera la configuration de l’environnement, vous permettant de commencer à utiliser les ressources GPU pour vos tâches d’IA.
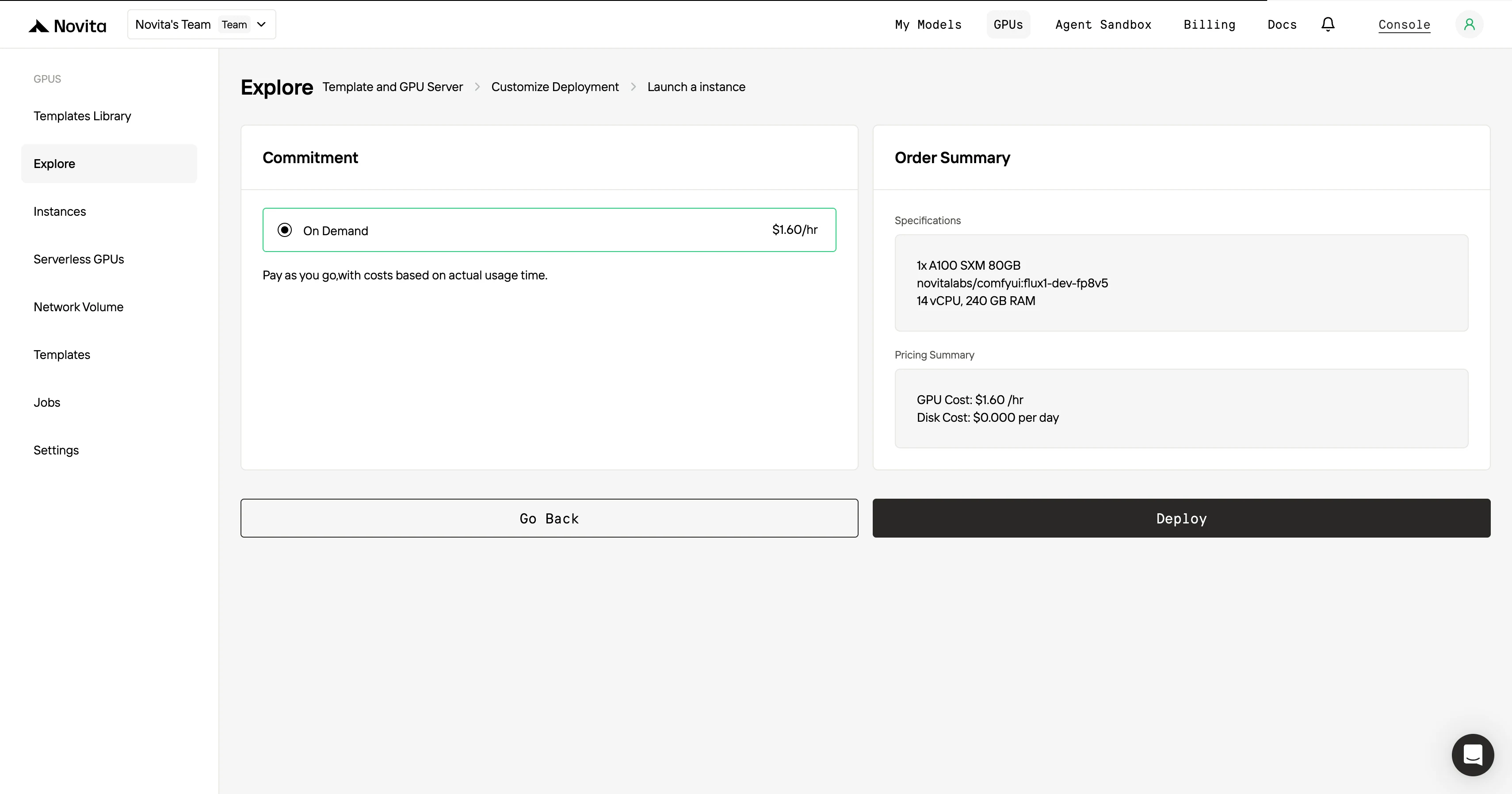
Pour une efficacité et une commodité maximales, utilisez l’API !
Novita AI propose des API pour GPT-OSS 120B
avec un contexte de 131K et des coûts de 0,1 $ par entrée et 0,5 $ par sortie. Novita AI propose également GPT-OSS 20B avec un contexte de 131 et des coûts de 0,05 $ par entrée et 0,2 $ par sortie, offrant un soutien solide pour maximiser le potentiel d’agent de code de GPT OSS.Novita AI
Étape 1 : Connectez-vous et accédez à la bibliothèque de modèles
Connectez-vous à votre compte et cliquez sur le bouton Bibliothèque de modèles.

Essayez GPT OSS dès maintenant !
Étape 2 : Choisissez votre modèle
Parcourez les options disponibles et sélectionnez le modèle qui correspond à vos besoins.

Étape 3 : Commencez votre essai gratuit
Commencez votre essai gratuit pour explorer les capacités du modèle sélectionné.

Étape 4 : Récupérez votre clé API
Pour vous authentifier auprès de l’API, nous vous fournirons une nouvelle clé API. En vous rendant sur la page « Paramètres », vous pouvez copier la clé API comme indiqué sur l’image.

Étape 5 : Installez l’API
Installez l’API à l’aide du gestionnaire de paquets spécifique à votre langage de programmation.
Après l’installation, importez les bibliothèques nécessaires dans votre environnement de développement. Initialisez l’API avec votre clé API pour commencer à interagir avec le LLM de Novita AI. Voici un exemple d’utilisation de l’API de complétion de chat pour les utilisateurs Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Pour libérer la puissance de GPT-OSS, la compréhension des exigences en matière de VRAM est essentielle :
- GPT-OSS 20B nécessite au moins 16 Go de VRAM, donc il fonctionne sur des GPU grand public haut de gamme comme la RTX 4060 Ti (16 Go), ce qui le rend accessible aux particuliers et aux passionnés.
- GPT-OSS 120B nécessite 80 Go de VRAM, nécessitant des GPU professionnels de centre de données comme le NVIDIA H100, ce qui est hors de portée pour la plupart des particuliers et des petites équipes.
Le déploiement local offre le plus de contrôle, mais s’accompagne de coûts matériels élevés et d’une complexité technique. L’utilisation de frameworks d’inférence légers comme Llama.cpp ou vLLM, ainsi que de techniques comme la quantification mxfp4 et Flash Attention, permet de réduire les besoins en VRAM.
Pour la plupart des développeurs, les GPU cloud sont le choix le plus judicieux – pas de gros coût initial, et vous bénéficiez d’un accès instantané à du matériel de premier ordre. Dans le même temps, des services API gérés comme Novita AI rendent les choses encore plus simples : il suffit d’appeler l’API, et vous êtes prêt à utiliser GPT-OSS sans avoir à gérer de matériel ou de déploiement du tout. C’est la meilleure façon de trouver un équilibre entre performance, coût et commodité, et de mettre une IA puissante à la portée de tous.
Questions fréquemment posées
Quelle quantité de VRAM ai-je besoin pour exécuter GPT-OSS ?
GPT-OSS 20B : au moins 16 Go de VRAM.
GPT-OSS 120B : au moins 80 Go de VRAM.
Quelle est la méthode la plus abordable pour exécuter GPT-OSS 20B localement ?
Utilisez un GPU grand public avec 16 Go de VRAM, comme la NVIDIA RTX 4060 Ti (16 Go), et un framework léger comme Llama.cpp avec un modèle quantifié GGUF.
Comment puis-je réduire l’utilisation de VRAM de GPT-OSS ?
Utilisez des frameworks légers (Llama.cpp, vLLM) avec des optimisations de mémoire intégrées.
Quantifiez le modèle (utilisez mxfp4 ou GGUF) pour une précision plus faible et une empreinte mémoire plus petite.
Activez des kernels efficaces comme Flash Attention, en particulier pour les textes longs.
Novita AI est une plateforme cloud d’IA qui offre aux développeurs un moyen simple de déployer des modèles d’IA grâce à notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour la construction et la mise à l’échelle.



