

OpenAI初のオープンソース大規模モデルシリーズであるGPT-OSSが登場しました。効率的なMixture-of-Experts(MoE)アーキテクチャ、最大128kのコンテキスト長への対応、推論・科学・コーディング分野での高いパフォーマンスを備え、開発者に新たな機会をもたらしています。誰でもこの高度な言語モデルを自身のハードウェアにダウンロードして実行できるようになりましたが、重要な疑問が残ります:GPT-OSSを実行するために実際に必要なVRAMはどれくらいなのでしょうか?
この記事では以下の点を解説します:
- GPUの推奨事項: コンシューマー向けからデータセンター向けまで、どのカードが最適なのか?
- VRAM最適化: 量子化や新しいフレームワークを活用してリソース使用量を削減する方法は?
- デプロイオプション: ローカルとクラウドGPU、どちらがコストパフォーマンスに優れているのか?
- 最も簡単な利用方法: APIサービスを活用してハードウェアの悩みを回避する方法は?
インディー開発者でも小規模チームでも、このガイドが最適な選択をする助けとなります。
GPT OSSに必要なVRAMはどれくらい?
GPT OSSは非常に効率的でスケーラブルな大規模言語モデルアーキテクチャです。Mixture-of-Experts(MoE)とオート回帰的Transformer設計を採用しており、スパース活性化により非常に大規模なモデルをより高速かつ効率的に実行できます。また最大128,000トークンの超長コンテキストに対応しているため、長文ドキュメントや複雑な会話も容易に処理できます。このアーキテクチャはRoPE位置エンコーディングを採用し、グローバルとローカルのアテンションウィンドウを切り替えることで、詳細な内容と広範な内容の両方を適切に処理できます。GPT OSSは推論・科学・コーディング分野で特に高い性能を発揮します。
またOpenAI APIや一般的なトークナイザーと直接互換性があるため、開発者は既存のワークフローに容易に統合できます。トレーニングでは大規模な高品質データセットを使用し、多数のGPUでトレーニングを行うほか、安全で信頼性が高く指示に従う能力に優れたモデルにするために強化学習も活用しています。
さらに、異なる推論モードに対応しているため、ニーズに応じて速度・精度・コストのバランスを調整できます。加えて、GPT OSSはツール利用を前提に設計されており、対話形式やロールの管理に優れているため、最も要求の厳しい複雑なアプリケーションでも柔軟かつ安全に利用できます。
| モデル | レイヤー数 | 総パラメータ数 | トークンごとの活性化パラメータ数 | 総エキスパート数 | トークンごとの活性化エキスパート数 | コンテキスト長 | 単一GPUのVRAM要件 |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16GB |
GPT OSS向けGPU選択のポイント
- VRAM容量が最も重要です:
- GPT-OSS 20Bの場合は、少なくとも16GBのメモリを搭載したGPUが必要です。
- GPT-OSS 120Bの場合は、少なくとも80GBのVRAMを搭載したGPUが必要です。
- GPUアーキテクチャも重要です:
このモデルは新しいGPUアーキテクチャで最も高い性能を発揮します。公式ドキュメントではHopperおよびBlackwellチップ(H100、H200、GB200など)に最適化されていると明記されているため、これらのGPUを使用することで最高のパフォーマンスが得られます。 - ソフトウェアとドライバー:
NVIDIAのGPUが一般的に最適です。CUDAエコシステムがAIタスクに対して非常に成熟しており、サポートが充実しているためです。Transformers、Triton、vLLMなどの主要なAIライブラリのほとんどがCUDAに深く最適化されています。
推奨GPU
GPT-OSS 20B(少なくとも16GBのVRAMが必要)向け:
- コンシューマー向けまたはプロ向けカード:
- NVIDIA RTX 4090 (24GB)
- NVIDIA RTX 4080 (16GB)
- NVIDIA RTX 4060 Ti (16GB)
- NVIDIA RTX 6000 Ada (48GB、プロ向けカード)
- AMD Radeon RX 7900 XTX (24GB)
GPT-OSS 120B(少なくとも80GBのVRAMが必要)向け:
- データセンター向けカード:
- NVIDIA H100 (80GB)
- NVIDIA H200 (141GB)
- NVIDIA A100 (80GB)
- NVIDIA A800 (80GB)
Novita AIで詳細な価格を確認できます! GPUの価格を確認!
GPT OSSのVRAM使用量を最適化する方法
軽量な推論フレームワークを活用する:
- Llama.cpp:
CPUとGPU(CUDA、Metal、Vulkan)の両方で動作するクロスプラットフォームの軽量推論エンジンです。GGUFなどの量子化フォーマットに対応しており、モデルサイズを大幅に削減し、メモリ使用量を抑えられます。 - vLLM:
高スループットの推論・デプロイエンジンです。PagedAttentionやFlash Attention 3などの高度な機能を備えており、大規模モデルの提供を非常に効率的に行えます。
高度なカーネルと量子化を活用する:
- Flash Attention:
効率的なアテンション実装で、特に長いシーケンスを処理する場合にメモリ使用量を大幅に削減し、計算速度を向上させます。 - 混合精度と量子化(mxfp4):
GPT-OSSはmxfp4の4ビット浮動小数点フォーマットに対応しています。HopperまたはBlackwell GPUのTritonカーネルと組み合わせて使用することで、VRAM使用量を極限まで抑え、推論速度を大幅に向上させられます。 - MegaBlocks MoEカーネル:
Mixture-of-Experts(MoE)モデル向けに最適化されたカーネルで、Hopperアーキテクチャ以外のGPUでの効率を向上させます。
transformersライブラリを使用してインストール・最適化する:
公式ではtransformersライブラリの使用を推奨しています。このライブラリには多くの最適化機能がバンドルされています。最高のパフォーマンスを得るには、CUDA 12.8向けにPyTorchとTritonを個別にインストールすることをおすすめします:
# 基本ライブラリをアップグレード
pip install --upgrade accelerate transformers kernels
# (任意) CUDA 12.8とTriton 3.4で最高のパフォーマンスを得るには、このバージョンのPyTorchをインストール
pip install torch==2.8.0 --index-url https://download.pytorch.org/whl/test/cu128
クラウドGPU:小規模開発者にとって賢い選択
ローカルで実行する場合のコストと複雑さが非常に高いため、多くの開発者はクラウドGPUサービスを利用することを好んでいます。
ローカルGPUを選択すべき場合
- 大きな予算があり、数十万~数百万円の初期費用を支払える場合。
- トレーニングや推論の長期的な高負荷なニーズがある場合。
- 厳格なデータプライバシー要件があり、データを自社環境外に流出させられない場合。
- ハードウェア、ソフトウェア、ネットワークを完全に制御したい場合。
クラウドGPUを選択すべき場合
- コストを抑えたい、大規模なハードウェア購入や継続的なメンテナンスを避けたい、従量課金で利用したい場合。
- ニーズが柔軟で、実験段階である、またはワークロードが時間とともに変化する場合。
- 調達を待つことなく、H100やH200などの最新・最強のGPUに即座にアクセスしたい場合。
- 面倒なドライバーのインストール、環境構築、物理的なメンテナンスに対応したくない場合。
Novita AIのようなクラウドGPUでGPT OSSを利用する方法
ステップ1:アカウント登録
Novita AIを初めて利用する場合は、当社のウェブサイトでアカウントを作成してください。登録が完了したら、「GPUs」タブに移動して利用可能なリソースを確認し、利用を開始しましょう。
 Novita AIの高性能GPUを試す
Novita AIの高性能GPUを試す
ステップ2:テンプレートとGPUサーバーの確認
まず、PyTorch、TensorFlow、CUDAなど、プロジェクトのニーズに合ったテンプレートを選択してください。PyTorch 2.2.1やCUDA 11.8.0など、要件に合ったバージョンを選びます。次に、十分なVRAM、RAM、ディスク容量を備え、要求の厳しいワークロードを処理できる高性能を提供するA100 GPUサーバー構成を選択してください。

ステップ3:デプロイ設定のカスタマイズ
テンプレートとGPUを選択した後、オペレーティングシステムのバージョン(例:CUDA 11.8)などのパラメータを調整してデプロイ設定をカスタマイズできます。その他の設定も変更して、プロジェクトの特定の要件に合わせた環境を構築できます。
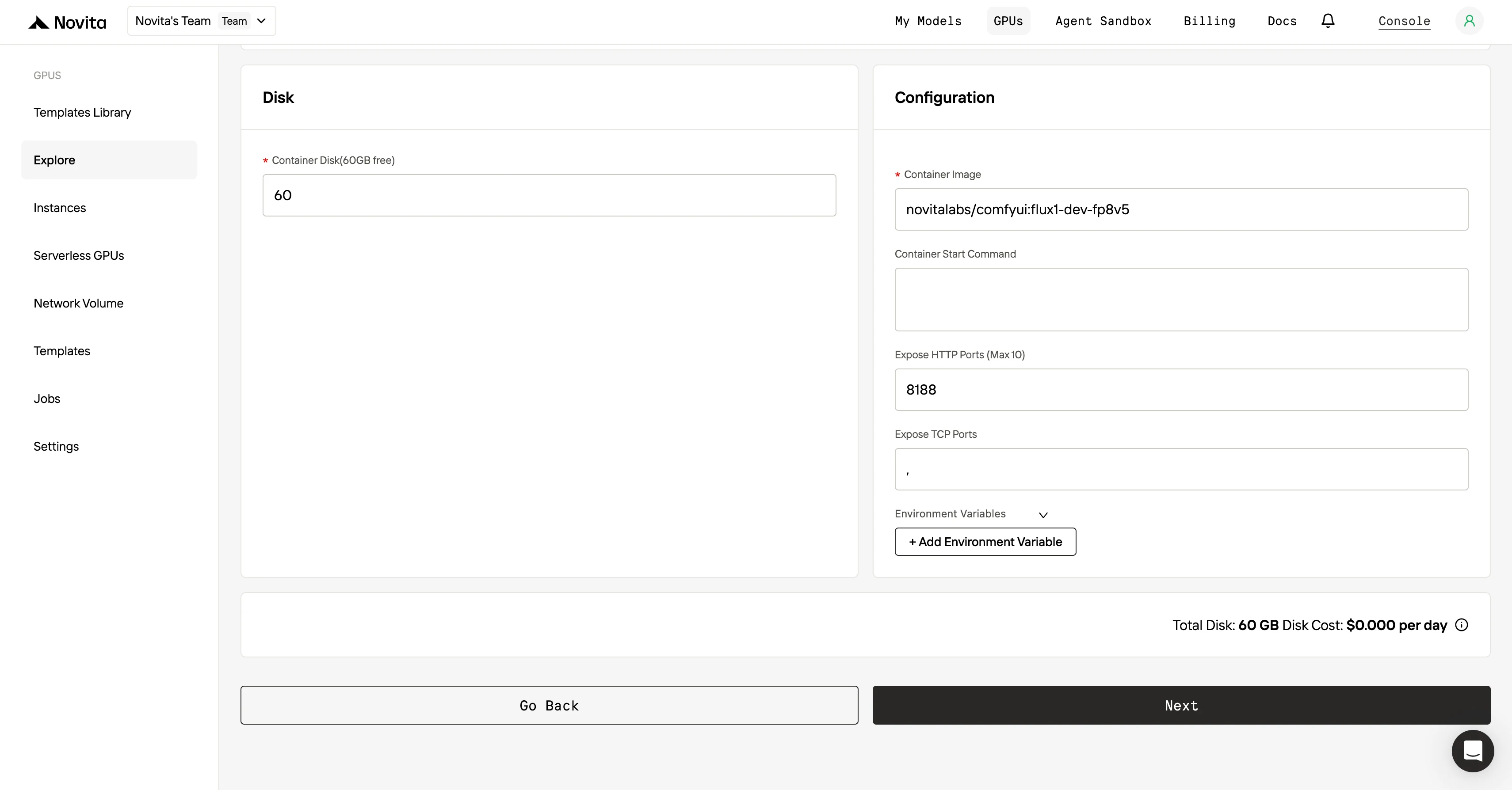
ステップ4:インスタンスの起動
テンプレートとデプロイ設定が確定したら、「Launch Instance」をクリックしてGPUインスタンスをセットアップします。環境のセットアップが開始され、AIタスクにGPUリソースを使用できるようになります。
最大の効率と利便性を求めるならAPIを活用しましょう!
Novita AIは131Kコンテキストに対応したGPT-OSS 120B APIを提供しており、料金は入力$0.1/出力$0.5です。またNovita AIはGPT-OSS 20Bも提供しており、131コンテキストに対応、料金は入力$0.05/出力$0.2で、GPT OSSのコードエージェントの可能性を最大限に引き出すための強力なサポートを提供します。
Novita AI
ステップ1:ログインしてモデルライブラリにアクセス
アカウントにログインし、モデルライブラリボタンをクリックしてください。
 今すぐGPT OSSを試す!
今すぐGPT OSSを試す!
ステップ2:モデルを選択
利用可能なオプションを閲覧し、ニーズに合ったモデルを選択してください。

ステップ3:無料トライアルを開始
選択したモデルの機能を探索するために、無料トライアルを開始してください。

ステップ4:APIキーの取得
APIでの認証のために、新しいAPIキーを発行します。「設定」ページに移動すると、画像の指示に従ってAPIキーをコピーできます。

ステップ5:APIのインストール 使用するプログラミング言語専用のパッケージマネージャーを使用してAPIをインストールしてください。 インストール後、必要なライブラリを開発環境にインポートします。APIキーでAPIを初期化することで、Novita AI LLMとの連携を開始できます。以下はPythonユーザー向けのチャット補完APIの使用例です。
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
GPT-OSSの能力を最大限に引き出すには、VRAM要件を理解することが重要です:
- GPT-OSS 20Bは少なくとも16GBのVRAMが必要なため、RTX 4060 Ti(16GB)のような高性能なコンシューマーGPUで実行でき、個人や愛好家でも利用しやすくなっています。
- GPT-OSS 120Bは80GBのVRAMを必要とし、NVIDIA H100のようなプロフェッショナルなデータセンターGPUが必要となるため、多くの個人や小規模チームには手が届きません。
ローカルデプロイは最も制御性が高いものの、ハードウェアコストが高く技術的な複雑さも伴います。Llama.cppやvLLMのような軽量な推論フレームワーク、mxfp4量子化やFlash Attentionなどの技術を活用することで、VRAMの必要量を削減できます。
ほとんどの開発者にとって、クラウドGPUはより賢い選択です。多額の初期費用がかからず、最高級のハードウェアに即座にアクセスできるためです。同時に、Novita AIのようなマネージドAPIサービスを利用すればさらに簡単です:APIを呼び出すだけで、ハードウェアやデプロイの対応をする必要なくGPT-OSSを利用できます。これはパフォーマンス、コスト、利便性のバランスを最適化する最良の方法であり、誰もが強力なAIを利用できるようにします。
よくある質問
GPT-OSSを実行するために必要なVRAMはどれくらいですか?
GPT-OSS 20B:少なくとも16GBのVRAMが必要です。
GPT-OSS 120B:少なくとも80GBのVRAMが必要です。
GPT-OSS 20Bをローカルで実行する最も安価な方法は何ですか? NVIDIA RTX 4060 Ti(16GB)のような16GB VRAM搭載のコンシューマーGPUと、GGUF量子化モデルを使用したLlama.cppのような軽量フレームワークを利用することです。
GPT-OSSのVRAM使用量を削減する方法は?
内蔵のメモリ最適化機能を備えた軽量フレームワーク(Llama.cpp、vLLM)を使用する。
モデルを量子化(mxfp4またはGGUFを使用)して精度を下げ、メモリフットプリントを小さくする。
特に長いテキストを処理する場合、Flash Attentionなどの効率的なカーネルを有効にする。
Novita AIは、シンプルなAPIを使用してAIモデルを容易にデプロイできる方法を開発者に提供するとともに、構築とスケーリングのための手頃で信頼性の高いGPUクラウドを提供するAIクラウドプラットフォームです。



