

Первый открытый серия больших моделей от OpenAI, GPT-OSS, уже доступна. Благодаря эффективной архитектуре Mixture-of-Experts (MoE), поддержке контекста длиной до 128k токенов и высокой производительности в задачах на рассуждения, науку и программирование, она открывает новые возможности для разработчиков. Теперь любой может скачать и запустить эту продвинутую языковую модель на собственном оборудовании. Но возникает ключевой вопрос: Сколько VRAM на самом деле нужно для запуска GPT-OSS?
Эта статья поможет вам разобраться во всём:
- Рекомендации по выбору GPU: Какие видеокарты подойдут лучше всего — от потребительских до решений для дата-центров?
- Оптимизация использования VRAM: Как с помощью квантования и новых фреймворков снизить потребление ресурсов?
- Варианты развертывания: Что выгоднее — локальный GPU или облачный?
- Самый простой способ доступа: Как использовать API-сервисы и избежать проблем с оборудованием?
Независимо от того, являетесь ли вы независимым разработчиком или небольшой командой, это руководство поможет вам сделать самый оптимальный выбор.
Сколько VRAM нужно для GPT OSS?
GPT OSS — это сверхэффективная и масштабируемая архитектура большой языковой модели. Она использует подход под названием Mixture-of-Experts (MoE) в сочетании с авторегрессивным Transformer-дизайном. Благодаря разреженной активации она может запускать очень большие модели значительно быстрее и эффективнее. Также она поддерживает сверхдлинные контексты — до 128 000 токенов, поэтому легко справляется с длинными документами или сложными диалогами. Архитектура сочетает позиционное кодирование RoPE и переключается между глобальными и локальными окнами внимания, что позволяет эффективно обрабатывать как детализированный, так и общий контент. GPT OSS показывает очень высокую производительность в задачах на рассуждения, науку и программирование.
Также с ней удобно работать, поскольку она напрямую совместима с OpenAI API и популярными токенизаторами, поэтому разработчики могут легко интегрировать её в свои существующие рабочие процессы без лишних усилий. Для обучения GPT OSS используются огромные наборы высококачественных данных, модель обучается на множестве GPU, а также применяет обучение с подкреплением, чтобы обеспечить безопасность, надёжность и качественное следование инструкциям.
Ещё одно преимущество — поддержка различных режимов рассуждений, поэтому вы можете балансировать между скоростью, точностью и стоимостью в зависимости от ваших потребностей. Кроме того, GPT OSS создана для использования инструментов и отлично справляется с управлением форматов диалогов и ролей, поэтому она очень гибкая и безопасна даже для самых требовательных и сложных приложений.
| Модель | Слои | Общее количество параметров | Активных параметров на токен | Общее количество экспертов | Активных экспертов на токен | Длина контекста | Требования к VRAM на одном GPU |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16GB |
Советы по выбору GPU для GPT OSS
- Объём VRAM — самый важный параметр:
- Для GPT-OSS 20B вам понадобится GPU с объёмом памяти не менее 16 ГБ.
- Для GPT-OSS 120B вам нужен GPU с объёмом VRAM не менее 80 ГБ.
- Архитектура GPU имеет значение:
Модель лучше всего работает на новых архитектурах GPU. В официальной документации explicitly указано, что она оптимизирована для чипов Hopper и Blackwell — например, H100, H200 и GB200, поэтому использование одного из них обеспечит максимальную производительность. - Программное обеспечение и драйверы:
Обычно лучше выбирать GPU NVIDIA, поскольку их экосистема CUDA очень зрелая и хорошо поддерживается для задач ИИ. Большинство крупных библиотек ИИ, таких как Transformers, Triton или vLLM, глубоко оптимизированы под CUDA.
Рекомендуемые GPU
Для GPT-OSS 20B (требуется не менее 16 ГБ VRAM):
- Потребительские или профессиональные карты, например:
- NVIDIA RTX 4090 (24 ГБ)
- NVIDIA RTX 4080 (16 ГБ)
- NVIDIA RTX 4060 Ti (16 ГБ)
- NVIDIA RTX 6000 Ada (48 ГБ, профессиональная карта)
- AMD Radeon RX 7900 XTX (24 ГБ)
Для GPT-OSS 120B (требуется не менее 80 ГБ VRAM):
- Карты для дата-центров, например:
- NVIDIA H100 (80 ГБ)
- NVIDIA H200 (141 ГБ)
- NVIDIA A100 (80 ГБ)
- NVIDIA A800 (80 ГБ)
Вы можете уточнить актуальные цены на Novita AI! Узнать цену GPU!
Как оптимизировать использование VRAM для GPT OSS?
Используйте более лёгкие фреймворки для инференса:
- Llama.cpp:
Это кроссплатформенный лёгкий движок для инференса, который работает как на CPU, так и на GPU (CUDA, Metal, Vulkan). Он поддерживает квантованные форматы, такие как GGUF, которые могут значительно уменьшить размер модели и снизить потребление памяти. - vLLM:
Высокопроизводительный движок для инференса и развертывания моделей. Он оснащён продвинутыми функциями, такими как PagedAttention и Flash Attention 3, что делает его очень эффективным для обслуживания больших моделей.
Используйте продвинутые ядра и квантование:
- Flash Attention:
Это эффективная реализация механизма внимания, которая может значительно снизить потребление памяти и ускорить вычисления, особенно при работе с длинными последовательностями. - Смешанная точность и квантование (mxfp4):
GPT-OSS поддерживает 4-битный формат чисел с плавающей точкой mxfp4. При использовании с ядрами Triton на GPU архитектуры Hopper или Blackwell вы получаете очень низкое потребление VRAM и высокую скорость инференса. - Ядро MegaBlocks MoE:
Это оптимизированное ядро для моделей Mixture-of-Experts (MoE), которое помогает повысить эффективность на GPU, не относящихся к архитектуре Hopper.
Установка и оптимизация через библиотеку transformers:
Официально рекомендуется использовать библиотеку transformers, которая включает в себя множество этих оптимизаций. Для максимальной производительности вы можете установить PyTorch и Triton специально для CUDA 12.8:
# Upgrade the basic libraries
pip install --upgrade accelerate transformers kernels
# (Optional) For best performance with CUDA 12.8 and Triton 3.4, install this version of PyTorch
pip install torch==2.8.0 --index-url https://download.pytorch.org/whl/test/cu128
Облачные GPU: умный выбор для небольших разработчиков
Поскольку стоимость и сложность локального запуска могут быть довольно высокими, большинство разработчиков на самом деле предпочитают использовать облачные GPU-сервисы.
Когда выбирать локальный GPU
- У вас большой бюджет, и вы можете позволить себе расходы в десятки или даже сотни тысяч долларов upfront.
- У вас есть долгосрочные потребности с высокой нагрузкой для обучения или инференса.
- У вас строгие требования к конфиденциальности данных, и вы не можете позволить данным покидать вашу собственную среду.
- Вы хотите иметь полный контроль над оборудованием, программным обеспечением и сетевой инфраструктурой.
Когда выбирать облачный GPU
- Вы чувствительны к стоимости и хотите избежать крупных закупок оборудования и постоянных расходов на обслуживание — достаточно платить только за то, что используете.
- Ваши потребности гибкие: возможно, вы всё ещё проводите эксперименты, или ваша рабочая нагрузка меняется со временем.
- Вы хотите получить мгновенный доступ к новейшим, самым мощным GPU, таким как H100 или H200, без ожидания закупок.
- Вы не хотите разбираться с сложной установкой драйверов, настройкой окружения или физическим обслуживанием.
Как получить доступ к GPT OSS на облачных GPU, например, через Novita AI?
Шаг 1: Зарегистрируйте аккаунт Если вы новичок на Novita AI, начните с создания аккаунта на нашем сайте. После регистрации перейдите на вкладку “GPU”, чтобы ознакомиться с доступными ресурсами и начать работу.

Попробуйте высокопроизводительные GPU от Novita AI
Шаг 2: Изучение шаблонов и GPU-серверов Начните с выбора шаблона, соответствующего потребностям вашего проекта: например, PyTorch, TensorFlow или CUDA. Выберите версию, подходящую под ваши требования, например PyTorch 2.2.1 или CUDA 11.8.0. Затем выберите конфигурацию GPU-сервера A100, которая обеспечивает высокую производительность для обработки требовательных рабочих нагрузок с большим объёмом VRAM, оперативной памяти и дискового пространства.

Шаг 3: Настройте развертывание После выбора шаблона и GPU настройте параметры развертывания: измените такие параметры, как версия операционной системы (например, CUDA 11.8). Вы также можете подкорректировать другие конфигурации, чтобы адаптировать окружение под специфические требования вашего проекта.
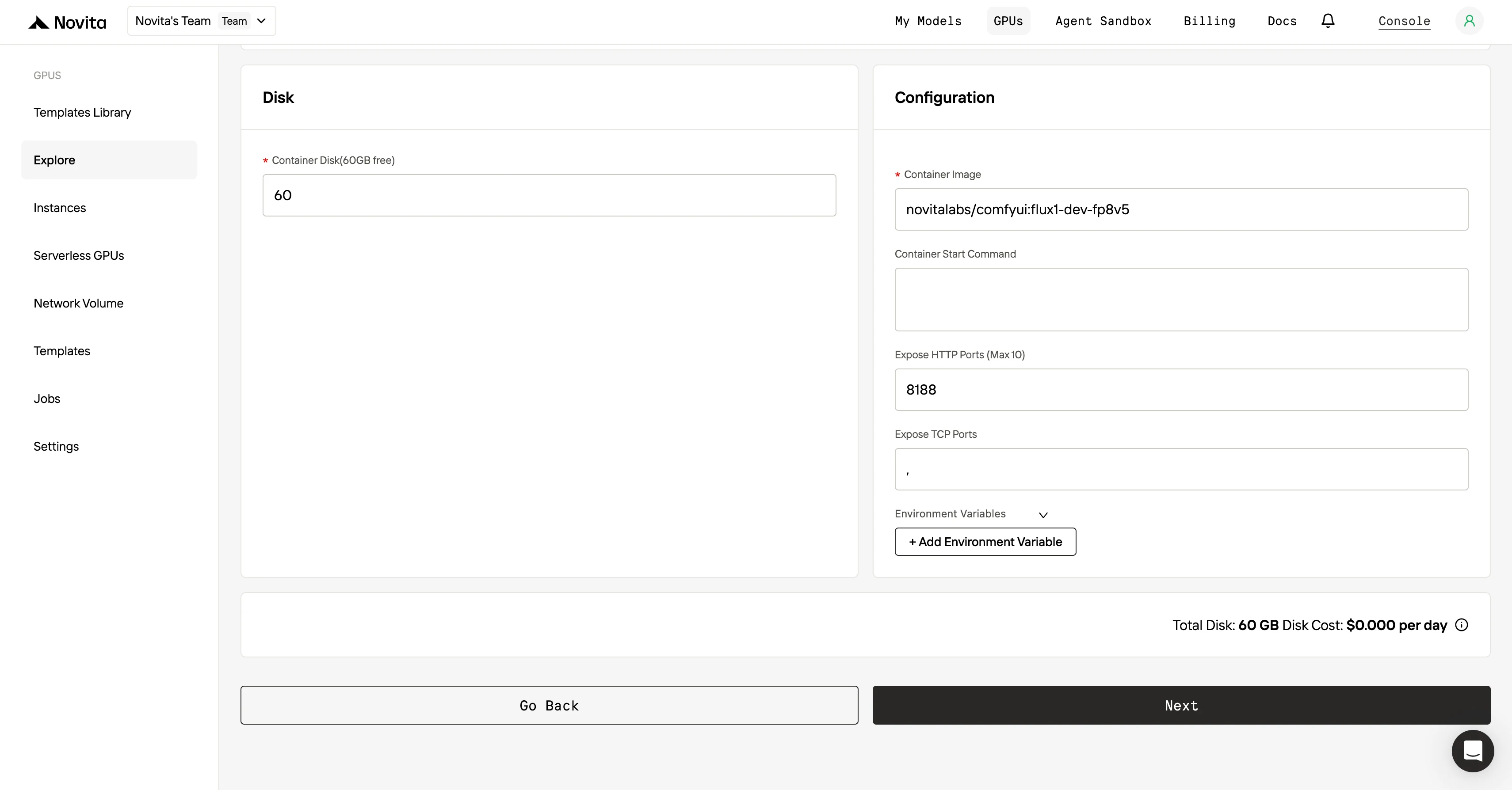
Шаг 4: Запустите инстанс После того как вы окончательно настроили шаблон и параметры развертывания, нажмите кнопку “Launch Instance”, чтобы создать ваш GPU-инстанс. Начнётся настройка окружения, после чего вы сможете начать использовать ресурсы GPU для задач ИИ.
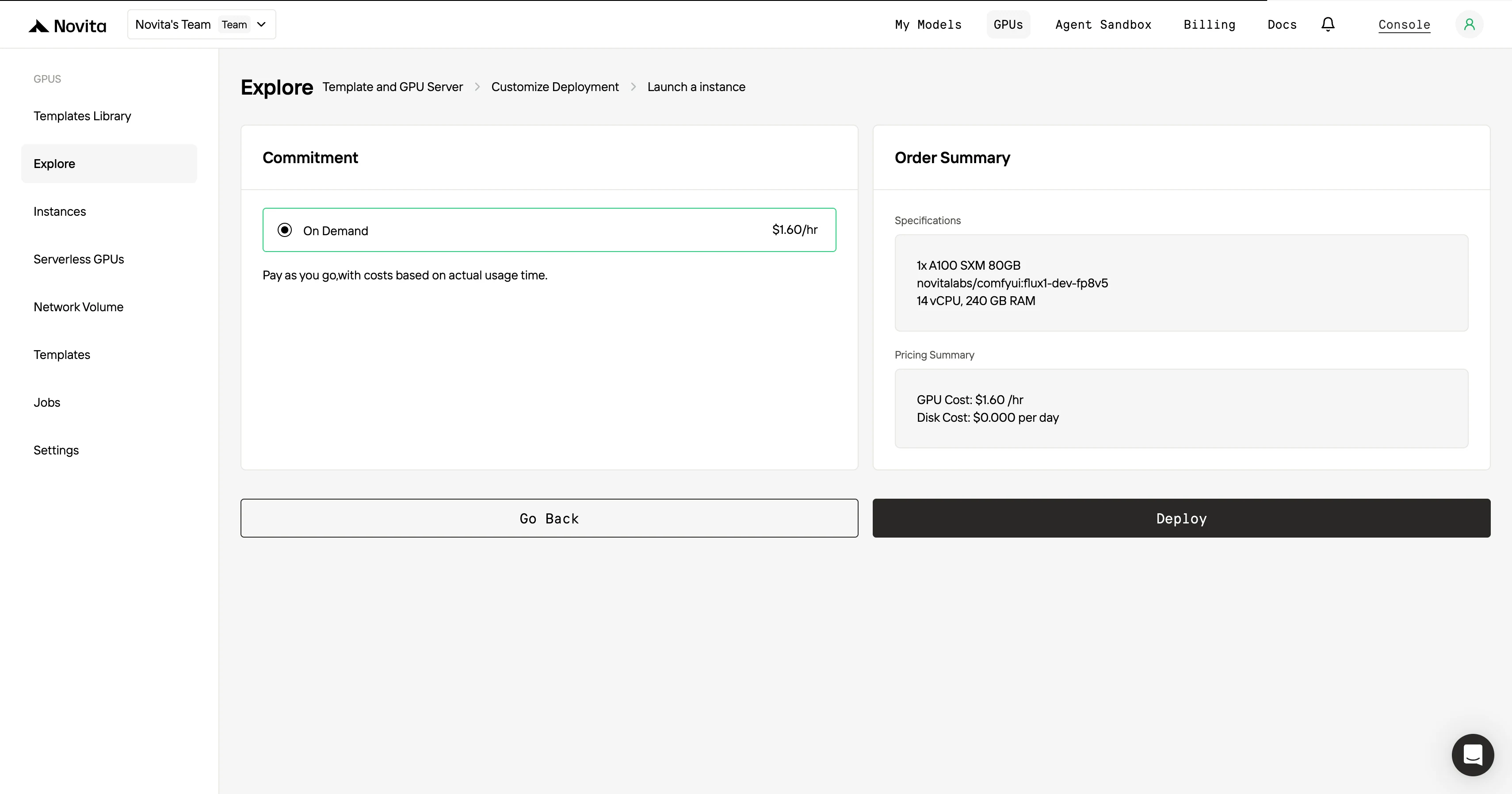
Для максимальной эффективности и удобства используйте API!
Novita AI предоставляет API для GPT-OSS 120B с контекстом 131K и стоимостью $0.1 за входной токен и $0.5 за выходной токен. Novita AI также предоставляет GPT-OSS 20B с контекстом 131 токенов и стоимостью $0.05 за входной токен и $0.2 за выходной токен, что обеспечивает мощную поддержку для максимального раскрытия потенциала GPT OSS в качестве кодового агента.
Novita AI
Шаг 1: Войдите в аккаунт и перейдите в библиотеку моделей Войдите в свой аккаунт и нажмите кнопку Библиотека моделей.

Шаг 2: Выберите модель Просмотрите доступные варианты и выберите модель, подходящую под ваши потребности.

Шаг 3: Начните бесплатный пробный период Начните бесплатный пробный период, чтобы изучить возможности выбранной модели.

Шаг 4: Получите ваш API-ключ Для аутентификации через API мы предоставим вам новый API-ключ. Перейдя на страницу «Настройки», вы можете скопировать API-ключ, как показано на изображении.

Шаг 5: Установите API Установите API с помощью менеджера пакетов, соответствующего вашему языку программирования.
После установки импортируйте необходимые библиотеки в ваше окружение для разработки. Инициализируйте API с помощью вашего API-ключа, чтобы начать взаимодействие с LLM от Novita AI. Ниже приведён пример использования API завершений чата для пользователей Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Чтобы раскрыть весь потенциал GPT-OSS, важно понимать требования к VRAM:
- GPT-OSS 20B требует не менее 16 ГБ VRAM, поэтому она запускается на высокопроизводительных потребительских GPU, таких как RTX 4060 Ti (16 ГБ), что делает её доступной для частных лиц и энтузиастов.
- GPT-OSS 120B требует 80 ГБ VRAM, для неё нужны профессиональные GPU для дата-центров, такие как NVIDIA H100, которые недоступны для большинства частных лиц и небольших команд.
Локальное развертывание даёт максимальный контроль, но сопряжено с высокими затратами на оборудование и технической сложностью. Использование лёгких фреймворков для инференса, таких как Llama.cpp или vLLM, а также техник вроде квантования mxfp4 и Flash Attention, помогает снизить потребность в VRAM.
Для большинства разработчиков облачные GPU — более разумный выбор: нет больших первоначальных затрат, а вы получаете мгновенный доступ к оборудованию высшего класса. При этом управляемые API-сервисы, такие как Novita AI, упрощают работу ещё больше: достаточно вызвать API, и вы можете использовать GPT-OSS, вообще не разбираясь с оборудованием или развертыванием. Это лучший способ сбалансировать производительность, стоимость и удобство, а также сделать мощный ИИ доступным для каждого.
Часто задаваемые вопросы
Сколько VRAM нужно для запуска GPT-OSS?
GPT-OSS 20B: не менее 16 ГБ VRAM.
GPT-OSS 120B: не менее 80 ГБ VRAM.
Какой самый бюджетный способ запустить GPT-OSS 20B локально? Используйте потребительскую GPU с объёмом 16 ГБ VRAM, например NVIDIA RTX 4060 Ti (16 ГБ), и лёгкий фреймворк вроде Llama.cpp с квантованной моделью в формате GGUF.
Как снизить потребление VRAM для GPT-OSS?
Используйте лёгкие фреймворки (Llama.cpp, vLLM) со встроенными оптимизациями памяти.
Квантуйте модель (используйте mxfp4 или GGUF) для снижения точности и уменьшения занимаемого объёма памяти.
Включите эффективные ядра, такие как Flash Attention, особенно при работе с длинными текстами.
Novita AI — это облачная ИИ-платформа, которая предоставляет разработчикам простой способ развертывания ИИ-моделей с помощью нашего простого API, а также доступное и надёжное облако GPU для построения и масштабирования решений.



