

La primera serie de modelos grandes de código abierto de OpenAI, GPT-OSS, ya está aquí. Con su eficiente arquitectura de Mezcla de Expertos (MoE), soporte para una longitud de contexto de hasta 128k y un rendimiento sobresaliente en razonamiento, ciencia y programación, abre nuevas oportunidades para los desarrolladores. Ahora cualquier persona puede descargar y ejecutar este modelo de lenguaje avanzado en su propio hardware. Pero hay una pregunta clave: ¿Cuánta VRAM necesitas realmente para ejecutar GPT-OSS?
Este artículo te lo explica todo:
- Recomendaciones de GPU: ¿Qué tarjetas son las mejores, desde el nivel de consumo hasta el de centros de datos?
- Optimización de VRAM: ¿Cómo puedes usar la cuantización y nuevos frameworks para reducir el uso de recursos?
- Opciones de despliegue: GPU local frente a GPU en la nube: ¿qué opción es más rentable?
- Acceso más sencillo: ¿Cómo usar los servicios de API y evitar dolores de cabeza con el hardware?
Tanto si eres un desarrollador independiente como un equipo pequeño, esta guía te ayudará a tomar la decisión más inteligente.
¿Cuánta VRAM necesita GPT OSS?
GPT OSS es una arquitectura de modelo de lenguaje grande supereficiente y escalable. Utiliza lo que se llama Mezcla de Expertos (MoE), junto con un diseño de Transformer autorregresivo. Gracias a la activación dispersa, puede ejecutar modelos muy grandes de forma mucho más rápida y eficiente. También soporta contextos muy largos, de hasta 128.000 tokens, por lo que puede manejar fácilmente documentos extensos o conversaciones complejas. La arquitectura combina la codificación de posiciones RoPE y alterna entre ventanas de atención globales y locales, lo que le permite gestionar tanto contenido detallado como general. GPT OSS es muy potente en lo que respecta a razonamiento, ciencia y programación.
También es fácil de usar porque es directamente compatible con la API de OpenAI y los tokenizadores más populares, por lo que los desarrolladores pueden integrarlo en sus flujos de trabajo existentes sin demasiados problemas. Para el entrenamiento, GPT OSS utiliza conjuntos de datos masivos y de alta calidad, se entrena en muchas GPUs y además usa aprendizaje por refuerzo para garantizar que sea seguro, fiable y bueno siguiendo instrucciones.
Otra característica interesante es que soporta diferentes modos de razonamiento, por lo que puedes equilibrar la velocidad, la precisión y el coste según tus necesidades. Además, GPT OSS está diseñado para el uso de herramientas y es excelente gestionando formatos de diálogo y roles, por lo que es muy flexible y seguro incluso para las aplicaciones más exigentes o complejas.
| Modelo | Capas | Parámetros Totales | Parámetros Activos Por Token | Expertos Totales | Expertos Activos Por Token | Longitud de Contexto | Requisito de VRAM por GPU Individual |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16GB |
Consejos para elegir una GPU para GPT OSS
- El tamaño de la VRAM es lo más importante:
- Para GPT-OSS 20B, necesitarás una GPU con al menos 16 GB de memoria.
- Para GPT-OSS 120B, necesitarás una GPU con al menos 80 GB de VRAM.
- La arquitectura de la GPU es importante: El modelo funciona mejor con arquitecturas de GPU más recientes. La documentación oficial indica específicamente que está optimizado para chips Hopper y Blackwell, como el H100, H200 y GB200, por lo que usar uno de estos te dará el mejor rendimiento.
- Software y controladores: Las GPUs NVIDIA suelen ser la mejor opción, ya que su ecosistema CUDA está muy maduro y es muy compatible con las tareas de IA. La mayoría de las bibliotecas de IA importantes, como Transformers, Triton o vLLM, están profundamente optimizadas para CUDA.
GPUs recomendadas
Para GPT-OSS 20B (necesita al menos 16 GB de VRAM):
- Tarjetas de consumo o profesionales como:
- NVIDIA RTX 4090 (24GB)
- NVIDIA RTX 4080 (16GB)
- NVIDIA RTX 4060 Ti (16GB)
- NVIDIA RTX 6000 Ada (48GB, tarjeta profesional)
- AMD Radeon RX 7900 XTX (24GB)
Para GPT-OSS 120B (necesita al menos 80 GB de VRAM):
- Tarjetas de centros de datos como:
- NVIDIA H100 (80GB)
- NVIDIA H200 (141GB)
- NVIDIA A100 (80GB)
- NVIDIA A800 (80GB)
¡Puedes consultar los precios detallados en Novita AI!
¡Consulta los precios de las GPUs!
¿Cómo optimizar el uso de VRAM para GPT OSS?
Usa frameworks de inferencia más ligeros:
- Llama.cpp: Se trata de un motor de inferencia ligero y multiplataforma que funciona tanto en CPU como en GPU (CUDA, Metal, Vulkan). Soporta formatos cuantizados como GGUF, que pueden reducir drásticamente el tamaño del modelo y disminuir el uso de memoria.
- vLLM: Un motor de inferencia y despliegue de alto rendimiento. Cuenta con funciones avanzadas como PagedAttention y Flash Attention 3, lo que lo hace muy eficiente para servir modelos grandes.
Aprovecha kernels avanzados y cuantización:
- Flash Attention: Se trata de una implementación de atención eficiente que puede reducir enormemente el uso de memoria y acelerar los cálculos, especialmente cuando trabajas con secuencias largas.
- Precisión mixta y cuantización (mxfp4): GPT-OSS soporta el formato de punto flotante de 4 bits mxfp4. Cuando se usa con kernels Triton en GPUs Hopper o Blackwell, obtienes un uso de VRAM muy bajo y velocidades de inferencia muy altas.
- Kernel MegaBlocks MoE: Se trata de un kernel optimizado para modelos de Mezcla de Expertos (MoE), que ayuda a aumentar la eficiencia en GPUs que no tienen arquitectura Hopper.
Instala y optimiza mediante la biblioteca transformers:
La recomendación oficial es usar la biblioteca transformers, que incluye muchas de estas optimizaciones. Para obtener el mejor rendimiento, puedes instalar PyTorch y Triton específicamente para CUDA 12.8:
# Upgrade the basic libraries
pip install --upgrade accelerate transformers kernels
# (Optional) For best performance with CUDA 12.8 and Triton 3.4, install this version of PyTorch
pip install torch==2.8.0 --index-url https://download.pytorch.org/whl/test/cu128
GPUs en la nube: una opción inteligente para desarrolladores pequeños
Debido a que el coste y la complejidad de ejecutar cosas de forma local puede ser bastante alto, la mayoría de los desarrolladores prefieren usar servicios de GPU en la nube.
Cuándo elegir una GPU local
- Tienes un presupuesto elevado y puedes permitirte decenas o incluso cientos de miles de dólares por adelantado.
- Tienes necesidades a largo plazo de alta carga para entrenamiento o inferencia.
- Tienes requisitos estrictos de privacidad de datos y no puedes permitir que los datos salgan de tu propio entorno.
- Quieres control total sobre el hardware, el software y la red.
Cuándo elegir una GPU en la nube
- Eres sensible al coste y quieres evitar grandes compras de hardware y mantenimiento continuo: solo pagas por lo que usas.
- Tus necesidades son flexibles, tal vez todavía estés experimentando o tu carga de trabajo cambie con el tiempo.
- Quieres acceso instantáneo a las GPUs más recientes y potentes, como la H100 o la H200, sin tener que esperar a los procesos de compra.
- No quieres lidiar con instalaciones complicadas de controladores, configuración de entornos o mantenimiento físico.
¿Cómo acceder a GPT OSS en GPUs en la nube como Novita AI?
Paso 1: Regístrate en una cuenta
Si eres nuevo en Novita AI, comienza por crear una cuenta en nuestro sitio web. Una vez registrado, ve a la pestaña “GPUs” para explorar los recursos disponibles y empezar tu recorrido.

Prueba las GPUs de alto rendimiento de Novita AI
Paso 2: Explora plantillas y servidores de GPU**
Comienza por seleccionar una plantilla que se ajuste a las necesidades de tu proyecto, como PyTorch, TensorFlow o CUDA. Elige la versión que se adapte a tus requisitos, como PyTorch 2.2.1 o CUDA 11.8.0. A continuación, selecciona la configuración de servidor de GPU A100, que ofrece un rendimiento potente para manejar cargas de trabajo exigentes con amplia VRAM, RAM y capacidad de disco.

Paso 3: Personaliza tu despliegue
Después de seleccionar una plantilla y una GPU, personaliza la configuración de tu despliegue ajustando parámetros como la versión del sistema operativo (por ejemplo, CUDA 11.8). También puedes modificar otras configuraciones para adaptar el entorno a los requisitos específicos de tu proyecto.
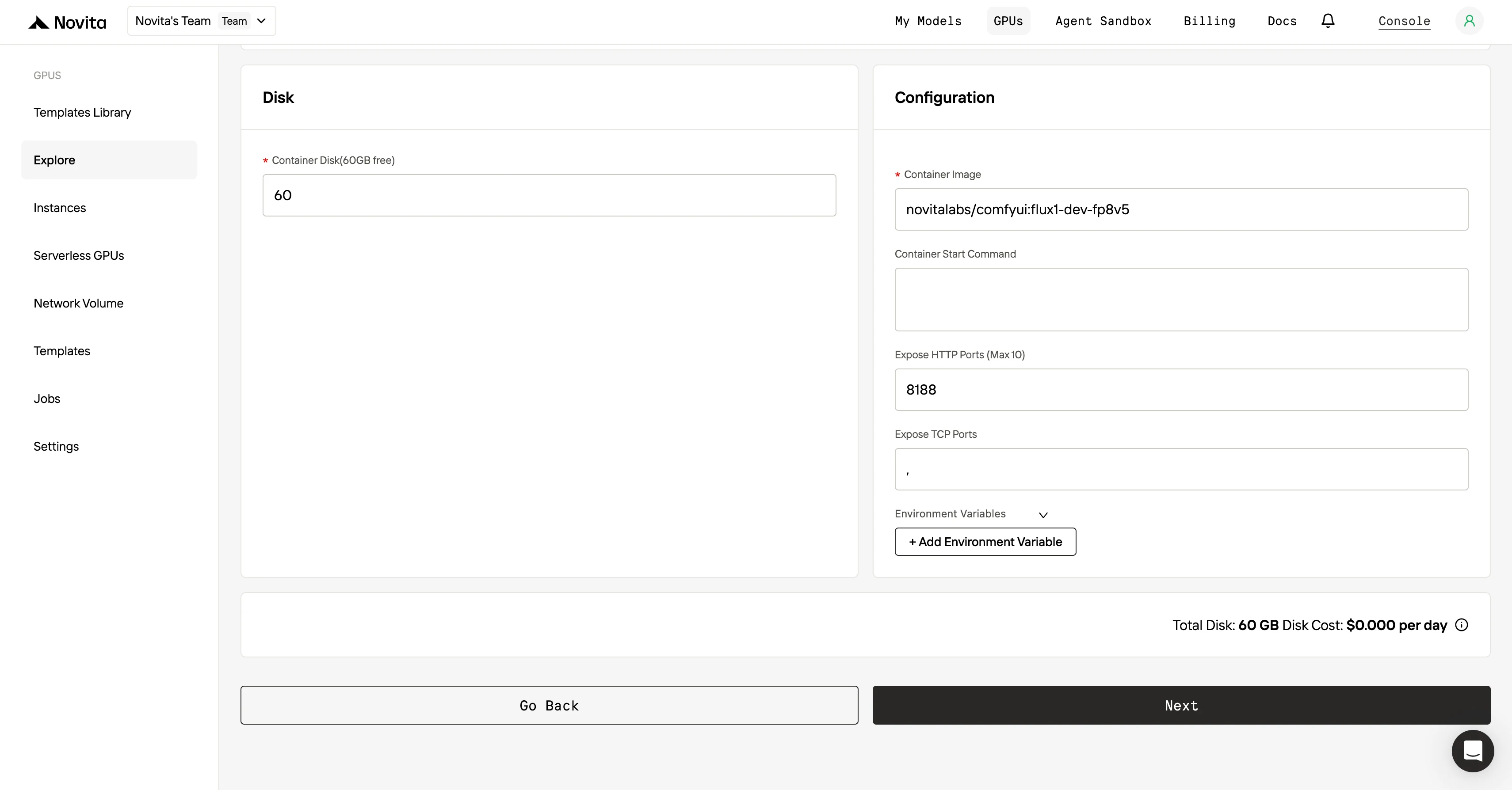
Paso 4: Lanza una instancia**
Una vez que hayas finalizado la plantilla y la configuración de despliegue, haz clic en “Lanzar instancia” para configurar tu instancia de GPU. Esto iniciará la configuración del entorno, permitiéndote empezar a usar los recursos de la GPU para tus tareas de IA.
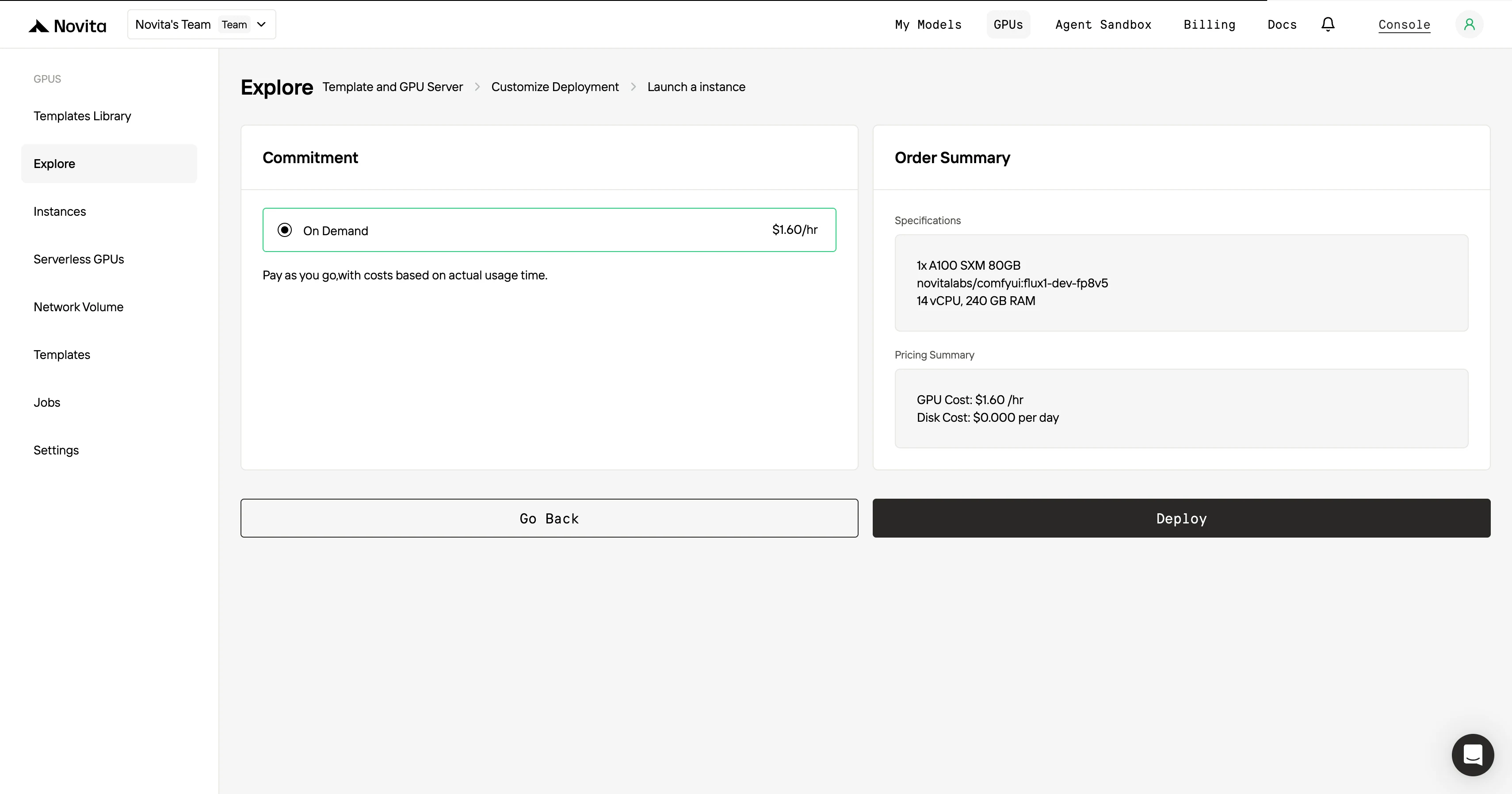
Para máxima eficiencia y comodidad, ¡usa la API!
Novita AI proporciona APIs de GPT-OSS 120B
con 131K de contexto y costes de $0.1 por entrada y $0.5 por salida. Novita AI también proporciona GPT-OSS 20B con 131 de contexto y costes de $0.05 por entrada y $0.2 por salida, ofreciendo un fuerte apoyo para maximizar el potencial del agente de código de GPT OSS.Novita AI
Paso 1: Inicia sesión y accede a la biblioteca de modelos
Inicia sesión en tu cuenta y haz clic en el botón Biblioteca de modelos.

Paso 2: Elige tu modelo
Explora las opciones disponibles y selecciona el modelo que se adapte a tus necesidades.

Paso 3: Inicia tu prueba gratuita
Comienza tu prueba gratuita para explorar las capacidades del modelo seleccionado.

Paso 4: Obtén tu clave de API
Para autenticarte con la API, te proporcionaremos una nueva clave de API. Entrando en la página de “Ajustes”, puedes copiar la clave de API como se indica en la imagen.

Paso 5: Instala la API
Instala la API usando el gestor de paquetes específico de tu lenguaje de programación.
Después de la instalación, importa las bibliotecas necesarias en tu entorno de desarrollo. Inicializa la API con tu clave de API para empezar a interactuar con el LLM de Novita AI. Este es un ejemplo de uso de la API de finalizaciones de chat para usuarios de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Para desbloquear el poder de GPT-OSS, es esencial comprender los requisitos de VRAM:
- GPT-OSS 20B necesita al menos 16 GB de VRAM, por lo que se ejecuta en GPUs de consumo de gama alta como la RTX 4060 Ti (16 GB), lo que lo hace accesible para particulares y entusiastas.
- GPT-OSS 120B requiere 80 GB de VRAM, necesitando GPUs profesionales de centros de datos como la NVIDIA H100, que está fuera del alcance de la mayoría de los particulares y equipos pequeños.
El despliegue local ofrece el mayor control, pero conlleva costes de hardware elevados y complejidad técnica. Usar frameworks de inferencia ligeros como Llama.cpp o vLLM, además de técnicas como la cuantización mxfp4 y Flash Attention, puede ayudar a reducir las necesidades de VRAM.
Para la mayoría de los desarrolladores, las GPUs en la nube son la opción más inteligente: no hay costes iniciales elevados y obtienes acceso instantáneo a hardware de primera categoría. Al mismo tiempo, los servicios de API gestionados como Novita AI lo hacen aún más fácil: solo tienes que llamar a la API y estarás listo para usar GPT-OSS sin tener que lidiar con hardware ni despliegue en absoluto. Esta es la mejor forma de equilibrar rendimiento, coste y comodidad, y pone una IA potente al alcance de todos.
Preguntas frecuentes
¿Cuánta VRAM necesito para ejecutar GPT-OSS? GPT-OSS 20B: al menos 16 GB de VRAM. GPT-OSS 120B: al menos 80 GB de VRAM.
¿Cuál es la forma más económica de ejecutar GPT-OSS 20B de forma local? Usa una GPU de consumo con 16 GB de VRAM, como la NVIDIA RTX 4060 Ti (16 GB), y un framework ligero como Llama.cpp con un modelo cuantizado GGUF.
¿Cómo puedo reducir el uso de VRAM de GPT-OSS? Usa frameworks ligeros (Llama.cpp, vLLM) con optimizaciones de memoria integradas. Cuantiza el modelo (usa mxfp4 o GGUF) para obtener una menor precisión y una huella de memoria más pequeña. Habilita kernels eficientes como Flash Attention, especialmente para textos largos.
Novita AI es una plataforma de IA en la nube que ofrece a los desarrolladores una forma sencilla de desplegar modelos de IA usando nuestra API simple, además de proporcionar una nube de GPU asequible y fiable para construir y escalar.



