

سلسلة النماذج الكبيرة مفتوحة المصدر الأولى من OpenAI، GPT-OSS، متاحة الآن. بفضل بنية الخبراء المختلطين (MoE) الفعالة، ودعم لطول سياق يصل إلى 128 ألف رمز، وأداء قوي في الاستدلال والعلوم والبرمجة، فإنها تقدم فرصًا جديدة للمطورين. يمكن لأي شخص الآن تنزيل وتشغيل هذا النموذج اللغوي المتقدم على أجهزته الخاصة. لكن هناك سؤال رئيسي: كم من ذاكرة الفيديو (VRAM) تحتاج فعلاً لتشغيل GPT-OSS؟
سيتناول هذا المقال النقاط التالية:
- توصيات وحدات المعالجة الرسومية: ما هي البطاقات الأفضل، من مستوى المستهلك إلى مستوى مراكز البيانات؟
- تحسين ذاكرة الفيديو: كيف يمكنك استخدام التكميم (quantization) والأطر الجديدة لتقليل استخدام الموارد؟
- خيارات النشر: وحدات المعالجة الرسومية المحلية مقابل السحابية—أيهما أكثر فعالية من حيث التكلفة؟
- أسهل طريقة للوصول: كيف تستخدم خدمات API وتتجنب متاعب الأجهزة؟
سواء كنت مطورًا مستقلاً أو فريقًا صغيرًا، سيساعدك هذا الدليل على اتخاذ الخيار الأذكى.
كم من ذاكرة الفيديو (VRAM) يحتاج GPT OSS؟
GPT OSS هو بنية نموذج لغوي كبيرة فعالة للغاية وقابلة للتوسع. يستخدم ما يسمى ببنية الخبراء المختلطين (MoE)، إلى جانب تصميم المحول التلقائي الانحدار (autoregressive Transformer). بفضل التنشيط المتناثر (sparse activation)، يمكنه تشغيل النماذج الكبيرة جدًا بشكل أسرع وأكثر كفاءة. كما يدعم سياقات طويلة جدًا تصل إلى 128 ألف رمز، لذا يمكنه التعامل مع المستندات الطويلة أو المحادثات المعقدة بسهولة. تجمع البنية بين ترميز الموضع RoPE وتتحول بين نوافذ الانتباه العامة والمحلية، مما يساعدها على إدارة المحتوى التفصيلي والواسع على حد سواء. يتميز GPT OSS بقوة كبيرة في مجالات الاستدلال والعلوم والبرمجة.
كما أنه سهل الاستخدام لأنه متوافق مباشرة مع واجهة برمجة تطبيقات OpenAI وأدوات الترميز (tokenizers) الشائعة، لذا يمكن للمطورين دمجه في سير العمل الحالي لديهم دون عناء كبير. بالنسبة للتدريب، يستخدم GPT OSS مجموعات بيانات ضخمة وعالية الجودة، ويتم تدريبه على عدد كبير من وحدات المعالجة الرسومية، بالإضافة إلى استخدام التعلم المعزز لضمان أنه آمن وموثوق وجيد في اتباع التعليمات.
هناك ميزة أخرى رائعة وهي أنه يدعم أوضاع استدلال مختلفة، لذا يمكنك الموازنة بين السرعة والدقة والتكلفة وفقًا لاحتياجاتك. علاوة على ذلك، تم بناء GPT OSS لاستخدام الأدوات، وهو رائع في إدارة تنسيقات الحوار والأدوار، لذا فهو مرن وآمن للغاية حتى لأكثر التطبيقات تطلبًا وتعقيدًا.
| النموذج | الطبقات | إجمالي المعلمات | المعلمات النشطة لكل رمز | إجمالي الخبراء | الخبراء النشطون لكل رمز | طول السياق | متطلبات ذاكرة الفيديو لوحدة المعالجة الرسومية الواحدة |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16GB |
نصائح لاختيار وحدة المعالجة الرسومية لـ GPT OSS
- حجم ذاكرة الفيديو هو الأهم:
- بالنسبة لـ GPT-OSS 20B، ستحتاج إلى وحدة معالجة رسومية بذاكرة لا تقل عن 16 جيجابايت.
- بالنسبة لـ GPT-OSS 120B، ستحتاج إلى شيء بذاكرة فيديو لا تقل عن 80 جيجابايت.
- بنية وحدة المعالجة الرسومية مهمة:
يعمل النموذج بشكل أفضل مع بنيات وحدات المعالجة الرسومية الأحدث. تشير الوثائق الرسمية تحديدًا إلى أنه محسّن لشرائح Hopper و Blackwell—مثل H100 و H200 و GB200—لذا فإن استخدام أحد هذه الشرائح سيمنحك أفضل أداء. - البرامج والتعريفات:
عادة ما تكون وحدات المعالجة الرسومية من NVIDIA الخيار الأفضل، حيث أن نظامها البيئي CUDA ناضج للغاية ومدعوم جيدًا لمهام الذكاء الاصطناعي. معظم مكتبات الذكاء الاصطناعي الكبيرة، مثل Transformers و Triton أو vLLM، محسّنة بعمق لـ CUDA.
وحدات المعالجة الرسومية الموصى بها
لـ GPT-OSS 20B (يحتاج إلى ذاكرة فيديو لا تقل عن 16 جيجابايت):
- بطاقات المستهلك أو الاحترافية مثل:
- NVIDIA RTX 4090 (24 جيجابايت)
- NVIDIA RTX 4080 (16 جيجابايت)
- NVIDIA RTX 4060 Ti (16 جيجابايت)
- NVIDIA RTX 6000 Ada (48 جيجابايت، بطاقة احترافية)
- AMD Radeon RX 7900 XTX (24 جيجابايت)
لـ GPT-OSS 120B (يحتاج إلى ذاكرة فيديو لا تقل عن 80 جيجابايت):
- بطاقات مراكز البيانات مثل:
- NVIDIA H100 (80 جيجابايت)
- NVIDIA H200 (141 جيجابايت)
- NVIDIA A100 (80 جيجابايت)
- NVIDIA A800 (80 جيجابايت)
يمكنك التحقق من الأسعار التفصيلية على Novita AI! تحقق من أسعار وحدات المعالجة الرسومية!
كيف تحسن استخدام ذاكرة الفيديو لـ GPT OSS؟
استخدام أطر استدلال أخف:
- Llama.cpp:
هذا هو محرك استدلال خفيف الوزن ومتعدد المنصات يعمل على كل من المعالج المركزي (CPU) ووحدة المعالجة الرسومية (CUDA و Metal و Vulkan). يدعم تنسيقات التكميم مثل GGUF، والتي يمكنها تقليل حجم النموذج بشكل كبير وتقليل استخدام الذاكرة. - vLLM:
محرك استدلال ونشر ذو إنتاجية عالية. يأتي مع ميزات متقدمة مثل PagedAttention و Flash Attention 3، مما يجعله فعالًا للغاية في تقديم النماذج الكبيرة.
الاستفادة من النوى المتقدمة والتكميم:
- Flash Attention:
هذا هو تنفيذ انتباه فعال يمكنه تقليل استخدام الذاكرة بشكل كبير وتسريع الحسابات، خاصة عند العمل مع تسلسلات طويلة. - الدقة المختلطة والتكميم (mxfp4):
يدعم GPT-OSS تنسيق الفاصلة العائمة 4 بت mxfp4. عند استخدامه مع نوى Triton على وحدات المعالجة الرسومية من فئة Hopper أو Blackwell، تحصل على استخدام منخفض جدًا لذاكرة الفيديو وسرعات استدلال سريعة للغاية. - نوى MegaBlocks MoE:
هذا هو نواة محسّنة لنماذج الخبراء المختلطين (MoE)، تساعد في تعزيز الكفاءة على وحدات المعالجة الرسومية التي لا تستخدم بنية Hopper.
التثبيت والتحسين عبر مكتبة transformers:
التوصية الرسمية هي استخدام مكتبة transformers، التي تحتوي على العديد من هذه التحسينات. للحصول على أفضل أداء، يمكنك تثبيت PyTorch و Triton خصيصًا لـ CUDA 12.8:
# Upgrade the basic libraries
pip install --upgrade accelerate transformers kernels
# (Optional) For best performance with CUDA 12.8 and Triton 3.4, install this version of PyTorch
pip install torch==2.8.0 --index-url https://download.pytorch.org/whl/test/cu128
وحدات المعالجة الرسومية السحابية: خيار ذكي للمطورين الصغار
بما أن تكلفة وتعقيد تشغيل الأشياء محليًا يمكن أن يكونا مرتفعين للغاية، يفضل معظم المطورين في الواقع استخدام خدمات وحدات المعالجة الرسومية السحابية.
متى تختار وحدة معالجة رسومية محلية
- لديك ميزانية كبيرة ويمكنك تحمل عشرات أو حتى مئات الآلاف من الدولارات مقدمًا.
- لديك احتياجات طويلة الأجل وعالية الحمل للتدريب أو الاستدلال.
- لديك متطلبات صارمة لخصوصية البيانات ولا يمكنك السماح للبيانات بمغادرة بيئتك الخاصة.
- تريد تحكمًا كاملاً في الأجهزة والبرامج والشبكات.
متى تختار وحدة معالجة رسومية سحابية
- أنت حساس للتكاليف وتريد تجنب مشتريات الأجهزة الكبيرة والصيانة المستمرة—فقط ادفع مقابل ما تستخدمه.
- احتياجاتك مرنة، ربما لا تزال تجرب، أو عبء عملك يتغير بمرور الوقت.
- تريد وصولًا فوريًا إلى أحدث وحدات المعالجة الرسومية الأقوى مثل H100 أو H200، دون انتظار عمليات الشراء.
- لا تريد التعامل مع تثبيتات التعريفات المعقدة، أو إعداد البيئة، أو الصيانة المادية.
كيف يمكنك الوصول إلى GPT OSS على وحدة معالجة رسومية سحابية مثل Novita AI؟
الخطوة 1: تسجيل حساب إذا كنت جديدًا على Novita AI، ابدأ بإنشاء حساب على موقعنا الإلكتروني. بمجرد تسجيلك، انتقل إلى علامة التبويب “وحدات المعالجة الرسومية” لاستكشاف الموارد المتاحة وبدء رحلتك.

جرب وحدات المعالجة الرسومية عالية الأداء من Novita AI
الخطوة 2: استكشاف القوالب وخوادم وحدات المعالجة الرسومية** ابدأ بتحديد قالب يطابق احتياجات مشروعك، مثل PyTorch أو TensorFlow أو CUDA. اختر الإصدار الذي يناسب متطلباتك، مثل PyTorch 2.2.1 أو CUDA 11.8.0. ثم اختر تكوين خادم وحدة المعالجة الرسومية A100، الذي يقدم أداءً قويًا للتعامل مع أحمال العمل الثقيلة مع ذاكرة فيديو وذاكرة وصول عشوائي (RAM) وسعة قرص كافية.

الخطوة 3: تخصيص النشر الخاص بك بعد تحديد القالب ووحدة المعالجة الرسومية، قم بتخصيص إعدادات النشر الخاصة بك عن طريق تعديل المعلمات مثل إصدار نظام التشغيل (مثل CUDA 11.8). يمكنك أيضًا تعديل التكوينات الأخرى لتكييف البيئة مع المتطلبات المحددة لمشروعك.
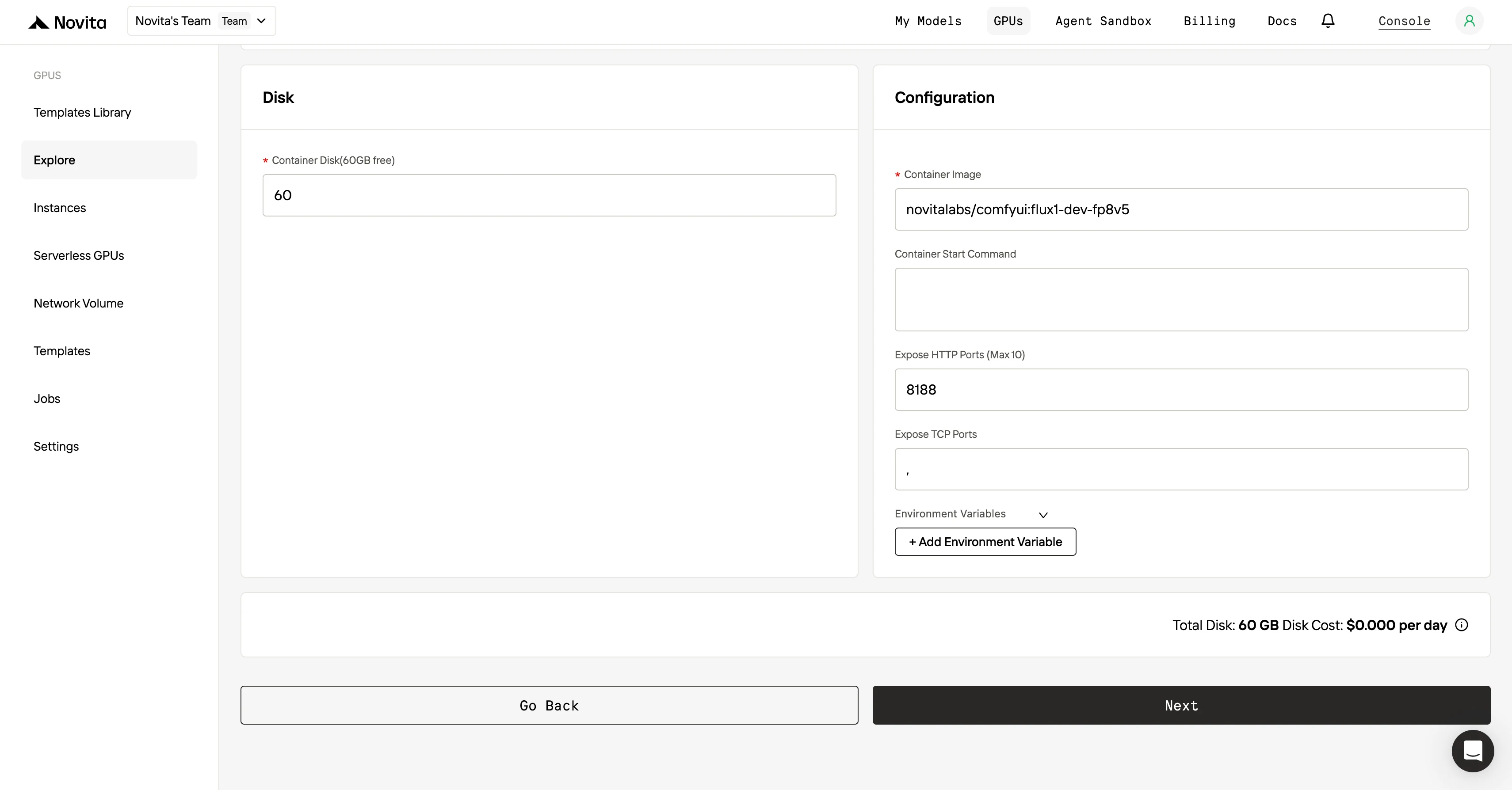
الخطوة 4: إطلاق مثيل**** بمجرد الانتهاء من القالب وإعدادات النشر، انقر على “إطلاق مثيل” لإعداد مثيل وحدة المعالجة الرسومية الخاصة بك. سيؤدي هذا إلى بدء إعداد البيئة، مما يمكنك من البدء في استخدام موارد وحدة المعالجة الرسومية لمهام الذكاء الاصطناعي الخاصة بك.
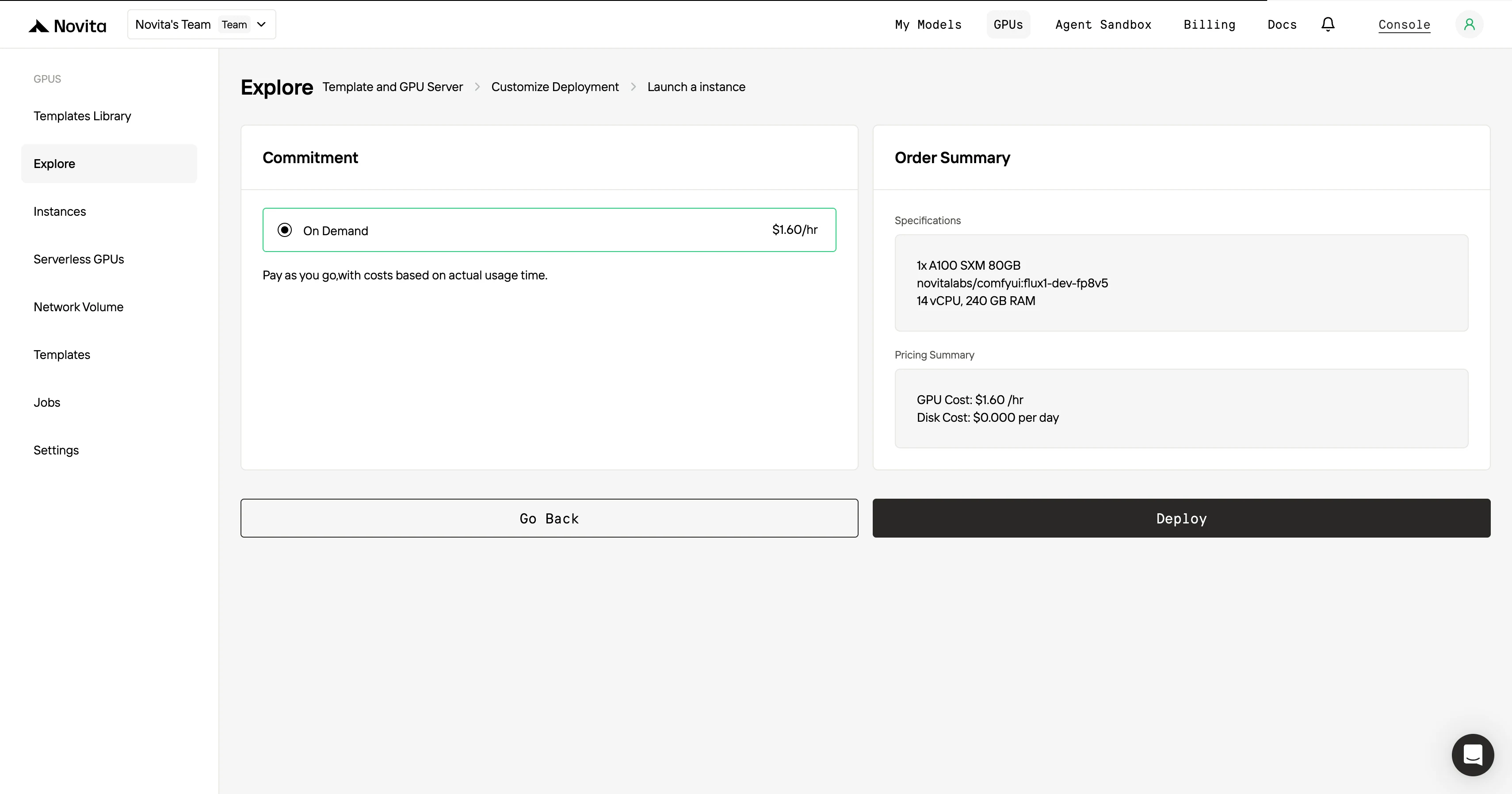
لأقصى قدر من الكفاءة والراحة، استخدم واجهة برمجة التطبيقات (API)!
تقدم Novita AI واجهات برمجة تطبيقات GPT-OSS 120B
مع سياق يصل إلى 131 ألف رمز وتكاليف 0.1 دولار لكل إدخال و 0.5 دولار لكل مخرج. كما تقدم Novita AI أيضًا GPT-OSS 20B مع سياق 131 رمز وتكاليف 0.05 دولار لكل إدخال و 0.2 دولار لكل مخرج، مما يوفر دعمًا قويًا لتعظيم إمكانات وكيل البرمجة لـ GPT OSS.Novita AI
الخطوة 1: تسجيل الدخول والوصول إلى مكتبة النماذج سجل الدخول إلى حسابك وانقر على زر مكتبة النماذج.

الخطوة 2: اختر النموذج الخاص بك تصفح الخيارات المتاحة واختر النموذج الذي يناسب احتياجاتك.

الخطوة 3: ابدأ تجربتك المجانية ابدأ تجربتك المجانية لاستكشاف إمكانات النموذج المحدد.

الخطوة 4: احصل على مفتاح API الخاص بك للمصادقة مع واجهة برمجة التطبيقات، سنزودك بمفتاح API جديد. عند الدخول إلى صفحة “الإعدادات”، يمكنك نسخ مفتاح API كما هو موضح في الصورة.

الخطوة 5: تثبيت واجهة برمجة التطبيقات قم بتثبيت واجهة برمجة التطبيقات باستخدام مدير الحزم الخاص بلغة البرمجة الخاصة بك.
بعد التثبيت، استورد المكتبات الضرورية إلى بيئة التطوير الخاصة بك. قم بتهيئة واجهة برمجة التطبيقات باستخدام مفتاح API الخاص بك لبدء التفاعل مع نموذج اللغوي الكبير من Novita AI. هذا مثال على استخدام واجهة برمجة تطبيقات إكمال الدردشة لمستخدمي بايثون.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
لفتح قوة GPT-OSS، فهم متطلبات ذاكرة الفيديو أمر ضروري:
- GPT-OSS 20B يحتاج إلى ذاكرة فيديو لا تقل عن 16 جيجابايت، لذا يعمل على وحدات المعالجة الرسومية للمستهلك عالية الأداء مثل RTX 4060 Ti (16 جيجابايت)، مما يجعله متاحًا للأفراد والهواة.
- GPT-OSS 120B يتطلب 80 جيجابايت من ذاكرة الفيديو، ويحتاج إلى وحدات معالجة رسومية احترافية لمراكز البيانات مثل NVIDIA H100، وهو أمر غير متاح لمعظم الأفراد والفرق الصغيرة.
يعطي النشر المحلي أكبر قدر من التحكم، لكنه يأتي مع تكاليف أجهزة عالية وتعقيد تقني. يمكن أن تساعد استخدام أطر الاستدلال الخفيفة مثل Llama.cpp أو vLLM، بالإضافة إلى تقنيات مثل التكميم mxfp4 و Flash Attention، في تقليل احتياجات ذاكرة الفيديو.
للمطورين في الغالب، وحدات المعالجة الرسومية السحابية هي الخيار الأذكى—لا توجد تكلفة مقدمًا كبيرة، وتحصل على وصول فوري إلى أجهزة من الفئة الأولى. في نفس الوقت، تجعل خدمات API المُدارة مثل Novita AI الأمر أسهل حتى: فقط اتصل بـ API، وستكون جاهزًا لاستخدام GPT-OSS دون التعامل مع الأجهزة أو النشر على الإطلاق. هذه هي أفضل طريقة لتحقيق التوازن بين الأداء والتكلفة والراحة، وتضع الذكاء الاصطناعي القوي في متناول الجميع.
الأسئلة الشائعة
كم من ذاكرة الفيديو (VRAM) أحتاج لتشغيل GPT-OSS؟
GPT-OSS 20B: ذاكرة فيديو لا تقل عن 16 جيجابايت.
GPT-OSS 120B: ذاكرة فيديو لا تقل عن 80 جيجابايت.
ما هي الطريقة الأكثر فعالية من حيث التكلفة لتشغيل GPT-OSS 20B محليًا؟ استخدم وحدة معالجة رسومية للمستهلك بذاكرة فيديو 16 جيجابايت، مثل NVIDIA RTX 4060 Ti (16 جيجابايت)، وإطار عمل خفيف مثل Llama.cpp مع نموذج مكمم بتنسيق GGUF.
كيف يمكنني تقليل استخدام ذاكرة الفيديو لـ GPT-OSS؟
استخدم أطرًا خفيفة (Llama.cpp, vLLM) مع تحسينات ذاكرة مدمجة.
قم بتكميم النموذج (استخدم mxfp4 أو GGUF) لدقة أقل وبصمة ذاكرة أصغر.
قم بتفعيل النوى الفعالة مثل Flash Attention، خاصة للنصوص الطويلة.
Novita AI هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، بالإضافة إلى توفير سحابة وحدات معالجة رسومية بأسعار معقولة وموثوقة للبناء والتوسع.



