

A primeira série de modelos grandes de código aberto da OpenAI, GPT-OSS, chegou. Com sua arquitetura eficiente de Mistura de Especialistas (MoE), suporte a comprimento de contexto de até 128k e forte desempenho em raciocínio, ciência e programação, ele traz novas oportunidades para desenvolvedores. Qualquer pessoa agora pode baixar e executar esse modelo de linguagem avançado em seu próprio hardware. Mas há uma pergunta chave: Quanta VRAM você realmente precisa para executar o GPT-OSS?
Este artigo vai explicar tudo para você:
- Recomendações de GPU: Quais placas são as melhores, do nível consumidor ao de data center?
- Otimização de VRAM: Como você pode usar quantização e novas estruturas para reduzir o consumo de recursos?
- Opções de implantação: GPU local vs. nuvem — o que é mais econômico?
- Acesso mais fácil: Como usar serviços de API e evitar dores de cabeça com hardware?
Seja você um desenvolvedor independente ou uma pequena equipe, este guia o ajudará a fazer a escolha mais inteligente.
Quanta VRAM o GPT OSS Precisa?
O GPT OSS é uma arquitetura de modelo de linguagem grande super eficiente e escalável. Ele usa o que chamamos de Mistura de Especialistas, ou MoE, juntamente com um design de Transformer autoregressivo. Graças à ativação esparsa, ele pode executar modelos muito grandes de forma muito mais rápida e eficiente. Ele também suporta contextos super longos — de até 128.000 tokens —, então consegue lidar facilmente com documentos longos ou conversas complexas. A arquitetura combina a codificação de posição RoPE e alterna entre janelas de atenção globais e locais, o que ajuda a gerenciar tanto conteúdo detalhado quanto abrangente. O GPT OSS é muito forte quando se trata de raciocínio, ciência e programação.
Também é fácil de trabalhar com ele porque é diretamente compatível com a API OpenAI e tokenizadores populares, então os desenvolvedores podem integrá-lo aos seus fluxos de trabalho existentes sem muito trabalho. Para treinamento, o GPT OSS usa conjuntos de dados massivos e de alta qualidade, é treinado em muitas GPUs e usa aprendizado por reforço para garantir que seja seguro, confiável e bom em seguir instruções.
Outra coisa legal é que ele suporta diferentes modos de raciocínio, então você pode equilibrar entre velocidade, precisão e custo dependendo das suas necessidades. Além disso, o GPT OSS foi construído para uso de ferramentas e é ótimo em gerenciar formatos de diálogo e funções, então é super flexível e seguro mesmo para as aplicações mais exigentes ou complexas.
| Modelo | Camadas | Parâmetros Totais | Parâmetros Ativos Por Token | Total de Especialistas | Especialistas Ativos Por Token | Comprimento de Contexto | Requisito de VRAM por GPU Única |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16GB |
Dicas para Escolher uma GPU para o GPT OSS
- O tamanho da VRAM é o mais importante:
- Para o GPT-OSS 20B, você vai querer uma GPU com pelo menos 16GB de memória.
- Para o GPT-OSS 120B, você vai precisar de algo com pelo menos 80GB de VRAM.
- A arquitetura da GPU importa:
O modelo funciona melhor com arquiteturas de GPU mais novas. A documentação oficial diz especificamente que ele é otimizado para chips Hopper e Blackwell — como o H100, H200 e GB200 —, então usar um desses lhe dará o melhor desempenho. - Software e drivers:
As GPUs NVIDIA são geralmente a melhor opção, já que seu ecossistema CUDA é super maduro e bem suportado para tarefas de IA. A maioria das grandes bibliotecas de IA, como Transformers, Triton ou vLLM, são profundamente otimizadas para CUDA.
GPUs Recomendadas
Para o GPT-OSS 20B (precisa de pelo menos 16GB de VRAM):
- Cartões consumidor ou profissionais como:
- NVIDIA RTX 4090 (24GB)
- NVIDIA RTX 4080 (16GB)
- NVIDIA RTX 4060 Ti (16GB)
- NVIDIA RTX 6000 Ada (48GB, cartão profissional)
- AMD Radeon RX 7900 XTX (24GB)
Para o GPT-OSS 120B (precisa de pelo menos 80GB de VRAM):
- Cartões de data center como:
- NVIDIA H100 (80GB)
- NVIDIA H200 (141GB)
- NVIDIA A100 (80GB)
- NVIDIA A800 (80GB)
Você pode verificar os preços detalhados na Novita AI!
Como Otimizar o Uso de VRAM para o GPT OSS?
Use estruturas de inferência mais leves:
- Llama.cpp:
Este é um mecanismo de inferência leve e multiplataforma que funciona tanto em CPU quanto em GPU (CUDA, Metal, Vulkan). Ele suporta formatos quantizados como GGUF, que podem reduzir drasticamente o tamanho do modelo e diminuir o uso de memória. - vLLM:
Um mecanismo de inferência e implantação de alto throughput. Ele vem com recursos avançados como PagedAttention e Flash Attention 3, tornando-o super eficiente para servir modelos grandes.
Aproveite kernels avançados e quantização:
- Flash Attention:
Esta é uma implementação de atenção eficiente que pode reduzir muito o uso de memória e acelerar a computação, especialmente quando você está trabalhando com sequências longas. - Precisão mista e quantização (mxfp4):
O GPT-OSS suporta o formato de ponto flutuante de 4 bits mxfp4. Quando usado com kernels Triton em GPUs Hopper ou Blackwell, você obtém uso de VRAM super baixo e velocidades de inferência extremamente rápidas. - Kernel MegaBlocks MoE:
Este é um kernel otimizado para modelos Mistura de Especialistas (MoE), ajudando a aumentar a eficiência em GPUs que não são da arquitetura Hopper.
Instale e otimize por meio da biblioteca transformers:
A recomendação oficial é usar a biblioteca transformers, que agrupa muitas dessas otimizações. Para obter o melhor desempenho, você pode instalar o PyTorch e o Triton especificamente para CUDA 12.8:
# Upgrade the basic libraries
pip install --upgrade accelerate transformers kernels
# (Optional) For best performance with CUDA 12.8 and Triton 3.4, install this version of PyTorch
pip install torch==2.8.0 --index-url https://download.pytorch.org/whl/test/cu128
GPUs em Nuvem: Uma Escolha Inteligente para Pequenos Desenvolvedores
Como o custo e a complexidade de executar localmente podem ser bastante altos, a maioria dos desenvolvedores na verdade prefere usar serviços de GPU em nuvem.
Quando Escolher uma GPU Local
- Você tem um orçamento grande e pode pagar dezenas ou até centenas de milhares de dólares antecipadamente.
- Você tem necessidades de longo prazo e alta carga para treinamento ou inferência.
- Você tem requisitos rigorosos de privacidade de dados e não pode deixar que os dados saiam do seu próprio ambiente.
- Você quer controle total sobre hardware, software e rede.
Quando Escolher GPU em Nuvem
- Você é sensível a custos e quer evitar grandes compras de hardware e manutenção contínua — basta pagar conforme o uso.
- Suas necessidades são flexíveis, talvez você ainda esteja experimentando, ou sua carga de trabalho mude com o tempo.
- Você quer acesso instantâneo às GPUs mais recentes e poderosas, como H100 ou H200, sem esperar por processos de compra.
- Você não quer lidar com instalações de drivers complicadas, configuração de ambiente ou manutenção física.
Como Acessar o GPT OSS em GPU em Nuvem como a Novita AI?
Passo 1: Registre uma conta Se você é novo na Novita AI, comece criando uma conta em nosso site. Depois de registrado, vá para a aba “GPUs” para explorar os recursos disponíveis e começar sua jornada.

Experimente as GPUs de Alto Desempenho da Novita AI
Passo 2: Explorar Modelos e Servidores de GPU Comece selecionando um modelo que corresponda às necessidades do seu projeto, como PyTorch, TensorFlow ou CUDA. Escolha a versão que se adapta aos seus requisitos, como PyTorch 2.2.1 ou CUDA 11.8.0. Em seguida, selecione a configuração de servidor de GPU A100, que oferece desempenho potente para lidar com cargas de trabalho exigentes com ampla VRAM, RAM e capacidade de disco.

Passo 3: Personalize Sua Implantação Depois de selecionar um modelo e uma GPU, personalize as configurações de implantação ajustando parâmetros como a versão do sistema operacional (ex: CUDA 11.8). Você também pode modificar outras configurações para adaptar o ambiente aos requisitos específicos do seu projeto.
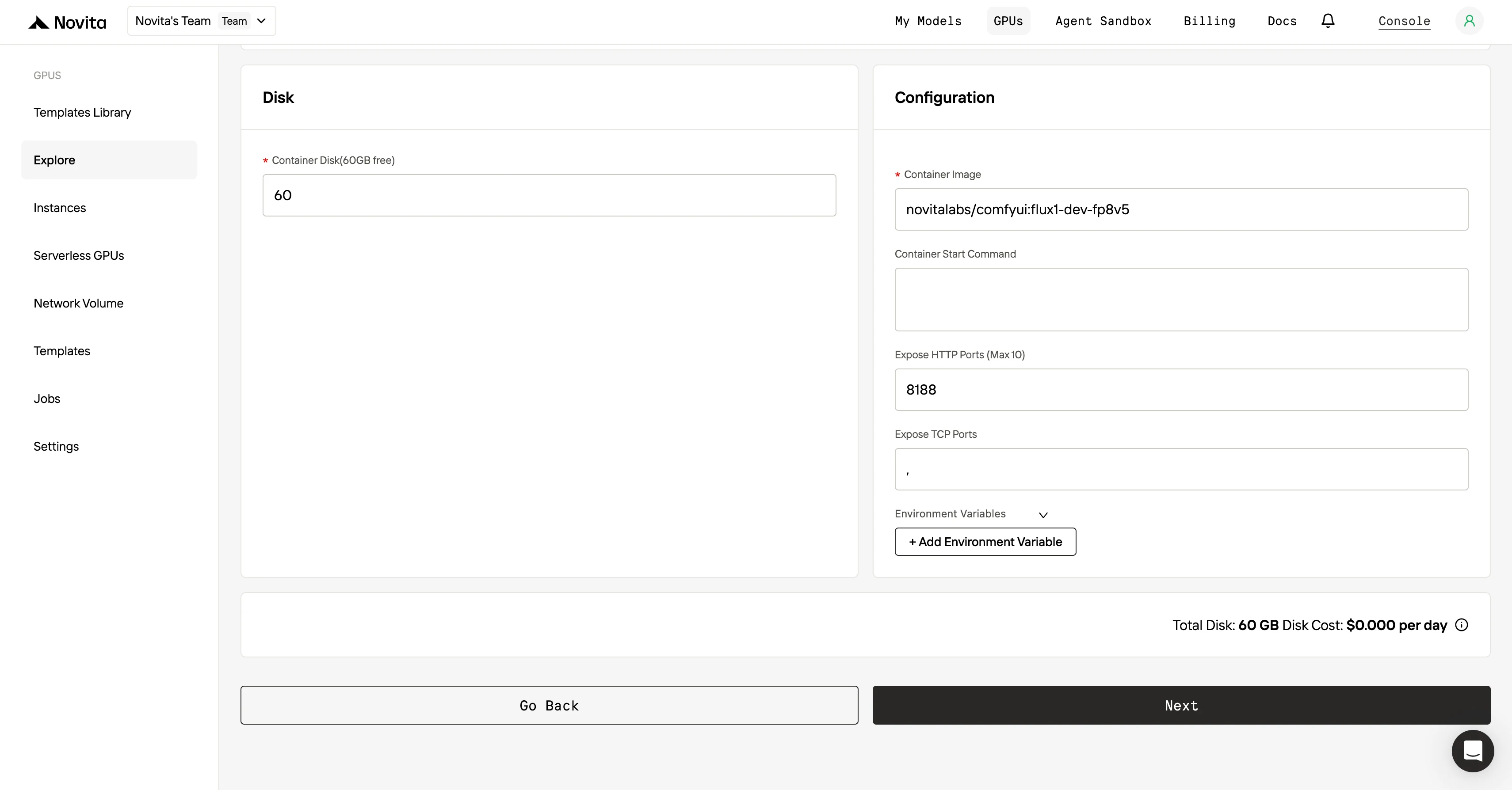
Passo 4: Inicie uma instância Depois de finalizar o modelo e as configurações de implantação, clique em “Iniciar Instância” para configurar sua instância de GPU. Isso iniciará a configuração do ambiente, permitindo que você comece a usar os recursos de GPU para suas tarefas de IA.
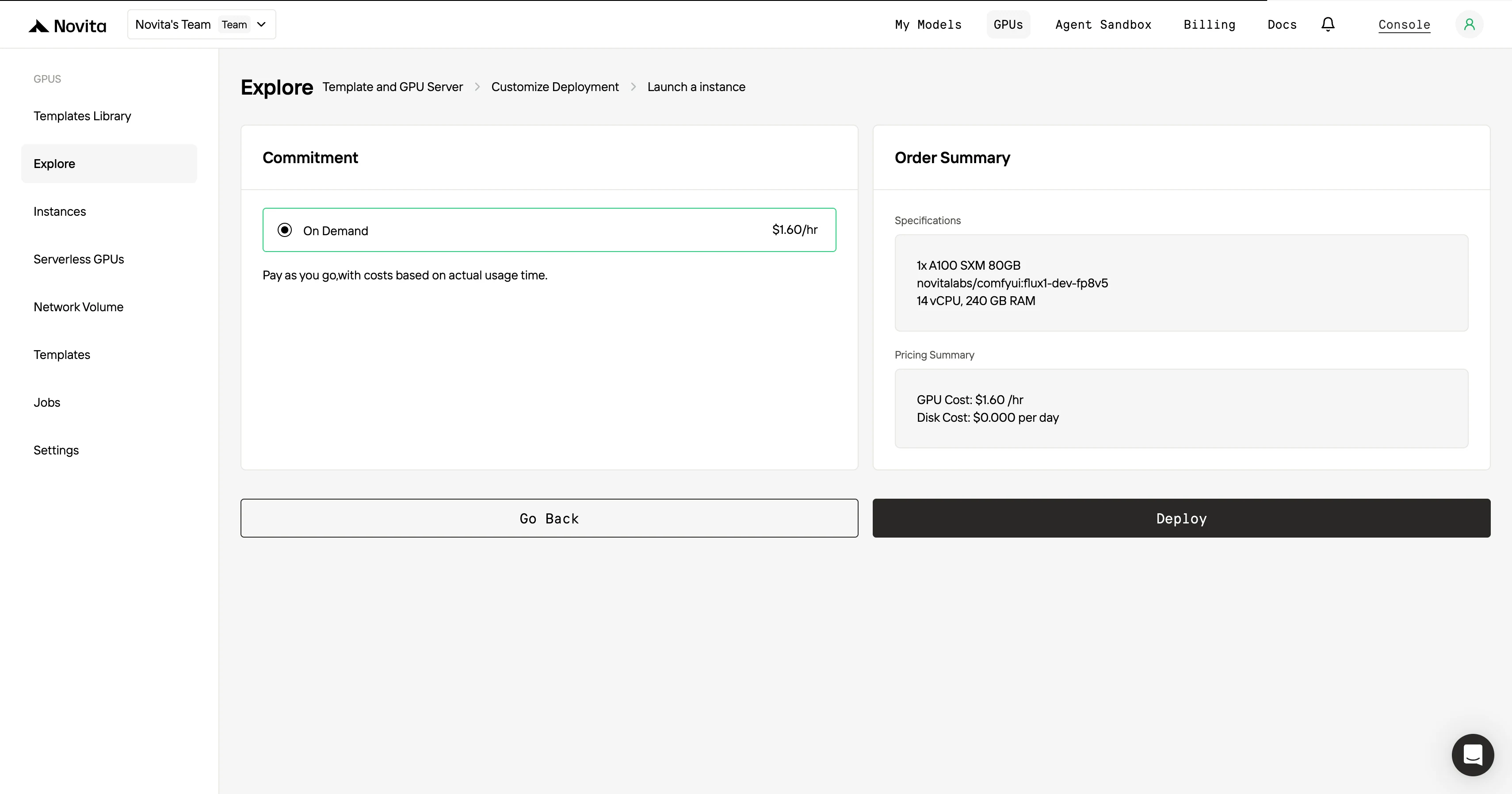
Para Máxima Eficiência e Conveniência, Use a API!
A Novita AI fornece APIs do GPT-OSS 120B
com 131K de contexto e custos de $0,1/entrada e $0,5/saída. A Novita AI também fornece o GPT-OSS 20B com 131 de contexto e custos de $0,05/entrada e $0,2/saída, entregando suporte forte para maximizar o potencial de agente de código do GPT OSS.Novita AI
Passo 1: Faça Login e Acesse a Biblioteca de Modelos Faça login na sua conta e clique no botão Biblioteca de Modelos.

Passo 2: Escolha Seu Modelo Navegue pelas opções disponíveis e selecione o modelo que atende às suas necessidades.

Passo 3: Inicie Seu Teste Gratuito Comece seu teste gratuito para explorar as capacidades do modelo selecionado.

Passo 4: Obtenha Sua Chave de API Para autenticar com a API, forneceremos uma nova chave de API para você. Acessando a página de “Configurações”, você pode copiar a chave de API conforme indicado na imagem.

Passo 5: Instale a API Instale a API usando o gerenciador de pacotes específico da sua linguagem de programação.
Após a instalação, importe as bibliotecas necessárias para o seu ambiente de desenvolvimento. Inicialize a API com sua chave de API para começar a interagir com o LLM da Novita AI. Este é um exemplo de uso da API de conclusões de chat para usuários de Python.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Para desbloquear o poder do GPT-OSS, entender os requisitos de VRAM é essencial:
- O GPT-OSS 20B precisa de pelo menos 16GB de VRAM, então ele é executado em GPUs consumidor de alto desempenho como a RTX 4060 Ti (16GB), tornando-o acessível para indivíduos e entusiastas.
- O GPT-OSS 120B requer 80GB de VRAM, precisando de GPUs profissionais de data center como a NVIDIA H100, o que está fora do alcance da maioria dos indivíduos e pequenas equipes.
A implantação local oferece o maior controle, mas vem com altos custos de hardware e complexidade técnica. Usar estruturas de inferência leves como Llama.cpp ou vLLM, além de técnicas como quantização mxfp4 e Flash Attention, pode ajudar a reduzir as necessidades de VRAM.
Para a maioria dos desenvolvedores, as GPUs em nuvem são a escolha mais inteligente — não há custo inicial alto, e você tem acesso instantâneo a hardware de primeira linha. Ao mesmo tempo, serviços de API gerenciados como a Novita AI tornam tudo ainda mais fácil: basta chamar a API, e você está pronto para usar o GPT-OSS sem lidar com hardware ou implantação nenhuma. Essa é a melhor forma de equilibrar desempenho, custo e conveniência, colocando IA poderosa ao alcance de todos.
Perguntas Frequentes
Quanta VRAM eu preciso para executar o GPT-OSS?
GPT-OSS 20B: pelo menos 16GB de VRAM.
GPT-OSS 120B: pelo menos 80GB de VRAM.
Qual é a forma mais acessível de executar o GPT-OSS 20B localmente? Use uma GPU consumidor com 16GB de VRAM, como a NVIDIA RTX 4060 Ti (16GB), e uma estrutura leve como Llama.cpp com um modelo quantizado GGUF.
Como posso reduzir o uso de VRAM do GPT-OSS?
Use estruturas leves (Llama.cpp, vLLM) com otimizações de memória integradas.
Quantize o modelo (use mxfp4 ou GGUF) para menor precisão e menor ocupação de memória.
Ative kernels eficientes como Flash Attention, especialmente para textos longos.
A Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma forma fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.



