

OpenAIs erste Open-Source-Großmodellreihe, GPT-OSS, ist da. Mit ihrer effizienten Mixture-of-Experts (MoE)-Architektur, der Unterstützung von bis zu 128k Kontextlänge und starken Leistungen in den Bereichen Reasoning, Wissenschaft und Programmierung eröffnet sie neue Möglichkeiten für Entwickler. Jeder kann dieses fortschrittliche Sprachmodell nun auf seiner eigenen Hardware herunterladen und ausführen. Aber es gibt eine zentrale Frage: Wie viel VRAM benötigen Sie tatsächlich, um GPT-OSS auszuführen?
Dieser Artikel erklärt es Ihnen im Detail:
- GPU-Empfehlungen: Welche Karten sind am besten, von Consumer- bis Rechenzentrumsniveau?
- VRAM-Optimierung: Wie können Sie Quantisierung und neue Frameworks nutzen, um den Ressourcenverbrauch zu senken?
- Bereitstellungsoptionen: Lokale vs. Cloud-GPU – was ist kosteneffizienter?
- Einfachster Zugang: Wie nutzen Sie API-Dienste und vermeiden Hardware-Probleme?
Egal, ob Sie ein unabhängiger Entwickler oder ein kleines Team sind, dieser Leitfaden hilft Ihnen, die klügste Entscheidung zu treffen.
Wie viel VRAM benötigt GPT OSS?
GPT OSS ist eine hocheffiziente und skalierbare Large-Language-Model-Architektur. Sie verwendet die sogenannte Mixture-of-Experts (MoE) zusammen mit einem autoregressiven Transformer-Design. Dank der spärlichen Aktivierung kann sie sehr große Modelle deutlich schneller und effizienter ausführen. Sie unterstützt zudem extrem lange Kontexte von bis zu 128.000 Tokens, sodass sie lange Dokumente oder komplexe Gespräche problemlos verarbeiten kann. Die Architektur kombiniert RoPE-Positionscodierung und wechselt zwischen globalen und lokalen Aufmerksamkeitsfenstern, was ihr hilft, sowohl detaillierte als auch breite Inhalte zu verwalten. GPT OSS ist besonders stark in den Bereichen Reasoning, Wissenschaft und Programmierung.
Sie ist zudem einfach zu handhaben, da sie direkt mit der OpenAI-API und gängigen Tokenizern kompatibel ist, sodass Entwickler sie ohne großen Aufwand in ihre bestehenden Workflows integrieren können. Für das Training verwendet GPT OSS massive, hochwertige Datensätze und wird auf vielen GPUs trainiert, zusätzlich wird Reinforcement Learning eingesetzt, um sicherzustellen, dass sie sicher, zuverlässig und gut darin ist, Anweisungen zu befolgen.
Ein weiterer Vorteil ist, dass sie verschiedene Reasoning-Modi unterstützt, sodass Sie je nach Bedarf zwischen Geschwindigkeit, Genauigkeit und Kosten abwägen können. Darüber hinaus ist GPT OSS für die Nutzung von Tools ausgelegt und eignet sich hervorragend zur Verwaltung von Dialogformaten und Rollen, sodass sie äußerst flexibel und sicher selbst für die anspruchsvollsten oder komplexesten Anwendungen ist.
| Modell | Schichten | Gesamtparameter | Aktive Parameter pro Token | Gesamtzahl Experten | Aktive Experten pro Token | Kontextlänge | VRAM-Anforderung pro einzelne GPU |
| gpt-oss-120b | 36 | 117B | 5,1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3,6B | 32 | 4 | 128k | 16GB |
Tipps zur Auswahl einer GPU für GPT OSS
- Die VRAM-Größe ist am wichtigsten:
- Für GPT-OSS 20B benötigen Sie eine GPU mit mindestens 16 GB Speicher.
- Für GPT-OSS 120B benötigen Sie eine GPU mit mindestens 80 GB VRAM.
- Die GPU-Architektur ist wichtig:
Das Modell funktioniert am besten mit neueren GPU-Architekturen. Die offizielle Dokumentation gibt explizit an, dass es für Hopper- und Blackwell-Chips optimiert ist – wie z. B. H100, H200 und GB200 – sodass die Nutzung eines solchen Chips die beste Leistung bietet. - Software und Treiber:
NVIDIA-GPUs sind in der Regel die beste Wahl, da ihr CUDA-Ökosystem für KI-Aufgaben sehr ausgereift und gut unterstützt ist. Die meisten großen KI-Bibliotheken wie Transformers, Triton oder vLLM sind tiefgehend für CUDA optimiert.
Empfohlene GPUs
Für GPT-OSS 20B (benötigt mindestens 16 GB VRAM):
- Consumer- oder Profi-Karten wie:
- NVIDIA RTX 4090 (24 GB)
- NVIDIA RTX 4080 (16 GB)
- NVIDIA RTX 4060 Ti (16 GB)
- NVIDIA RTX 6000 Ada (48 GB, Profi-Karte)
- AMD Radeon RX 7900 XTX (24 GB)
Für GPT-OSS 120B (benötigt mindestens 80 GB VRAM):
- Rechenzentrums-Karten wie:
- NVIDIA H100 (80 GB)
- NVIDIA H200 (141 GB)
- NVIDIA A100 (80 GB)
- NVIDIA A800 (80 GB)
Ausführliche Preisinformationen finden Sie auf Novita AI!
Wie optimieren Sie den VRAM-Verbrauch für GPT OSS?
Nutzen Sie leichtgewichtige Inferenz-Frameworks:
- Llama.cpp:
Dies ist eine plattformübergreifende, leichtgewichtige Inferenz-Engine, die sowohl auf CPU als auch GPU (CUDA, Metal, Vulkan) läuft. Sie unterstützt quantisierte Formate wie GGUF, die die Modellgröße drastisch reduzieren und den Speicherverbrauch senken können. - vLLM:
Eine Inferenz- und Bereitstellungs-Engine mit hohem Durchsatz. Sie verfügt über fortschrittliche Funktionen wie PagedAttention und Flash Attention 3, die sie äußerst effizient für die Bereitstellung großer Modelle machen.
Nutzen Sie fortschrittliche Kernel und Quantisierung:
- Flash Attention:
Dies ist eine effiziente Aufmerksamkeitsimplementierung, die den Speicherverbrauch deutlich senken und die Berechnung beschleunigen kann, insbesondere bei der Arbeit mit langen Sequenzen. - Gemischte Präzision und Quantisierung (mxfp4):
GPT-OSS unterstützt das 4-Bit-Gleitkommaformat mxfp4. Bei Verwendung mit Triton-Kernen auf Hopper- oder Blackwell-GPUs erhalten Sie einen extrem niedrigen VRAM-Verbrauch und blitzschnelle Inferenzgeschwindigkeiten. - MegaBlocks MoE-Kernel:
Dies ist ein optimierter Kernel für Mixture-of-Experts (MoE)-Modelle, der die Effizienz auf GPUs, die keine Hopper-Architektur haben, verbessert.
Installation und Optimierung über die Transformers-Bibliothek:
Die offizielle Empfehlung ist die Nutzung der transformers-Bibliothek, die viele dieser Optimierungen bündelt. Für die beste Leistung können Sie PyTorch und Triton speziell für CUDA 12.8 installieren:
# Upgrade the basic libraries
pip install --upgrade accelerate transformers kernels
# (Optional) For best performance with CUDA 12.8 and Triton 3.4, install this version of PyTorch
pip install torch==2.8.0 --index-url https://download.pytorch.org/whl/test/cu128
Cloud-GPUs: Eine clevere Wahl für kleine Entwickler
Da die Kosten und der Aufwand für den lokalen Betrieb ziemlich hoch sein können, bevorzugen die meisten Entwickler tatsächlich Cloud-GPU-Dienste.
Wann Sie eine lokale GPU wählen sollten
- Sie haben ein großes Budget und können Zehntausende oder sogar Hunderttausende von Dollar im Voraus bezahlen.
- Sie haben langfristige, hochbelastete Anforderungen an Training oder Inferenz.
- Sie haben strenge Datenschutzanforderungen und können keine Daten aus Ihrer eigenen Umgebung herauslassen.
- Sie möchten die volle Kontrolle über Hardware, Software und Netzwerk haben.
Wann Sie eine Cloud-GPU wählen sollten
- Sie sind kostensensibel und möchten große Hardwareanschaffungen und laufende Wartung vermeiden – zahlen Sie einfach nach Nutzung.
- Ihre Anforderungen sind flexibel, vielleicht experimentieren Sie noch oder Ihre Arbeitslast ändert sich im Laufe der Zeit.
- Sie möchten sofortigen Zugriff auf die neuesten, leistungsstärksten GPUs wie H100 oder H200, ohne auf die Beschaffung zu warten.
- Sie möchten sich nicht mit kniffligen Treiberinstallationen, Umgebungseinrichtung oder physischer Wartung herumschlagen.
Wie greifen Sie auf GPT OSS auf Cloud-GPUs wie Novita AI zu?
Schritt 1:Registrieren Sie ein Konto Wenn Sie neu bei Novita AI sind, beginnen Sie mit der Erstellung eines Kontos auf unserer Website. Sobald Sie registriert sind, wechseln Sie zum Tab “GPUs”, um verfügbare Ressourcen zu erkunden und Ihre Reise zu starten.

Testen Sie die Hochleistungs-GPUs von Novita AI
Schritt 2:Vorlagen und GPU-Server erkunden** Wählen Sie zunächst eine Vorlage, die zu den Anforderungen Ihres Projekts passt, wie z. B. PyTorch, TensorFlow oder CUDA. Wählen Sie die Version, die Ihren Anforderungen entspricht, wie z. B. PyTorch 2.2.1 oder CUDA 11.8.0. Wählen Sie anschließend die A100-GPU-Serverkonfiguration, die eine leistungsstarke Performance für anspruchsvolle Arbeitslasten mit reichlich VRAM, RAM und Speicherkapazität bietet.

Schritt 3:Passen Sie Ihre Bereitstellung an Nach der Auswahl von Vorlage und GPU passen Sie Ihre Bereitstellungseinstellungen an, indem Sie Parameter wie die Betriebssystemversion (z. B. CUDA 11.8) anpassen. Sie können auch andere Konfigurationen anpassen, um die Umgebung auf die spezifischen Anforderungen Ihres Projekts abzustimmen.
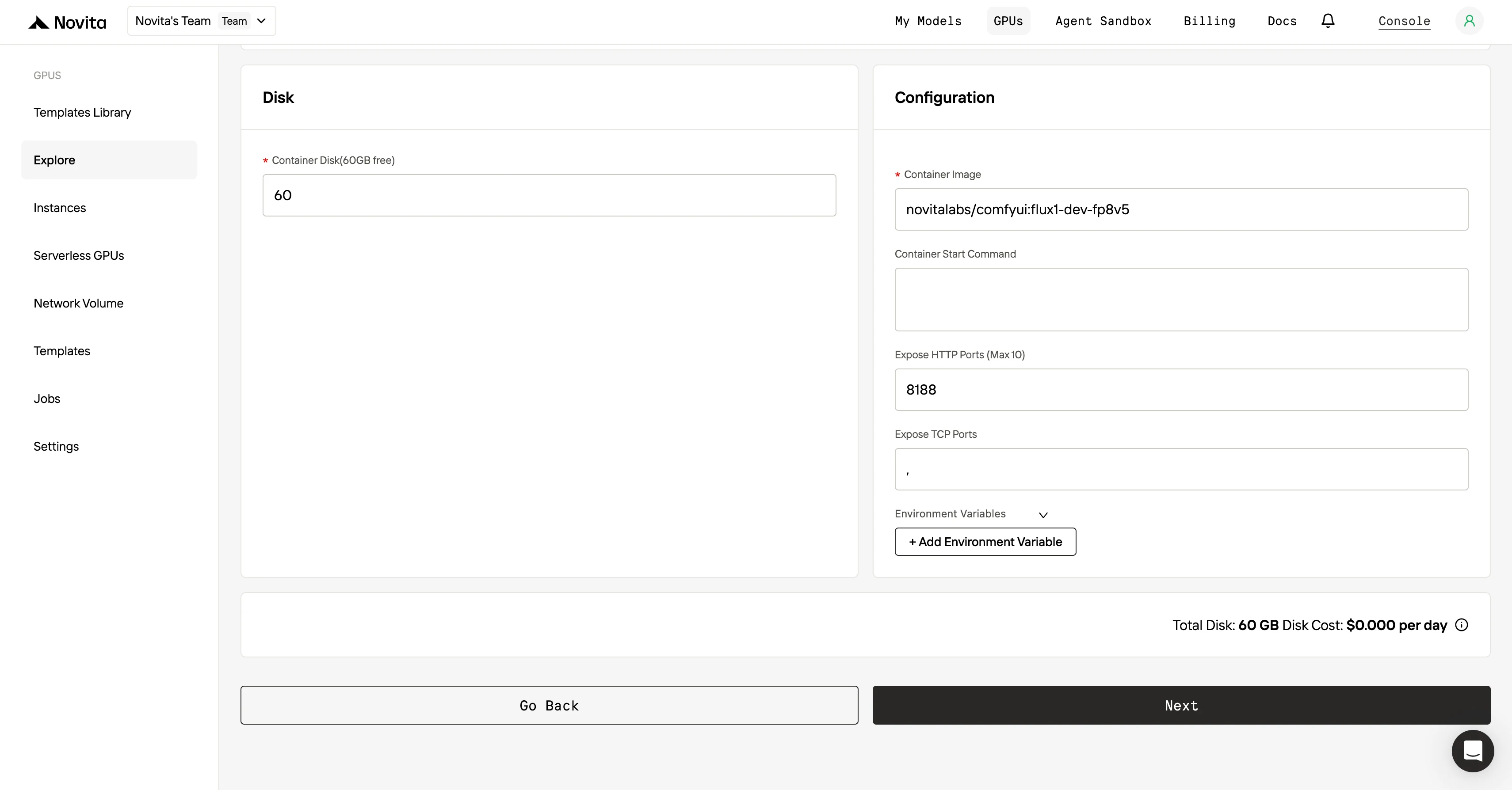
Schritt 4:Starten eine Instanz** Sobald Sie Vorlage und Bereitstellungseinstellungen festgelegt haben, klicken Sie auf “Instanz starten”, um Ihre GPU-Instanz einzurichten. Dadurch wird die Umgebungseinrichtung gestartet, sodass Sie die GPU-Ressourcen für Ihre KI-Aufgaben nutzen können.
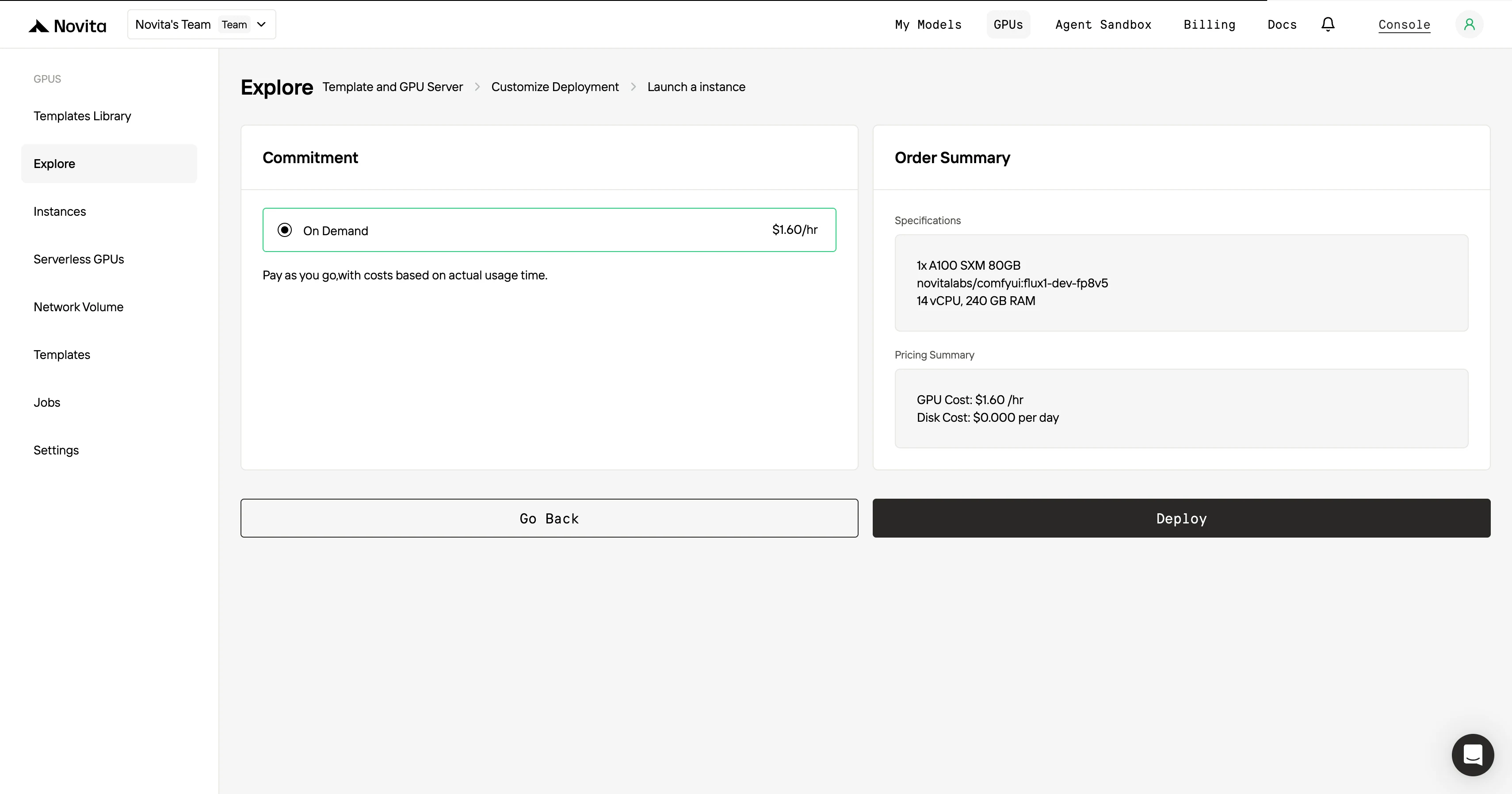
Für maximale Effizienz und Komfort nutzen Sie die API!
Novita AI bietet GPT-OSS 120B
APIs mit 131K Kontext und Kosten von $0,1/Eingabe und $0,5/Ausgabe. Novita AI bietet zudem GPT-OSS 20B mit 131 Kontext und Kosten von $0,05/Eingabe und $0,2/Ausgabe und bietet damit starke Unterstützung bei der Maximierung des Code-Agent-Potenzials von GPT OSS.Novita AI
Schritt 1: Melden Sie sich an und greifen Sie auf die Modellbibliothek zu Melden Sie sich bei Ihrem Konto an und klicken Sie auf die Schaltfläche Modellbibliothek.

Schritt 2: Wählen Sie Ihr Modell Durchstöbern Sie die verfügbaren Optionen und wählen Sie das Modell, das Ihren Anforderungen entspricht.

Schritt 3: Starten Sie Ihre kostenlose Testversion Starten Sie Ihre kostenlose Testversion, um die Funktionen des ausgewählten Modells zu erkunden.

Schritt 4: Holen Sie sich Ihren API-Schlüssel Zur Authentifizierung bei der API stellen wir Ihnen einen neuen API-Schlüssel zur Verfügung. Auf der Seite „Einstellungen“ können Sie den API-Schlüssel wie in der Abbildung gezeigt kopieren.

Schritt 5: Installieren Sie die API Installieren Sie die API über den für Ihre Programmiersprache spezifischen Paketmanager.
Nach der Installation importieren Sie die erforderlichen Bibliotheken in Ihre Entwicklungsumgebung. Initialisieren Sie die API mit Ihrem API-Schlüssel, um mit dem Novita AI LLM zu interagieren. Dies ist ein Beispiel für die Nutzung der Chat-Completion-API für Python-Nutzer.
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
Um die Leistung von GPT-OSS freizuschalten, ist das Verständnis der VRAM-Anforderungen unerlässlich:
- GPT-OSS 20B benötigt mindestens 16 GB VRAM, sodass es auf High-End-Consumer-GPUs wie der RTX 4060 Ti (16 GB) läuft und für Einzelpersonen und Enthusiasten zugänglich ist.
- GPT-OSS 120B benötigt 80 GB VRAM, sodass professionelle Rechenzentrums-GPUs wie die NVIDIA H100 erforderlich sind, was für die meisten Einzelpersonen und kleinen Teams unerschwinglich ist.
Die lokale Bereitstellung bietet die größte Kontrolle, ist aber mit hohen Hardwarekosten und technischer Komplexität verbunden. Die Nutzung leichtgewichtiger Inferenz-Frameworks wie Llama.cpp oder vLLM sowie Techniken wie mxfp4-Quantisierung und Flash Attention kann helfen, den VRAM-Bedarf zu senken.
Für die meisten Entwickler sind Cloud-GPUs die klügere Wahl – es gibt keine hohen Vorabkosten und Sie erhalten sofortigen Zugriff auf erstklassige Hardware. Gleichzeitig machen verwaltete API-Dienste wie Novita AI es noch einfacher: Rufen Sie einfach die API auf, und Sie können GPT-OSS nutzen, ohne sich überhaupt mit Hardware oder Bereitstellung auseinandersetzen zu müssen. Dies ist die beste Möglichkeit, Leistung, Kosten und Komfort in Einklang zu bringen und macht leistungsstarke KI für jeden zugänglich.
Häufig gestellte Fragen
Wie viel VRAM benötige ich, um GPT-OSS auszuführen?
GPT-OSS 20B: Mindestens 16 GB VRAM.
GPT-OSS 120B: Mindestens 80 GB VRAM.
Was ist die günstigste Möglichkeit, GPT-OSS 20B lokal auszuführen? Nutzen Sie eine Consumer-GPU mit 16 GB VRAM, wie die NVIDIA RTX 4060 Ti (16 GB), und ein leichtgewichtiges Framework wie Llama.cpp mit einem quantisierten GGUF-Modell.
Wie kann ich den VRAM-Verbrauch von GPT-OSS senken?
Nutzen Sie leichtgewichtige Frameworks (Llama.cpp, vLLM) mit integrierten Speicheroptimierungen.
Quantisieren Sie das Modell (verwenden Sie mxfp4 oder GGUF) für geringere Präzision und einen kleineren Speicherbedarf.
Aktivieren Sie effiziente Kernel wie Flash Attention, insbesondere für lange Texte.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Erstellung und Skalierung bereitstellt.



