

OpenAI 首个开源大模型系列 GPT-OSS 正式发布。该模型采用高效的混合专家(MoE)架构,支持最长 128k 上下文长度,在推理、科学计算和编程领域表现突出,为开发者带来了新的机遇。现在任何人都可以在自己的硬件上下载并运行这款先进的大语言模型,但关键问题是:你实际需要多少显存才能运行 GPT-OSS?
本文将为你详细解答以下问题:
- GPU 推荐: 从消费级到数据中心级,哪些显卡最合适?
- 显存优化: 如何通过量化和新框架降低资源占用?
- 部署方案: 本地部署和云 GPU 哪个性价比更高?
- 最便捷的获取方式: 如何通过 API 服务使用,避开硬件相关的麻烦?
无论你是独立开发者还是小团队,这篇指南都能帮你做出最明智的选择。
运行 GPT OSS 需要多少显存?
GPT OSS 是一款高效且可扩展的大语言模型架构,采用混合专家(MoE)架构与自回归 Transformer 设计。得益于稀疏激活机制,它能够更快速、更高效地运行超大规模模型。同时支持超长上下文——最长可达 128,000 个 token,可轻松处理长文档或复杂对话。该架构结合了 RoPE 位置编码,并在全局和局部注意力窗口间切换,能够同时兼顾细节内容和宏观内容的处理。GPT OSS 在推理、科学计算和编程领域表现非常出色。
它的易用性也很高,直接兼容 OpenAI API 和主流分词器,开发者可以几乎无门槛地将它接入现有工作流。训练方面,GPT OSS 使用了大规模高质量数据集,在大量 GPU 上完成训练,同时采用强化学习技术保障模型的安全性、可靠性和指令遵循能力。
此外,它支持多种推理模式,你可以根据需求在速度、准确性和成本之间灵活平衡。不仅如此,GPT OSS 原生支持工具调用,在对话格式和角色管理方面表现优异,灵活性和安全性都很高,能够满足最严苛、最复杂的应用场景需求。
| 模型 | 层数 | 总参数量 | 单 token 激活参数量 | 专家总数 | 单 token 激活专家数 | 上下文长度 | 单 GPU 显存需求 |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16GB |
选择 GPT OSS 用 GPU 的注意事项
- 显存大小是最核心的指标:
- 运行 GPT-OSS 20B,你需要至少 16GB 显存的 GPU。
- 运行 GPT-OSS 120B,你需要至少 80GB 显存的 GPU。
- GPU 架构很重要: 该模型在新款 GPU 架构上表现最佳。官方文档明确指出,模型针对 Hopper 和 Blackwell 架构芯片做了优化,比如 H100、H200 和 GB200,使用这些芯片能获得最佳性能。
- 软件和驱动支持: NVIDIA GPU 通常是首选,因为其 CUDA 生态非常成熟,对 AI 任务的支持完善。绝大多数主流 AI 库,比如 Transformers、Triton、vLLM 都针对 CUDA 做了深度优化。
推荐 GPU 列表
针对 GPT-OSS 20B(至少需要 16GB 显存):
- 消费级或专业级显卡可选:
- NVIDIA RTX 4090(24GB)
- NVIDIA RTX 4080(16GB)
- NVIDIA RTX 4060 Ti(16GB)
- NVIDIA RTX 6000 Ada(48GB,专业卡)
- AMD Radeon RX 7900 XTX(24GB)
针对 GPT-OSS 120B(至少需要 80GB 显存):
- 数据中心级显卡可选:
- NVIDIA H100(80GB)
- NVIDIA H200(141GB)
- NVIDIA A100(80GB)
- NVIDIA A800(80GB)
你可以在 Novita AI 查看详细价格! 查看 GPU 价格!
如何优化 GPT OSS 的显存占用?
使用更轻量的推理框架:
- Llama.cpp: 这是一款跨平台、轻量级的推理引擎,支持 CPU 和 GPU(CUDA、Metal、Vulkan)运行。它支持 GGUF 等量化格式,可以大幅缩小模型体积、降低内存占用。
- vLLM: 一款高吞吐量推理与部署引擎,内置 PagedAttention、Flash Attention 3 等高级特性,运行大模型时效率极高。
利用高级内核和量化技术:
- Flash Attention: 这是一种高效的注意力机制实现,能够大幅降低内存占用、加速计算,在处理长序列时优势尤为明显。
- 混合精度与量化(mxfp4): GPT-OSS 支持 mxfp4 4 位浮点格式,在 Hopper 或 Blackwell 架构 GPU 上搭配 Triton 内核使用时,能够实现极低的显存占用和极快的推理速度。
- MegaBlocks MoE 内核: 这是针对混合专家(MoE)模型优化的内核,能够提升非 Hopper 架构 GPU 上的运行效率。
通过 transformers 库安装和优化:
官方推荐使用 transformers 库,该库内置了多项上述优化。要获得最佳性能,你可以安装适配 CUDA 12.8 的 PyTorch 和 Triton:
# 升级基础依赖库
pip install --upgrade accelerate transformers kernels
# (可选)为 CUDA 12.8 和 Triton 3.4 获得最佳性能,安装该版本 PyTorch
pip install torch==2.8.0 --index-url https://download.pytorch.org/whl/test/cu128
云 GPU:小型开发者的明智之选
由于本地运行的成本和复杂度较高,大多数开发者更倾向于使用云 GPU 服务。
什么时候选择本地 GPU?
- 预算充足,能够承担数万甚至数十万美元的前期硬件投入。
- 有长期、高负载的训练或推理需求。
- 有严格的数据隐私要求,不允许数据离开自有环境。
- 希望对硬件、软件和网络有完全的控制权。
什么时候选择云 GPU?
- 对成本敏感,希望避免大额硬件采购和持续的运维成本,按需付费即可。
- 需求灵活,可能还在实验阶段,或工作负载随时间波动较大。
- 希望即时获取最新的高性能 GPU(比如 H100、H200),无需等待采购流程。
- 不想处理复杂的驱动安装、环境配置或物理硬件维护工作。
如何在 Novita AI 这类云 GPU 平台上使用 GPT OSS?
步骤1:注册账号
如果你是 Novita AI 的新用户,请先在官网创建账号。注册完成后,进入「GPU」标签页浏览可用资源,开启你的使用之旅。
 试用 Novita AI 高性能 GPU
试用 Novita AI 高性能 GPU
步骤2:选择模板和 GPU 服务器
首先选择符合你项目需求的模板,比如 PyTorch、TensorFlow 或 CUDA,选择适配你需求的版本,比如 PyTorch 2.2.1 或 CUDA 11.8.0。然后选择 A100 GPU 服务器配置,该配置性能强劲,拥有充足的显存、内存和磁盘容量,能够应对高负载工作流。

步骤3:定制你的部署配置
选择好模板和 GPU 后,你可以自定义部署配置,调整操作系统版本(比如 CUDA 11.8)等参数,还可以修改其他配置来适配项目的特定需求。
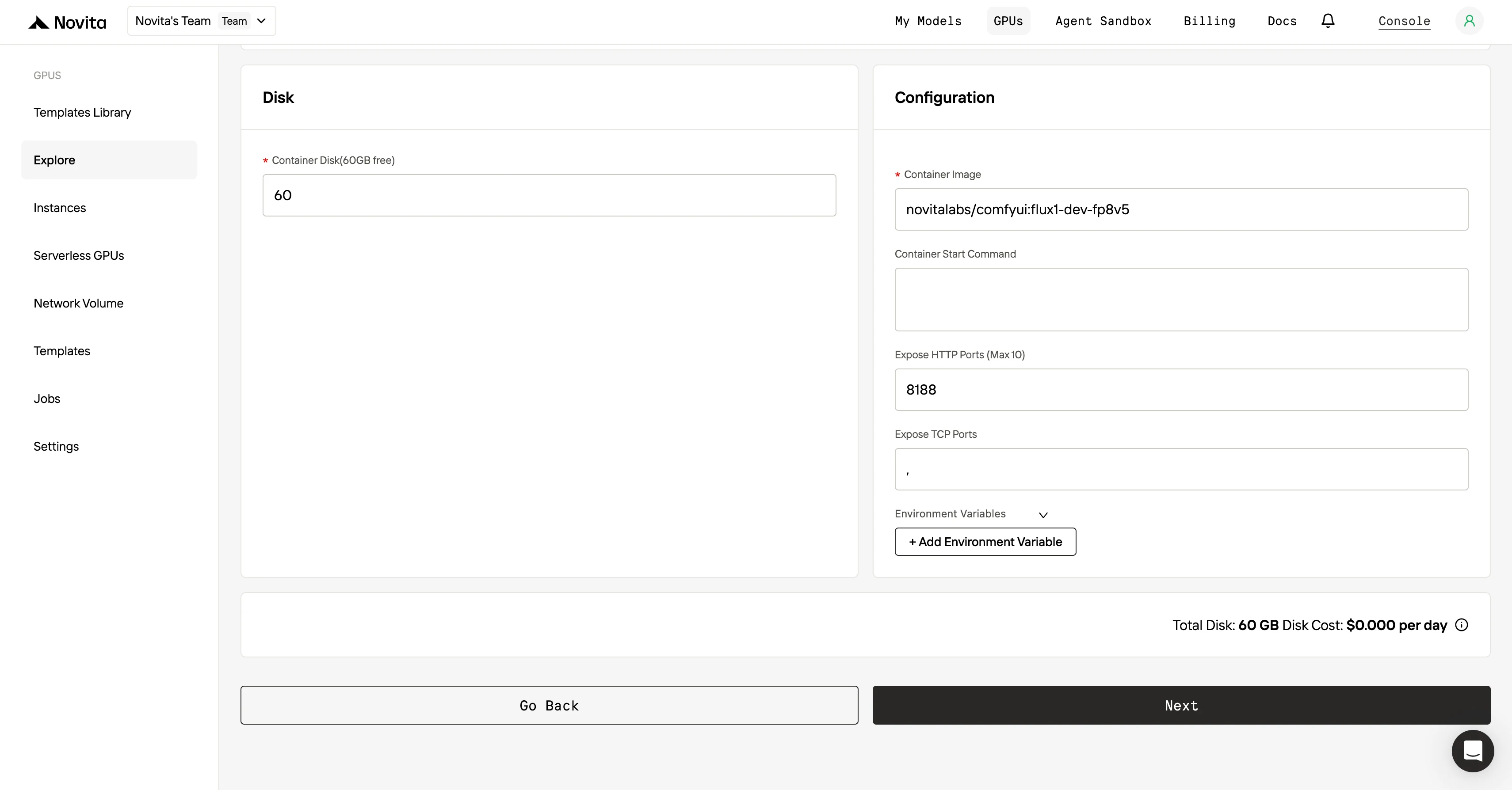
步骤4:启动实例
完成模板和部署配置的选择后,点击「启动实例」即可创建 GPU 实例。系统会自动完成环境配置,你就可以开始使用 GPU 资源开展 AI 任务了。
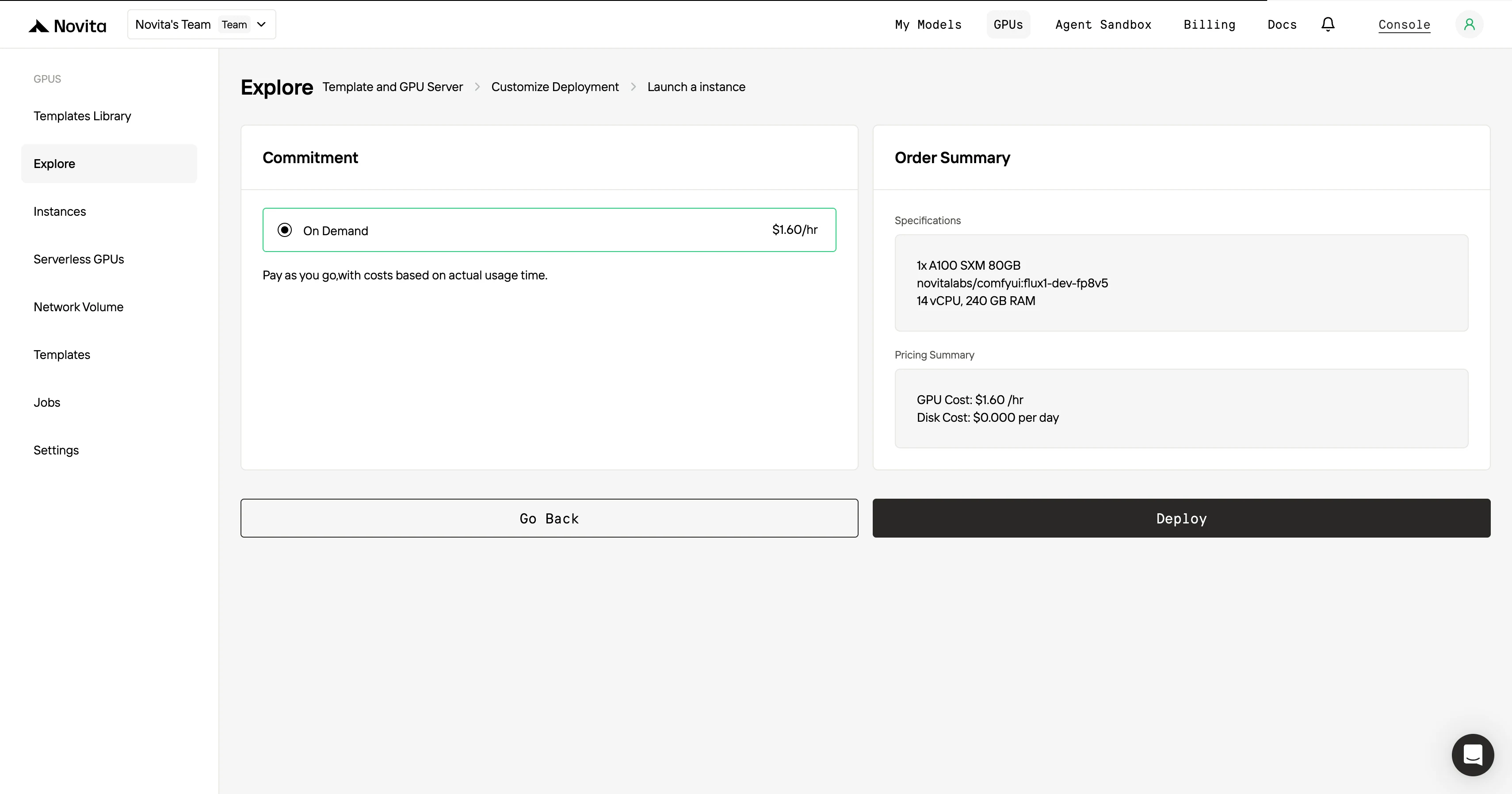
想要最高效率和便捷性?用 API 就够了!
Novita AI 提供 GPT-OSS 120B API,支持 131K 上下文,输入价格为 $0.1/次,输出价格为 $0.5/次。Novita AI 还提供 GPT-OSS 20B,支持 131K 上下文,输入价格为 $0.05/次,输出价格为 $0.2/次,能够充分释放 GPT OSS 在代码代理场景的潜力。
Novita AI
步骤1:登录并进入模型库
登录你的账号,点击「模型库」按钮。
 立即试用 GPT OSS!
立即试用 GPT OSS!
步骤2:选择模型
浏览可用选项,选择符合你需求的模型。

步骤3:开始免费试用
启动免费试用,探索所选模型的能力。

步骤4:获取 API 密钥
要调用 API 进行身份验证,我们会为你提供新的 API 密钥。进入「设置」页面,你就可以按照下图提示复制 API 密钥。

步骤5:安装 API 库 使用你所用编程语言的包管理器安装 API 库。 安装完成后,将必要的库导入到你的开发环境中,用 API 密钥初始化 API,即可开始调用 Novita AI 的大语言模型。以下是 Python 用户调用聊天补全 API 的示例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
要释放 GPT-OSS 的全部能力,首先需要了解其显存需求:
- GPT-OSS 20B 至少需要 16GB 显存,可以在 RTX 4060 Ti(16GB)这类高端消费级 GPU 上运行,个人和爱好者也能轻松入手。
- GPT-OSS 120B 需要 80GB 显存,必须使用 NVIDIA H100 这类专业数据中心 GPU,对大多数个人和小团队来说门槛较高。
本地部署能提供最高的控制权,但硬件成本高、技术复杂度也高。使用 Llama.cpp 或 vLLM 这类轻量推理框架,搭配 mxfp4 量化、Flash Attention 等技术,可以降低显存需求。
对大多数开发者来说,云 GPU 是更明智的选择——无需大额前期投入,还能即时获取顶级硬件。同时,像 Novita AI 这类托管式 API 服务更加便捷:只需调用 API 就能使用 GPT-OSS,完全不需要处理硬件和部署问题。这是在性能、成本和便捷性之间取得最佳平衡的方式,让强大的 AI 能力触手可及。
常见问题
运行 GPT-OSS 需要多少显存? GPT-OSS 20B:至少需要 16GB 显存。 GPT-OSS 120B:至少需要 80GB 显存。
本地运行 GPT-OSS 20B 最经济的方式是什么? 使用 16GB 显存的消费级 GPU(比如 NVIDIA RTX 4060 Ti(16GB)),搭配 Llama.cpp 这类轻量框架和 GGUF 量化模型即可。
如何降低 GPT-OSS 的显存占用?
- 使用内置内存优化特性的轻量框架(Llama.cpp、vLLM)。
- 对模型进行量化(使用 mxfp4 或 GGUF 格式),降低精度、减小内存占用。
- 开启 Flash Attention 等高效内核,处理长文本时优势尤为明显。
Novita AI 是一个 AI 云平台,为开发者提供简单的 API 来部署 AI 模型,同时提供高性价比、可靠的 GPU 云服务,用于 AI 应用的构建和扩展。



