

OpenAI 首個開源大型模型系列 GPT-OSS 正式登場。憑藉高效的混合專家(Mixture-of-Experts, MoE)架構、最高支援 128k 上下文長度,以及在推理、科學和程式碼領域的強勁表現,它為開發者帶來了全新的機會。現在任何人都可以在自己的硬體上下載並運行這個先進的語言模型。但有一個關鍵問題:你到底需要多少 VRAM 才能運行 GPT-OSS?
這篇文章將為你詳細解析:
- GPU 建議: 從消費級到資料中心級,哪些顯卡最適合?
- VRAM 優化: 如何透過量化與新框架降低資源消耗?
- 部署方案選擇: 本地部署與雲端 GPU 哪個性價比更高?
- 最便捷的接入方式: 如何使用 API 服務,免除硬體煩惱?
無論你是獨立開發者還是小型團隊,這份指南都能幫助你做出最明智的選擇。
GPT OSS 需要多少 VRAM?
GPT OSS 是一款效能極高、可擴展性強的大型語言模型架構。它採用混合專家(Mixture-of-Experts, MoE)架構搭配自回歸 Transformer 設計,得益於稀疏激活機制,運行超大型模型時速度更快、效率更高。同時它支援極長的上下文——最高可達 128,000 個 token,能輕鬆處理長篇文件或複雜對話。該架構結合了 RoPE 位置編碼,並在全局與局部注意力窗口間切換,能同時勝任細節處理與大範圍內容理解任務。在推理、科學和程式碼領域,GPT OSS 的表現非常突出。
此外它非常易於使用,直接相容 OpenAI API 和主流分詞器,開發者可以幾乎無障礙地將它接入現有工作流程。訓練階段,GPT OSS 使用了海量高品質數據集,在大量 GPU 上進行訓練,同時透過強化學習確保模型安全、可靠、善於遵循指令。
另一個特點是它支援多種推理模式,你可以根據需求在速度、準確度和成本之間取得平衡。除此之外,GPT OSS 原生支援工具調用,在對話格式與角色管理方面表現優異,靈活性與安全性極高,甚至能勝任最苛刻、最複雜的應用場景。
| 模型 | 層數 | 總參數量 | 每 Token 活躍參數量 | 專家總數 | 每 Token 活躍專家數 | 上下文長度 | 單張 GPU VRAM 需求 |
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k | 80GB |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k | 16GB |
為 GPT OSS 選擇 GPU 的注意事項
- VRAM 大小是最重要的考量因素:
- 運行 GPT-OSS 20B 需要至少 16GB 記憶體的 GPU。
- 運行 GPT-OSS 120B 需要至少 80GB VRAM 的 GPU。
- GPU 架構非常重要:
模型在較新的 GPU 架構上表現最佳。官方文件明確指出它針對 Hopper 和 Blackwell 晶片進行了優化——例如 H100、H200 和 GB200,使用這些晶片能獲得最佳效能。 - 軟體與驅動程式:
NVIDIA GPU 通常是首選,因為其 CUDA 生態系非常成熟,對 AI 任務的支援極佳。Transformers、Triton、vLLM 等主流 AI 函式庫都針對 CUDA 進行了深度優化。
推薦 GPU
適用於 GPT-OSS 20B(至少需要 16GB VRAM):
- 消費級或專業級顯卡,例如:
- NVIDIA RTX 4090(24GB)
- NVIDIA RTX 4080(16GB)
- NVIDIA RTX 4060 Ti(16GB)
- NVIDIA RTX 6000 Ada(48GB,專業卡)
- AMD Radeon RX 7900 XTX(24GB)
適用於 GPT-OSS 120B(至少需要 80GB VRAM):
- 資料中心級顯卡,例如:
- NVIDIA H100(80GB)
- NVIDIA H200(141GB)
- NVIDIA A100(80GB)
- NVIDIA A800(80GB)
你可以在 Novita AI 查詢詳細價格!
如何優化 GPT OSS 的 VRAM 使用量?
使用更輕量的推理框架:
- Llama.cpp:
這是一款跨平台輕量級推理引擎,支援 CPU 和 GPU(CUDA、Metal、Vulkan)運行。它支援 GGUF 等量化格式,能大幅縮小模型體積、降低記憶體消耗。 - vLLM:
這是一款高吞吐量推理與部署引擎,內建 PagedAttention、Flash Attention 3 等進階功能,運行大型模型時效率極高。
運用進階核心與量化技術:
- Flash Attention:
這是一種高效的注意力實現方案,能大幅降低記憶體使用量、加快計算速度,尤其在處理長序列時效果顯著。 - 混合精度與量化(mxfp4):
GPT-OSS 支援 mxfp4 4-bit 浮點格式。在 Hopper 或 Blackwell GPU 上搭配 Triton 核心使用時,能實現極低的 VRAM 消耗與極快的推理速度。 - MegaBlocks MoE 核心:
這是針對混合專家(MoE)模型優化的核心,能提升非 Hopper 架構 GPU 的運行效率。
透過 transformers 函式庫安裝與優化:
官方建議使用 transformers 函式庫,它內建了多項上述優化功能。要獲得最佳效能,你可以專門為 CUDA 12.8 安裝 PyTorch 和 Triton:
# Upgrade the basic libraries
pip install --upgrade accelerate transformers kernels
# (Optional) For best performance with CUDA 12.8 and Triton 3.4, install this version of PyTorch
pip install torch==2.8.0 --index-url https://download.pytorch.org/whl/test/cu128
雲端 GPU:小型開發者的明智選擇
由於本地運行的成本與複雜度較高,大多數開發者實際上更傾向於使用雲端 GPU 服務。
何時選擇本地 GPU
- 預算充足,能承擔數萬甚至數十萬美元的 upfront 硬體成本。
- 有長期、高負載的訓練或推理需求。
- 有嚴格的數據隱私要求,無法讓數據離開自有環境。
- 希望完全掌控硬體、軟體和網路配置。
何時選擇雲端 GPU
- 對成本敏感,希望避免大額硬體採購與後續維護費用,只需按用量付費。
- 需求彈性較大,可能還在實驗階段,或工作負載會隨時間變化。
- 希望即時獲得 H100、H200 等最新、最強勁的 GPU,無需等待採購流程。
- 不想處理繁瑣的驅動安裝、環境配置或實體維護工作。
如何在 Novita AI 這類雲端 GPU 平台上使用 GPT OSS?
步驟1:註冊帳號 如果你還不是 Novita AI 的用戶,請先在我們官網建立帳號。註冊完成後,前往「GPUs」分頁瀏覽可用資源,開啟你的使用之旅。

步驟2:瀏覽模板與 GPU 伺服器 首先選擇符合你專案需求的模板,例如 PyTorch、TensorFlow 或 CUDA,再選擇符合需求的版本,比如 PyTorch 2.2.1 或 CUDA 11.8.0。接著選擇 A100 GPU 伺服器配置,它擁有強勁效能,充足的 VRAM、RAM 和磁碟容量,能勝任高負載工作負載。

步驟3:自訂部署配置 選擇模板和 GPU 後,你可以調整作業系統版本(例如 CUDA 11.8)等參數,自訂部署設置,也可以修改其他配置,讓環境完全符合你的專案需求。
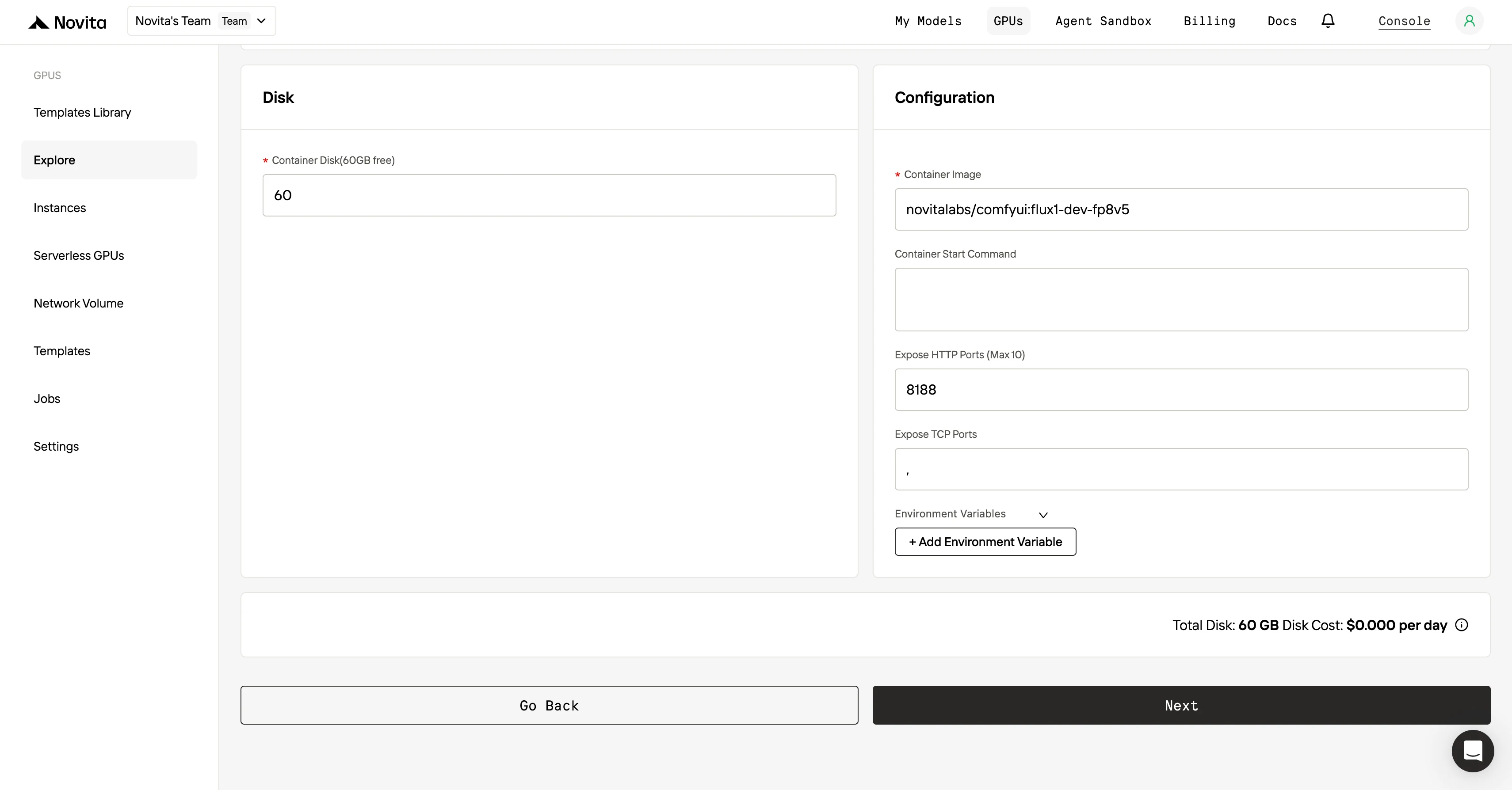
步驟4:啟動實例 確認模板和部署設置無誤後,點擊「Launch Instance」按鈕建立 GPU 實例,系統會自動開始環境配置,完成後你就可以使用 GPU 資源執行 AI 任務了。
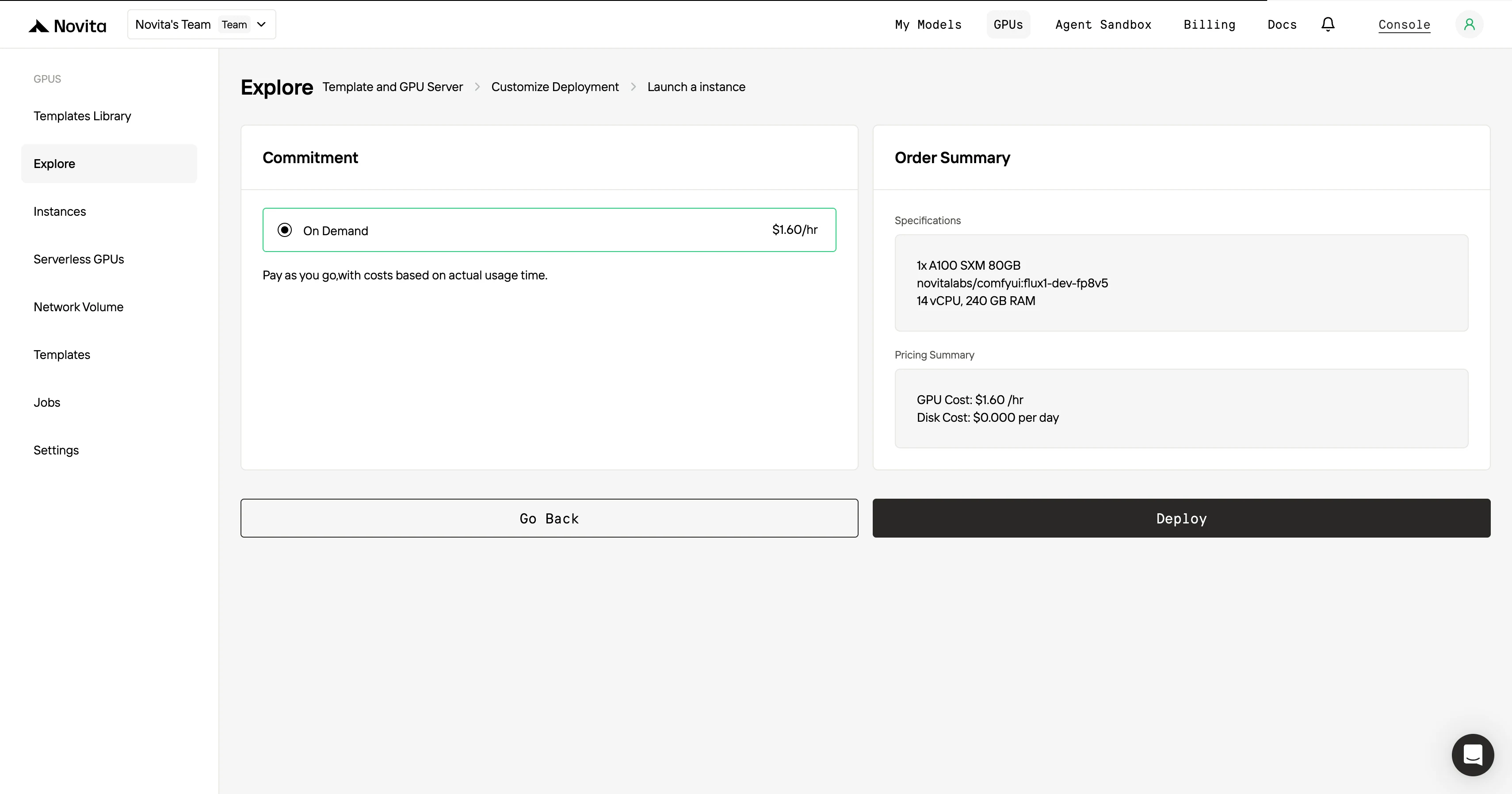
追求極致效率與便捷?使用 API 就對了!
Novita AI 提供 GPT-OSS 120B API,支援 131K 上下文,價格為 輸入 $0.1/百萬 token、輸出 $0.5/百萬 token。同時也提供 GPT-OSS 20B API,支援 131K 上下文,價格為 輸入 $0.05/百萬 token、輸出 $0.2/百萬 token,充分發揮 GPT OSS 在程式碼代理領域的潛力。
Novita AI
步驟1:登入並進入模型庫 登入你的帳號,點擊 模型庫 按鈕。

步驟2:選擇模型 瀏覽可用的模型選項,選擇符合你需求的模型。

步驟3:開始免費試用 開始免費試用,探索所選模型的能力。

步驟4:獲取 API 金鑰 為了進行 API 身份驗證,我們會為你提供新的 API 金鑰。進入「設定」頁面,即可按照圖中指示複製 API 金鑰。

步驟5:安裝 API 使用你所用程式語言對應的套件管理器安裝 API。 安裝完成後,將必要的函式庫匯入你的開發環境,使用 API 金鑰初始化 API,即可開始與 Novita AI LLM 互動。以下為 Python 使用者調用聊天補全 API 的範例:
from openai import OpenAI
client = OpenAI(
base_url="https://api.novita.ai/v3/openai",
api_key="",
)
model = "openai/gpt-oss-120b"
stream = True # or False
max_tokens = 65536
system_content = ""Be a helpful assistant""
temperature = 1
top_p = 1
min_p = 0
top_k = 50
presence_penalty = 0
frequency_penalty = 0
repetition_penalty = 1
response_format = { "type": "text" }
chat_completion_res = client.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": system_content,
},
{
"role": "user",
"content": "Hi there!",
}
],
stream=stream,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
response_format=response_format,
extra_body={
"top_k": top_k,
"repetition_penalty": repetition_penalty,
"min_p": min_p
}
)
if stream:
for chunk in chat_completion_res:
print(chunk.choices[0].delta.content or "", end="")
else:
print(chat_completion_res.choices[0].message.content)
要充分發揮 GPT-OSS 的效能,了解其 VRAM 需求至關重要:
- GPT-OSS 20B 至少需要 16GB VRAM,因此可以在 RTX 4060 Ti(16GB)這類高階消費級 GPU 上運行,個人與愛好者也能輕鬆入手。
- GPT-OSS 120B 需要 80GB VRAM,必須使用 NVIDIA H100 這類專業資料中心 GPU,對大多數個人和小型團隊來說門檻較高。
本地部署能提供最高的控制權,但同時也伴隨高昂的硬體成本與技術複雜度。使用 Llama.cpp 或 vLLM 這類輕量推理框架,搭配 mxfp4 量化、Flash Attention 等技術,可以降低 VRAM 需求。
對大多數開發者而言,雲端 GPU 是更聰明的選擇——無需大額前期投入,就能即時獲得頂級硬體。與此同時,Novita AI 這類託管 API 服務讓使用變得更加簡單:只需調用 API,就能直接使用 GPT-OSS,完全不用處理硬體或部署相關問題。這是平衡效能、成本與便捷性的最佳方案,讓強大的 AI 觸手可及。
常見問題
運行 GPT-OSS 需要多少 VRAM?
GPT-OSS 20B:至少需要 16GB VRAM。
GPT-OSS 120B:至少需要 80GB VRAM。
本地運行 GPT-OSS 20B 最省錢的方式是什麼? 使用搭載 16GB VRAM 的消費級 GPU(例如 NVIDIA RTX 4060 Ti(16GB)),搭配 Llama.cpp 這類輕量框架與 GGUF 量化模型即可。
如何降低 GPT-OSS 的 VRAM 使用量?
- 使用內建記憶體優化功能的輕量框架(Llama.cpp、vLLM)。
- 對模型進行量化(使用 mxfp4 或 GGUF 格式),降低精度以縮小記憶體佔用。
- 啟用 Flash Attention 等高效核心,尤其處理長文本時效果顯著。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 介面,方便部署 AI 模型,同時也提供高性價比、可靠的 GPU 雲端服務,用於建構與擴展 AI 應用。



