

KI-Entwicklung ist auf schnelle, bedarfsorientierte GPU-Infrastruktur angewiesen. Novita AI bietet eine sofort einsetzbare GPU-Cloud, die Warteschlangen und Einrichtungsverzögerungen eliminiert.
In realen Entwicklungs-Workflows können Teams innerhalb von Minuten NVIDIA A100- oder H100-Instanzen erstellen, um große Modelle feinzujustieren, Inferenz-Pipelines auszuführen oder neue Architekturen zu benchmarken, ohne auf gemeinsam genutzte Cluster-Ressourcen warten zu müssen.
Diese sofortige Skalierbarkeit hilft Entwicklern, schneller zu iterieren, Kosten zu kontrollieren und mit minimalen Reibungen von Prototyp zur Produktion zu gelangen.
Wichtige Erkenntnisse
Sofortige Bereitstellung: GPU-Instanzen starten in unter 30 Sekunden.
Preiswerte Leistung: A100/H100-GPUs zu wettbewerbsfähigen Stundensätzen, Spot-Instanzen sind bis zu 50 % günstiger.
Passend für den Einsatzzweck: Die A100 eignet sich für kleine/mittlere Modelle und gemeinsam genutzte Umgebungen; die H100 ist für massives LLM-Training ausgelegt.
Warum A100/H100 wählen?

A100 vs H100: Technischer Vergleich
| Merkmal | A100 (Ampere-Architektur) | H100 (Hopper-Architektur) |
|---|---|---|
| Architektur-Generation | Ampere – 3. Generation Tensor Cores. | Hopper – 4. Generation Tensor Cores + Transformer-Engine. |
| Speichertyp und Bandbreite | 80 GB HBM2e-Speicher 2 TB/s Bandbreite. |
80 GB HBM3-Speicher 3,9 TB/s Bandbreite. |
| MIG | Die A100 ermöglicht es, eine einzelne GPU in bis zu sieben isolierte Instanzen für Multi-Tenant- oder Multi-Modell-Workloads zu partitionieren. | Die H100 bietet eine stärkere Isolierung und verbesserte QoS für Multi-Tenant-Inferenz. |
A100 vs H100: Benchmarks
| Kategorie | A100 80GB SXM (Ampere) | H100 80GB SXM (Hopper) | Verbesserung (H100 vs A100) |
|---|---|---|---|
| Architektur | Ampere | Hopper | — |
| Speicher | HBM2e | HBM3 | Neue Generation |
| 80 GB | 80 GB | — | |
| 2,0 TB/s | 3,35 TB/s | +68 % | |
| Verbindung | 600 GB/s + PCIe Gen4 64 GB/s | 900 GB/s + PCIe Gen5 128 GB/s | +50 % NVLink-Geschwindigkeit |
| Leistung (TDP) | 400 W | Bis zu 700 W | +75 % (konfigurierbar) |
| MIG-Unterstützung | 7 × 10 GB | 7 × 10 GB | Gleiche Anzahl, verbesserte QoS |
| FP64 | 9,7 TFLOPS | 34 TFLOPS | +3,5× |
| FP64 Tensor Core | 19,5 TFLOPS | 67 TFLOPS | +3,4× |
| FP32 | 19,5 TFLOPS | 67 TFLOPS | +3,4× |
| TF32 Tensor Core | 156 / 312 TFLOPS (spärlich) | 989 TFLOPS | +3,2× (dicht) |
| BF16 Tensor Core | 312 / 624 TFLOPS (spärlich) | 1.979 TFLOPS | +3,2× |
| FP16 Tensor Core | 312 / 624 TFLOPS (spärlich) | 1.979 TFLOPS | +3,2× |
| FP8 Tensor Core | — | 3.958 TFLOPS | Neue Präzisionsstufe |
| INT8 Tensor Core | 624 / 1.248 TOPS (spärlich) | 3.958 TOPS | +3,2× |
Die H100 SXM stellt einen deutlichen Generationssprung gegenüber der A100 SXM sowohl im technischen Design als auch in der Benchmark-Leistung dar. Der Rechendurchsatz verdreifacht sich in etwa über alle Präzisionsstufen, während Speicher- und Verbindungsbandbreiten ebenfalls deutlich skalieren.
Die A100 bleibt energieeffizienter und kostengünstiger für gemeinsam genutzte oder mittelgroße Workloads, aber die H100 ist die überlegene Wahl für Entwickler, die maximale Geschwindigkeit und Skalierbarkeit anstreben.
A100 vs H100: Empfohlene Anwendungsfälle
| Anwendungsfall | Empfohlene GPU | Grund |
|---|---|---|
| Begrenztes Budget, Modelle ≤ 30 Mrd. Parameter, gemeinsam genutzte Nutzung | A100 | Bewährte Stabilität, hohe Kosteneffizienz, MIG-Unterstützung |
| Großskaliges Training (≥ 70 Mrd. Parameter), Multi-GPU-Knoten | H100 | Zukunftsorientiert, erstklassige Geschwindigkeit und Skalierbarkeit |
Kostenvergleich auf Novita AI
Novita bietet die niedrigsten On-Demand-H100-Preise ab 1,80 $/Stunde
bis zu 30 % günstiger als andere Anbieter mit identischer GPU-Leistung.
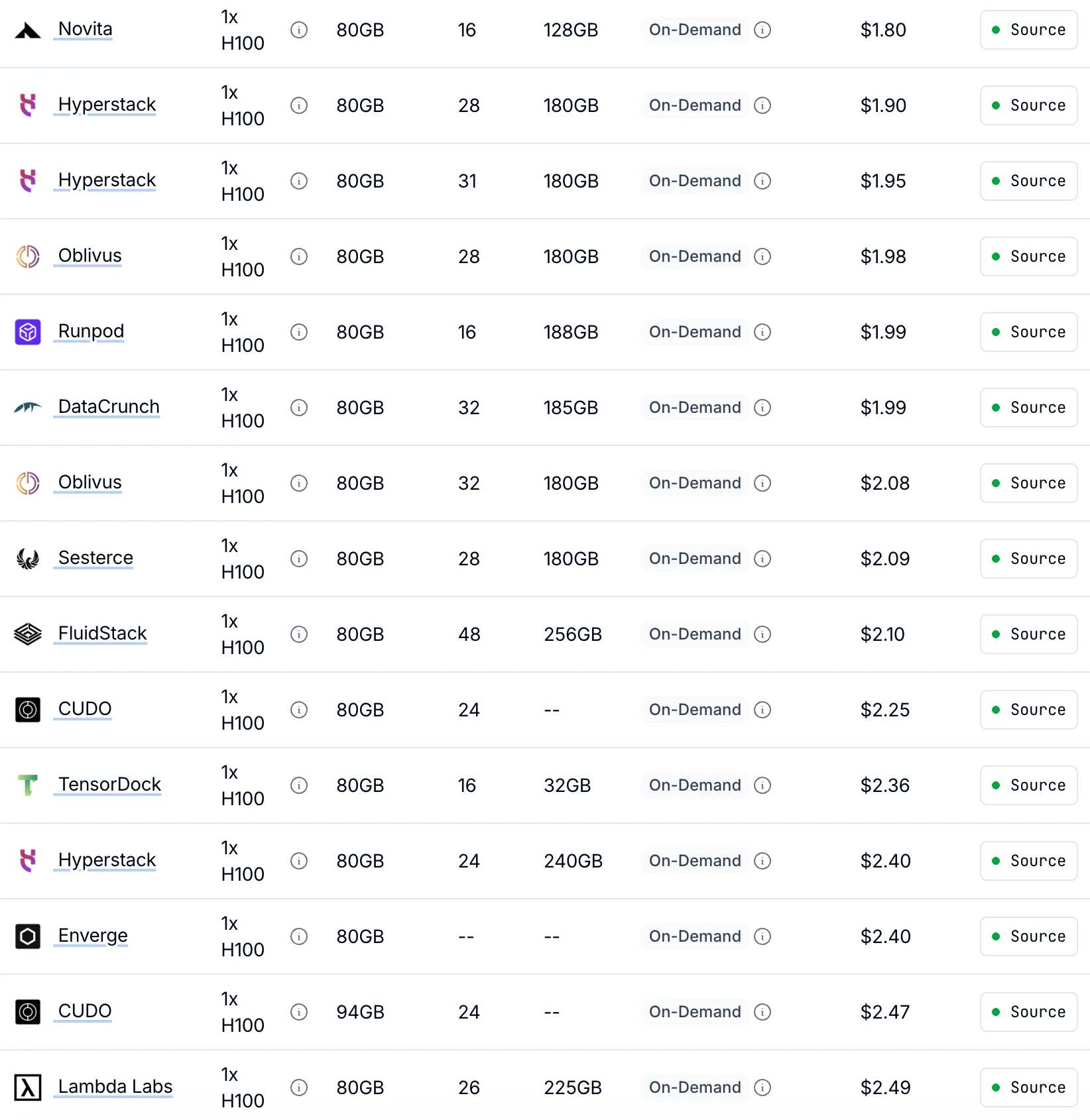
Von Getdeploying
| GPU-Typ | Spezifikation | Preismodell | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB VRAM | On-Demand | 1,45 $/Stunde | 11,60 $/Stunde |
| Spot | 0,73 $/Stunde | 5,84 $/Stunde | ||
| A100 SXM 80GB | 80 GB VRAM | On-Demand | 1,60 $/Stunde | 12,80 $/Stunde |
| Spot | 0,80 $/Stunde | 6,40 $/Stunde |
Der Spot-Modus von Novita AI ist eine kostenoptimierte GPU-Mietoption, die die ungenutzte oder Leerlauf-GPU-Kapazität der Plattform nutzt. Im Gegensatz zu On-Demand-Instanzen, die dedizierte Hardware für garantierte kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar – sie werden zu deutlich niedrigeren Preisen angeboten, typischerweise 40–60 % günstiger.
Dieses Preismodell funktioniert, weil Novita ungenutzte GPUs dynamisch an Kurzzeitnutzer neu zuweist, anstatt sie ungenutzt zu lassen. Dadurch verbessert die Plattform die gesamte Infrastrukturnutzungseffizienz, während Entwickler von deutlich niedrigeren Rechenkosten für flexible Workloads profitieren.
Warum Novita AI für die Miete von günstigen A100 und H100 wählen
- Sofortiger, globaler GPU-Zugriff: GPU-Instanzen starten in Sekunden in allen globalen Regionen, was niedrige Latenz und schnelle Experimente ermöglicht.
- Serverless + GPU-Cloud-Hybrid: Bietet sowohl vollständige GPU-Instanzen als auch serverlose GPU-Modi (Pay-as-you-go) für flexible Workload-Typen.
- Integrationen & Beobachtbarkeit: Kompatibel mit Monitoring/Tracing-Stacks (z. B. über Langfuse) und sofort einsetzbaren API-Endpunkten im OpenAI-Stil.
- Entwicklerzentrierte Kostenoptimierung: Neben dem Grundpreis senken Funktionen wie Spot-Instanzen (≈50 % Ersparnis) und schnelle Bereitstellung die Gesamtbetriebskosten.
Wie verwendet man A100 und H100 auf Novita AI?
Schritt 1:Konto registrieren
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Nach der Registrierung navigieren Sie zum Bereich „Explore“ in der linken Seitenleiste, um unsere GPU-Angebote einzusehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2:Vorlagen und GPU-Server erkunden
Wählen Sie aus Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu Ihren Projektanforderungen passen. Wählen Sie anschließend Ihre bevorzugte GPU-Konfiguration – Optionen umfassen die leistungsstarken L40S, RTX 4090 oder A100 SXM4, jeweils mit unterschiedlichen VRAM-, RAM- und Spezifikationsangaben.
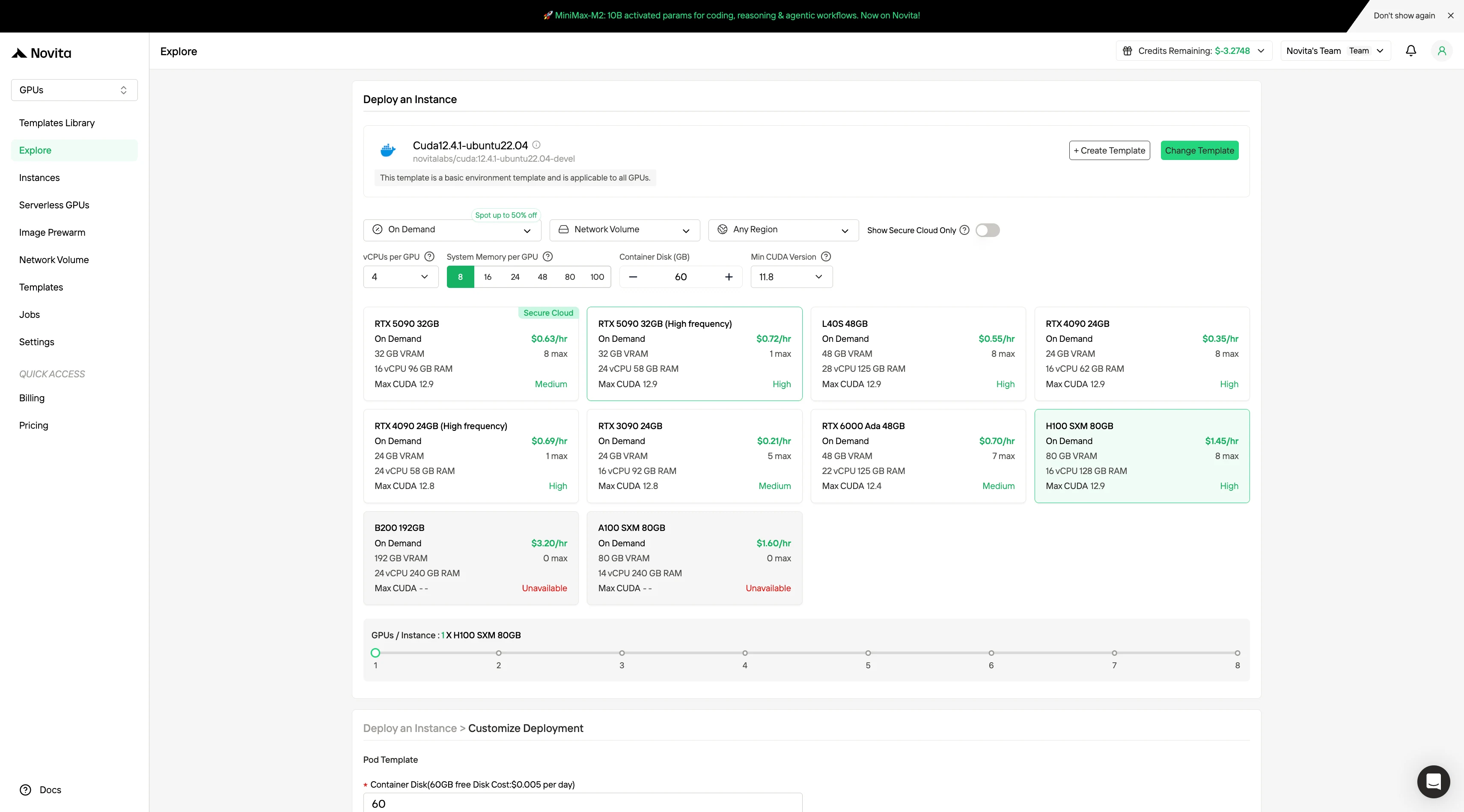
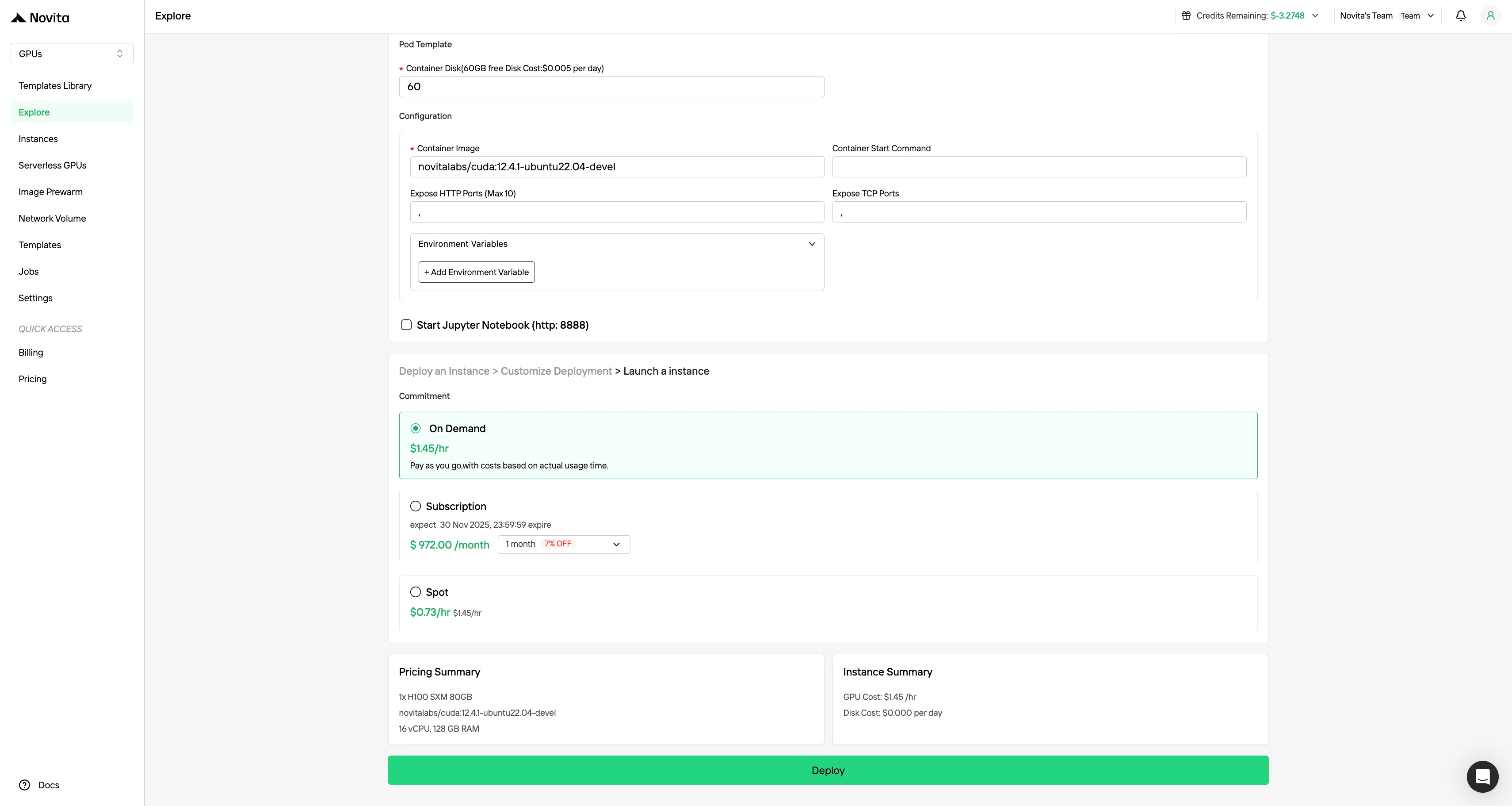
Schritt 3: Bereitstellung anpassen
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten.
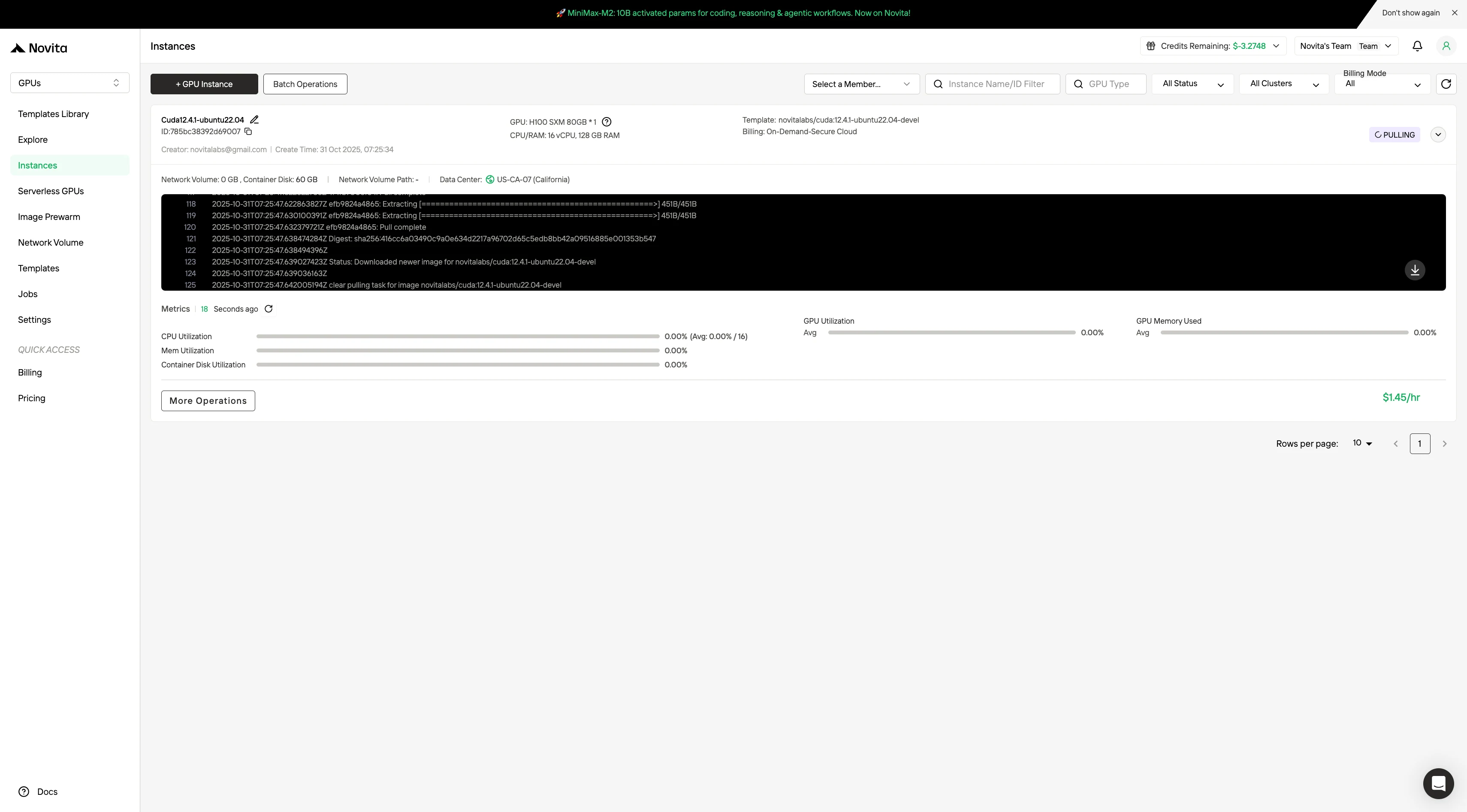
Schritt 4:Starten einer Instanz
Wählen Sie „Instanz starten“, um Ihre Bereitstellung zu beginnen. Ihre leistungsstarke GPU-Umgebung ist innerhalb von Minuten einsatzbereit, sodass Sie sofort mit Ihren Machine-Learning-, Rendering- oder Rechenprojekten starten können.
Die Auswahl von GPUs bedeutet, Leistung, Kosten und zukünftige Skalierbarkeit abzuwägen.
- Wählen Sie die A100, wenn Sie zuverlässige, kosteneffiziente Rechenleistung für mittelgroße LLMs oder Multi-Tenant-Aufgaben benötigen.
- Wählen Sie die H100, wenn Ihr Ziel großskaliges LLM-Training, Multi-GPU-Pipelines und modernster Durchsatz sind.
Die sofortige Bereitstellung und die flexiblen Preise von Novita AI machen es zu einer starken Plattform für beide Wege.
Nächster Schritt: Passen Sie Ihre Modellgröße und Ihr Budget an die richtige GPU an und starten Sie dann eine Instanz auf Novita AI GPUs, um Ihre Leistungsgewinne zu validieren.
Häufig gestellte Fragen
Gibt es weitere Vorteile neben den niedrigen Stundensätzen bei der Nutzung von Novita AI?
Ja – zu den Vorteilen gehören global verteilte GPU-Knoten für niedrige Latenz, serverlose GPU-Modi für Pay-as-you-go-Skalierbarkeit, eine einheitliche API für über 200 Modelle und vereinfachtes Infrastrukturmanagement.
Wann sollte ich die NVIDIA A100 statt der H100 wählen?
Wählen Sie die A100 für Workloads mit moderater Modellgröße (z. B. ≤30 Mrd. Parameter), gemeinsam genutzter Nutzung oder wenn Kosteneffizienz wichtiger ist als Spitzendurchsatz.
Wann ist die NVIDIA H100 die bessere Wahl?
Wählen Sie die H100, wenn Sie sehr große Modelle (70 Mrd. + Parameter) trainieren, Multi-GPU- oder Multi-Knoten-Setups verwenden oder den schnellsten Trainings- und Inferenzdurchsatz benötigen.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Erstellung und Skalierung bereitstellt.
Empfohlene Lektüre



