

AI 開發高度依賴快速、隨需應用的 GPU 基礎設施。Novita AI 提供可立即部署的 GPU 雲端服務,完全免除排隊與設定延遲。
在實際開發流程中,團隊可在數分鐘內啟動 NVIDIA A100 或 H100 執行個體,用於微調大型模型、執行推論管線,或測試新架構效能,完全無需等待共享叢集資源。
這種即時可擴展性能幫助開發者更快迭代、控制成本,並以極低的阻力從原型階段推進到量產。
重點摘要
即時部署: GPU 執行個體可在 30 秒內啟動。
高性價比效能: A100/H100 GPU 提供具競爭力的小時費率,Spot 執行個體價格最多可省 50%。
用途匹配: A100 適合中小型模型與共享環境;H100 則專為超大規模 LLM 訓練設計。
Check the Best Price on Novita AI Now!
為什麼選擇 A100/H100?

A100 與 H100 技術比較
| 功能 | A100(Ampere 架構) | H100(Hopper 架構) |
|---|---|---|
| 架構世代 | Ampere – 第 3 代 Tensor Core | Hopper – 第 4 代 Tensor Core + Transformer Engine |
| 記憶體類型與頻寬 | 80 GB HBM2e 記憶體 2 TB/s 頻寬 |
80 GB HBM3 記憶體 3.9 TB/s 頻寬 |
| MIG 技術 | A100 可將單張 GPU 分割為最多 7 個隔離執行個體,適用於多租戶或多模型工作負載 | H100 進一步強化隔離性,並提升多租戶推論的 QoS 表現 |
A100 與 H100 效能基準測試
| 類別 | A100 80GB SXM(Ampere) | H100 80GB SXM(Hopper) | 效能提升(H100 對比 A100) |
|---|---|---|---|
| 架構 | Ampere | Hopper | — |
| 記憶體 | HBM2e | HBM3 | 新一代 |
| 80 GB | 80 GB | — | |
| 2.0 TB/s | 3.35 TB/s | +68% | |
| 互連技術 | 600 GB/s + PCIe Gen4 64 GB/s | 900 GB/s + PCIe Gen5 128 GB/s | NVLink 速度提升 50% |
| 功耗(TDP) | 400 W | 最高 700 W | +75%(可配置) |
| MIG 支援 | 7 × 10 GB | 7 × 10 GB | 數量相同,QoS 更優 |
| FP64 | 9.7 TFLOPS | 34 TFLOPS | +3.5 倍 |
| FP64 Tensor Core | 19.5 TFLOPS | 67 TFLOPS | +3.4 倍 |
| FP32 | 19.5 TFLOPS | 67 TFLOPS | +3.4 倍 |
| TF32 Tensor Core | 156 / 312 TFLOPS(稀疏) | 989 TFLOPS | +3.2 倍(密集) |
| BF16 Tensor Core | 312 / 624 TFLOPS(稀疏) | 1,979 TFLOPS | +3.2 倍 |
| FP16 Tensor Core | 312 / 624 TFLOPS(稀疏) | 1,979 TFLOPS | +3.2 倍 |
| FP8 Tensor Core | — | 3,958 TFLOPS | 新增精度模式 |
| INT8 Tensor Core | 624 / 1,248 TOPS(稀疏) | 3,958 TOPS | +3.2 倍 |
H100 SXM 在技術設計與效能基準測試上,相較於 A100 SXM 都有明顯的世代躍升。所有精確度下的計算吞吐量大約提升至 3 倍,記憶體與互連頻寬也有顯著增長。
A100 在共享或中規模工作負載下仍具有更高的能源效率與成本效益,但對於追求極致速度與可擴展性的開發者來說,H100 是更優的選擇。
A100 與 H100 適用場景建議
| 適用場景 | 推薦 GPU | 原因 |
|---|---|---|
| 預算有限、模型參數量 ≤ 300 億、共享租用 | A100 | 穩定性經過驗證、成本效益高、支援 MIG 技術 |
| 大規模訓練(參數量 ≥ 700 億)、多 GPU 節點 | H100 | 符合未來需求、頂級速度與可擴展性 |
Novita AI 上的價格比較
Novita 提供業界最低的 H100 隨需定價,每小時僅需 1.80 美元
比提供相同 GPU 效能的其他供應商便宜高達 30%。
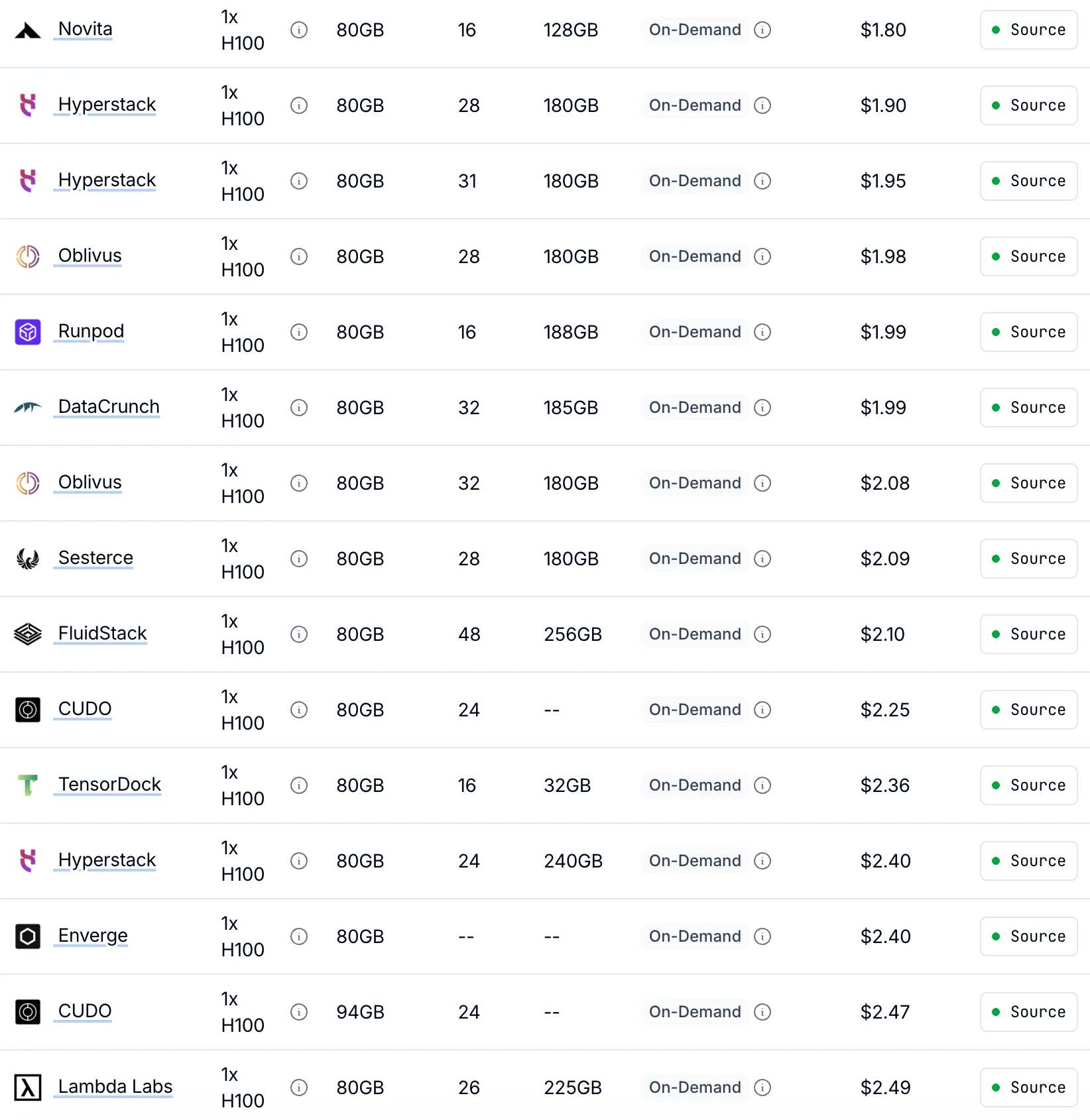
From Getdeploying
| GPU 類型 | 規格 | 定價模式 | 1 張 GPU | 8 張 GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB 視訊記憶體 | 隨需 | 1.45 美元/小時 | 11.60 美元/小時 |
| Spot | 0.73 美元/小時 | 5.84 美元/小時 | ||
| A100 SXM 80GB | 80 GB 視訊記憶體 | 隨需 | 1.60 美元/小時 | 12.80 美元/小時 |
| Spot | 0.80 美元/小時 | 6.40 美元/小時 |
Novita AI 的 Spot 模式是一種成本優化的 GPU 租賃選項,會利用平台上未使用或閒置的 GPU 容量。與預留專用硬體、保證持續使用的隨需執行個體不同,Spot 執行個體是可中斷的——價格低非常多,通常比隨需便宜 40–60%。
這個定價模式能運作,是因為 Novita 會動態將閒置的 GPU 重新分配給短期用戶,而非讓其閒置。透過這種方式,平台提升了整體基礎設施利用率,同時開發者也能以更低的運算成本執行彈性的工作負載。
為什麼選擇 Novita AI 租用平價 A100 與 H100
- 即時全球 GPU 存取:GPU 執行個體可在全球各地區於數秒內啟動,實現低延遲存取與快速實驗。
- Serverless + GPU 雲端混合模式:同時提供完整 GPU 執行個體與 Serverless GPU 模式(隨用隨付),適配各類型彈性工作負載。
- 整合與可觀測性:相容各類監控/追蹤堆疊(例如透過 Langfuse),並提供可直接使用的 OpenAI 風格 API 端點。
- 以開發者為核心的成本優化:除了基礎價格外,Spot 執行個體(約省 50% 費用)與快速啟動等功能,能進一步降低總擁有成本。
如何在 Novita AI 上使用 A100 與 H100?
步驟 1:註冊帳號
透過我們的官方網站建立 Novita AI 帳號。註冊完成後,前往左側邊欄的「Explore」頁面,即可查看我們提供的 GPU 選項,開始你的 AI 開發之旅。

步驟 2:選擇模板與 GPU 伺服器
根據你的專案需求選擇對應模板,例如 PyTorch、TensorFlow 或 CUDA。接著選擇你偏好的 GPU 配置,可選方案包括高效的 L40S、RTX 4090 或 A100 SXM4,每種配置的視訊記憶體(VRAM)、RAM 與儲存規格都不同。
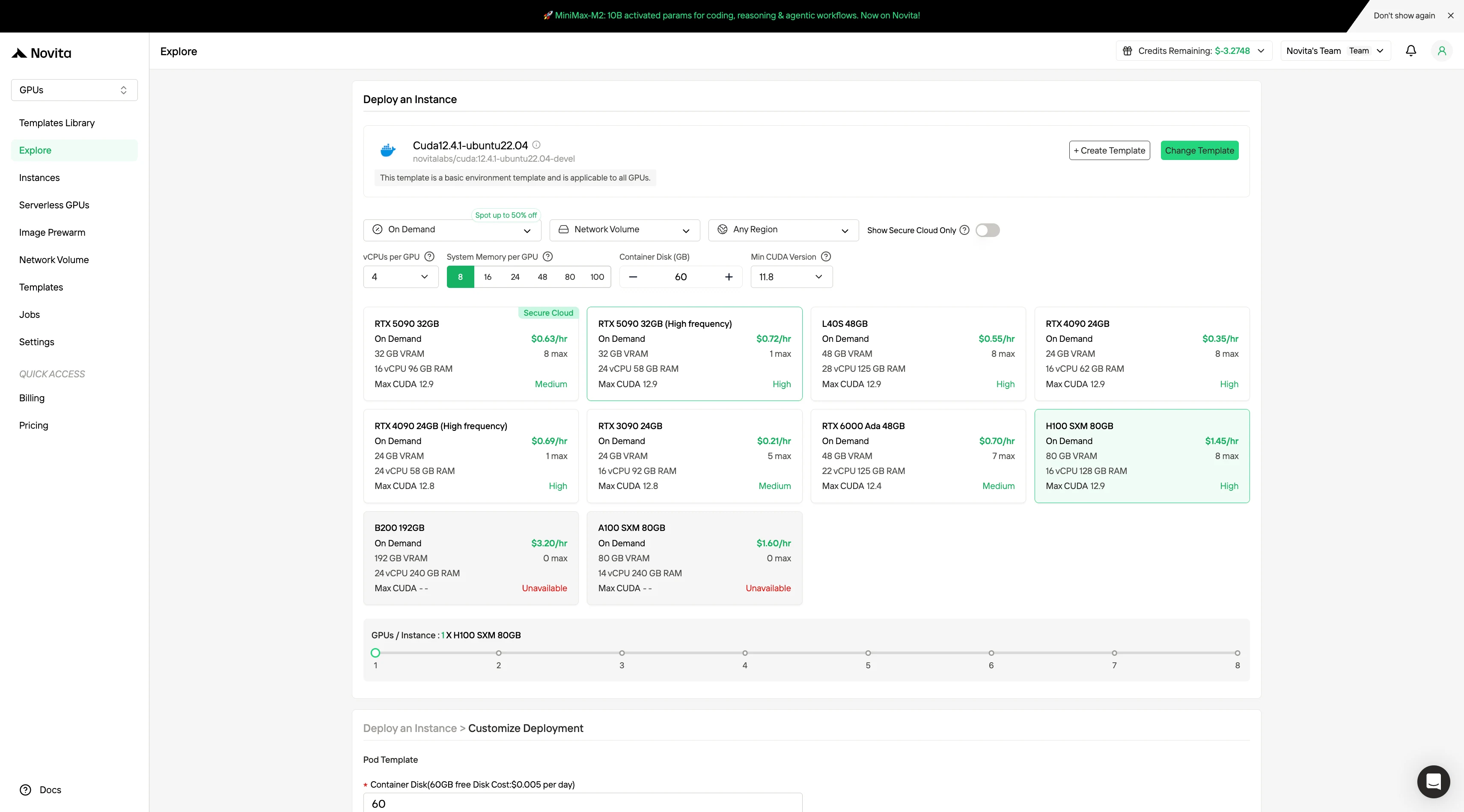
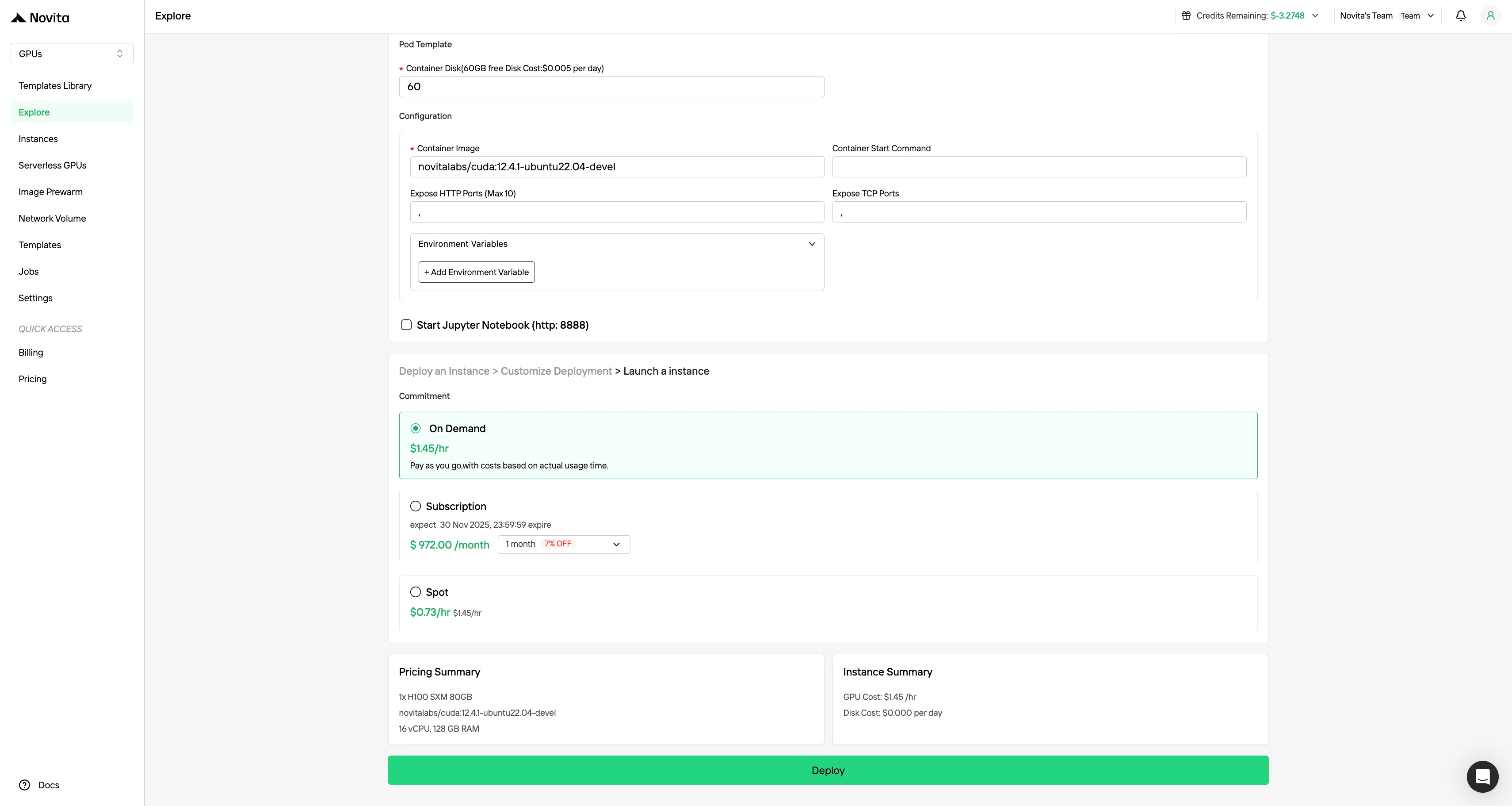
步驟 3:自訂部署配置
選擇你偏好的作業系統與配置選項,自訂你的執行環境,確保能為你的特定 AI 工作負載與開發需求發揮最佳效能。
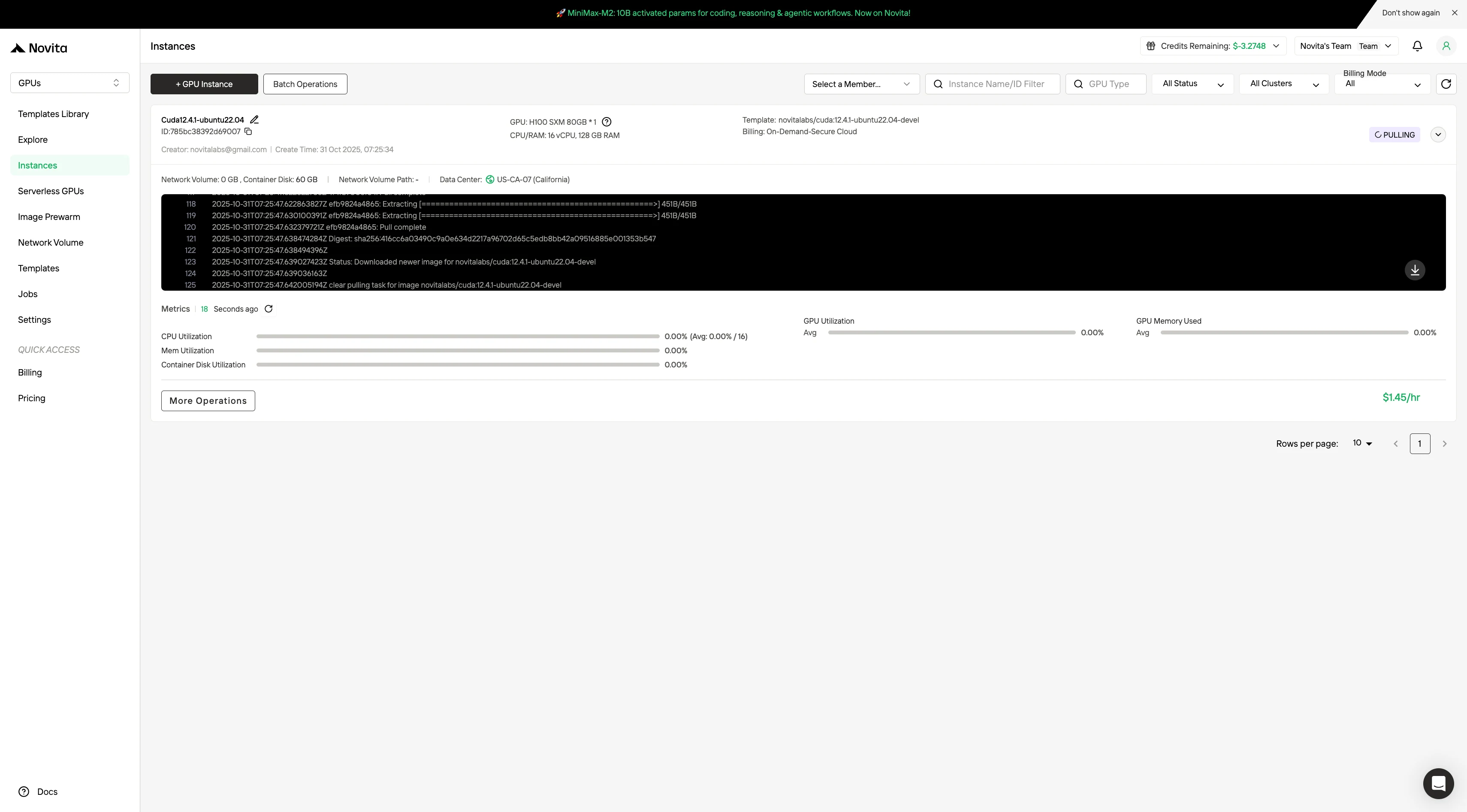
步驟 4:啟動執行個體
點選「Launch Instance」開始部署。你的高效能 GPU 環境將在數分鐘內準備完成,你可以立即開始進行機器學習、渲染或運算專案。
選擇 GPU 時需要平衡效能、成本與未來可擴展性三個要素。
- 如果你需要為中型 LLM 或多租戶任務提供可靠、高成本效益的運算資源,請選擇 A100。
- 如果你的目標是大規模 LLM 訓練、多 GPU 管線處理,以及追求頂級吞吐量,請選擇 H100。
Novita AI 的即時部署與彈性定價,能完美支援這兩種使用場景。
下一步: 根據你的模型大小與預算選擇合適的 GPU,並在 Novita AI GPUs 上啟動執行個體,驗證你能獲得的效能提升。
常見問題
使用 Novita AI 除了低小時費率外,還有其他額外好處嗎?
有的——額外好處包括:全球分布的 GPU 節點實現低延遲存取、隨用隨付的 Serverless GPU 模式實現彈性擴展、支援 200+ 模型的統一 API,以及簡化的基礎設施管理。
什麼時候應該選擇 NVIDIA A100 而非 H100?
當工作負載的模型參數量适中(例如 ≤300 億)、需要共享租用,或是成本效益比峰值吞吐量更重要時,選擇 A100 是更好的選擇。
什麼時候 NVIDIA H100 是更好的選擇?
當你訓練非常大的模型(700 億以上參數)、使用多 GPU 或多節點架構,或是需要最快的訓練與推論吞吐量時,選擇 H100 是更好的選擇。
Novita AI 是一個 AI 雲端平台,為開發者提供簡單的 API 來輕鬆部署 AI 模型,同時也提供平價、可靠的 GPU 雲端服務,用於建構與擴展 AI 應用。
推薦閱讀



