

El desarrollo de IA depende de una infraestructura de GPU rápida y bajo demanda. Novita AI ofrece una nube de GPU de implementación instantánea que elimina los retrasos de cola y configuración.
En flujos de trabajo reales, los equipos pueden poner en marcha instancias NVIDIA A100 o H100 en minutos para ajustar modelos grandes, ejecutar canalizaciones de inferencia o evaluar nuevas arquitecturas sin esperar recursos de clúster compartidos.
Esta escalabilidad inmediata ayuda a los desarrolladores a iterar más rápido, controlar costos y pasar del prototipo a la producción con una fricción mínima.
Conclusiones clave
Implementación instantánea: Las instancias de GPU se lanzan en menos de 30 segundos.
Rendimiento asequible: GPU A100/H100 a tarifas por hora competitivas, con instancias Spot hasta un 50 % más baratas.
Adecuado para el propósito: A100 es ideal para modelos pequeños/medianos y entornos compartidos; H100 se dirige al entrenamiento masivo de LLM.
¿Por qué elegir A100/H100?

Comparación técnica entre A100 y H100
| Característica | A100 (arquitectura Ampere) | H100 (arquitectura Hopper) |
|---|---|---|
| Generación de arquitectura | Ampere – Tensor Cores de 3.ª generación. | Hopper – Tensor Cores de 4.ª generación + Transformer Engine. |
| Tipo de memoria y ancho de banda | 80 GB HBM2e 2 TB/s de ancho de banda. |
80 GB HBM3 3.9 TB/s de ancho de banda. |
| MIG | A100 permite dividir una sola GPU en hasta siete instancias aisladas para cargas de trabajo multiinquilino o multimodelo. | H100 mejora con aislamiento más fuerte y QoS mejorada para inferencia multiinquilino. |
A100 vs H100: Comparativas
| Categoría | A100 80GB SXM (Ampere) | H100 80GB SXM (Hopper) | Mejora (H100 vs A100) |
|---|---|---|---|
| Arquitectura | Ampere | Hopper | — |
| Memoria | HBM2e | HBM3 | Nueva generación |
| 80 GB | 80 GB | — | |
| 2.0 TB/s | 3.35 TB/s | +68% | |
| Interconexión | 600 GB/s + PCIe Gen4 64 GB/s | 900 GB/s + PCIe Gen5 128 GB/s | +50% velocidad NVLink |
| Potencia (TDP) | 400 W | Hasta 700 W | +75% (configurable) |
| Soporte MIG | 7 × 10 GB | 7 × 10 GB | Misma cantidad, QoS mejorada |
| FP64 | 9.7 TFLOPS | 34 TFLOPS | +3,5× |
| FP64 Tensor Core | 19.5 TFLOPS | 67 TFLOPS | +3,4× |
| FP32 | 19.5 TFLOPS | 67 TFLOPS | +3,4× |
| TF32 Tensor Core | 156 / 312 TFLOPS (disperso) | 989 TFLOPS | +3,2× (denso) |
| BF16 Tensor Core | 312 / 624 TFLOPS (disperso) | 1,979 TFLOPS | +3,2× |
| FP16 Tensor Core | 312 / 624 TFLOPS (disperso) | 1,979 TFLOPS | +3,2× |
| FP8 Tensor Core | — | 3,958 TFLOPS | Nuevo modo de precisión |
| INT8 Tensor Core | 624 / 1,248 TOPS (disperso) | 3,958 TOPS | +3,2× |
La H100 SXM ofrece un salto generacional claro sobre la A100 SXM tanto en diseño técnico como en rendimiento de referencia. El rendimiento de cómputo aproximadamente se triplica en todas las precisiones, mientras que el ancho de banda de la memoria y la interconexión también aumentan significativamente.
La A100 sigue siendo más eficiente energéticamente y rentable para cargas de trabajo compartidas o de escala media, pero la H100 es la opción superior para desarrolladores que buscan máxima velocidad y escalabilidad.
A100 vs H100: Casos de uso recomendados
| Caso de uso | GPU recomendada | Por qué |
|---|---|---|
| Presupuesto limitado, modelos ≤ 30 B parámetros, tenencia compartida | A100 | Estabilidad probada, buena eficiencia de costos, soporte MIG |
| Entrenamiento a gran escala (≥ 70 B parámetros), nodos multi-GPU | H100 | Preparado para el futuro, velocidad y escalabilidad de primer nivel |
Comparación de costos en Novita AI
Novita ofrece el precio bajo demanda más bajo para H100 a $1.80/hora
hasta un 30% más barato que otros proveedores con rendimiento de GPU idéntico.
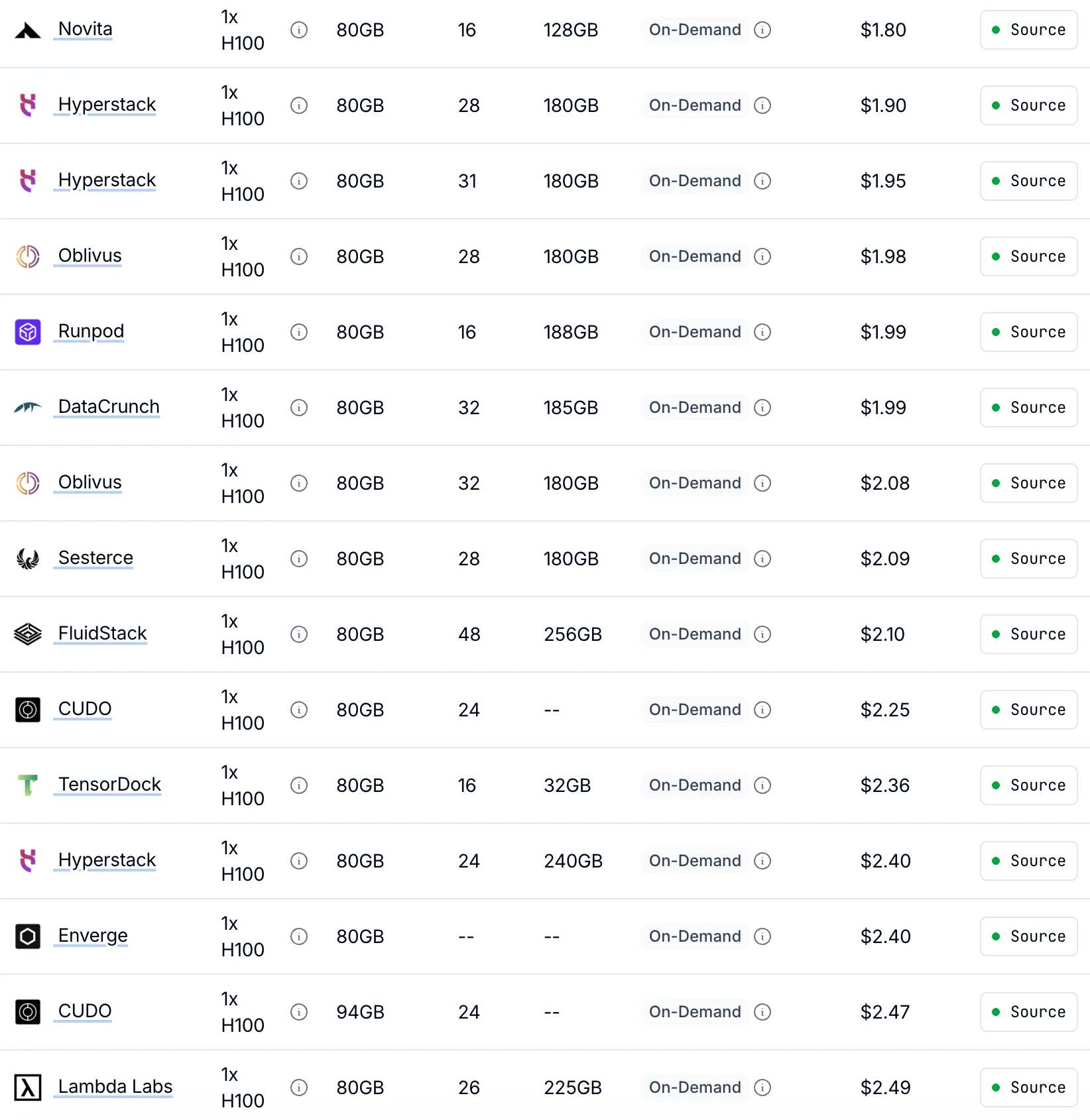
De Getdeploying
| Tipo de GPU | Especificación | Modelo de precio | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB VRAM | Bajo demanda | $1.45/hora | $11.60/hora |
| Spot | $0.73/hora | $5.84/hora | ||
| A100 SXM 80GB | 80 GB VRAM | Bajo demanda | $1.60/hora | $12.80/hora |
| Spot | $0.80/hora | $6.40/hora |
El modo Spot de Novita AI es una opción de alquiler de GPU optimizada en costos que aprovecha la capacidad de GPU no utilizada o inactiva de la plataforma. A diferencia de las instancias bajo demanda, que reservan hardware dedicado para uso continuo garantizado, las instancias Spot son interrumpibles y se ofrecen a precios significativamente más bajos, típicamente 40–60% más baratas.
Este modelo de precios funciona porque Novita reasigna dinámicamente las GPU inactivas a usuarios a corto plazo en lugar de dejarlas sin usar. Al hacerlo, la plataforma mejora la eficiencia general de utilización de la infraestructura, mientras que los desarrolladores se benefician de costos computacionales mucho más bajos para cargas de trabajo flexibles.
¿Por qué elegir Novita AI para alquilar A100 y H100 baratos?
- Acceso instantáneo a GPU globales: Las instancias de GPU se lanzan en segundos en regiones globales, permitiendo acceso de baja latencia y experimentación rápida.
- Híbrido Serverless + GPU Cloud: Ofrece tanto instancias de GPU completas como modos de GPU sin servidor (pago por uso) para tipos de carga de trabajo flexibles.
- Integraciones y observabilidad: Compatible con pilas de monitoreo/seguimiento (por ejemplo, a través de Langfuse) y endpoints API de estilo OpenAI.
- Optimización de costos centrada en el desarrollador: Además del precio base, características como instancias Spot (≈50% de ahorro) y el inicio rápido reducen el costo total de propiedad.
¿Cómo usar A100 y H100 en Novita AI?
Paso 1: Registrarse
Crea tu cuenta de Novita AI a través de nuestro sitio web. Después del registro, navega a la sección “Explorar” en la barra lateral izquierda para ver nuestras ofertas de GPU y comenzar tu viaje de desarrollo de IA.

Paso 2: Explorar plantillas y servidores GPU
Elige entre plantillas como PyTorch, TensorFlow o CUDA que se ajusten a las necesidades de tu proyecto. Luego selecciona la configuración de GPU que prefieras: las opciones incluyen la potente L40S, RTX 4090 o A100 SXM4, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.
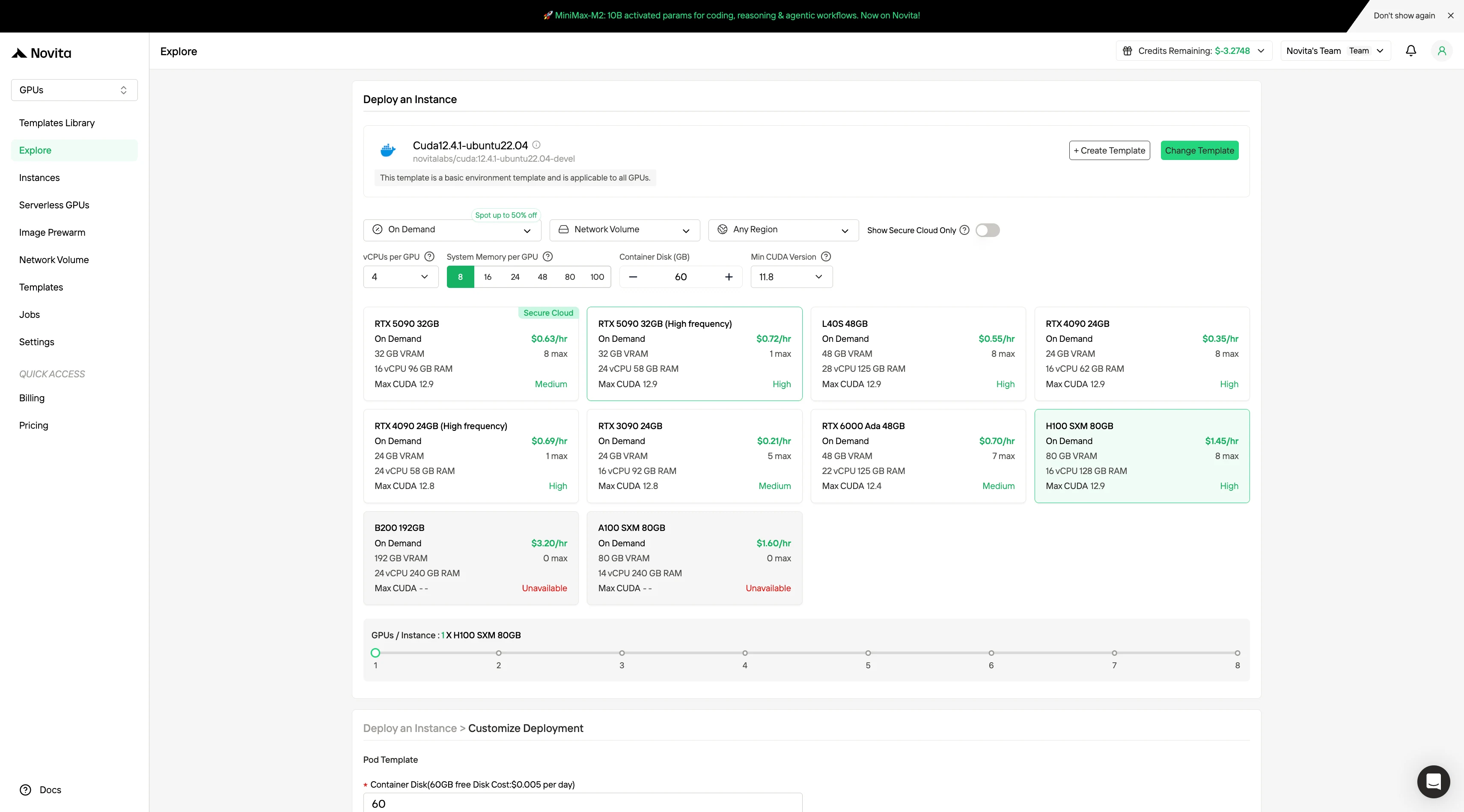
Paso 3: Personalizar tu implementación
Personaliza tu entorno seleccionando tu sistema operativo preferido y las opciones de configuración para garantizar un rendimiento óptimo para tus cargas de trabajo de IA específicas y necesidades de desarrollo.
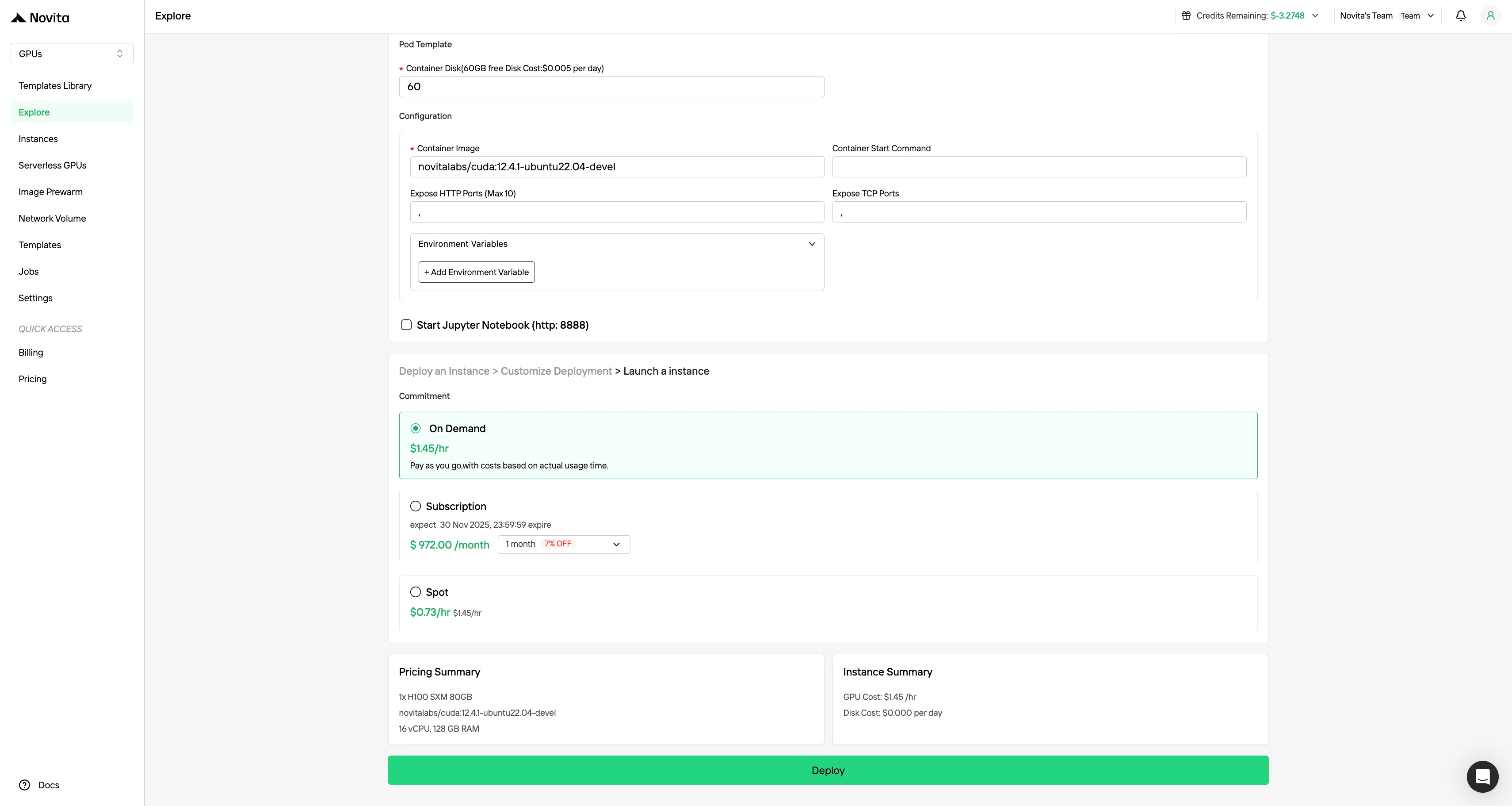
Paso 4: Lanzar una instancia
Selecciona “Launch Instance” para iniciar tu implementación. Tu entorno de GPU de alto rendimiento estará listo en minutos, permitiéndote comenzar inmediatamente tus proyectos de aprendizaje automático, renderizado o computación.
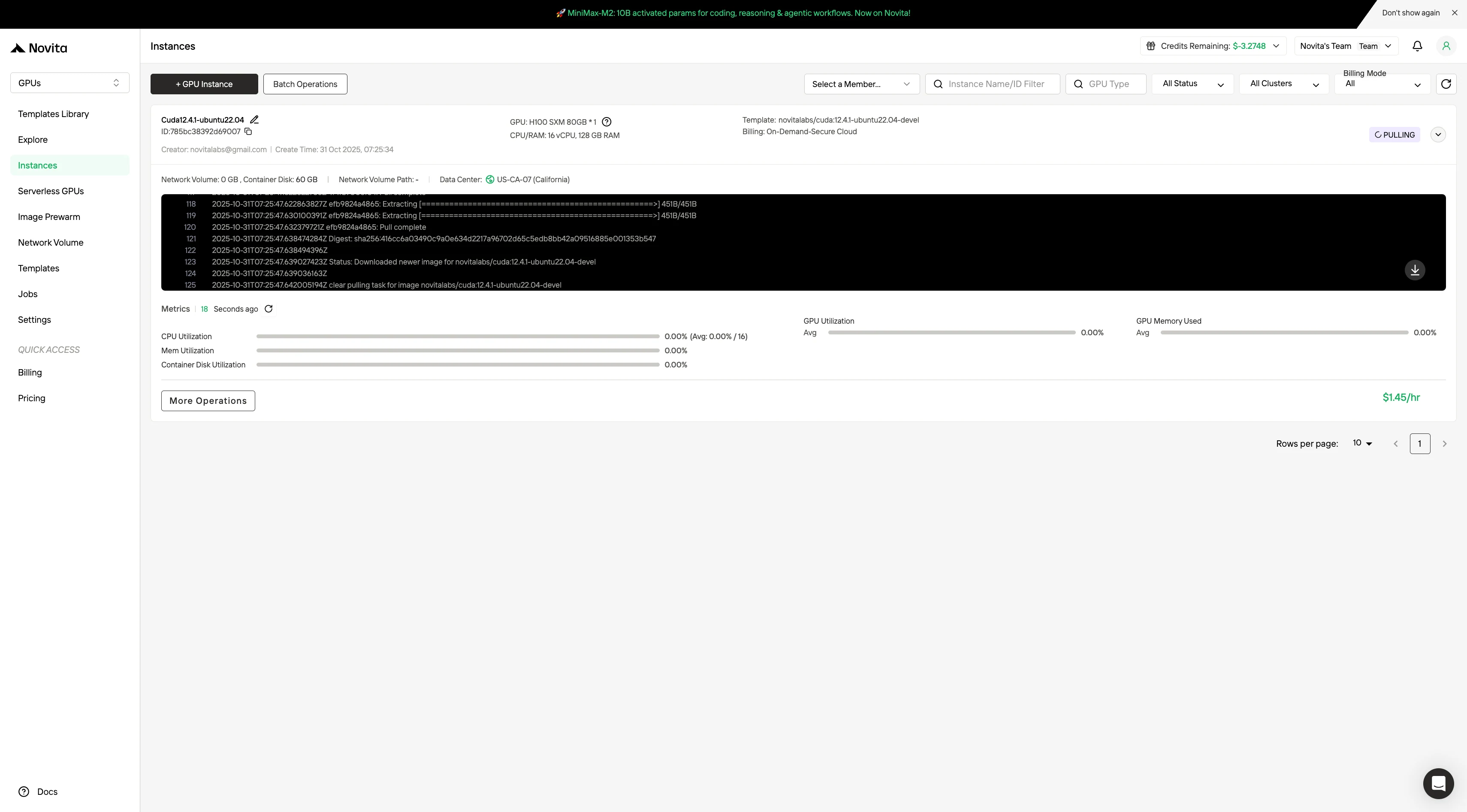
Seleccionar GPUs implica equilibrar rendimiento, costo y escalabilidad futura.
- Elige A100 si necesitas cómputo confiable y rentable para LLM de tamaño mediano o tareas multiinquilino.
- Elige H100 si tu objetivo es el entrenamiento de LLM a gran escala, canalizaciones multi-GPU y rendimiento de vanguardia.
La implementación instantánea y los precios flexibles de Novita AI lo convierten en una plataforma sólida para ambos caminos.
Próximo paso: Haz coincidir el tamaño de tu modelo y presupuesto con la GPU adecuada, luego inicia una instancia en Novita AI GPUs para validar tus ganancias de rendimiento.
Preguntas Frecuentes
¿Hay beneficios adicionales más allá del bajo costo por hora al usar Novita AI?
Sí: los beneficios incluyen nodos de GPU distribuidos globalmente para acceso de baja latencia, modos de GPU sin servidor para escalabilidad de pago por uso, API unificada para más de 200 modelos y gestión de infraestructura simplificada.
¿Cuándo debo elegir la NVIDIA A100 sobre la H100?
Elige A100 para cargas de trabajo con tamaño de modelo moderado (por ejemplo, ≤30 B parámetros), tenencia compartida o cuando la eficiencia de costos sea más importante que el rendimiento máximo.
¿Cuándo se convierte la NVIDIA H100 en la mejor opción?
Elige H100 cuando entrenes modelos muy grandes (70 B+ parámetros), uses configuraciones multi-GPU o multinodo, o necesites el rendimiento más rápido de entrenamiento e inferencia.
Novita AI es una plataforma de nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA usando nuestra API simple, al mismo tiempo que proporciona la nube de GPU asequible y confiable para construir y escalar.
Lectura recomendada



