

يعتمد تطوير الذكاء الاصطناعي على بنية تحتية فورية لوحدات معالجة الرسومات (GPU) عند الطلب. توفر Novita AI سحابة GPU قابلة للنشر الفوري التي تلغي أوقات الانتظار وتأخيرات الإعداد.
في سير عمل التطوير الفعلي، يمكن للفرق تشغيل مثيلات NVIDIA A100 أو H100 في غضون دقائق لضبط النماذج الكبيرة بدقة، أو تشغيل خطوط أنابيب الاستدلال، أو اختبار بنى جديدة دون انتظار موارد المجموعة المشتركة.
تساعد هذه القابلية للتوسع الفوري المطورين على التكرار بشكل أسرع، والتحكم في التكاليف، والانتقال من النموذج الأولي إلى الإنتاج بأقل قدر من الاحتكاك.
النقاط الرئيسية
النشر الفوري: تبدأ مثيلات GPU في أقل من 30 ثانية.
أداء بأسعار معقولة: وحدات GPU A100/H100 بأسعار ساعية تنافسية، مع مثيلات Spot تصل إلى 50% أرخص.
مناسبة للغرض: تناسب A100 النماذج الصغيرة/المتوسطة والبيئات المشتركة؛ بينما تستهدف H100 تدريب نماذج اللغة الكبيرة الضخمة.
لماذا تختار A100/H100؟

مقارنة تقنية بين A100 و H100
| الميزة | A100 (بنية Ampere) | H100 (بنية Hopper) |
|---|---|---|
| جيل البنية | Ampere – نوى Tensor من الجيل الثالث. | Hopper – نوى Tensor من الجيل الرابع + محول Transformer Engine. |
| نوع الذاكرة وعرض النطاق | ذاكرة HBM2e سعة 80 جيجابايت عرض نطاق 2 تيرابايت/ثانية. |
ذاكرة HBM3 سعة 80 جيجابايت عرض نطاق 3.9 تيرابايت/ثانية. |
| MIG | تسمح A100 بتقسيم وحدة GPU واحدة إلى ما يصل إلى سبع مثيلات منعزلة لأحمال عمل متعددة المستأجرين أو متعددة النماذج. | تعزز H100 بعزل أقوى وجودة خدمة (QoS) محسنة للاستدلال متعدد المستأجرين. |
مقارنة أداء بين A100 و H100
| الفئة | A100 80GB SXM (Ampere) | H100 80GB SXM (Hopper) | التحسين (H100 مقابل A100) |
|---|---|---|---|
| البنية | Ampere | Hopper | — |
| الذاكرة | HBM2e | HBM3 | جيل جديد |
| 80 جيجابايت | 80 جيجابايت | — | |
| 2.0 تيرابايت/ثانية | 3.35 تيرابايت/ثانية | +68% | |
| التوصيل البيني | 600 جيجابايت/ثانية + PCIe Gen4 64 جيجابايت/ثانية | 900 جيجابايت/ثانية + PCIe Gen5 128 جيجابايت/ثانية | +50% سرعة NVLink |
| الطاقة (TDP) | 400 وات | حتى 700 وات | +75% (قابل للتكوين) |
| دعم MIG | 7 × 10 جيجابايت | 7 × 10 جيجابايت | نفس العدد، جودة خدمة (QoS) محسنة |
| FP64 | 9.7 TFLOPS | 34 TFLOPS | +3.5× |
| نواة Tensor FP64 | 19.5 TFLOPS | 67 TFLOPS | +3.4× |
| FP32 | 19.5 TFLOPS | 67 TFLOPS | +3.4× |
| نواة Tensor TF32 | 156 / 312 TFLOPS (متناثر) | 989 TFLOPS | +3.2× (كثيف) |
| نواة Tensor BF16 | 312 / 624 TFLOPS (متناثر) | 1,979 TFLOPS | +3.2× |
| نواة Tensor FP16 | 312 / 624 TFLOPS (متناثر) | 1,979 TFLOPS | +3.2× |
| نواة Tensor FP8 | — | 3,958 TFLOPS | وضع دقة جديد |
| نواة Tensor INT8 | 624 / 1,248 TOPS (متناثر) | 3,958 TOPS | +3.2× |
يوفر H100 SXM قفزة جيلية واضحة مقارنة بـ A100 SXM من حيث التصميم التقني وأداء الاختبارات. يتضاعف الإنتاجية الحسابية ثلاث مرات تقريبًا عبر جميع الدقات، بينما تتوسع أيضًا عرض نطاق الذاكرة والتوصيل البيني بشكل كبير.
تظل A100 أكثر كفاءة في استهلاك الطاقة وتكلفة لأحمال العمل المشتركة أو متوسطة الحجم، لكن H100 هو الخيار الأفضل للمطورين الذين يستهدفون أقصى سرعة وقابلية للتوسع.
حالات الاستخدام الموصى بها: A100 مقابل H100
| حالة الاستخدام | GPU الموصى به | السبب |
|---|---|---|
| ميزانية محدودة، نماذج ≤ 30 مليار معامل، مستأجرين مشتركين | A100 | استقرار مثبت، كفاءة تكلفة عالية، دعم MIG |
| تدريب على نطاق واسع (≥ 70 مليار معامل)، عقد GPU متعددة | H100 | جاهز للمستقبل، سرعة وقابلية توسع من الفئة الأولى |
مقارنة التكاليف على Novita AI
تقدم Novita أدنى سعر لـ H100 عند الطلب بمعدل 1.80 دولار للساعة
ما يصل إلى 30% أرخص من مقدمي الخدمة الآخرين بأداء GPU متطابق.
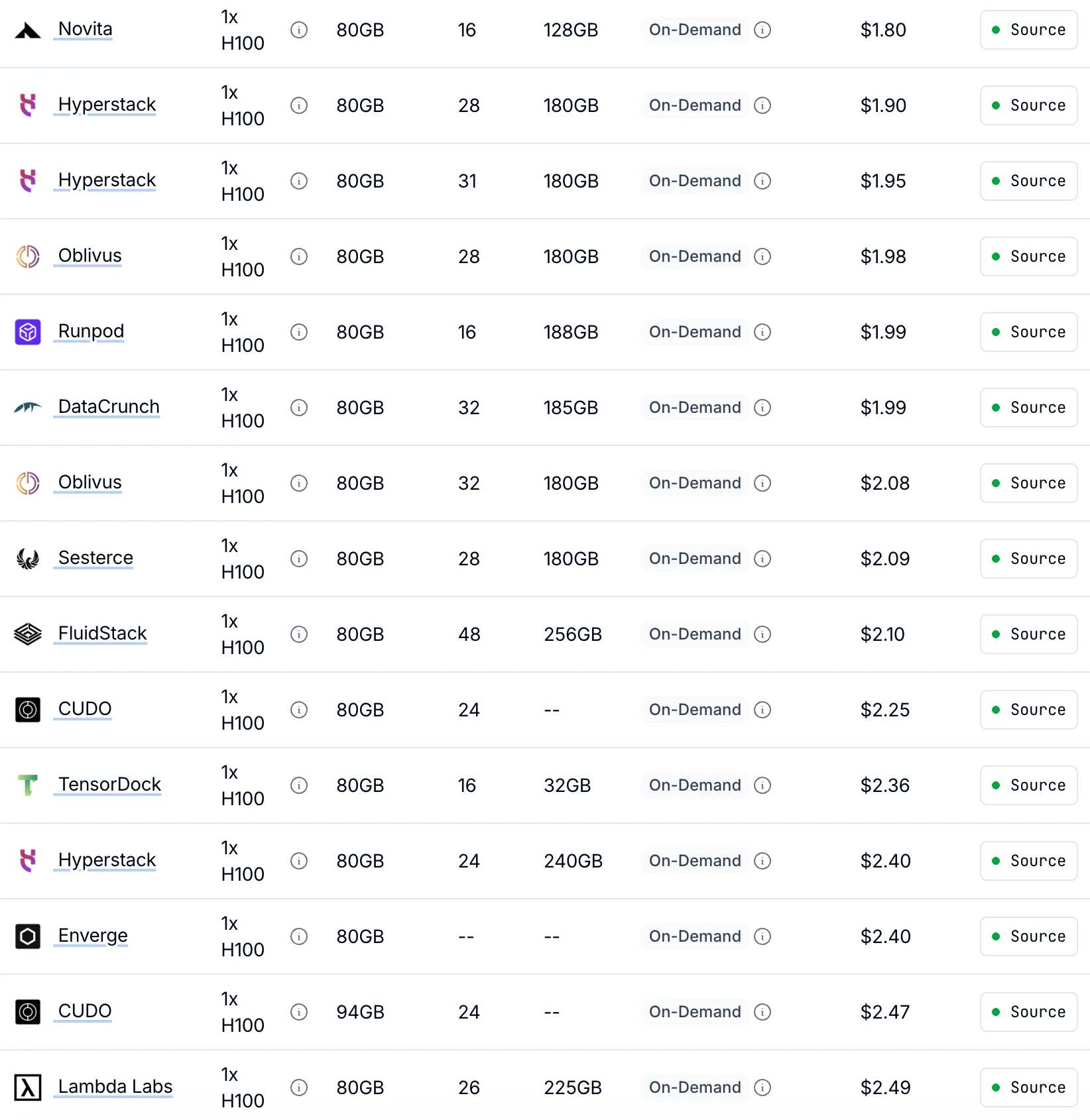
من Getdeploying
| نوع GPU | المواصفات | نموذج التسعير | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | ذاكرة VRAM سعة 80 جيجابايت | عند الطلب | 1.45 دولار/ساعة | 11.60 دولار/ساعة |
| Spot | 0.73 دولار/ساعة | 5.84 دولار/ساعة | ||
| A100 SXM 80GB | ذاكرة VRAM سعة 80 جيجابايت | عند الطلب | 1.60 دولار/ساعة | 12.80 دولار/ساعة |
| Spot | 0.80 دولار/ساعة | 6.40 دولار/ساعة |
وضع Spot من Novita AI هو خيار استئجار GPU مُحسّن للتكاليف يستخدم سعة GPU غير المستخدمة أو الخاملة للمنصة. على عكس المثيلات عند الطلب، التي تحجز أجهزة مخصصة لاستخدام مستمر مضمون، فإن مثيلات Spot قابلة للقطع — معروضة بأسعار أقل بكثير، عادةً أرخص بنسبة 40-60%.
يعمل نموذج التسعير هذا لأن Novita تعيد تخصيص وحدات GPU الخالية ديناميكيًا للمستخدمين على المدى القصير بدلاً من تركها غير مستخدمة. من خلال القيام بذلك، تعمل المنصة على تحسين كفاءة استخدام البنية التحتية بشكل عام، بينما يستفيد المطورون من تكاليف حسابية أقل بكثير لأحمال العمل المرنة.
لماذا تختار Novita AI لاستئجار A100 و H100 بأسعار منخفضة
- وصول فوري وعالمي لوحدات GPU: تبدأ مثيلات GPU في ثوانٍ عبر المناطق العالمية، مما يتيح وصولاً منخفض الزمن وتجارب سريعة.
- هجين خوادم بدون خوادم + سحابة GPU: يقدم كلاً من مثيلات GPU الكاملة وأوضاع GPU بدون خوادم (ادفع حسب الاستخدام) لأنواع أحمال العمل المرنة.
- التكاملات والمراقبة: متوافق مع مكدسات المراقبة والتتبع (مثل عبر Langfuse) ونقاط نهاية API بأسلوب OpenAI الجاهزة للاستخدام.
- تحسين التكاليف يركز على المطورين: إلى جانب السعر الأساسي، تقلل ميزات مثل مثيلات Spot (توفير ≈ 50%) والتشغيل السريع من إجمالي تكلفة الملكية.
كيفية استخدام A100 و H100 على Novita AI؟
الخطوة 1:تسجيل حساب
أنشئ حساب Novita AI الخاص بك عبر موقعنا الإلكتروني. بعد التسجيل، انتقل إلى قسم “استكشاف” في الشريط الجانبي الأيسر لعرض عروض GPU الخاصة بنا وابدأ رحلة تطوير الذكاء الاصطناعي الخاصة بك.

الخطوة 2: استكشاف القوالب وخوادم GPU**
اختر من بين القوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم اختر تكوين GPU المفضل لديك — تتضمن الخيارات L40S القوي، أو RTX 4090 أو A100 SXM4، لكل منها مواصفات مختلفة لذاكرة VRAM وذاكرة الوصول العشوائي (RAM) والتخزين.
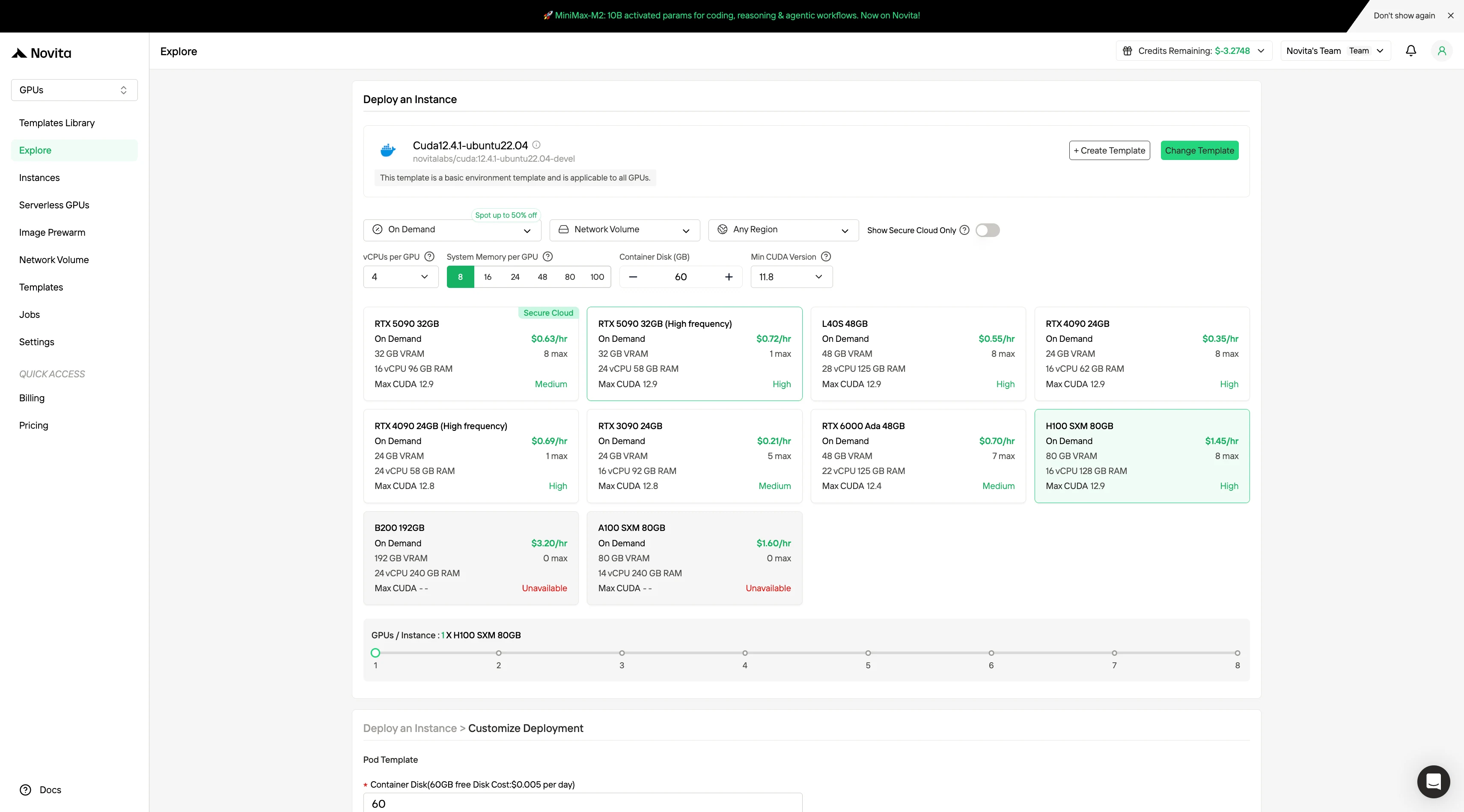
الخطوة 3:تخصيص النشر الخاص بك
خصص بيئتك عن طريق اختيار نظام التشغيل وخيارات التكوين المفضلة لديك لضمان الأداء الأمثل لأحمال عمل الذكاء الاصطناعي الخاصة بك واحتياجات التطوير.
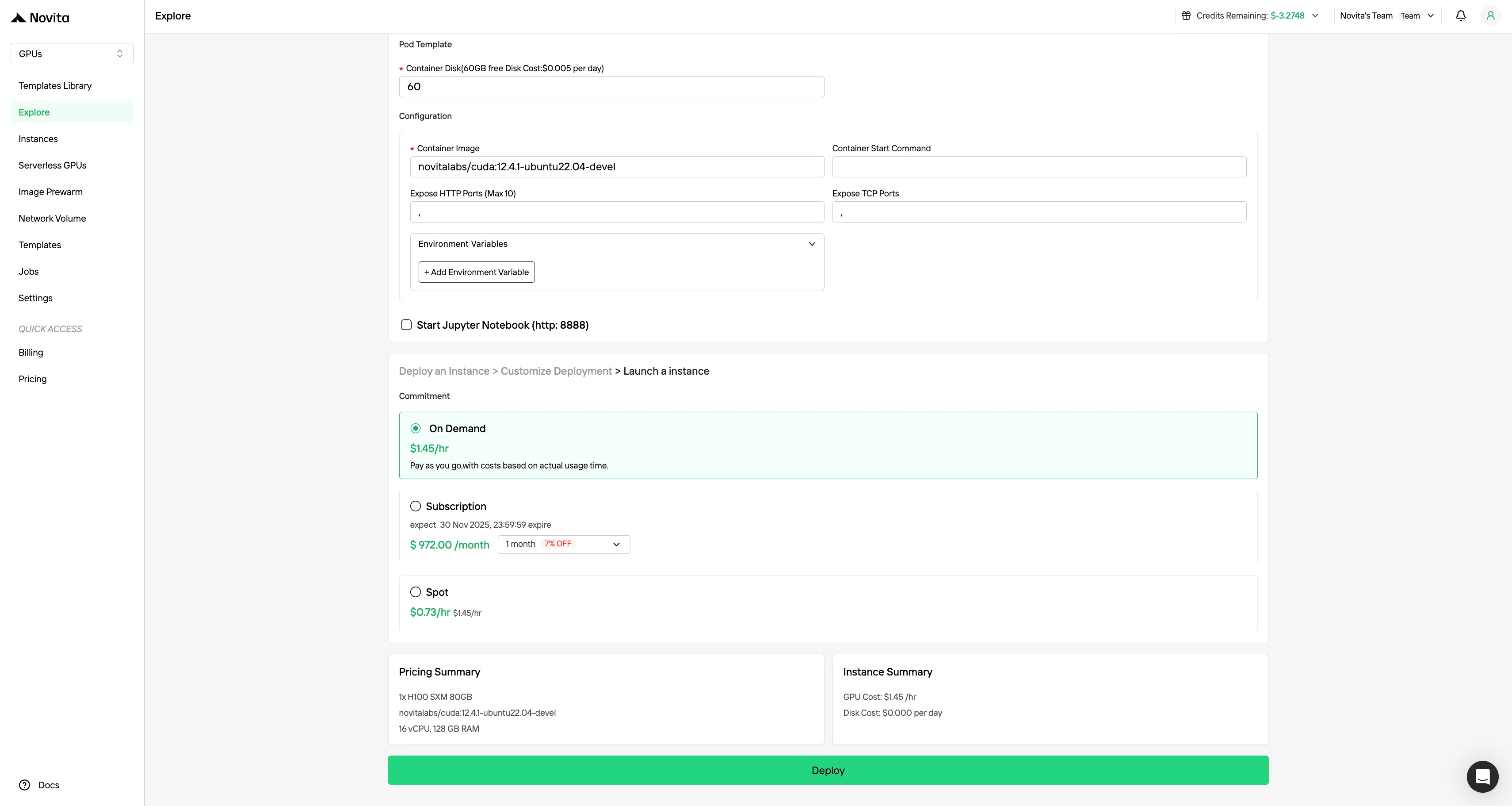
الخطوة 4: تشغيل مثيل مثيل**
اختر “تشغيل مثيل” لبدء النشر الخاص بك. ستكون بيئة GPU عالية الأداء جاهزة في غضون دقائق، مما يسمح لك بالبدء فورًا في مشاريع التعلم الآلي أو العرض الحاسوبي أو الحسابية الخاصة بك.
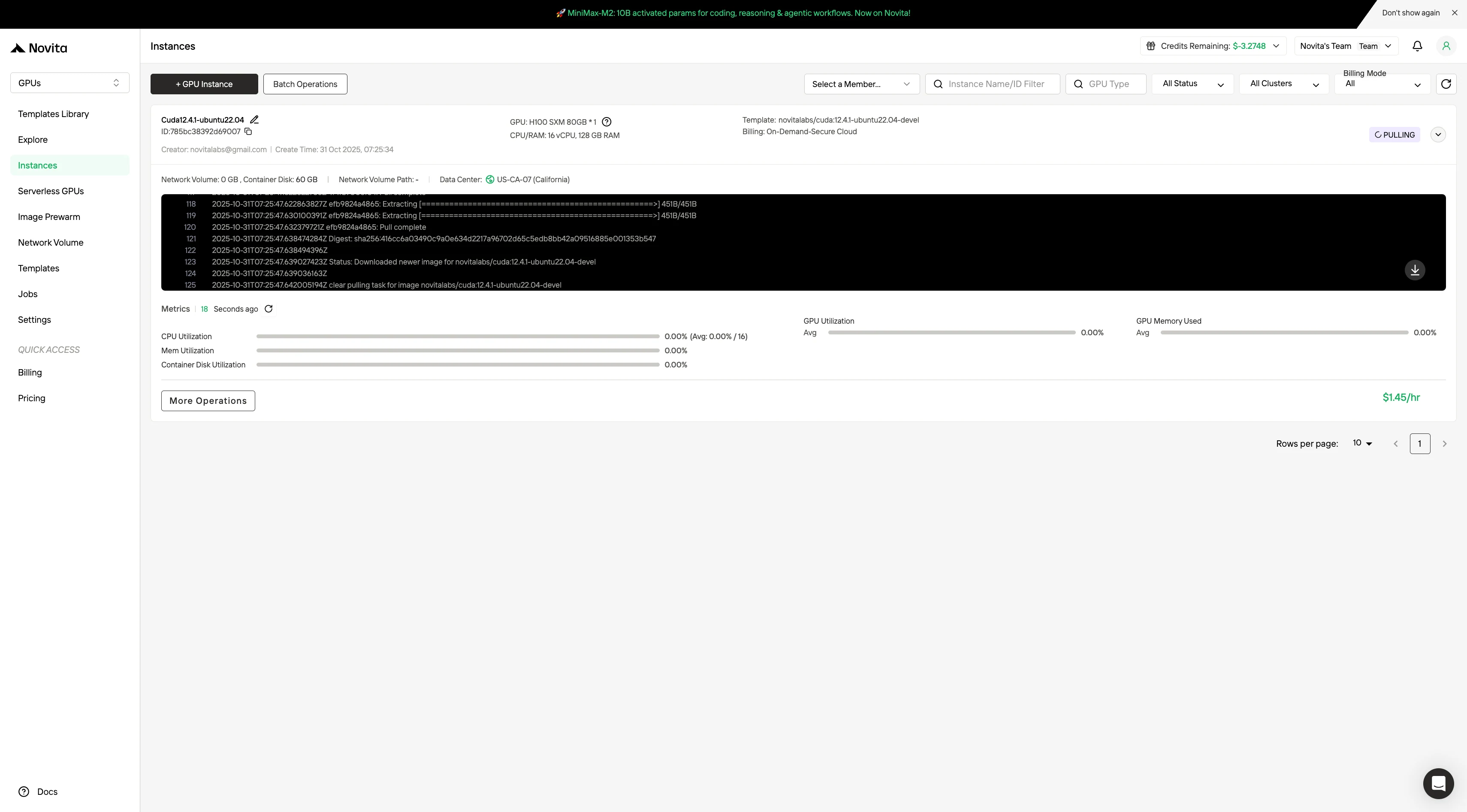
يعني اختيار وحدات GPU الموازنة بين الأداء والتكلفة والقابلية للتوسع المستقبلية.
- اختر A100 إذا كنت بحاجة إلى حساب موثوق وفعال من حيث التكلفة لنماذج لغة كبيرة متوسطة الحجم أو مهام متعددة المستأجرين.
- اختر H100 إذا كان هدفك هو تدريب نماذج لغة كبيرة على نطاق واسع، وخطوط أنابيب GPU متعددة، وإنتاجية من الفئة الأولى. يجعل النشر الفوري والتسعير المرن من Novita AI منصة قوية لكلا المسارين.
الخطوة التالية: طابق حجم النموذج والميزانية الخاصة بك مع GPU المناسب، ثم شغل مثيلًا على وحدات GPU من Novita AI للتحقق من مكاسب الأداء الخاصة بك.
الأسئلة الشائعة
هل هناك فوائد إضافية بخلاف التكلفة الساعية المنخفضة عند استخدام Novita AI?
نعم — تشمل الفوائد عقد GPU موزعة عالميًا للوصول منخفض الزمن، وأوضاع GPU بدون خوادم لقابلية التوسع بالدفع حسب الاستخدام، وAPI موحد لأكثر من 200 نموذج، وإدارة بنية تحتية مبسطة.
متى يجب أن أختار NVIDIA A100 بدلاً من H100؟
اختر A100 لأحمال العمل ذات حجم النموذج المعتدل (مثل ≤ 30 مليار معامل)، أو المستأجرين المشتركين، أو عندما تكون كفاءة التكلفة أهم من أقصى إنتاجية.
متى يصبح NVIDIA H100 الخيار الأفضل؟
اختر H100 عندما تدرب نماذج كبيرة جدًا (70 مليار معامل أو أكثر)، أو تستخدم إعدادات GPU متعددة أو عقد متعددة، أو تحتاج إلى أسرع إنتاجية للتدريب والاستدلال.
Novita AI هي منصة سحابة ذكاء اصطناعي توفر للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام API البسيط الخاص بنا، بالإضافة إلى توفير سحابة GPU بأسعار معقولة وموثوقة للبناء والتوسع.
قراءات موصى بها



