

AI development relies on rapid, on-demand GPU infrastructure. Novita AI delivers an instantly deployable GPU cloud that removes queueing and setup delays.
In real development workflows, teams can spin up NVIDIA A100 or H100 instances within minutes to fine-tune large models, run inference pipelines, or benchmark new architectures without waiting for shared cluster resources.
This immediate scalability helps developers iterate faster, control costs, and move from prototype to production with minimal friction.
Key Takeways
Instant deployment: GPU instances launch in under 30 seconds.
Affordable performance: A100/H100 GPUs at competitive hourly rates, with Spot instances up to 50 % cheaper.
Fit for purpose: A100 suits small/medium models and shared environments; H100 targets massive LLM training.
Why Choose A100/H100?

A100 vs H100: Technical Comparison
| Feature | A100 (Ampere architecture) | H100 (Hopper architecture) |
|---|---|---|
| Architecture Generation | Ampere – 3rd gen Tensor Cores. | Hopper – 4th gen Tensor Cores + Transformer Engine. |
| Memory Type & Bandwidth | 80 GB HBM2e memory 2 TB/s bandwidth. | 80 GB HBM3 memory 3.9 TB/s bandwidth. |
| MIG | A 100 allows a single GPU to be partitioned into up to seven isolated instances for multi-tenant or multi-model workloads. | H100 enhances with stronger isolation and improved QoS for multi-tenant inference. |
A100 vs H100: Benchmarks
| Category | A100 80GB SXM (Ampere) | H100 80GB SXM (Hopper) | Improvement (H100 vs A100) |
|---|---|---|---|
| Architecture | Ampere | Hopper | — |
| Memory | HBM2e | HBM3 | New generation |
| 80 GB | 80 GB | — | |
| 2.0 TB/s | 3.35 TB/s | +68% | |
| Interconnect | 600 GB/s + PCIe Gen4 64 GB/s | 900 GB/s + PCIe Gen5 128 GB/s | +50% NVLink speed |
| Power (TDP) | 400 W | Up to 700 W | +75% (configurable) |
| MIG Support | 7 × 10 GB | 7 × 10 GB | Same count, improved QoS |
| FP64 | 9.7 TFLOPS | 34 TFLOPS | +3.5× |
| FP64 Tensor Core | 19.5 TFLOPS | 67 TFLOPS | +3.4× |
| FP32 | 19.5 TFLOPS | 67 TFLOPS | +3.4× |
| TF32 Tensor Core | 156 / 312 TFLOPS (sparse) | 989 TFLOPS | +3.2× (dense) |
| BF16 Tensor Core | 312 / 624 TFLOPS (sparse) | 1,979 TFLOPS | +3.2× |
| FP16 Tensor Core | 312 / 624 TFLOPS (sparse) | 1,979 TFLOPS | +3.2× |
| FP8 Tensor Core | — | 3,958 TFLOPS | New precision mode |
| INT8 Tensor Core | 624 / 1,248 TOPS (sparse) | 3,958 TOPS | +3.2× |
The H100 SXM delivers a clear generational leap over the A100 SXM in both technical design and benchmark performance. Compute throughput roughly triples across all precisions, while memory and interconnect bandwidths also scale significantly.
The A100 remains more power-efficient and cost-effective for shared or mid-scale workloads, but the H100 is the superior choice for developers targeting maximum speed and scalability.
A100 vs H100: Recommended Use Cases
| Use Case | Recommended GPU | Why |
|---|---|---|
| Limited budget, models ≤ 30 B parameters, shared tenancy | A100 | Proven stability, strong cost efficiency, MIG support |
| Large-scale training (≥ 70 B parameters), multi-GPU nodes | H100 | Future-ready, top-tier speed and scalability |
Cost Comparison on Novita AI
Novita offers the lowest on-demand H100 pricing at $1.80/hr
up to 30% cheaper than other providers with identical GPU performance.
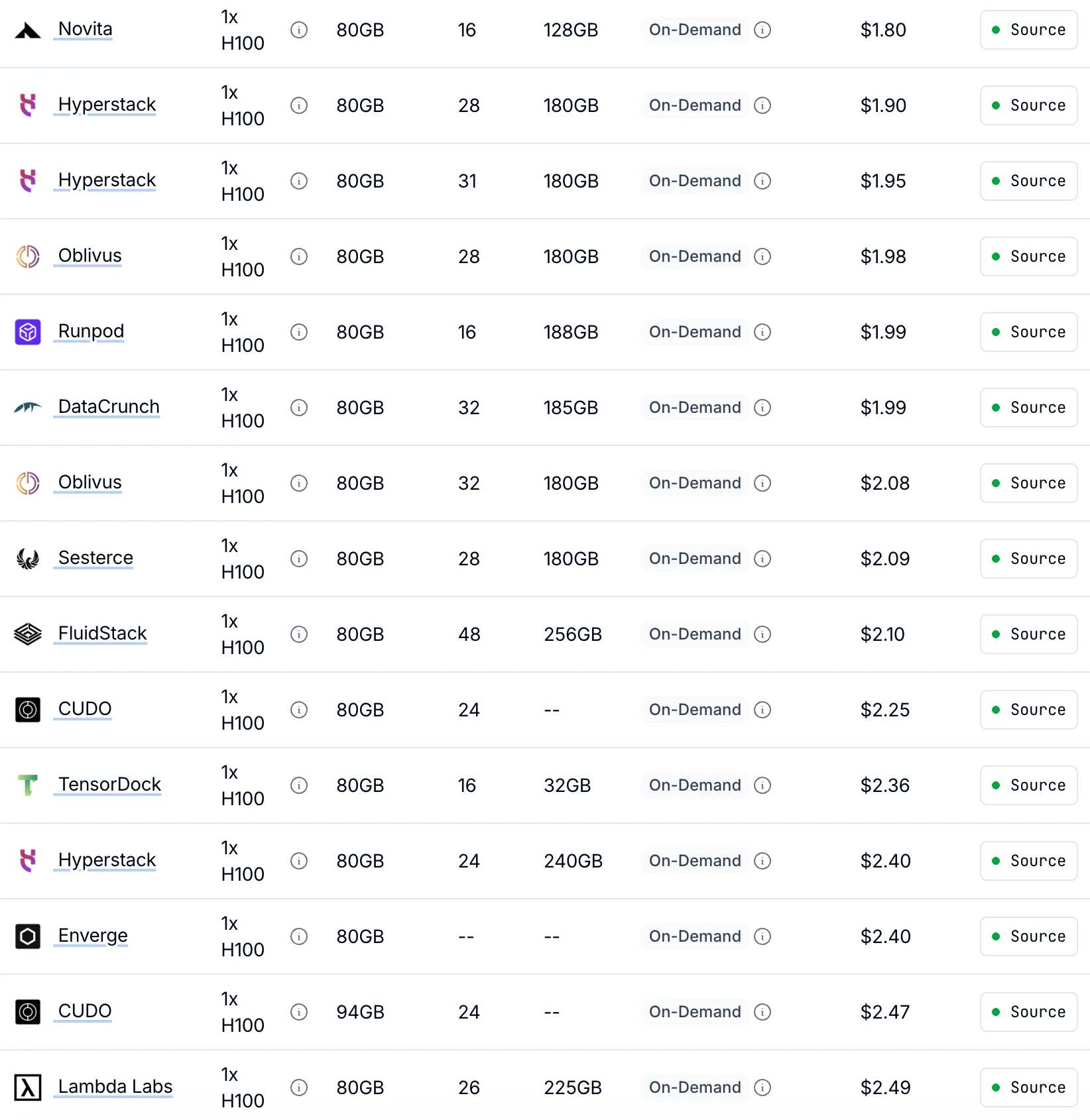
From Getdeploying
| GPU Type | Specification | Pricing Model | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB VRAM | On-Demand | $1.45/hr | $11.60/hr |
| Spot | $0.73/hr | $5.84/hr | ||
| A100 SXM 80GB | 80 GB VRAM | On-Demand | $1.60/hr | $12.80/hr |
| Spot | $0.80/hr | $6.40/hr |
Novita AI’s Spot mode is a cost-optimized GPU rental option that leverages the platform’s unused or idle GPU capacity. Unlike on-demand instances, which reserve dedicated hardware for guaranteed continuous use, Spot instances are interruptible—offered at significantly lower prices, typically 40–60% cheaper.
This pricing model works because Novita dynamically reallocates idle GPUs to short-term users instead of leaving them unused. By doing so, the platform improves overall infrastructure utilization efficiency, while developers benefit from much lower computational costs for flexible workloads.
Why Choose Novita AI For Renting Cheap A100 and H100
- Instant, global GPU access: GPU instances launch in seconds across global regions, enabling low-latency access and rapid experimentation.
- Serverless + GPU Cloud hybrid: Offers both full-GPU instances and serverless GPU modes (pay-as-you-go) for flexible workload types.
- Integrations & observability: Compatible with monitoring/tracing stacks (e.g., via Langfuse) and drop-in OpenAI-style API endpoints.
- Developer-centric cost optimisation: Apart from base price, features like spot instances (≈50 % savings) and fast spin-up reduce total cost of ownership.
How to Use A100 and H100 on Novita AI?
Step1:Register an account
Create your Novita AI account through our website. After registration, navigate to the “Explore” section in the left sidebar to view our GPU offerings and begin your AI development journey.

Step2:Exploring Templates and GPU Servers
Choose from templates like PyTorch, TensorFlow, or CUDA that match your project needs. Then select your preferred GPU configuration—options include the powerful L40S, RTX 4090 or A100 SXM4, each with different VRAM, RAM, and storage specifications.
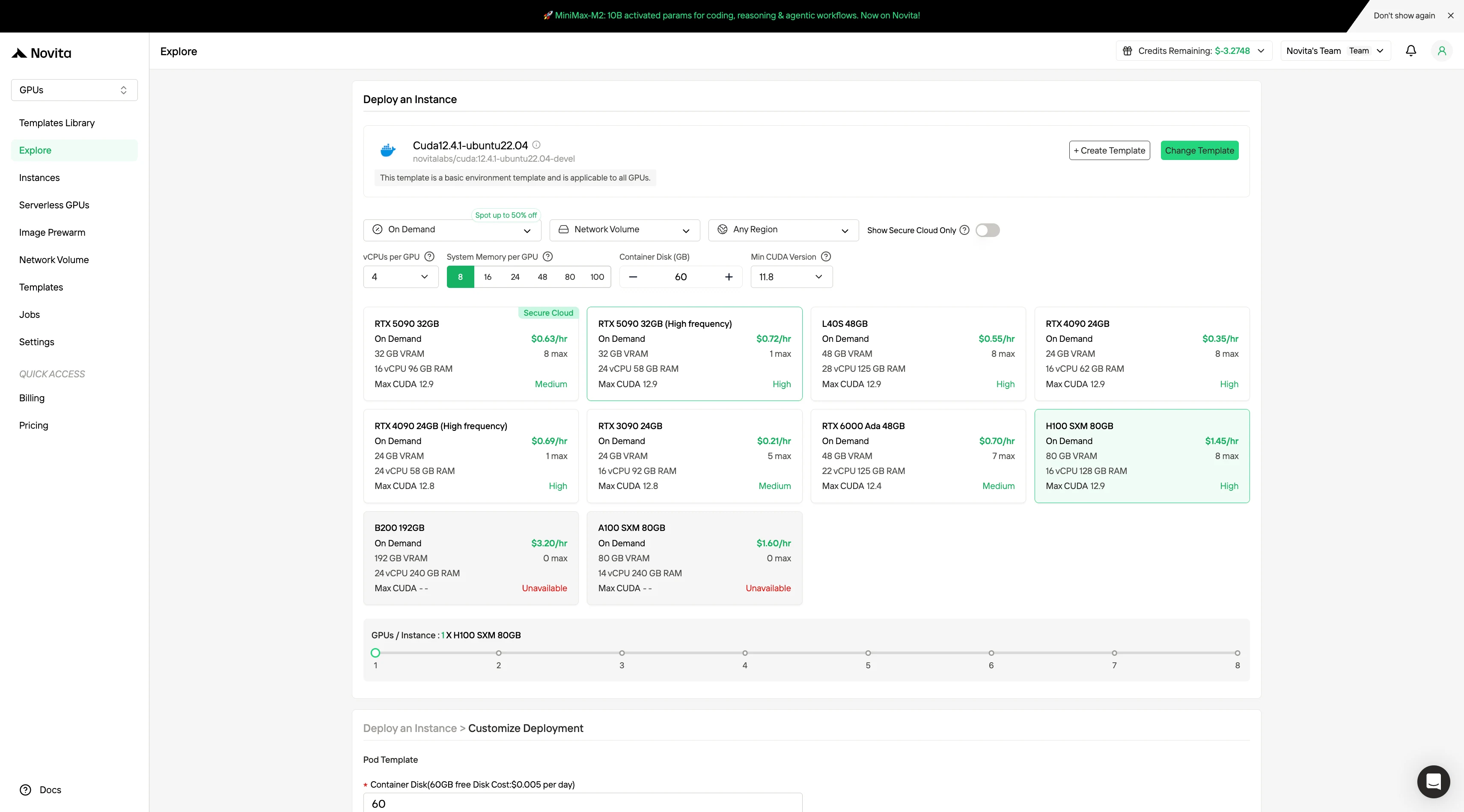
Step3:Tailor Your Deployment
Customize your environment by selecting your preferred operating system and configuration options to ensure optimal performance for your specific AI workloads and development needs.
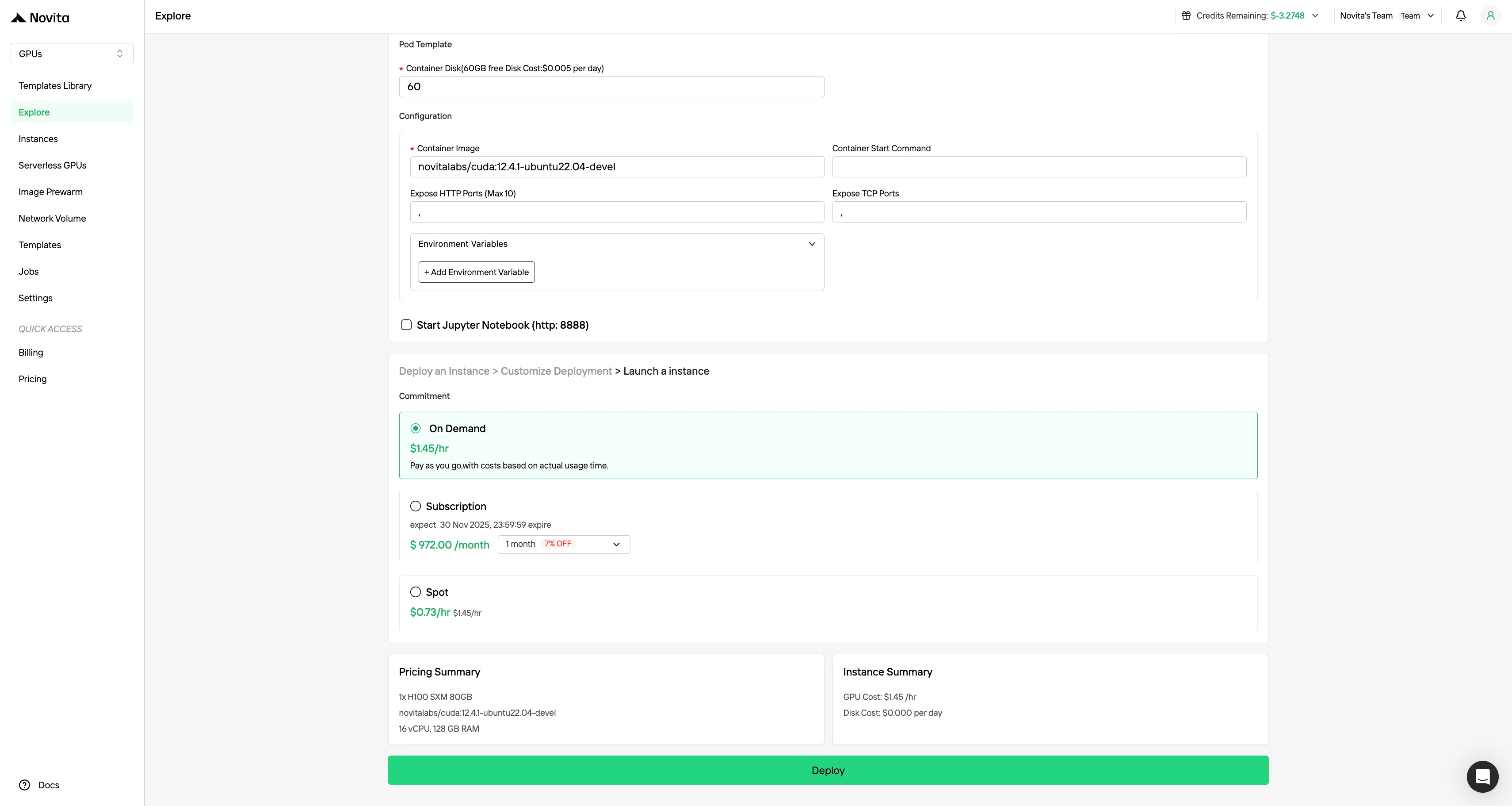
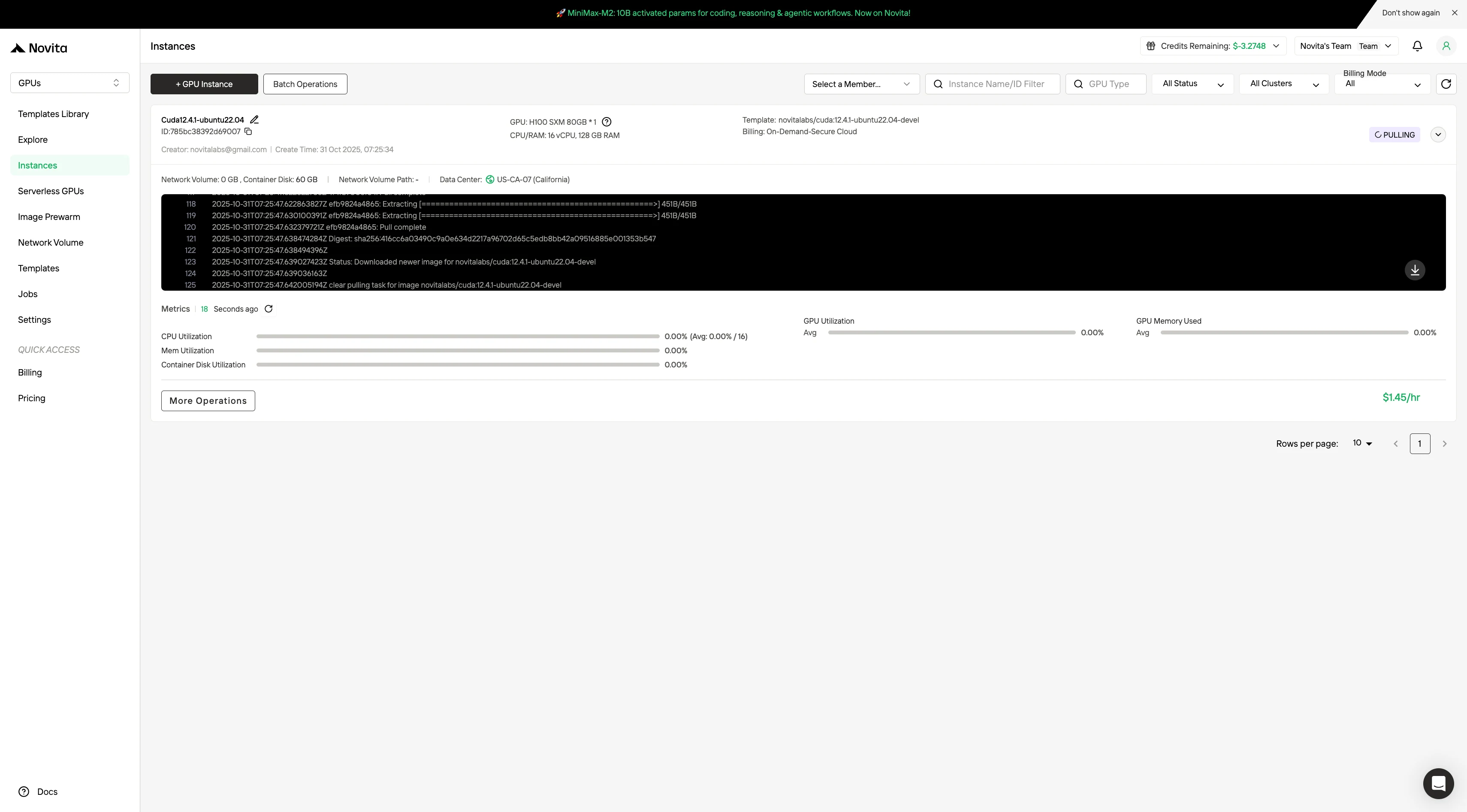
Step4:Launch an instance
Select “Launch Instance” to start your deployment. Your high-performance GPU environment will be ready within minutes, allowing you to immediately begin your machine learning, rendering, or computational projects.
Selecting GPUs means balancing performance, cost, and future scalability.
- Choose A100 if you need dependable, cost-efficient compute for mid-sized LLMs or multi-tenant tasks.
- Choose H100 if your goal is large-scale LLM training, multi-GPU pipelines, and cutting-edge throughput.
Novita AI’s instant deployment and flexible pricing make it a strong platform for both paths.
Next step: Match your model size and budget to the right GPU, then spin up an instance on Novita AI GPUs to validate your performance gains.
Frequently Asked Questions
Are there additional benefits beyond low hourly cost when using Novita AI?
Yes — benefits include globally distributed GPU nodes for low-latency access, serverless GPU modes for pay-as-you-go scalability, unified API for 200+ models, and simplified infrastructure management.
When should I choose the NVIDIA A100 over the H100?
Choose A100 for workloads with moderate model size (e.g., ≤30 B parameters), shared tenancy, or when cost-efficiency matters more than peak throughput.s better.
When does the NVIDIA H100 become the better choice?
Choose H100 when you train very large models (70 B+ parameters), use multi-GPU or multi-node setups, or require the fastest training and inference throughput.
Novita AI is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Recommended Reading



