

Разработка ИИ опирается на быструю инфраструктуру GPU по требованию. Novita AI предоставляет готовый к мгновенному развертыванию облачный сервис GPU, который исключает очереди и задержки при настройке.
В реальных рабочих процессах разработки команды могут запускать экземпляры NVIDIA A100 или H100 в течение нескольких минут для тонкой настройки крупных моделей, запуска конвейеров вывода или бенчмаркинга новых архитектур, не дожидаясь доступа к общим ресурсам кластера.
Такая мгновенная масштабируемость помогает разработчикам быстрее итерировать, контролировать расходы и переходить от прототипа к продакшену с минимальными трудностями.
Ключевые преимущества
Мгновенное развертывание: Экземпляры GPU запускаются менее чем за 30 секунд.
Доступная производительность: GPU A100/H100 по конкурентоспособным почасовым тарифам, Spot-инстансы до 50 % дешевле.
Подходит под задачи: A100 подходит для небольших/средних моделей и общих сред; H100 предназначен для массового обучения LLM.
Почему стоит выбрать A100/H100?

A100 против H100: Техническое сравнение
| Характеристика | A100 (архитектура Ampere) | H100 (архитектура Hopper) |
|---|---|---|
| Поколение архитектуры | Ampere — тензорные ядра 3-го поколения. | Hopper — тензорные ядра 4-го поколения + Transformer Engine. |
| Тип памяти и пропускная способность | 80 ГБ памяти HBM2e Пропускная способность 2 ТБ/с. |
80 ГБ памяти HBM3 Пропускная способность 3,9 ТБ/с. |
| MIG | A100 позволяет разделить один GPU на до семи изолированных экземпляров для многопользовательских или многомодельных рабочих нагрузок. | H100 улучшает за счет более сильной изоляции и улучшенного QoS для многопользовательского вывода. |
A100 против H100: Бенчмарки
| Категория | A100 80GB SXM (Ampere) | H100 80GB SXM (Hopper) | Улучшение (H100 по сравнению с A100) |
|---|---|---|---|
| Архитектура | Ampere | Hopper | — |
| Память | HBM2e | HBM3 | Новое поколение |
| 80 ГБ | 80 ГБ | — | |
| 2,0 ТБ/с | 3,35 ТБ/с | +68% | |
| Интерфейс | 600 ГБ/с + PCIe Gen4 64 ГБ/с | 900 ГБ/с + PCIe Gen5 128 ГБ/с | +50% скорости NVLink |
| Потребляемая мощность (TDP) | 400 Вт | До 700 Вт | +75% (настраиваемое) |
| Поддержка MIG | 7 × 10 ГБ | 7 × 10 ГБ | Одинаковое количество, улучшенный QoS |
| FP64 | 9,7 TFLOPS | 34 TFLOPS | +3,5× |
| Тензорные ядра FP64 | 19,5 TFLOPS | 67 TFLOPS | +3,4× |
| FP32 | 19,5 TFLOPS | 67 TFLOPS | +3,4× |
| Тензорные ядра TF32 | 156 / 312 TFLOPS (разреженный) | 989 TFLOPS | +3,2× (плотный) |
| Тензорные ядра BF16 | 312 / 624 TFLOPS (разреженный) | 1 979 TFLOPS | +3,2× |
| Тензорные ядра FP16 | 312 / 624 TFLOPS (разреженный) | 1 979 TFLOPS | +3,2× |
| Тензорные ядра FP8 | — | 3 958 TFLOPS | Новый режим точности |
| Тензорные ядра INT8 | 624 / 1 248 TOPS (разреженный) | 3 958 TOPS | +3,2× |
H100 SXM представляет собой явный скачок поколений по сравнению с A100 SXM как в техническом проектировании, так и в производительности по бенчмаркам. Пропускная способность вычислений примерно утраивается для всех режимов точности, а пропускная способность памяти и интерфейсов также значительно увеличивается.
A100 остается более энергоэффективным и экономически выгодным для общих или средних по масштабу рабочих нагрузок, но H100 является лучшим выбором для разработчиков, ориентированных на максимальную скорость и масштабируемость.
A100 против H100: Рекомендуемые сценарии использования
| Сценарий использования | Рекомендуемый GPU | Почему |
|---|---|---|
| Ограниченный бюджет, модели ≤ 30 млрд параметров, общий доступ | A100 | Проверенная стабильность, высокая экономическая эффективность, поддержка MIG |
| Крупномасштабное обучение (≥ 70 млрд параметров), многопроцессорные узлы | H100 | Готов к будущим задачам, высочайшая скорость и масштабируемость |
Сравнение стоимости на Novita AI
Novita предлагает самые низкие тарифы на H100 по требованию от $1,80 в час
что на 30 % дешевле, чем у других провайдеров с идентичной производительностью GPU.
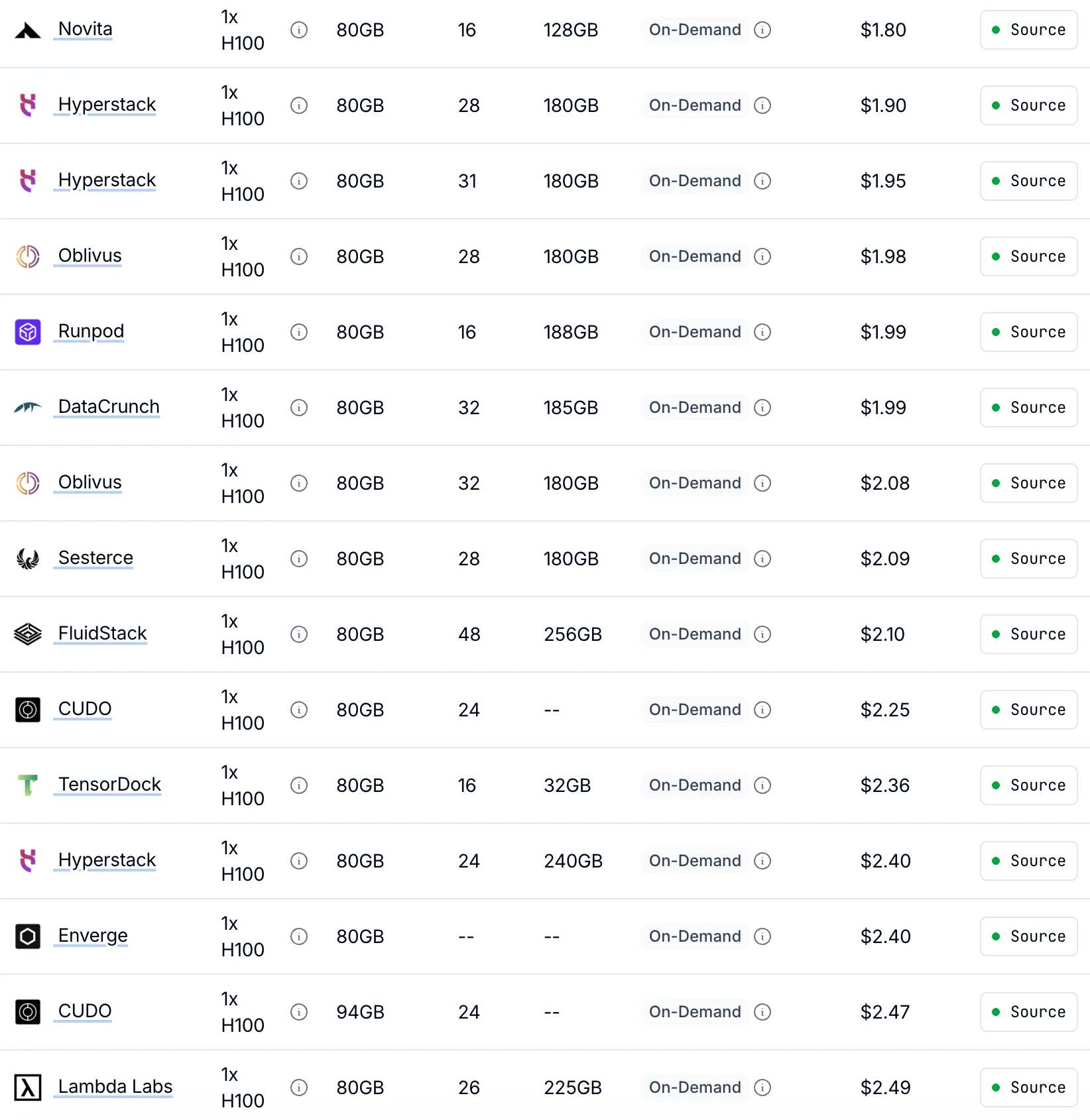
Источник: Getdeploying
| Тип GPU | Спецификация | Модель тарификации | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 ГБ VRAM | По требованию | $1,45 в час | $11,60 в час |
| Spot | $0,73 в час | $5,84 в час | ||
| A100 SXM 80GB | 80 ГБ VRAM | По требованию | $1,60 в час | $12,80 в час |
| Spot | $0,80 в час | $6,40 в час |
Spot-режим Novita AI — это оптимизированный по стоимости вариант аренды GPU, который использует неиспользуемую или простаивающую мощность GPU платформы. В отличие от инстансов по требованию, которые резервируют выделенное оборудование для гарантированного непрерывного использования, Spot-инстансы являются прерываемыми — они предлагаются по значительно более низким ценам, обычно на 40–60% дешевле.
Эта модель тарификации работает, потому что Novita динамически перераспределяет простаивающие GPU для краткосрочных пользователей вместо того, чтобы оставлять их неиспользуемыми. Благодаря этому платформа повышает общую эффективность использования инфраструктуры, а разработчики получают значительно более низкие вычислительные расходы для гибких рабочих нагрузок.
Почему стоит выбрать Novita AI для аренды недорогих A100 и H100
- Мгновенный глобальный доступ к GPU: Инстансы GPU запускаются за секунды в глобальных регионах, что обеспечивает доступ с низкой задержкой и быстрое тестирование гипотез.
- Гибрид Serverless + облако GPU: Предлагает как полноценные инстансы GPU, так и бессерверные режимы GPU (оплата по факту использования) для гибких типов рабочих нагрузок.
- Интеграции и наблюдаемость: Совместим со стеками мониторинга/трейсинга (например, через Langfuse) и готовыми API-эндпоинтами в стиле OpenAI.
- Оптимизация стоимости с фокусом на разработчиков: Помимо базовой цены, такие функции, как Spot-инстансы (≈50% экономия) и быстрый запуск, снижают общую стоимость владения.
Как использовать A100 и H100 на Novita AI?
Шаг 1: Зарегистрируйте аккаунт
Создайте аккаунт Novita AI на нашем сайте. После регистрации перейдите в раздел «Explore» в левой боковой панели, чтобы ознакомиться с нашими предложениями GPU и начать свой путь в разработке ИИ.

Шаг 2: Изучение шаблонов и GPU-серверов**
Выбирайте из шаблонов, таких как PyTorch, TensorFlow или CUDA, которые соответствуют потребностям вашего проекта. Затем выберите предпочитаемую конфигурацию GPU — доступны варианты с мощными L40S, RTX 4090 или A100 SXM4, каждый с разными характеристиками видеопамяти, оперативной памяти и хранилища.
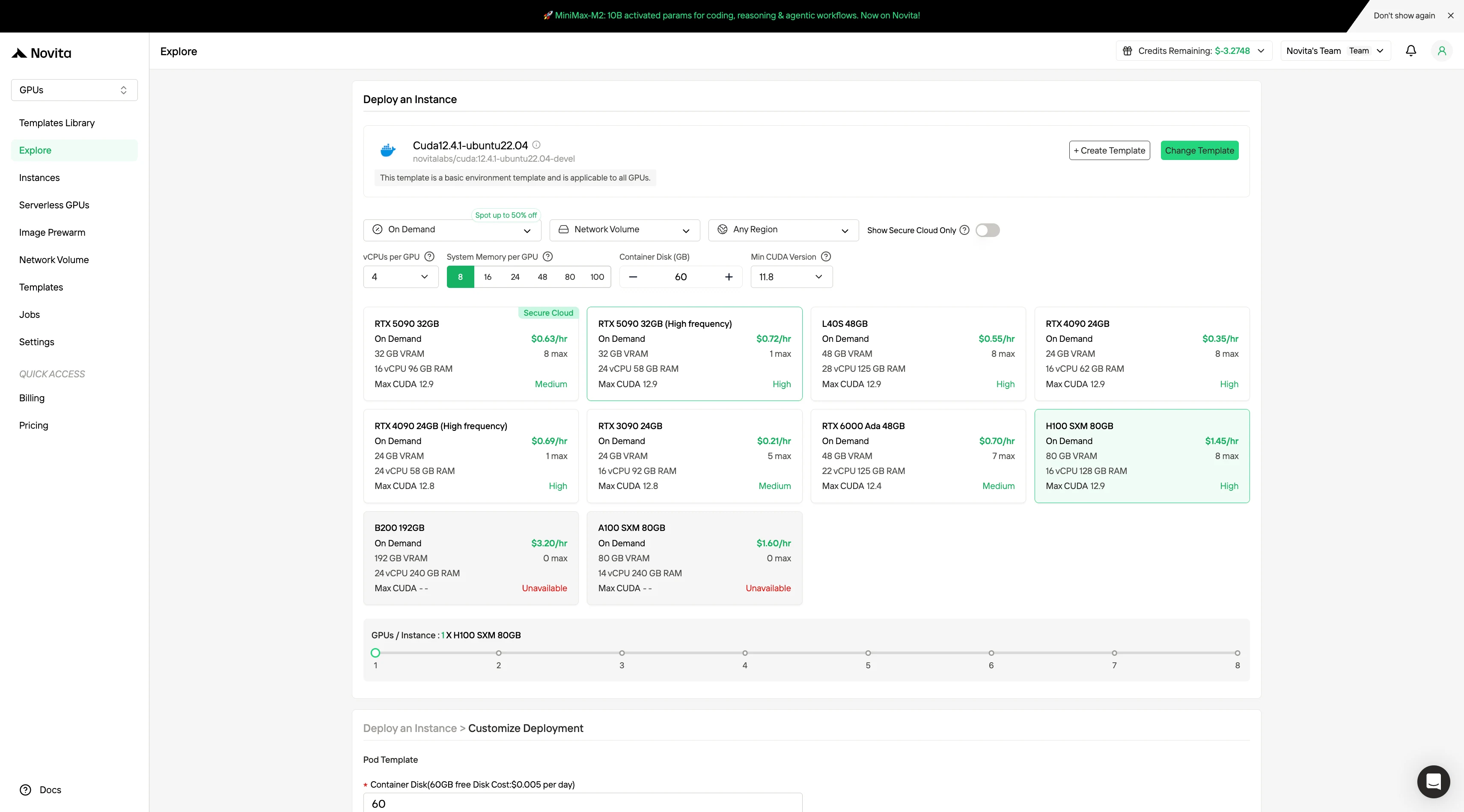
Шаг 3: Настройте развертывание
Настройте окружение, выбрав предпочитаемую операционную систему и параметры конфигурации, чтобы обеспечить оптимальную производительность для ваших конкретных рабочих нагрузок ИИ и потребностей разработки.
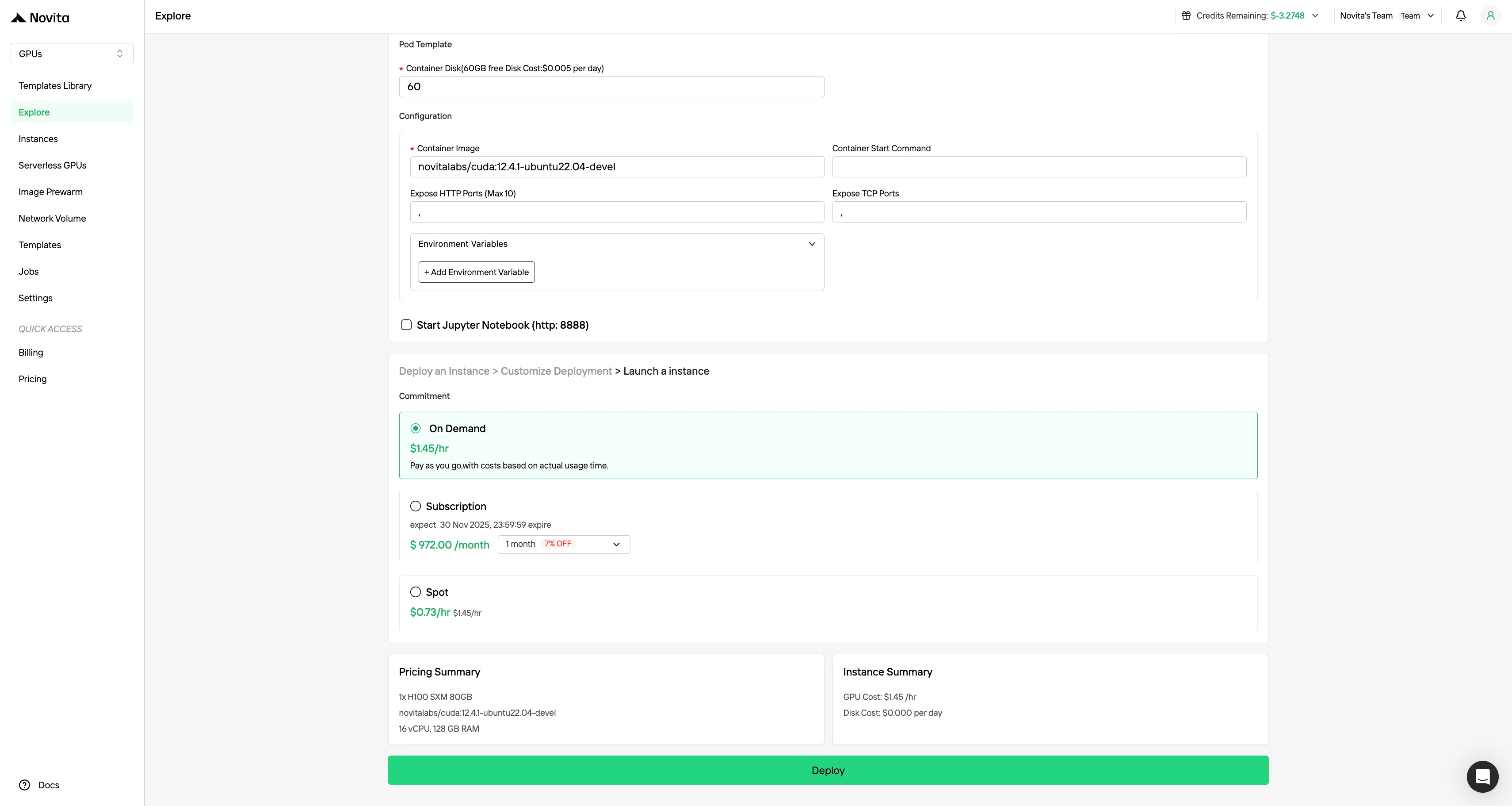
Шаг 4: Запустите инстанс**
Выберите «Launch Instance», чтобы начать развертывание. Ваше высокопроизводительное окружение GPU будет готово в течение нескольких минут, что позволит вам немедленно приступить к проектам в области машинного обучения, рендеринга или вычислительных задач.
Выбор GPU означает баланс между производительностью, стоимостью и будущей масштабируемостью.
- Выберите A100, если вам нужна надежная, экономически эффективная вычислительная мощность для LLM среднего размера или многопользовательских задач.
- Выберите H100, если ваша цель — крупномасштабное обучение LLM, многопроцессорные конвейеры и передовая пропускная способность.
Мгновенное развертывание и гибкое тарификация Novita AI делают платформу сильным выбором для обоих сценариев.
Следующий шаг: Соотнесите размер вашей модели и бюджет с подходящим GPU, затем запустите инстанс на странице GPU Novita AI, чтобы проверить прирост производительности.
Часто задаваемые вопросы
Есть ли дополнительные преимущества, помимо низкой почасовой стоимости, при использовании Novita AI?
Да — преимущества включают глобально распределенные узлы GPU для доступа с низкой задержкой, бессерверные режимы GPU для масштабирования по факту использования, единый API для более чем 200 моделей и упрощенное управление инфраструктурой.
Когда стоит выбирать NVIDIA A100 вместо H100?
Выбирайте A100 для рабочих нагрузок с умеренным размером модели (например, ≤30 млрд параметров), общим доступом или в случаях, когда экономическая эффективность важнее пиковой пропускной способности.
Когда NVIDIA H100 становится лучшим выбором?
Выбирайте H100, когда вы обучаете очень крупные модели (70+ млрд параметров), используете многопроцессорные или многоузловые конфигурации или требуете самую быструю пропускную способность обучения и вывода.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развертывать модели ИИ с использованием нашего простого API, а также предоставляет доступное и надежное облако GPU для построения и масштабирования решений.
Рекомендуемые материалы



