

AI開発は、迅速かつオンデマンドなGPUインフラに依存しています。Novita AIは、待ち時間やセットアップの遅延を排除した、即座にデプロイ可能なGPUクラウドを提供します。
実際の開発ワークフローでは、チームはNVIDIA A100またはH100インスタンスを数分以内に起動し、大規模モデルのファインチューニング、推論パイプラインの実行、新しいアーキテクチャのベンチマークを、共有クラスタリソースを待つことなく行えます。
この即時のスケーラビリティにより、開発者はより迅速にイテレーションを行い、コストを制御し、プロトタイプから本番環境への移行を最小限の摩擦で実現できます。
主なポイント
即時デプロイ: GPUインスタンスが30秒以内に起動。
手頃なパフォーマンス: 競争力のある時間料金のA100/H100 GPU、スポットインスタンスで最大50%割引。
目的に応じて選択: A100は中小規模モデルや共有環境に最適。H100は大規模LLMトレーニングに最適。
A100/H100を選ぶ理由

A100 vs H100:技術比較
| 機能 | A100(Ampereアーキテクチャ) | H100(Hopperアーキテクチャ) |
|---|---|---|
| アーキテクチャ世代 | Ampere – 第3世代Tensorコア | Hopper – 第4世代Tensorコア + Transformer Engine |
| メモリタイプと帯域幅 | 80 GB HBM2eメモリ 2 TB/s帯域幅 |
80 GB HBM3メモリ 3.9 TB/s帯域幅 |
| MIG | A100は1つのGPUを最大7つの独立したインスタンスに分割可能。マルチテナントまたはマルチモデルワークロード向け。 | H100は、マルチテナント推論においてより強力な分離と改善されたQoSを強化。 |
A100 vs H100:ベンチマーク
| カテゴリ | A100 80GB SXM (Ampere) | H100 80GB SXM (Hopper) | 改善率(H100 vs A100) |
|---|---|---|---|
| アーキテクチャ | Ampere | Hopper | — |
| メモリ | HBM2e | HBM3 | 新世代 |
| 80 GB | 80 GB | — | |
| 2.0 TB/s | 3.35 TB/s | +68% | |
| インターコネクト | 600 GB/s + PCIe Gen4 64 GB/s | 900 GB/s + PCIe Gen5 128 GB/s | +50% NVLink速度 |
| 消費電力(TDP) | 400 W | 最大700 W | +75%(設定可能) |
| MIGサポート | 7 × 10 GB | 7 × 10 GB | 同じ数、改善されたQoS |
| FP64 | 9.7 TFLOPS | 34 TFLOPS | +3.5倍 |
| FP64 Tensor Core | 19.5 TFLOPS | 67 TFLOPS | +3.4倍 |
| FP32 | 19.5 TFLOPS | 67 TFLOPS | +3.4倍 |
| TF32 Tensor Core | 156 / 312 TFLOPS(スパース) | 989 TFLOPS | +3.2倍(密) |
| BF16 Tensor Core | 312 / 624 TFLOPS(スパース) | 1,979 TFLOPS | +3.2倍 |
| FP16 Tensor Core | 312 / 624 TFLOPS(スパース) | 1,979 TFLOPS | +3.2倍 |
| FP8 Tensor Core | — | 3,958 TFLOPS | 新しい精度モード |
| INT8 Tensor Core | 624 / 1,248 TOPS(スパース) | 3,958 TOPS | +3.2倍 |
H100 SXMは、技術設計とベンチマークパフォーマンスの両方において、A100 SXMを明確に凌駕しています。すべての精度で計算スループットが約3倍になり、メモリおよびインターコネクト帯域幅も大幅に向上しています。
A100は、共有または中規模のワークロードにおいて電力効率とコスト効率に優れていますが、最大の速度とスケーラビリティを追求する開発者にはH100が最適な選択肢です。
A100 vs H100:推奨ユースケース
| ユースケース | 推奨GPU | 理由 |
|---|---|---|
| 限られた予算、30Bパラメータ以下のモデル、共有テナンシー | A100 | 実績のある安定性、高いコスト効率、MIGサポート |
| 大規模トレーニング(70Bパラメータ以上)、マルチGPUノード | H100 | 将来性、トップクラスの速度とスケーラビリティ |
Novita AIでのコスト比較
Novitaは、同一のGPUパフォーマンスを提供する他社よりも最大30%安い、オンデマンドH100料金を1時間あたり1.80ドルで提供しています。
競合他社と比較して、同一のGPUパフォーマンスで最大30%安くなっています。
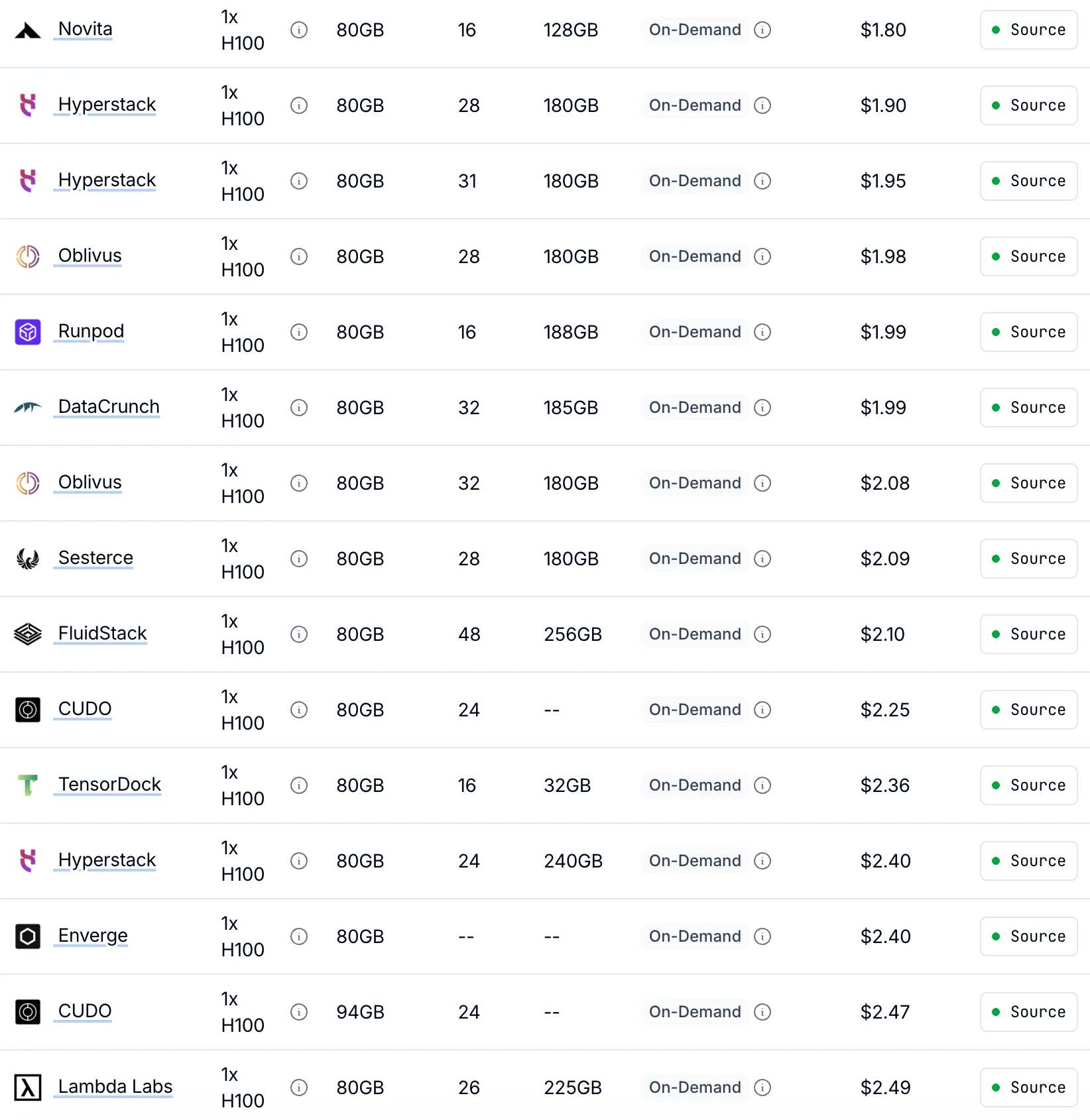
| GPUタイプ | 仕様 | 料金モデル | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB VRAM | オンデマンド | $1.45/時間 | $11.60/時間 |
| スポット | $0.73/時間 | $5.84/時間 | ||
| A100 SXM 80GB | 80 GB VRAM | オンデマンド | $1.60/時間 | $12.80/時間 |
| スポット | $0.80/時間 | $6.40/時間 |
Novita AIの スポットモード は、プラットフォームの未使用またはアイドル状態のGPUキャパシティを活用する、コスト最適化されたGPUレンタルオプションです。専用ハードウェアを予約して継続使用を保証するオンデマンドインスタンスとは異なり、スポットインスタンスは 中断可能 であり、大幅に低い価格(通常 40〜60%割引)で提供されます。
この料金モデルが機能するのは、Novitaがアイドル状態のGPUを未使用のままにするのではなく、短期ユーザーに動的に再割り当てするためです。これにより、プラットフォーム全体の インフラストラクチャ利用効率 が向上し、開発者は柔軟なワークロードに対して 大幅に低い計算コスト の恩恵を受けられます。
安価なA100とH100をレンタルするならNovita AIを選ぶ理由
- 即時かつグローバルなGPUアクセス:世界中のリージョンでGPUインスタンスを数秒で起動。低レイテンシアクセスと迅速な実験を実現。
- サーバーレス + GPUクラウドのハイブリッド:フルGPUインスタンスとサーバーレスGPUモード(従量課金制)の両方を提供し、柔軟なワークロードに対応。
- 統合と可観測性:モニタリング/トレーシングスタック(例:Langfuse経由)との互換性、およびドロップインでOpenAIスタイルのAPIエンドポイントを提供。
- 開発者中心のコスト最適化:基本価格に加え、スポットインスタンス(約50%節約)や高速スピンアップなどの機能により、総所有コストを削減。
Novita AIでA100とH100を使用する方法
ステップ1:アカウント登録
ウェブサイトからNovita AIアカウントを作成します。登録後、左サイドバーの「Explore」セクションに移動してGPUオファリングを確認し、AI開発の旅を始めましょう。

ステップ2:テンプレートとGPUサーバーの探索
プロジェクトのニーズに合ったPyTorch、TensorFlow、CUDAなどのテンプレートを選択します。次に、希望するGPU構成を選択します。オプションには、強力なL40S、RTX 4090、A100 SXM4などがあり、それぞれ異なるVRAM、RAM、ストレージ仕様があります。
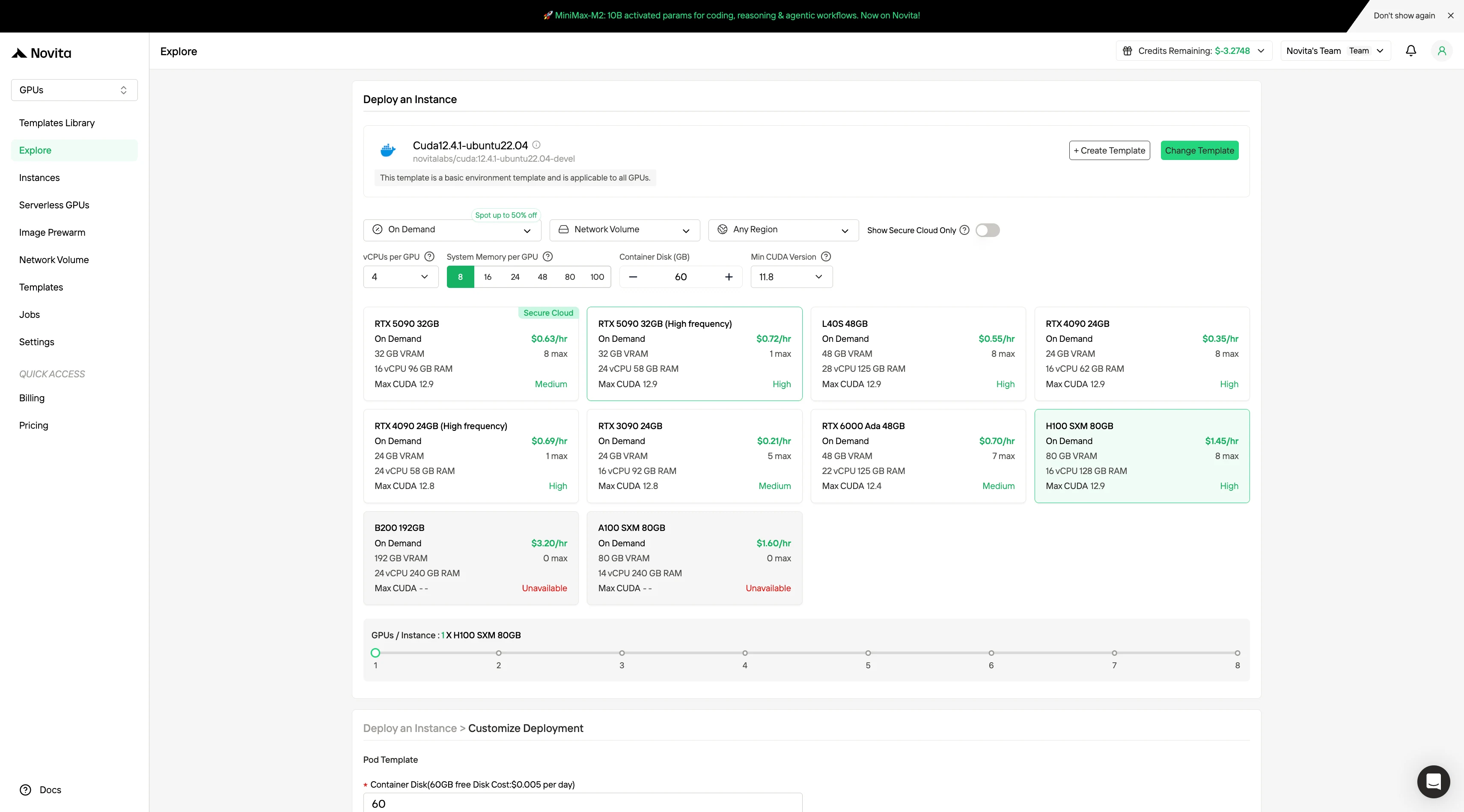
ステップ3:デプロイのカスタマイズ
好みのオペレーティングシステムと構成オプションを選択して環境をカスタマイズし、特定のAIワークロードと開発ニーズに対して最適なパフォーマンスを確保します。
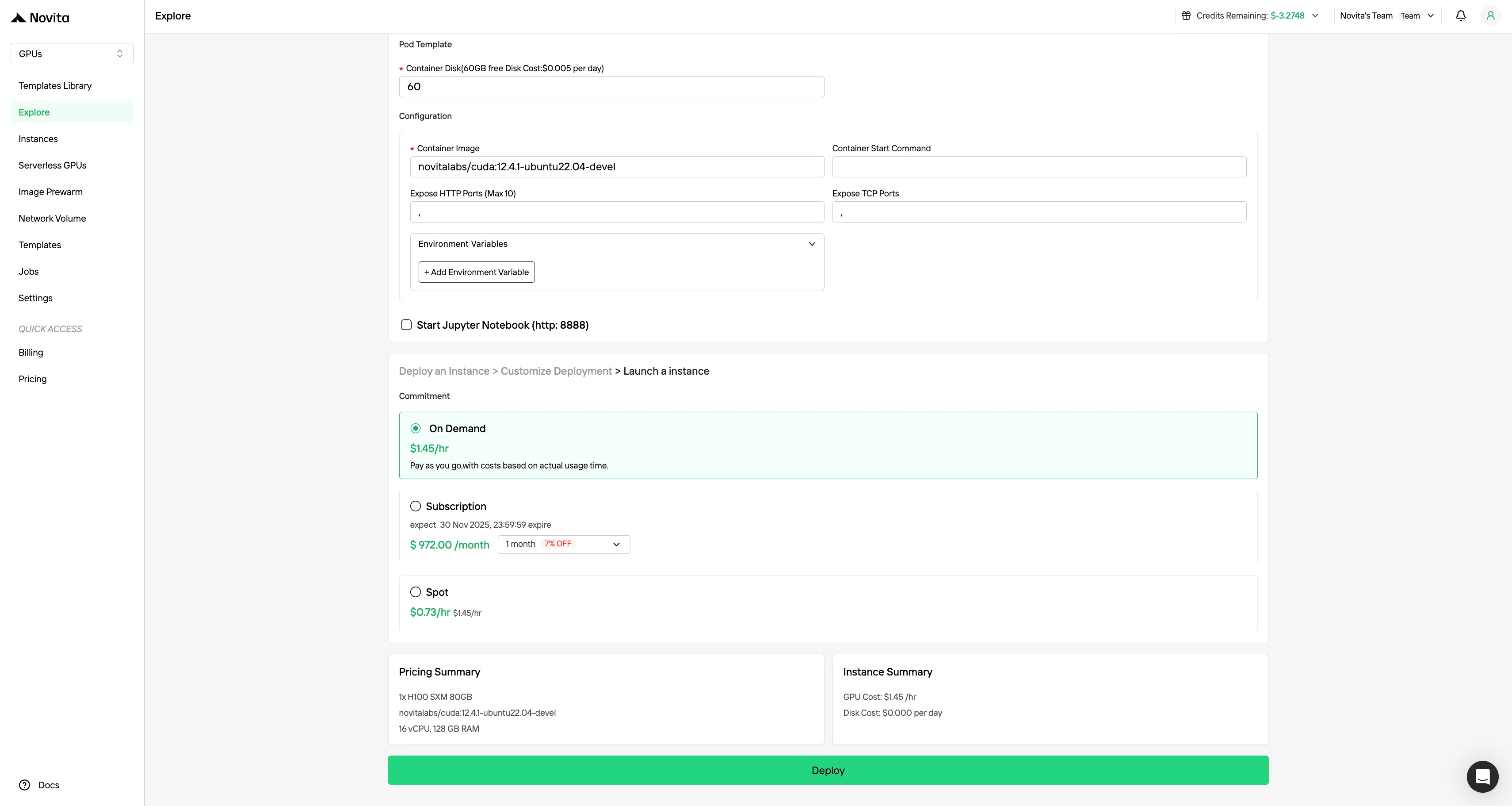
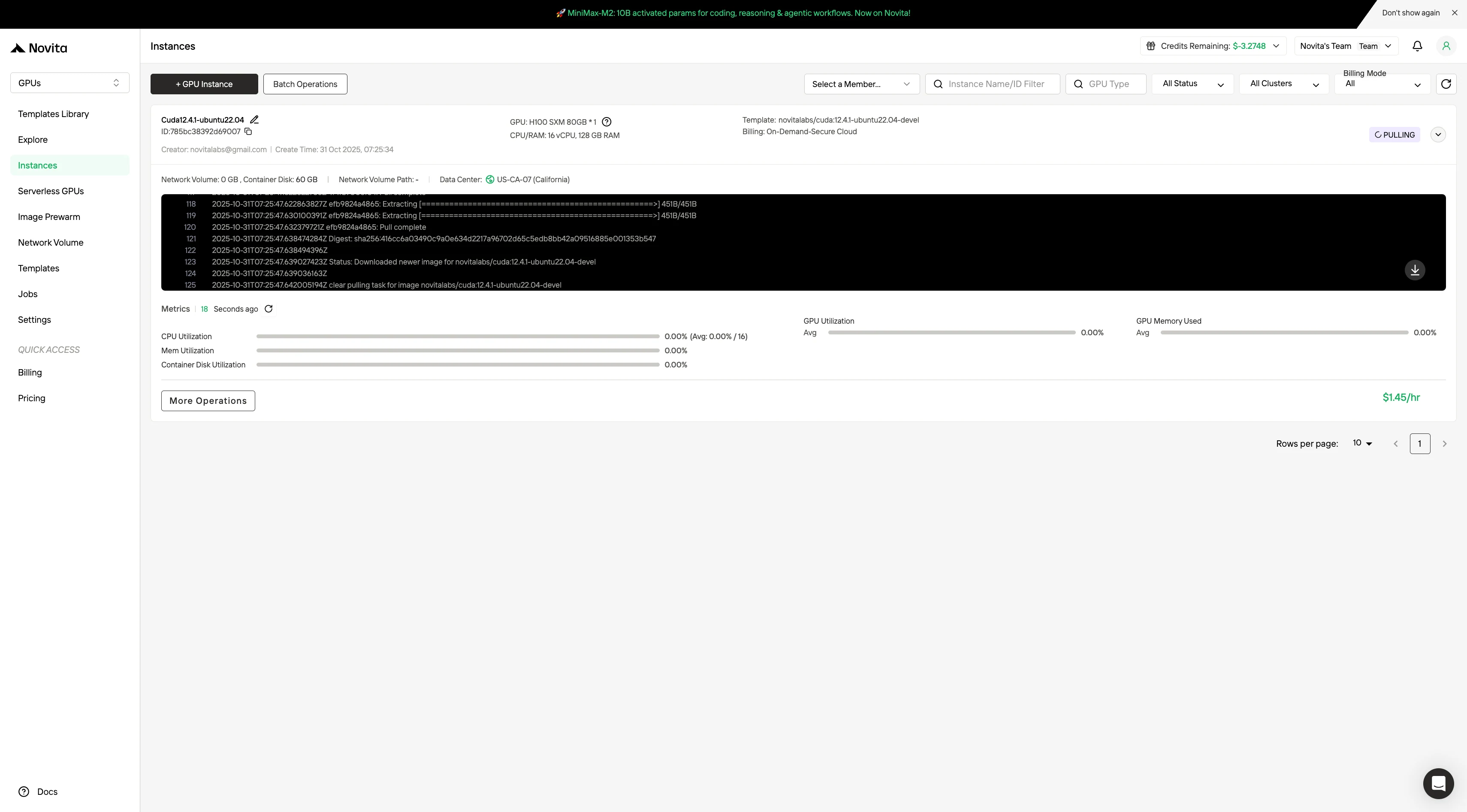
ステップ4:インスタンスの起動
「Launch Instance」を選択してデプロイを開始します。高性能GPU環境が数分以内に準備完了し、すぐに機械学習、レンダリング、または計算プロジェクトを開始できます。
GPUを選択するということは、パフォーマンス、コスト、将来のスケーラビリティのバランスを意味します。
- A100を選ぶ:中規模LLMやマルチテナントタスクに信頼性が高くコスト効率の良い計算が必要な場合。
- H100を選ぶ:大規模LLMトレーニング、マルチGPUパイプライン、最先端のスループットを目指す場合。 Novita AIの即時デプロイと柔軟な料金設定は、両方の道筋において強力なプラットフォームです。
次のステップ: モデルサイズと予算に合ったGPUを選択し、Novita AI GPUs でインスタンスを起動してパフォーマンス向上を検証しましょう。
よくある質問
低い時間料金以外に、Novita AI を使用する追加のメリットはありますか?
はい。メリットには、低レイテンシアクセスのためのグローバルに分散されたGPUノード、従量課金制スケーラビリティのためのサーバーレスGPUモード、200以上のモデルに対応する統一API、簡素化されたインフラ管理が含まれます。
NVIDIA H100よりもA100を選ぶべきなのはどのような場合ですか?
モデルサイズが中程度(例:30Bパラメータ以下)のワークロード、共有テナンシー、または最大スループットよりもコスト効率が重要な場合にA100を選択してください。
NVIDIA H100がより良い選択となるのはどのような場合ですか?
非常に大規模なモデル(70Bパラメータ以上)をトレーニングする場合、マルチGPUまたはマルチノードセットアップを使用する場合、または最速のトレーニングおよび推論スループットが必要な場合にH100を選択してください。
Novita AI は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、構築とスケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。
おすすめの記事



