

AI 开发依赖于快速、按需的 GPU 基础设施。Novita AI 提供即时部署的 GPU 云,消除了排队和设置延迟。
在实际开发工作流中,团队可以在几分钟内启动 NVIDIA A100 或 H100 实例,用于微调大型模型、运行推理管道或测试新架构,无需等待共享集群资源。
这种即时可扩展性帮助开发者更快迭代、控制成本,并以最小摩擦从原型过渡到生产。
关键要点
即时部署: GPU 实例在 30 秒内启动。
经济实惠的性能: A100/H100 GPU 具有竞争力的按小时费率,竞价实例最高可节省 50%。
按需选择: A100 适合中小型模型和共享环境;H100 面向大规模 LLM 训练。
为什么选择 A100/H100?

A100 vs H100:技术对比
| 特性 | A100(Ampere 架构) | H100(Hopper 架构) |
|---|---|---|
| 架构代际 | Ampere – 第 3 代 Tensor Core | Hopper – 第 4 代 Tensor Core + Transformer Engine |
| 内存类型与带宽 | 80 GB HBM2e 内存 2 TB/s 带宽 |
80 GB HBM3 内存 3.9 TB/s 带宽 |
| MIG | A100 允许将单个 GPU 划分为最多七个独立实例,适用于多租户或多模型工作负载 | H100 增强了隔离性并改进了多租户推理的 QoS |
A100 vs H100:基准测试
| 类别 | A100 80GB SXM(Ampere) | H100 80GB SXM(Hopper) | 提升(H100 vs A100) |
|---|---|---|---|
| 架构 | Ampere | Hopper | — |
| 内存 | HBM2e | HBM3 | 新一代 |
| 80 GB | 80 GB | — | |
| 2.0 TB/s | 3.35 TB/s | +68% | |
| 互连 | 600 GB/s + PCIe Gen4 64 GB/s | 900 GB/s + PCIe Gen5 128 GB/s | +50% NVLink 速度 |
| 功耗(TDP) | 400 W | 最高 700 W | +75%(可配置) |
| MIG 支持 | 7 × 10 GB | 7 × 10 GB | 数量相同,QoS 提升 |
| FP64 | 9.7 TFLOPS | 34 TFLOPS | +3.5× |
| FP64 Tensor Core | 19.5 TFLOPS | 67 TFLOPS | +3.4× |
| FP32 | 19.5 TFLOPS | 67 TFLOPS | +3.4× |
| TF32 Tensor Core | 156 / 312 TFLOPS(稀疏) | 989 TFLOPS | +3.2×(密集) |
| BF16 Tensor Core | 312 / 624 TFLOPS(稀疏) | 1,979 TFLOPS | +3.2× |
| FP16 Tensor Core | 312 / 624 TFLOPS(稀疏) | 1,979 TFLOPS | +3.2× |
| FP8 Tensor Core | — | 3,958 TFLOPS | 新精度模式 |
| INT8 Tensor Core | 624 / 1,248 TOPS(稀疏) | 3,958 TOPS | +3.2× |
H100 SXM 在技术设计和基准性能上相比 A100 SXM 实现了明显的代际飞跃。所有精度的计算吞吐量大约翻了三倍,同时内存和互连带宽也显著提升。
A100 在共享或中等规模工作负载中仍然更节能、更具成本效益,但 H100 是追求最大速度和可扩展性的开发者的更优选择。
A100 vs H100:推荐用例
| 用例 | 推荐 GPU | 原因 |
|---|---|---|
| 预算有限,模型 ≤ 300 亿参数,共享租户 | A100 | 经过验证的稳定性,强大的成本效益,MIG 支持 |
| 大规模训练(≥ 700 亿参数),多 GPU 节点 | H100 | 面向未来,顶级速度和可扩展性 |
Novita AI 上的成本对比
Novita 提供最低的按需 H100 价格,仅 $1.80/小时
比同等 GPU 性能的其他提供商便宜 30%。
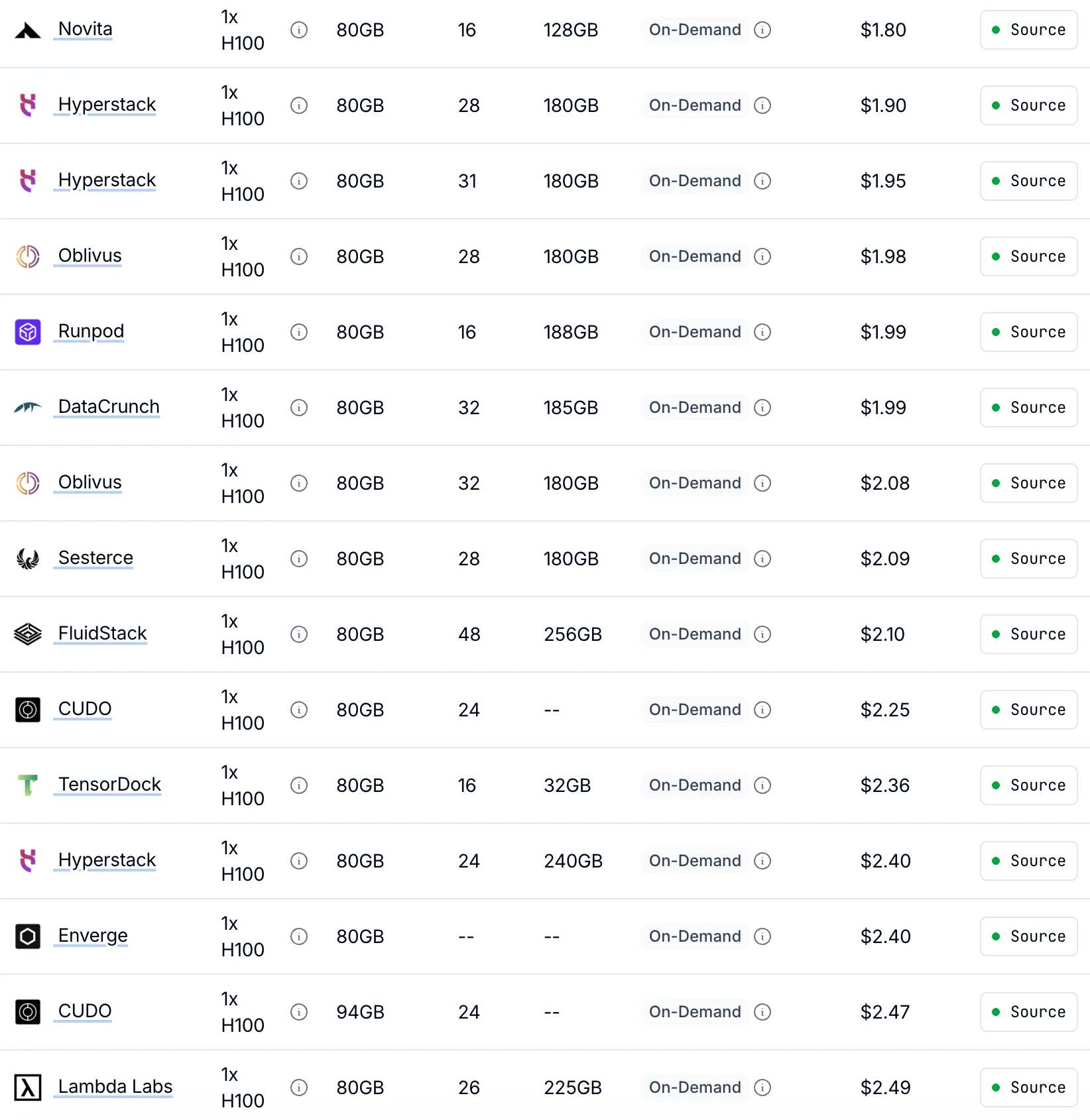
数据来源:Getdeploying
| GPU 类型 | 规格 | 计费模式 | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB 显存 | 按需 | $1.45/小时 | $11.60/小时 |
| 竞价 | $0.73/小时 | $5.84/小时 | ||
| A100 SXM 80GB | 80 GB 显存 | 按需 | $1.60/小时 | $12.80/小时 |
| 竞价 | $0.80/小时 | $6.40/小时 |
Novita AI 的 竞价模式 是一种成本优化的 GPU 租赁选项,利用平台未使用或闲置的 GPU 容量。与保留专用硬件以保证持续使用的按需实例不同,竞价实例是 可中断的——以显著更低的价格提供,通常便宜 40–60%。
这种定价模式之所以有效,是因为 Novita 动态地将闲置 GPU 重新分配给短期用户,而不是让它们闲置。通过这样做,平台提高了整体 基础设施利用率,而开发者则从灵活工作负载的 更低计算成本 中受益。
为什么选择 Novita AI 租用廉价 A100 和 H100
- 即时、全球 GPU 访问:GPU 实例在数秒内跨全球区域启动,实现低延迟访问和快速实验。
- 无服务器 + GPU 云混合:提供完整 GPU 实例和无服务器 GPU 模式(按需付费),适用于灵活的工作负载类型。
- 集成与可观测性:兼容监控/追踪栈(例如通过 Langfuse)以及即插即用的 OpenAI 风格 API 端点。
- 以开发者为中心的成本优化:除基础价格外,竞价实例(约节省 50%)和快速启动等功能降低了总体拥有成本。
如何在 Novita AI 上使用 A100 和 H100?
步骤 1:注册账户
通过我们的网站创建你的 Novita AI 账户。注册后,导航至左侧边栏的“探索”部分,查看我们的 GPU 产品并开始你的 AI 开发之旅。

步骤 2:探索模板和 GPU 服务器
从 PyTorch、TensorFlow 或 CUDA 等模板中选择符合项目需求的模板。然后选择你偏好的 GPU 配置——选项包括强大的 L40S、RTX 4090 或 A100 SXM4,每种配置具有不同的显存、内存和存储规格。
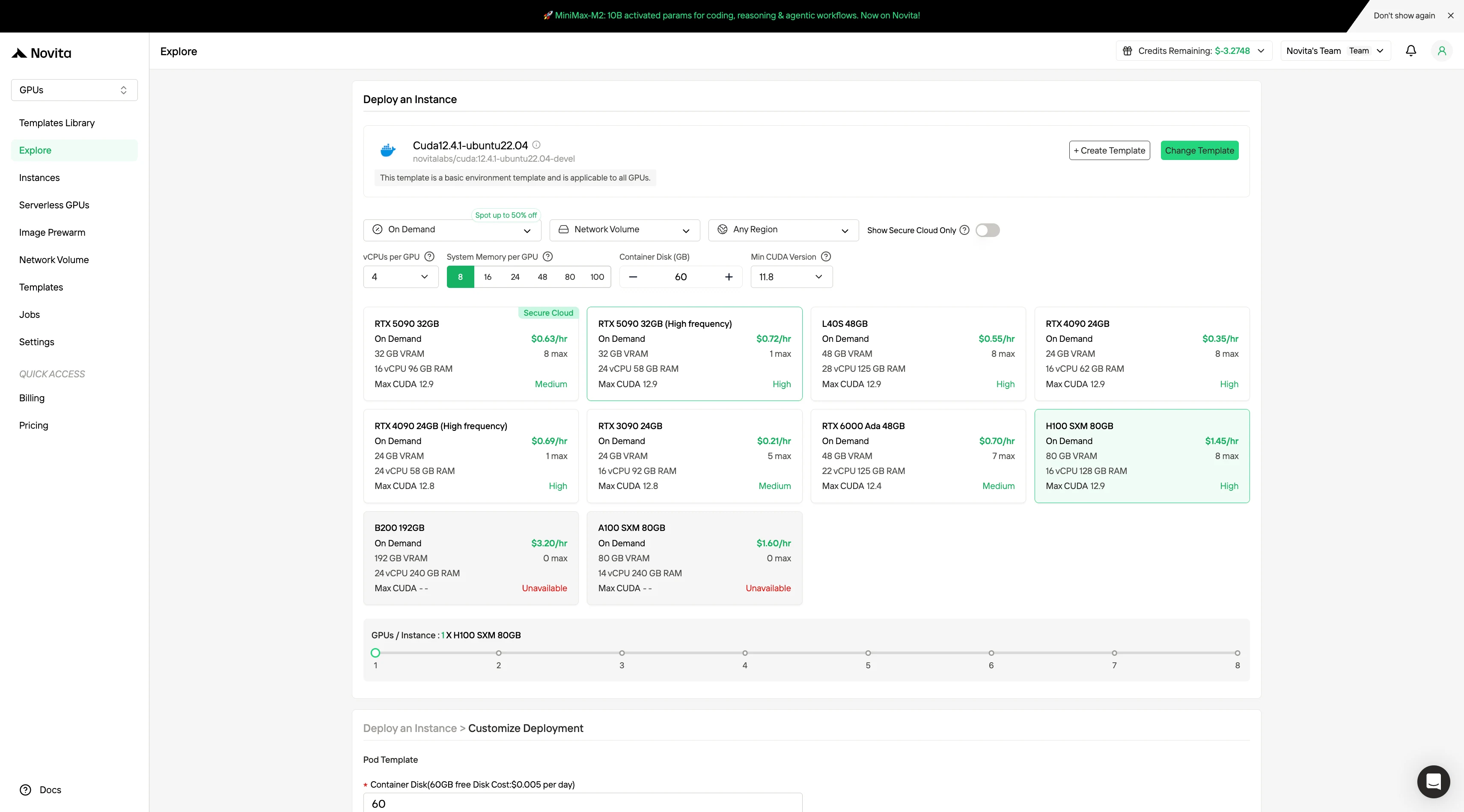
步骤 3:定制你的部署
通过选择偏好的操作系统和配置选项来定制你的环境,确保针对特定 AI 工作负载和开发需求获得最佳性能。
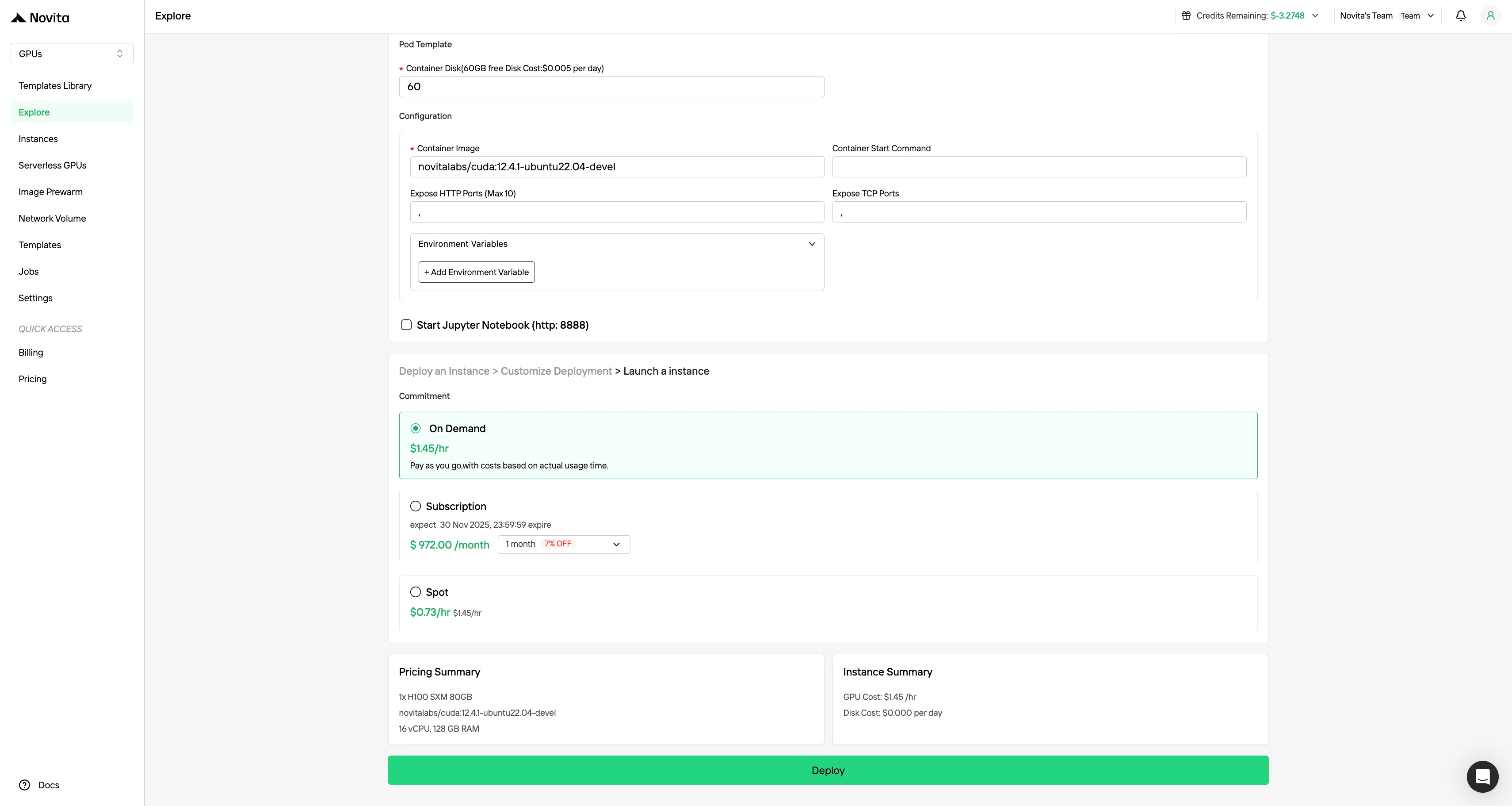
步骤 4:启动实例
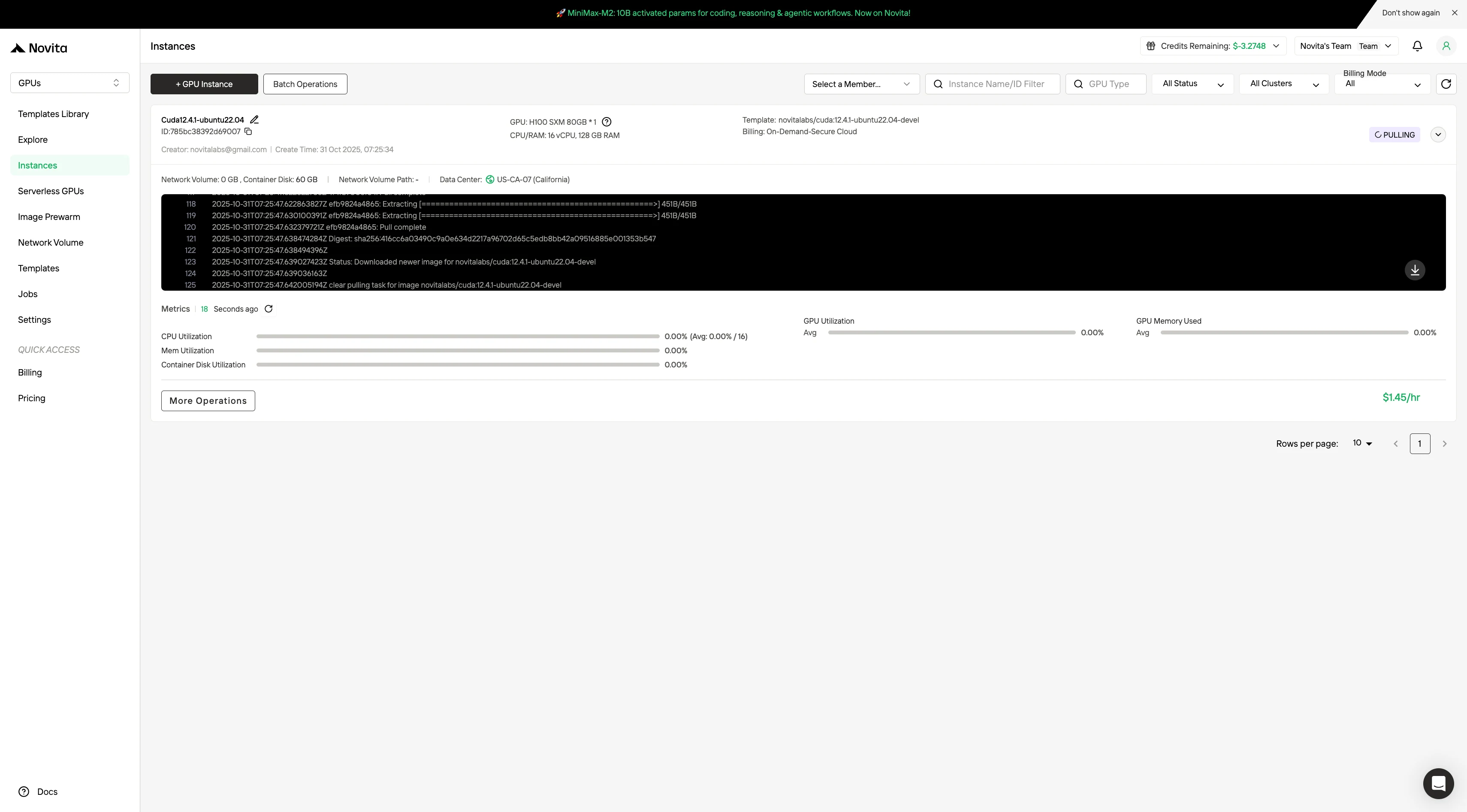
选择“启动实例”开始部署。你的高性能 GPU 环境将在几分钟内准备就绪,让你立即开始机器学习、渲染或计算项目。
选择 GPU 意味着在 性能、成本 和 未来可扩展性 之间取得平衡。
- 选择 A100:如果你需要可靠、经济高效的计算能力来处理中型 LLM 或多租户任务。
- 选择 H100:如果你的目标是大规模 LLM 训练、多 GPU 管道和尖端吞吐量。
Novita AI 的即时部署和灵活定价使其成为两种路径的强大平台。
下一步: 根据模型规模和预算匹配正确的 GPU,然后在 Novita AI GPUs 上启动实例,验证你的性能提升。
常见问题
除了低小时成本外,使用 Novita AI 还有其他好处吗?
是的——好处包括全球分布的 GPU 节点以实现低延迟访问、无服务器 GPU 模式以实现按需付费的可扩展性、统一 API 支持 200+ 模型,以及简化的基础设施管理。
什么时候应该选择 NVIDIA A100 而不是 H100?
当工作负载模型规模适中(例如 ≤300 亿参数)、共享租户,或者成本效益比峰值吞吐量更重要时,选择 A100。
什么时候 NVIDIA H100 是更好的选择?
当你训练非常大的模型(700 亿参数以上)、使用多 GPU 或多节点设置,或者需要最快的训练和推理吞吐量时,选择 H100。
Novita AI 是一个 AI 云平台,为开发者提供通过简单 API 部署 AI 模型的便捷方式,同时提供经济实惠且可靠的 GPU 云用于构建和扩展。
推荐阅读



