

Le développement IA repose sur une infrastructure GPU rapide et à la demande. Novita AI propose un cloud GPU instantanément déployable qui élimine les files d’attente et les délais de configuration.
Dans les flux de travail de développement réels, les équipes peuvent lancer des instances NVIDIA A100 ou H100 en quelques minutes pour affiner de grands modèles, exécuter des pipelines d’inférence ou réaliser des benchmarks de nouvelles architectures sans attendre les ressources partagées d’un cluster.
Cette évolutivité immédiate permet aux développeurs d’itérer plus rapidement, de contrôler les coûts et de passer du prototype à la production avec un minimum de friction.
Points clés
Déploiement instantané : Les instances GPU se lancent en moins de 30 secondes.
Performance abordable : GPU A100/H100 à des tarifs horaires compétitifs, avec des instances Spot jusqu’à 50 % moins chères.
Adapté à vos besoins : L’A100 convient aux petits/moyens modèles et aux environnements partagés ; le H100 cible l’entraînement de LLM massifs.
Consultez les meilleurs tarifs sur Novita AI dès maintenant !
Pourquoi choisir l’A100/H100 ?

A100 vs H100 : Comparaison technique
| Fonctionnalité | A100 (architecture Ampere) | H100 (architecture Hopper) |
|---|---|---|
| Génération d’architecture | Ampere – 3e génération de Tensor Cores. | Hopper – 4e génération de Tensor Cores + Transformer Engine. |
| Type et bande passante de la mémoire | 80 Go de mémoire HBM2e 2 To/s de bande passante. |
80 Go de mémoire HBM3 3,9 To/s de bande passante. |
| MIG | L’A100 permet de partitionner un seul GPU en jusqu’à sept instances isolées pour des charges de travail multi-tenantes ou multi-modèles. | Le H100 améliore cela avec une isolation plus forte et une QoS améliorée pour l’inférence multi-tenante. |
A100 vs H100 : Benchmarks
| Catégorie | A100 80Go SXM (Ampere) | H100 80Go SXM (Hopper) | Amélioration (H100 vs A100) |
|---|---|---|---|
| Architecture | Ampere | Hopper | — |
| Mémoire | HBM2e | HBM3 | Nouvelle génération |
| 80 Go | 80 Go | — | |
| 2,0 To/s | 3,35 To/s | +68 % | |
| Interconnexion | 600 Go/s + PCIe Gen4 64 Go/s | 900 Go/s + PCIe Gen5 128 Go/s | +50 % de vitesse NVLink |
| Puissance (TDP) | 400 W | Jusqu’à 700 W | +75 % (configurable) |
| Support MIG | 7 × 10 Go | 7 × 10 Go | Même nombre, QoS améliorée |
| FP64 | 9,7 TFLOPS | 34 TFLOPS | +3,5× |
| FP64 Tensor Core | 19,5 TFLOPS | 67 TFLOPS | +3,4× |
| FP32 | 19,5 TFLOPS | 67 TFLOPS | +3,4× |
| TF32 Tensor Core | 156 / 312 TFLOPS (creux) | 989 TFLOPS | +3,2× (dense) |
| BF16 Tensor Core | 312 / 624 TFLOPS (creux) | 1 979 TFLOPS | +3,2× |
| FP16 Tensor Core | 312 / 624 TFLOPS (creux) | 1 979 TFLOPS | +3,2× |
| FP8 Tensor Core | — | 3 958 TFLOPS | Nouveau mode de précision |
| INT8 Tensor Core | 624 / 1 248 TOPS (creux) | 3 958 TOPS | +3,2× |
Le H100 SXM représente un saut générationnel clair par rapport à l’A100 SXM, tant sur le plan de la conception technique que des performances en benchmark. Le débit de calcul triple approximativement sur toutes les précisions, tandis que la bande passante de la mémoire et de l’interconnexion augmente également de manière significative.
L’A100 reste plus économe en énergie et plus rentable pour les charges de travail partagées ou de taille moyenne, mais le H100 est le choix supérieur pour les développeurs visant la vitesse et l’évolutivité maximales.
A100 vs H100 : Cas d’usage recommandés
| Cas d’usage | GPU recommandé | Pourquoi |
|---|---|---|
| Budget limité, modèles ≤ 30 milliards de paramètres, tenance partagée | A100 | Stabilité éprouvée, excellent rapport qualité-prix, support MIG |
| Entraînement à grande échelle (≥ 70 milliards de paramètres), nœuds multi-GPU | H100 | Prêt pour l’avenir, vitesse et évolutivité de premier ordre |
Comparaison des coûts sur Novita AI
Novita propose les tarifs H100 à la demande les plus bas à 1,80 $/h
Jusqu’à 30 % moins cher que les autres fournisseurs avec des performances GPU identiques.
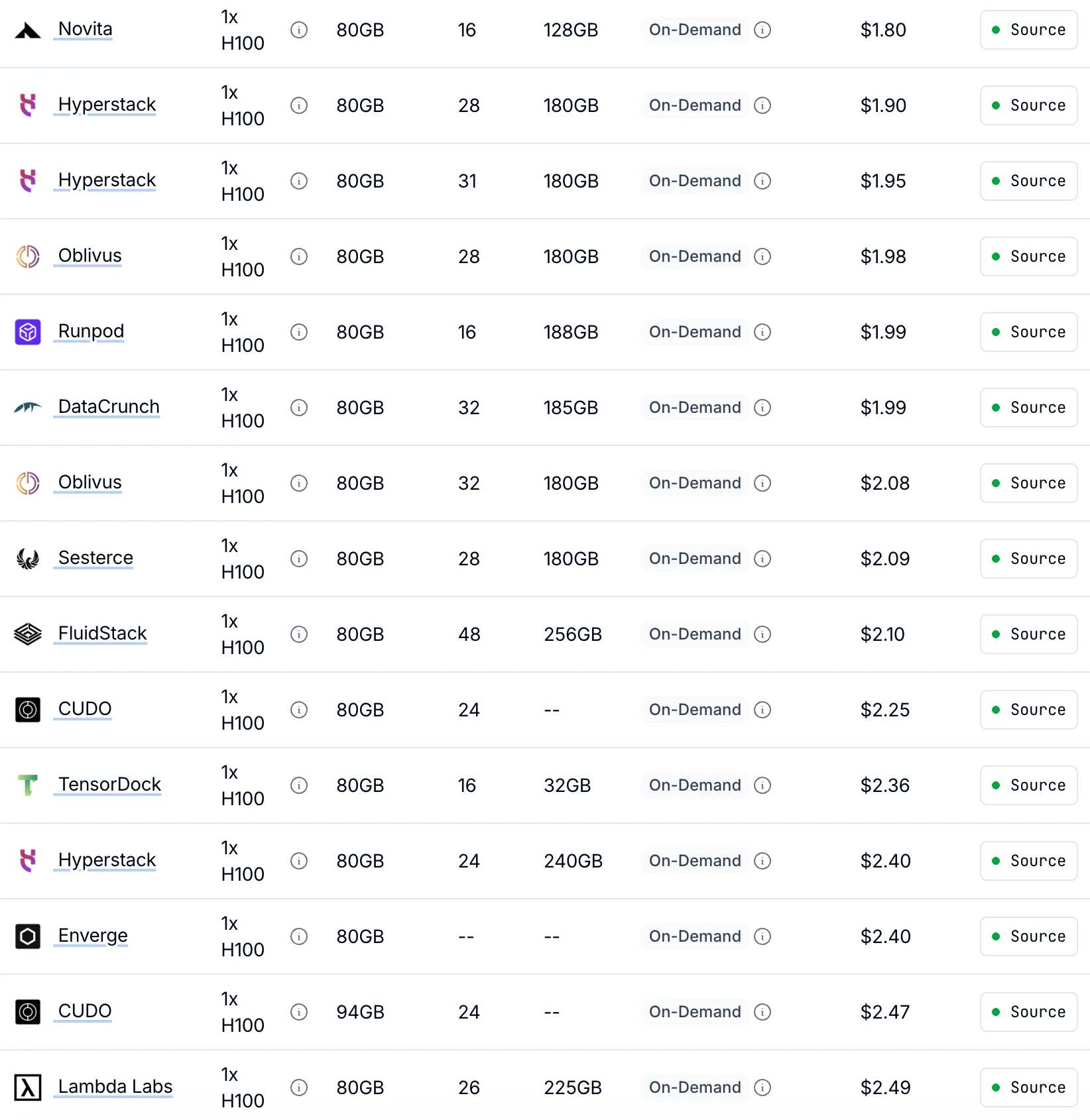
De Getdeploying
| Type de GPU | Spécification | Modèle de tarification | 1× GPU | 8× GPU |
|---|---|---|---|---|
| H100 SXM 80Go | 80 Go de VRAM | À la demande | 1,45 $/h | 11,60 $/h |
| Spot | 0,73 $/h | 5,84 $/h | ||
| A100 SXM 80Go | 80 Go de VRAM | À la demande | 1,60 $/h | 12,80 $/h |
| Spot | 0,80 $/h | 6,40 $/h |
Le mode Spot de Novita AI est une option de location de GPU optimisée pour les coûts qui exploite la capacité GPU inutilisée ou inactive de la plateforme. Contrairement aux instances à la demande, qui réservent du matériel dédié pour une utilisation continue garantie, les instances Spot sont interruptibles — proposées à des prix nettement plus bas, généralement 40 à 60 % moins chères.
Ce modèle de tarification fonctionne car Novita réaffecte dynamiquement les GPU inactifs aux utilisateurs à court terme au lieu de les laisser inutilisés. Ce faisant, la plateforme améliore l’efficacité d’utilisation globale de l’infrastructure, tandis que les développeurs bénéficient de coûts de calcul beaucoup plus bas pour des charges de travail flexibles.
Pourquoi choisir Novita AI pour louer des A100 et H100 à bas prix
- Accès GPU instantané et mondial : Les instances GPU se lancent en quelques secondes dans toutes les régions du monde, permettant un accès à faible latence et une expérimentation rapide.
- Hybride Serverless + Cloud GPU : Propose à la fois des instances GPU complètes et des modes GPU serverless (paiement à l’usage) pour des types de charges de travail flexibles.
- Intégrations et observabilité : Compatible avec les piles de surveillance et de traçage (par ex. via Langfuse) et des points de terminaison API de style OpenAI prêts à l’emploi.
- Optimisation des coûts centrée sur les développeurs : En plus du prix de base, des fonctionnalités comme les instances Spot (≈50 % d’économies) et un lancement rapide réduisent le coût total de possession.
Comment utiliser l’A100 et le H100 sur Novita AI ?
Étape 1:Créer un compte
Créez votre compte Novita AI via notre site web. Après inscription, rendez-vous dans la section « Explorer » de la barre latérale gauche pour consulter nos offres GPU et commencer votre parcours de développement IA.

Essayez Novita AI dès maintenant
Étape 2:Explorer les modèles et les serveurs GPU**
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA qui correspondent aux besoins de votre projet. Sélectionnez ensuite votre configuration GPU préférée : les options incluent le puissant L40S, le RTX 4090 ou l’A100 SXM4, chacun avec des spécifications de VRAM, de RAM et de stockage différentes.
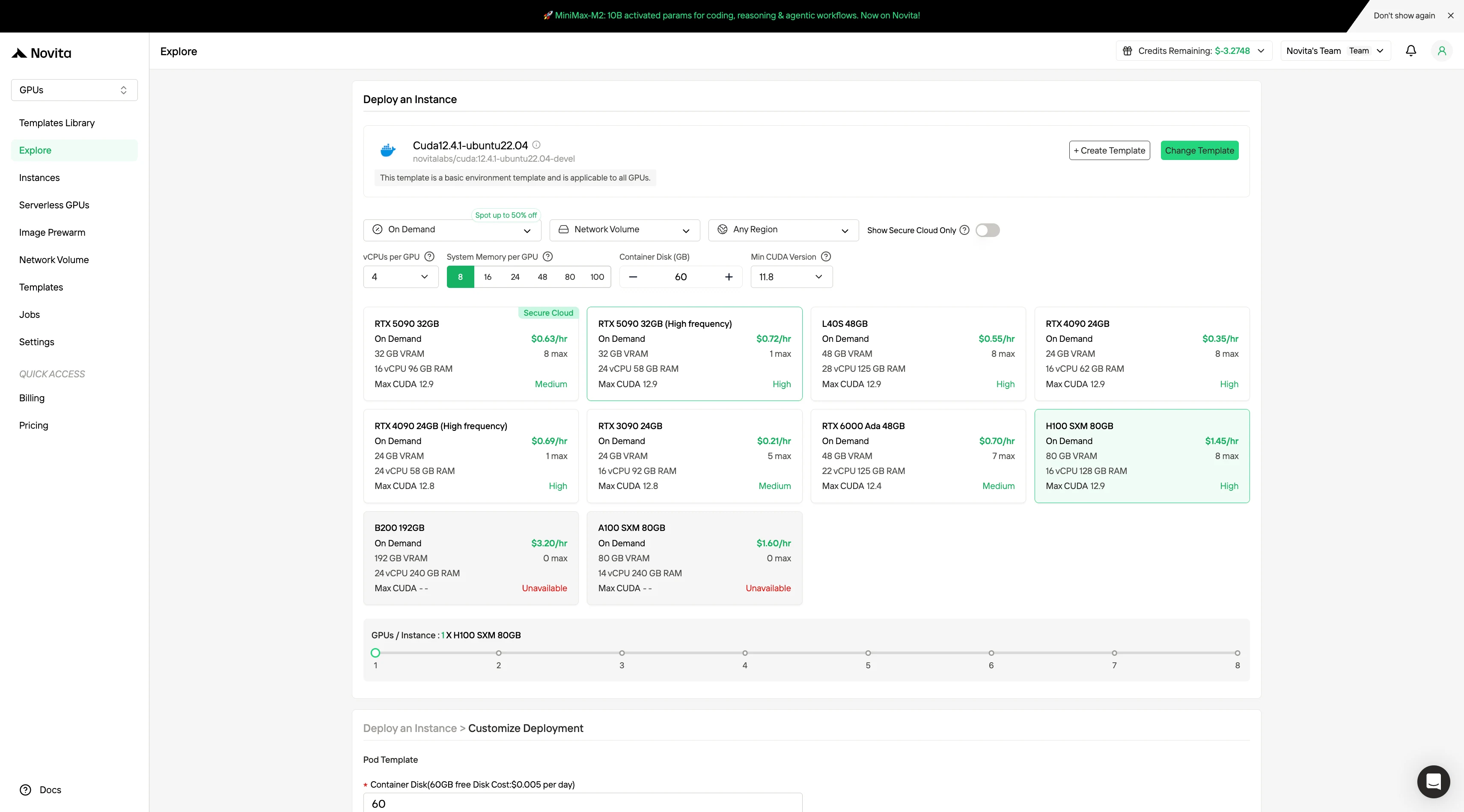
Étape 3 : Personnalisez votre déploiement
Personnalisez votre environnement en sélectionnant votre système d’exploitation et vos options de configuration préférés pour garantir des performances optimales pour vos charges de travail IA et vos besoins de développement spécifiques.
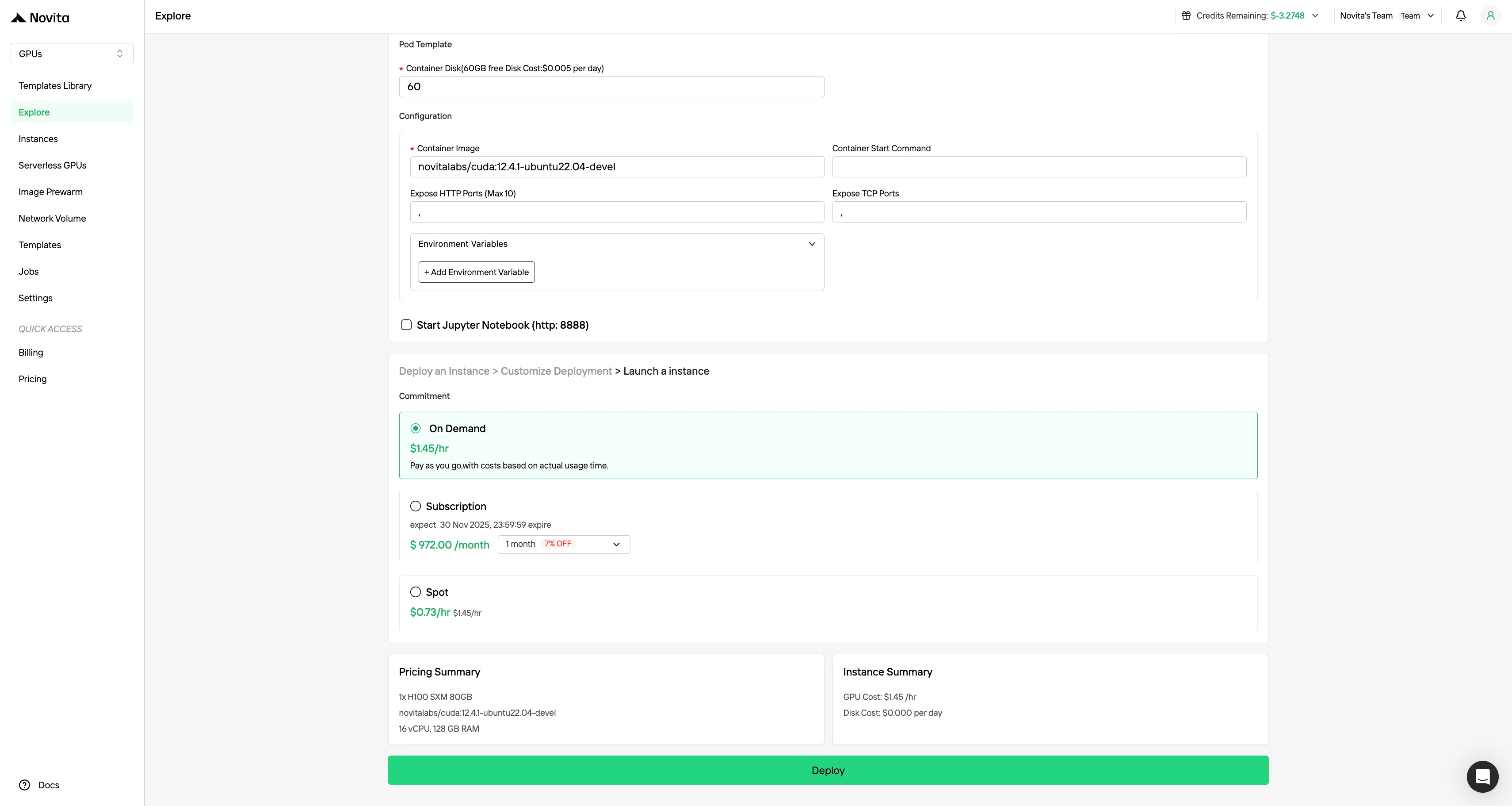
Étape 4:Lancer une instance**
Sélectionnez « Lancer une instance » pour démarrer votre déploiement. Votre environnement GPU haute performance sera prêt en quelques minutes, vous permettant de commencer immédiatement vos projets d’apprentissage automatique, de rendu ou de calcul.
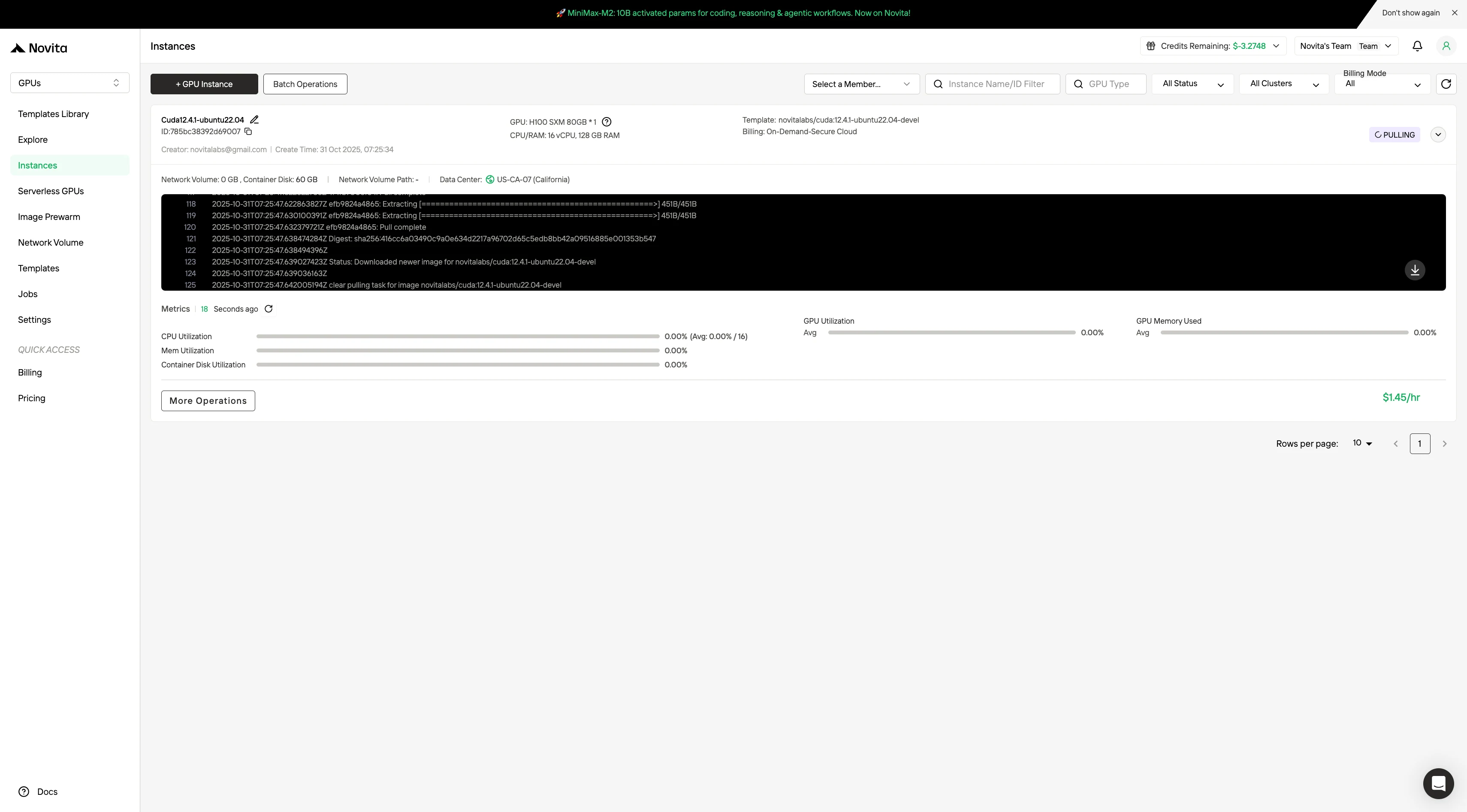
Sélectionner des GPU signifie équilibrer performance, coût et évolutivité future.
- Choisissez l’A100 si vous avez besoin de calculs fiables et rentables pour des LLM de taille moyenne ou des tâches multi-tenantes.
- Choisissez le H100 si votre objectif est l’entraînement de LLM à grande échelle, des pipelines multi-GPU et un débit de pointe.
Le déploiement instantané et les tarifs flexibles de Novita AI en font une plateforme solide pour les deux options.
Prochaine étape : Associez la taille de votre modèle et votre budget au GPU adapté, puis lancez une instance sur les GPU Novita AI pour valider vos gains de performance.
Foire aux questions
Quels sont les avantages supplémentaires au-delà du faible coût horaire lors de l’utilisation de Novita AI ?
Oui — les avantages incluent des nœuds GPU répartis dans le monde entier pour un accès à faible latence, des modes GPU serverless pour une évolutivité à l’usage, une API unifiée pour plus de 200 modèles et une gestion simplifiée de l’infrastructure.
Quand dois-je choisir le NVIDIA A100 plutôt que le H100 ?
Choisissez l’A100 pour des charges de travail avec une taille de modèle modérée (par ex. ≤30 milliards de paramètres), une tenance partagée ou lorsque le rapport qualité-prix prime sur le débit maximal.
Quand le NVIDIA H100 devient-il le meilleur choix ?
Choisissez le H100 lorsque vous entraînez des modèles très volumineux (70 milliards de paramètres et plus), utilisez des configurations multi-GPU ou multi-nœuds, ou nécessitez l’entraînement et l’inférence les plus rapides.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API intuitive, tout en fournissant un cloud GPU abordable et fiable pour construire et mettre à l’échelle.
Lectures recommandées



