

O desenvolvimento de IA depende de infraestrutura de GPU rápida e sob demanda. A Novita AI oferece uma nuvem de GPU implantável instantaneamente que elimina filas de espera e atrasos de configuração.
Em fluxos de trabalho de desenvolvimento reais, as equipes podem criar instâncias de NVIDIA A100 ou H100 em questão de minutos para realizar ajuste fino de modelos grandes, executar pipelines de inferência ou fazer benchmarks de novas arquiteturas sem esperar por recursos compartilhados de cluster.
Essa escalabilidade imediata ajuda os desenvolvedores a iterar mais rápido, controlar custos e passar do protótipo para a produção com o mínimo de atrito.
Principais Conclusões
Implantação instantânea: as instâncias de GPU são iniciadas em menos de 30 segundos.
Desempenho acessível: GPUs A100/H100 com taxas horárias competitivas, com instâncias Spot até 50% mais baratas.
Adequado para o propósito: o A100 é adequado para modelos pequenos/médios e ambientes compartilhados; o H100 é voltado para treinamento massivo de LLMs.
Por que escolher A100/H100?

A100 vs H100: Comparação Técnica
| Recurso | A100 (arquitetura Ampere) | H100 (arquitetura Hopper) |
|---|---|---|
| Geração de Arquitetura | Ampere – 3ª geração de Tensor Cores. | Hopper – 4ª geração de Tensor Cores + Transformer Engine. |
| Tipo de Memória e Largura de Banda | 80 GB de memória HBM2e Largura de banda de 2 TB/s. |
80 GB de memória HBM3 Largura de banda de 3,9 TB/s. |
| MIG | O A100 permite que uma única GPU seja particionada em até sete instâncias isoladas para cargas de trabalho multitenant ou multimodelo. | O H100 aprimora com isolamento mais forte e QoS aprimorado para inferência multitenant. |
A100 vs H100: Benchmarks
| Categoria | A100 80GB SXM (Ampere) | H100 80GB SXM (Hopper) | Melhoria (H100 vs A100) |
|---|---|---|---|
| Arquitetura | Ampere | Hopper | — |
| Memória | HBM2e | HBM3 | Nova geração |
| 80 GB | 80 GB | — | |
| 2,0 TB/s | 3,35 TB/s | +68% | |
| Interconexão | 600 GB/s + PCIe Gen4 64 GB/s | 900 GB/s + PCIe Gen5 128 GB/s | +50% de velocidade NVLink |
| Energia (TDP) | 400 W | Até 700 W | +75% (configurável) |
| Suporte a MIG | 7 × 10 GB | 7 × 10 GB | Mesma quantidade, QoS aprimorado |
| FP64 | 9,7 TFLOPS | 34 TFLOPS | +3,5× |
| Núcleo Tensor FP64 | 19,5 TFLOPS | 67 TFLOPS | +3,4× |
| FP32 | 19,5 TFLOPS | 67 TFLOPS | +3,4× |
| Núcleo Tensor TF32 | 156 / 312 TFLOPS (esparso) | 989 TFLOPS | +3,2× (denso) |
| Núcleo Tensor BF16 | 312 / 624 TFLOPS (esparso) | 1 979 TFLOPS | +3,2× |
| Núcleo Tensor FP16 | 312 / 624 TFLOPS (esparso) | 1 979 TFLOPS | +3,2× |
| Núcleo Tensor FP8 | — | 3 958 TFLOPS | Novo modo de precisão |
| Núcleo Tensor INT8 | 624 / 1 248 TOPS (esparso) | 3 958 TOPS | +3,2× |
O H100 SXM representa um salto generacional claro em relação ao A100 SXM, tanto em design técnico quanto em desempenho de benchmark. O throughput de computação aproximadamente triplica em todas as precisões, enquanto as larguras de banda de memória e interconexão também aumentam significativamente.
O A100 continua sendo mais eficiente em energia e econômico para cargas de trabalho compartilhadas ou de médio porte, mas o H100 é a escolha superior para desenvolvedores que buscam velocidade e escalabilidade máximas.
A100 vs H100: Casos de Uso Recomendados
| Caso de Uso | GPU Recomendada | Por quê |
|---|---|---|
| Orçamento limitado, modelos ≤ 30 B de parâmetros, tenência compartilhada | A100 | Estabilidade comprovada, alta eficiência de custo, suporte a MIG |
| Treinamento em larga escala (≥ 70 B de parâmetros), nós com várias GPUs | H100 | Pronto para o futuro, velocidade e escalabilidade de primeira linha |
Comparação de Custos na Novita AI
A Novita oferece o menor preço de H100 sob demanda por $1,80/hora
até 30% mais barato que outros provedores com desempenho de GPU idêntico.
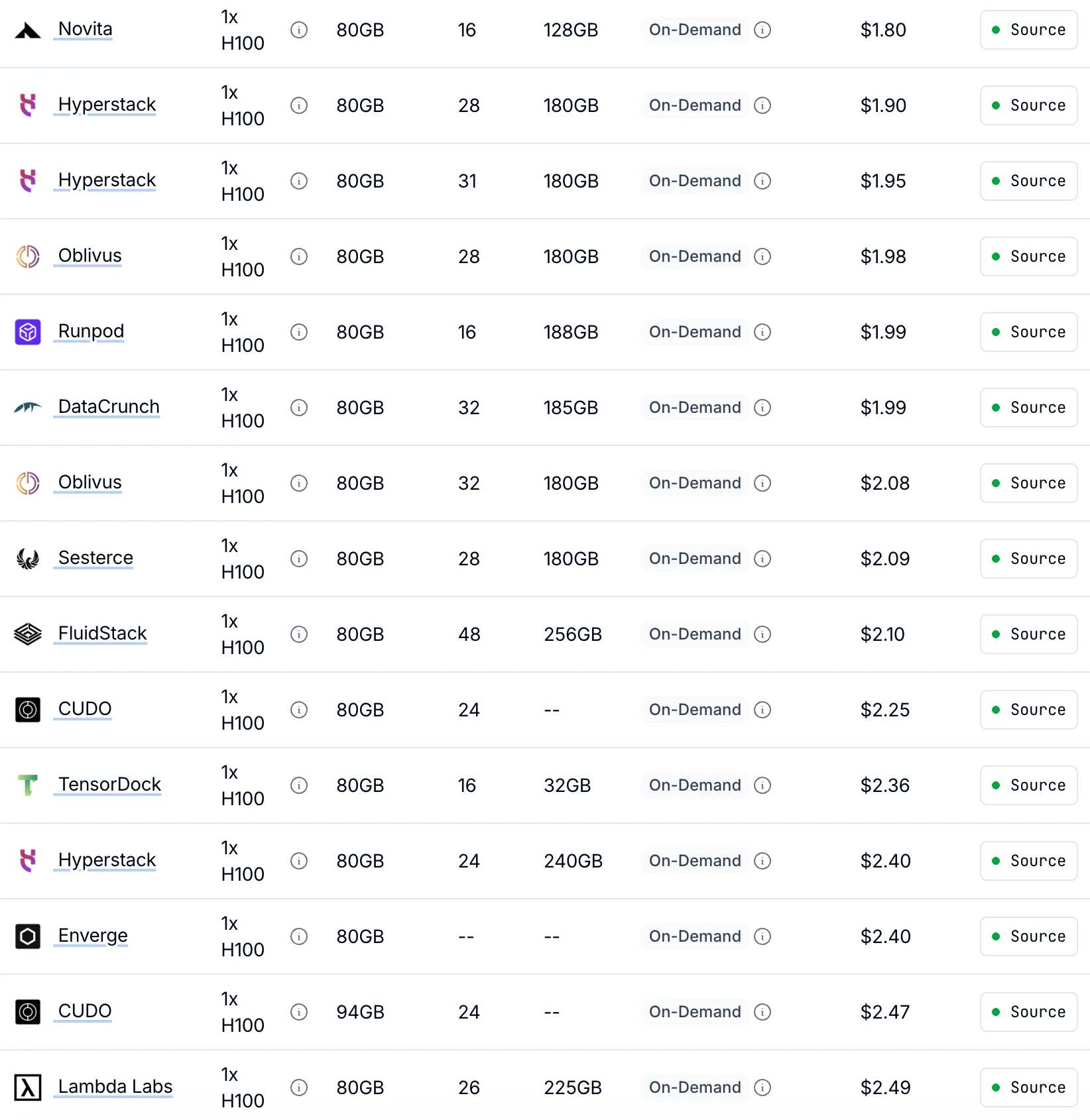
De Getdeploying
| Tipo de GPU | Especificação | Modelo de Preço | 1× GPU | 8× GPUs |
|---|---|---|---|---|
| H100 SXM 80GB | 80 GB de VRAM | Sob Demanda | $1,45/hora | $11,60/hora |
| Spot | $0,73/hora | $5,84/hora | ||
| A100 SXM 80GB | 80 GB de VRAM | Sob Demanda | $1,60/hora | $12,80/hora |
| Spot | $0,80/hora | $6,40/hora |
O modo Spot da Novita AI é uma opção de aluguel de GPU otimizada para custos que aproveita a capacidade de GPU não utilizada ou ociosa da plataforma. Ao contrário das instâncias sob demanda, que reservam hardware dedicado para uso contínuo garantido, as instâncias Spot são interrompíveis – oferecidas a preços significativamente mais baixos, geralmente 40–60% mais baratas.
Esse modelo de preço funciona porque a Novita realoca dinamicamente GPUs ociosas para usuários de curto prazo, em vez de deixá-las sem uso. Ao fazer isso, a plataforma melhora a eficiência de utilização da infraestrutura geral, enquanto os desenvolvedores se beneficiam de custos computacionais muito menores para cargas de trabalho flexíveis.
Por que escolher a Novita AI para alugar A100 e H100 baratos
- Acesso instantâneo e global a GPUs: as instâncias de GPU são iniciadas em segundos em regiões globais, permitindo acesso de baixa latência e experimentação rápida.
- Híbrido de Serverless + Nuvem de GPU: oferece tanto instâncias de GPU completa quanto modos de GPU serverless (pague pelo uso) para tipos de carga de trabalho flexíveis.
- Integrações e observabilidade: compatível com pilhas de monitoramento/rastreamento (ex: via Langfuse) e endpoints de API no estilo OpenAI prontos para uso.
- Otimização de custos centrada no desenvolvedor: além do preço base, recursos como instâncias Spot (≈50% de economia) e inicialização rápida reduzem o custo total de propriedade.
Como usar A100 e H100 na Novita AI?
Passo 1: Crie uma conta
Crie sua conta na Novita AI através do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e começar sua jornada de desenvolvimento de IA.

Passo 2: Explore Modelos e Servidores de GPU
Escolha entre modelos como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto. Em seguida, selecione sua configuração de GPU preferida – as opções incluem o poderoso L40S, RTX 4090 ou A100 SXM4, cada um com diferentes especificações de VRAM, RAM e armazenamento.
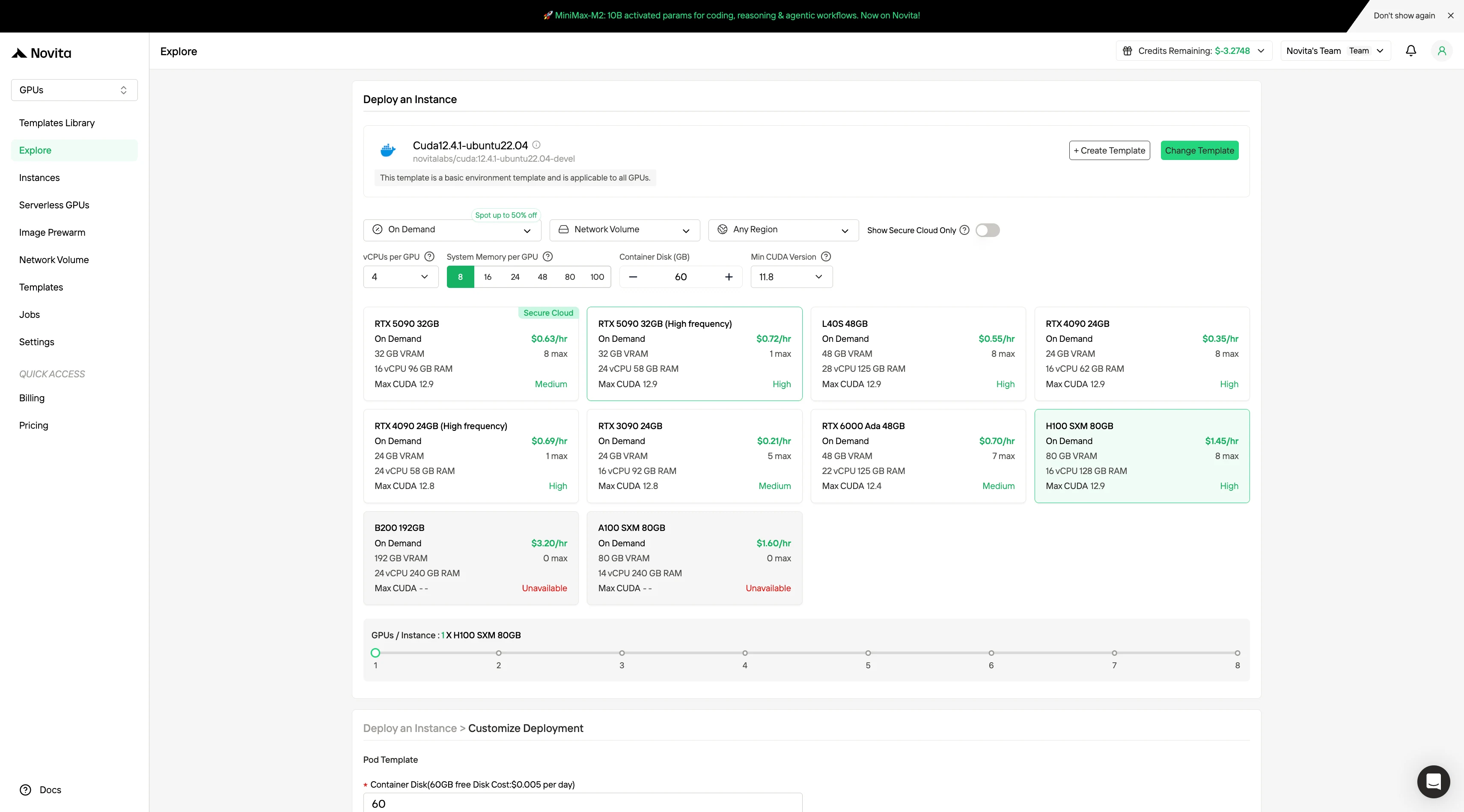
Passo 3: Personalize sua Implantação
Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir o desempenho ideal para suas cargas de trabalho de IA e necessidades de desenvolvimento específicas.
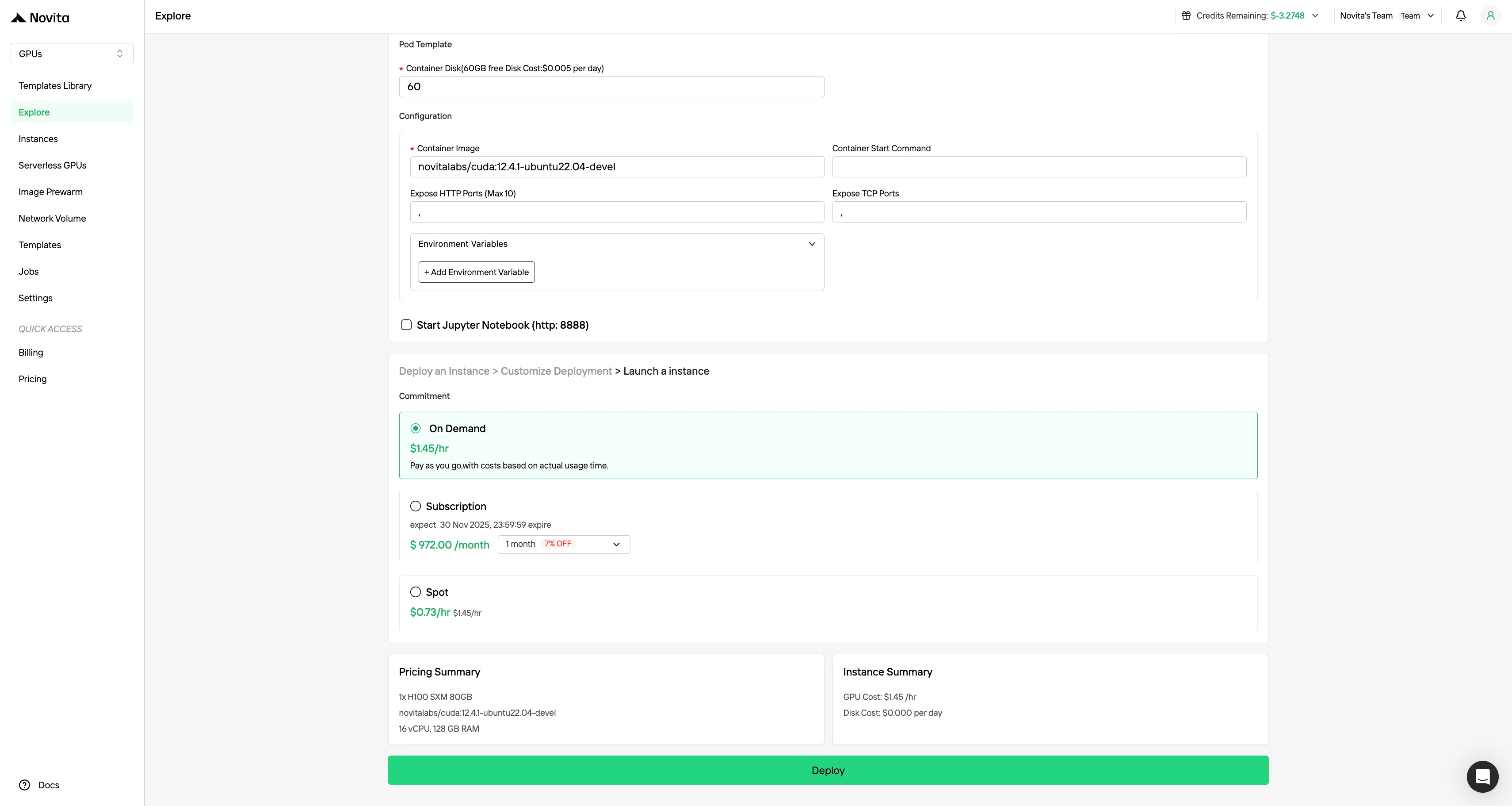
Passo 4: Inicie uma instância
Selecione “Iniciar Instância” para começar sua implantação. Seu ambiente de GPU de alto desempenho estará pronto em questão de minutos, permitindo que você comece imediatamente seus projetos de aprendizado de máquina, renderização ou computacionais.
Selecionar GPUs significa equilibrar desempenho, custo e escalabilidade futura.
- Escolha o A100 se você precisar de computação confiável e econômica para LLMs de médio porte ou tarefas multitenant.
- Escolha o H100 se seu objetivo é treinamento de LLMs em larga escala, pipelines com várias GPUs e throughput de ponta.
A implantação instantânea e os preços flexíveis da Novita AI tornam a plataforma uma opção forte para ambos os caminhos.
Próximo passo: corresponda o tamanho do seu modelo e orçamento à GPU certa, depois crie uma instância nas GPUs da Novita AI para validar seus ganhos de desempenho.
Perguntas Frequentes
Existem benefícios adicionais além do baixo custo horário ao usar Novita AI?
Sim – os benefícios incluem nós de GPU distribuídos globalmente para acesso de baixa latência, modos de GPU serverless para escalabilidade pagamento pelo uso, API unificada para mais de 200 modelos e gerenciamento simplificado de infraestrutura.
Quando devo escolher a NVIDIA A100 em vez da H100?
Escolha o A100 para cargas de trabalho com tamanho de modelo moderado (ex: ≤30 B de parâmetros), tenência compartilhada ou quando a eficiência de custo é mais importante que o throughput de pico.
Quando a NVIDIA H100 se torna a escolha melhor?
Escolha o H100 quando você treinar modelos muito grandes (70 B+ de parâmetros), usar configurações com várias GPUs ou vários nós ou precisar do treinamento e throughput de inferência mais rápidos.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer uma nuvem de GPU acessível e confiável para construir e escalar.
Leituras Recomendadas



