

Wichtige Highlights
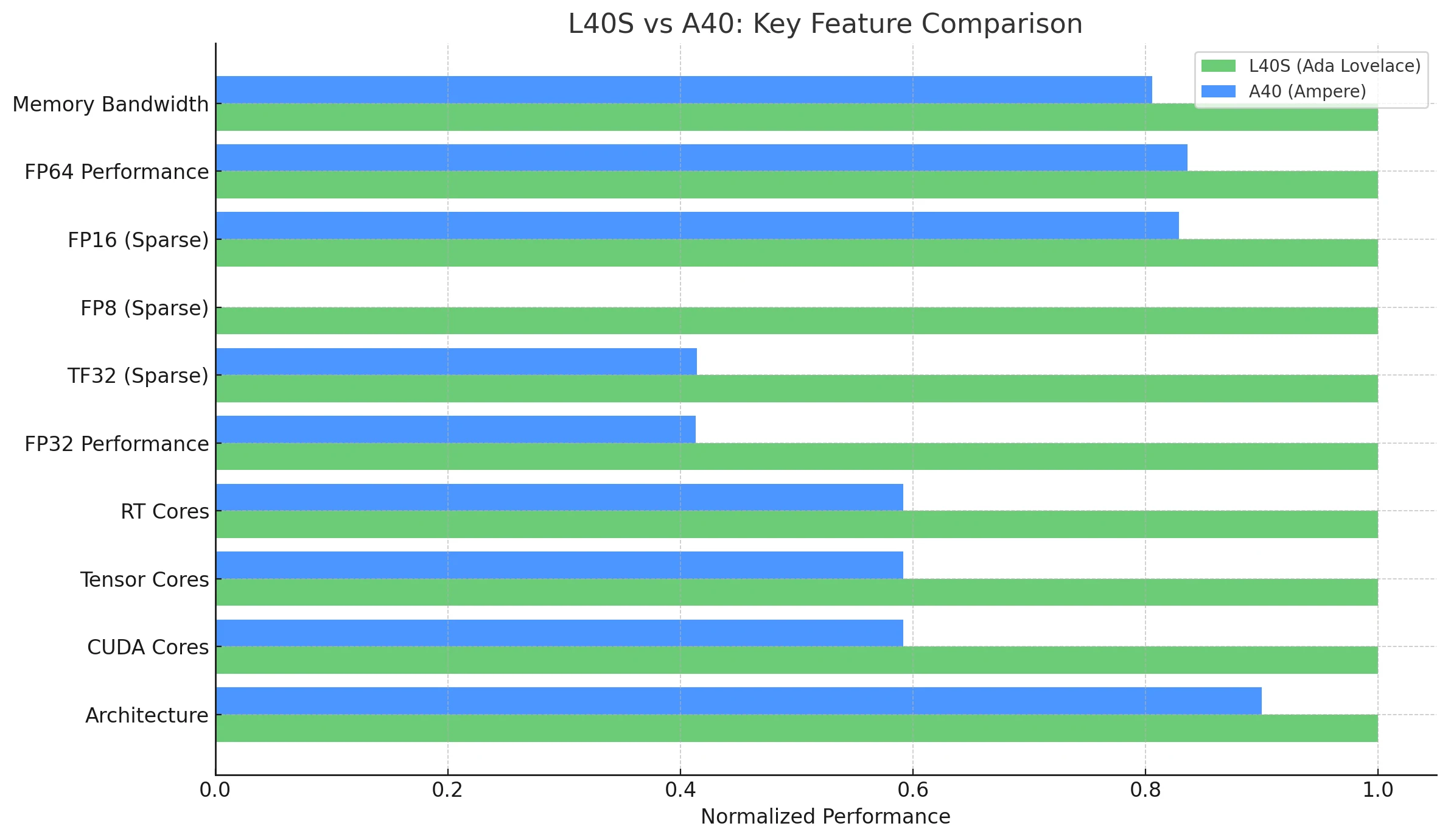
Leistung: L40S übertrifft den A40 in allen Metriken, mit exklusiver FP8-Unterstützung, deutlich höherer FP32/TF32-Leistung sowie überlegener Speicherbandbreite und Effizienz der CUDA-/Tensor-Cores.
Energieeffizienz: L40S erreicht bei ~60 % weniger Stromverbrauch pro GPU die gleiche oder bessere Leistung, während der A40 keine FP8-Unterstützung für KI-Aufgaben mit niedriger Präzision bietet.
Anwendungsschwerpunkt: Der L40S eignet sich besser für KI-Inferenz, Präzisionsaufgaben und Visualisierungsaufgaben und profitiert von der fortschrittlichen Ada-Lovelace-Architektur.

Novita AI

Runpod
Die Kosten für die Nutzung von L40S auf Novita AI betragen etwa die Hälfte des Preises von RunPod.
Der NVIDIA L40S, basierend auf der Ada-Lovelace-Architektur, ist eine deutliche Verbesserung gegenüber dem A40. Er bietet erweiterte KI-Inferenzfähigkeiten mit nativer FP8-Unterstützung, überlegene Grafikleistung durch RT-Cores der dritten Generation und eine verbesserte Energieeffizienz. Diese Fortschritte machen den L40S zu einer vielseitigen und kosteneffizienten Wahl für moderne Workloads im Rechenzentrum.
L40S vs A40: Architekturvergleich
Der NVIDIA L40S, basierend auf der Ada-Lovelace-Architektur, stellt einen bedeutenden Schritt gegenüber seinem auf Ampere basierenden Vorgänger, dem NVIDIA A40, dar. Beide GPUs sind für ein breites Spektrum an Workloads in Rechenzentren konzipiert, darunter KI, Grafik und HPC, doch der L40S bringt erhebliche Leistungsverbesserungen und neue Funktionen.
| Merkmal / Metrik | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| Architektur | Ada Lovelace | Ampere |
| CUDA-Cores | 18.176 | 10.752 |
| Tensor-Cores | 568 (Vierte Generation) | 336 (Dritte Generation) |
| RT-Cores | 142 (Dritte Generation) | 84 (Zweite Generation) |
| FP32-Leistung | 91,6 TFLOPS | 37,4 TFLOPS |
| TF32 Tensor (Sparse) | 183 | 366* | 74,8 | 149,6* |
| FP8 Tensor (Sparse) | 733 PFLOPS | Nativ nicht unterstützt (Einschränkung von Ampere) |
| FP16 Tensor (Sparse) | 362,05 TFLOPS | 149,7 | 299,4* |
| GPU-Speicher | 48 GB GDDR6 mit ECC | 48 GB GDDR6 mit ECC |
| Speicherbandbreite | 864 GB/s | 696 GB/s |
| Stromverbrauch (TDP) | 350 W | 300 W |
| Multi-Instance GPU (MIG) | Nein | Nein |
| NVLink | Nein | Ja (2-Wege, 112,5 GB/s Gesamtbandbreite) |
L40S vs A40: Energieeffizienz
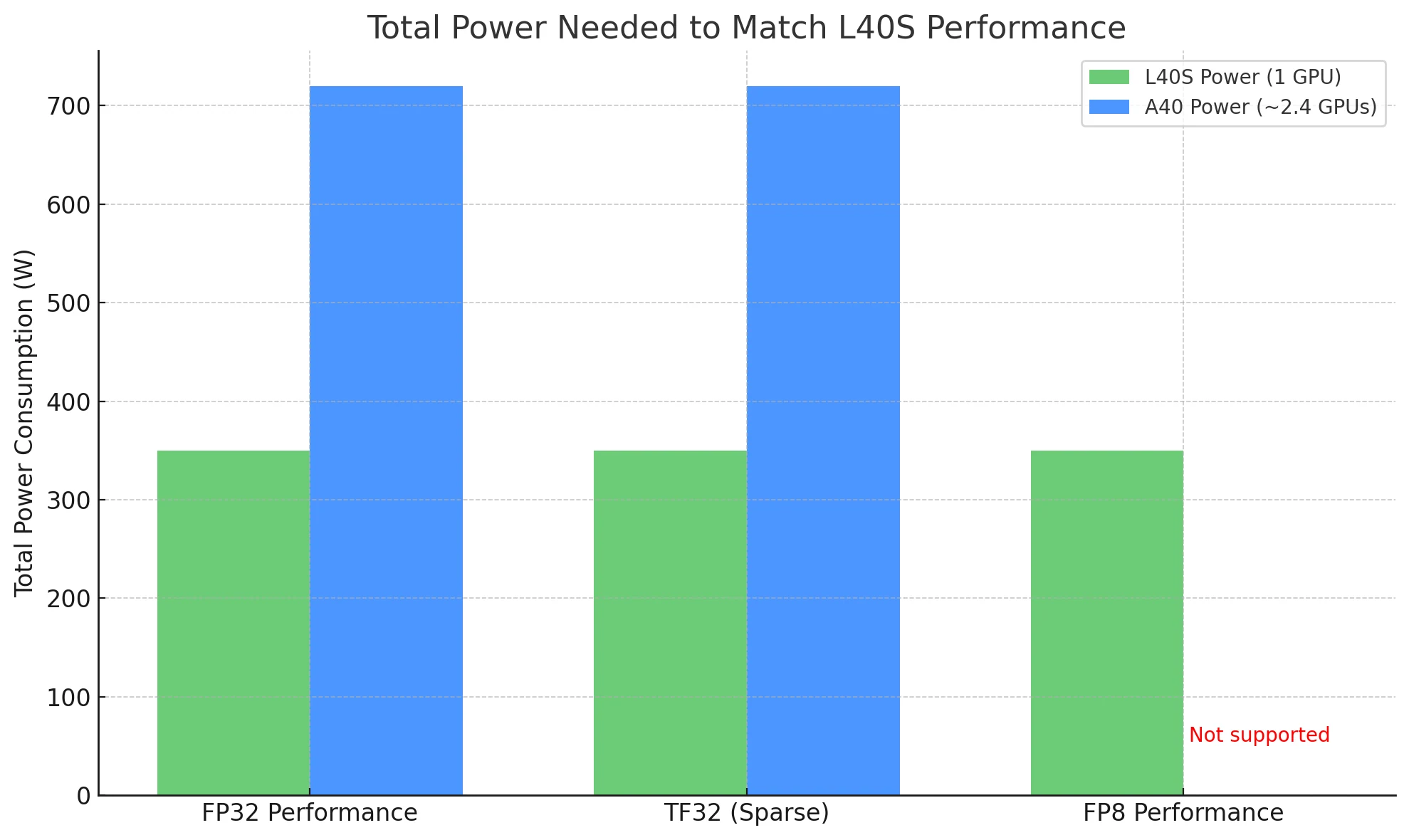
Beim Vergleich von GPUs ist die Gesamtleistung, die benötigt wird, um die gleiche Arbeitslast zu bewältigen, ein aussagekräftigeres Effizienzmaß – und hier sticht der L40S hervor.
- FP32-Leistung: Der L40S liefert ~91,6 TFLOPS, der A40 ~37,4 TFLOPS – etwa 2,4× mehr Leistung.
- TF32 (Sparse): Der L40S erreicht 366 TFLOPS, der A40 ~149,6 TFLOPS – ebenfalls etwa 2,4× der Ausgabe.
- FP8-Leistung: Der L40S hat einen erheblichen Vorteil durch native FP8-Unterstützung. Der auf der älteren Ampere-Architektur basierende A40 unterstützt FP8 überhaupt nicht.
Um die Leistung des L40S zu erreichen:
- Mit L40S: Sie benötigen nur 1 Karte mit einem Verbrauch von ~350 W.
- Mit A40: Sie würden theoretisch ~2,4 Karten benötigen, mit einer Gesamtleistungsaufnahme von ~720 W.
In realen Bereitstellungen bedeutet dies, dass der L40S bei halbem Stromverbrauch einen höheren Durchsatz liefern kann, was ihn besonders in leistungssensiblen oder großen Umgebungen zu einer weitaus kosteneffizienteren und skalierbaren Wahl macht.
L40S vs A40: Anwendungen
KI-Training & Inferenz
| Bereich | L40S | A40 |
|---|---|---|
| Training | Hervorragend für mittleres/großes Training (TF32: 366 TFLOPS), geringere Kosten, aber kein NVLink. | Besser für massive Modelle mit hoher Bandbreite (TF32: 149,6 TFLOPS, NVLink). |
| Inferenz | Hervorragende FP8-Unterstützung (738 PFLOPS), stark für LLMs & Deployment. | Kein FP8; stark in FP16, BF16, INT8. |
Grafik & Visualisierung
| Funktion | L40S | A40 |
|---|---|---|
| CUDA-Cores | 18.176 | 10.752 |
| RT-Cores | 142 | 84 |
| Treiber | RTX Enterprise, Omniverse, Studio bereit | Rechenzentrumsorientiert, eingeschränkte Grafik-Tools |
| FP32-Leistung | 91,6 TFLOPS | 37,4 TFLOPS |
Präzisions-Workloads
| Funktion | L40S | A40 |
|---|---|---|
| FP64-Nutzung | 1431 | 585 |
| FP32-Nutzung | 91,6 | 37,4 |
Empfehlung
- Wählen Sie L40S, wenn Sie Folgendes benötigen:
- Hochdurchsatz-Inferenz (insbesondere FP8-Unterstützung)
- Kosteneffizientes KI-Training mittlerer Größe
- Visuelle Workloads (Rendering, Omniverse)
- Allgemeine KI-Beschleunigung mit moderner Architektur
- Wählen Sie A40, wenn Sie Folgendes benötigen:
- NVLink-Unterstützung für Multi-GPU-Training großer Modelle
- Ein traditionelleres, rechenzentrumsorientiertes Setup ohne Grafikabhängigkeiten
Wie Sie L40S zu einem sehr günstigen Preis nutzen können?
Novita AI bietet eine cloudbasierte Plattform mit leistungsstarken GPU-Instanzen. Mit leistungsstarken GPUs gewährleistet es eine effiziente Leistung für komplexe Aufgaben, verbessert die Zugänglichkeit für die Bereitstellung auf verschiedenen Hardwareplattformen und bietet eine kosteneffiziente Lösung im Vergleich zur lokalen Hardwarevorhaltung für große KI-Bereitstellungen.
Schritt 1: Registrieren Sie ein Konto
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Navigieren Sie nach der Registrierung im linken Seitenbereich zum Bereich „Explore“, um unser GPU-Angebot zu sehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2: Vorlagen und GPU-Server erkunden
Wählen Sie aus Vorlagen wie PyTorch, TensorFlow oder CUDA, die Ihren Projektanforderungen entsprechen. Wählen Sie dann Ihre bevorzugte GPU-Konfiguration – Optionen umfassen den leistungsstarken L40S, RTX 4090 oder A100 SXM4, jeweils mit unterschiedlichen VRAM-, RAM- und Speicherspezifikationen.

Schritt 3: Passen Sie Ihre Bereitstellung an
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten.

Schritt 4: Starten Sie eine Instanz
Wählen Sie „Instanz starten“, um Ihre Bereitstellung zu starten. Ihre leistungsstarke GPU-Umgebung wird innerhalb weniger Minuten einsatzbereit sein, sodass Sie sofort mit Ihren Projekten im maschinellen Lernen, Rendering oder in der Datenverarbeitung beginnen können.

Der NVIDIA L40S stellt in fast jeder Hinsicht einen großen Sprung gegenüber dem A40 dar – von der FP8-Inferenz über das Grafik-Rendering bis hin zur Energieeffizienz. Mit der Ada-Lovelace-Architektur liefert er mehr als die doppelte Leistung des A40 bei deutlich geringerem Stromverbrauch. Für KI-Inferenz, Training mittlerer Größe und visualisierungsintensive Workflows ist der L40S der klare Gewinner. Der A40 kann weiterhin für ältere Setups relevant sein, die NVLink oder traditionelle Rechenworkloads erfordern.
Häufig gestellte Fragen
Welche GPU ist besser für KI-Inferenz – L40S oder A40?
L40S. Er unterstützt nativ FP8 und liefert bis zu 738 PFLOPS, was ihn für Inferenzaufgaben weitaus leistungsfähiger macht.
Kann ich L40S für KI-Training großer Modelle verwenden?
Ja, der L40S bietet 366 TFLOPS (TF32 Sparse) und eignet sich hervorragend für Training mittlerer bis großer Größe – obwohl er keine NVLink-Unterstützung bietet.
Was macht den L40S energieeffizienter?
Sie benötigen nur 1 L40S (~350 W), um die Leistung von 2,4 A40 (~720 W) zu erreichen, was die Energiekosten halbiert.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=NVIDIA A100 GPU Performance: Why It’s Still the Go-to Choice for AI Training) ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud zum Erstellen und Skalieren bereitstellt.
Empfohlene Lektüre



