

Ключевые моменты
Производительность: L40S превосходит A40 по всем показателям: эксклюзивная поддержка FP8, значительно более высокая производительность FP32/TF32, а также превосходная пропускная способность памяти и эффективность CUDA/Tensor Core.
Энергоэффективность: L40S достигает такой же или лучшей производительности при энергопотреблении примерно на 60% меньше на один GPU, а A40 не поддерживает FP8 для задач ИИ с низкой точностью.
Область применения: L40S лучше подходит для инференса ИИ, рабочих нагрузок с высокой точностью и задач визуализации, используя преимущества передовой архитектуры Ada Lovelace.

Novita AI

Runpod
Стоимость использования L40S на Novita AI примерно вдвое ниже, чем на RunPod.
NVIDIA L40S, построенный на архитектуре Ada Lovelace, является значительным обновлением по сравнению с A40. Он обеспечивает расширенные возможности инференса ИИ с нативной поддержкой FP8, превосходную графическую производительность благодаря RT-ядрам третьего поколения и улучшенную энергоэффективность. Эти улучшения делают L40S универсальным и экономически эффективным выбором для современных рабочих нагрузок в центрах обработки данных.
L40S vs A40: Сравнение архитектур
NVIDIA L40S, построенный на архитектуре Ada Lovelace, представляет собой значительный шаг вперёд по сравнению со своим предшественником на Ampere — NVIDIA A40. Оба GPU предназначены для широкого спектра рабочих нагрузок в центрах обработки данных, включая ИИ, графику и HPC, но L40S обеспечивает существенное улучшение производительности и новые функции.
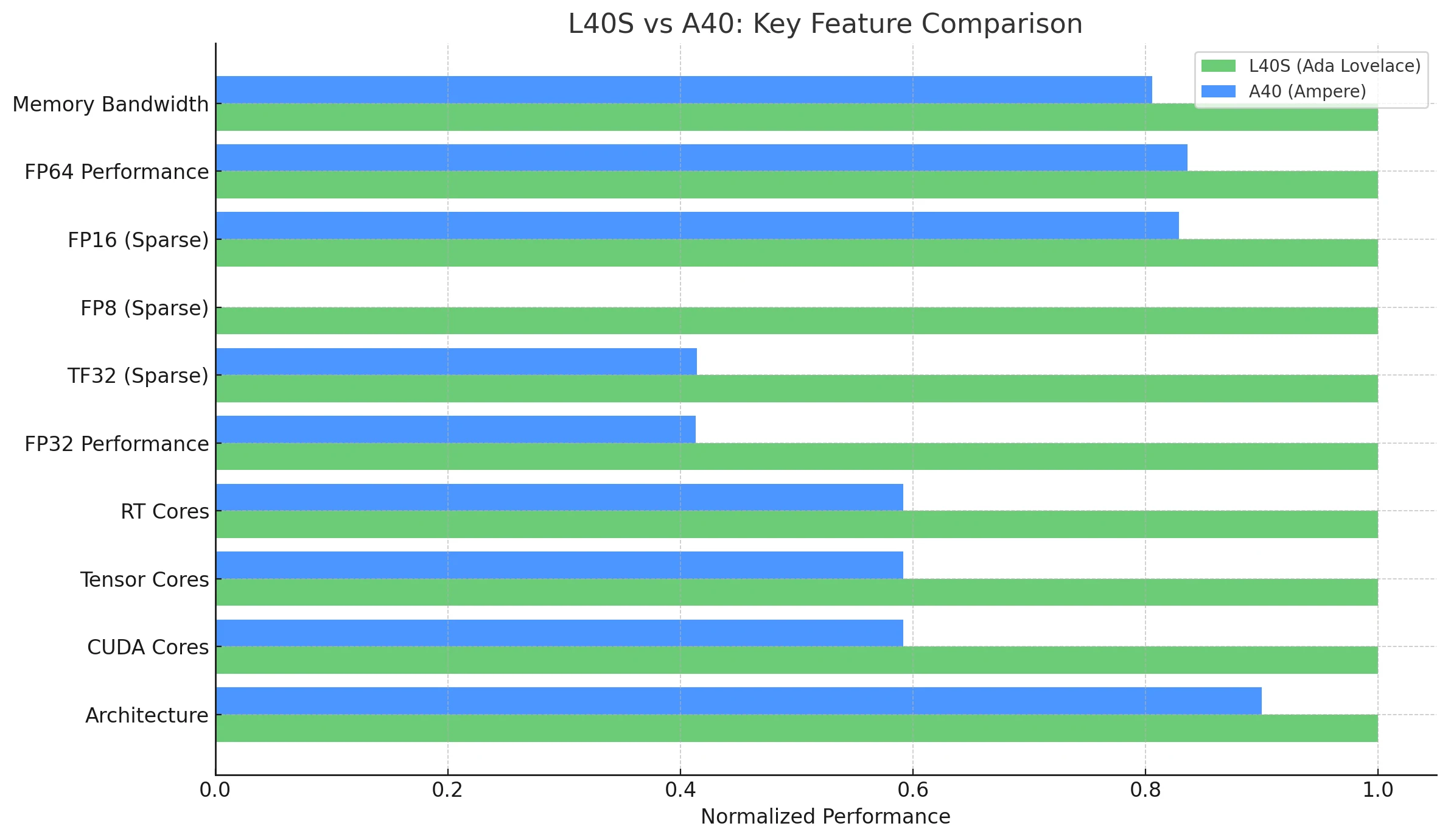
| Характеристика / Метрика | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| Архитектура | Ada Lovelace | Ampere |
| CUDA-ядра | 18 176 | 10 752 |
| Tensor-ядра | 568 (четвёртое поколение) | 336 (третье поколение) |
| RT-ядра | 142 (третье поколение) | 84 (второе поколение) |
| Производительность FP32 | 91,6 TFLOPS | 37,4 TFLOPS |
| TF32 Tensor (разреж.) | 183 | 366* |
| FP8 Tensor (разреж.) | 733 PFLOPS | Не поддерживается нативно (ограничение Ampere) |
| FP16 Tensor (разреж.) | 362,05 TFLOPS | 149,7 |
| Память GPU | 48 ГБ GDDR6 с ECC | 48 ГБ GDDR6 с ECC |
| Пропускная способность памяти | 864 ГБ/с | 696 ГБ/с |
| Энергопотребление (TDP) | 350 Вт | 300 Вт |
| Multi-Instance GPU (MIG) | Нет | Нет |
| NVLink | Нет | Да (2-канальный, 112,5 ГБ/с общая пропускная способность) |
L40S vs A40: Энергоэффективность
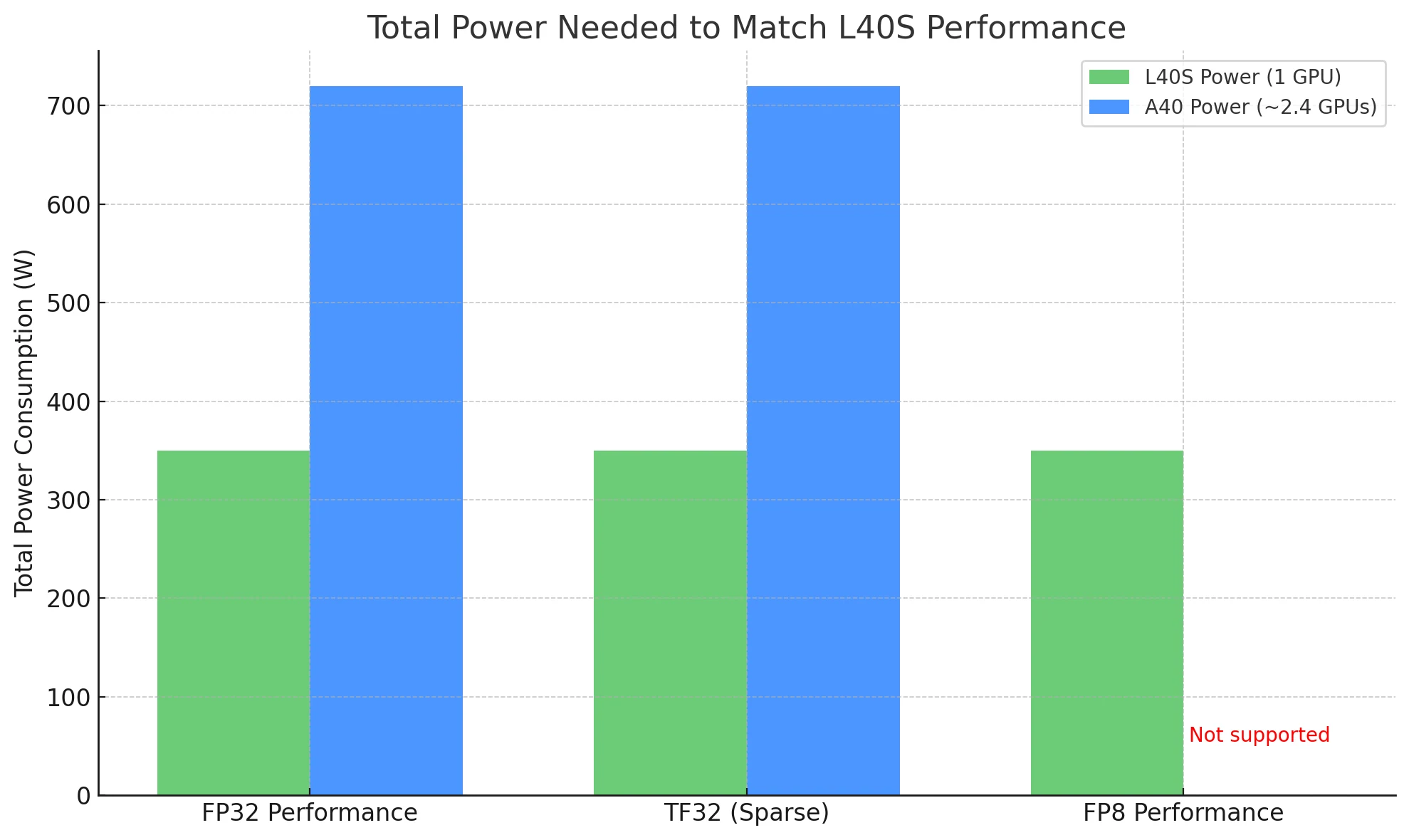
При сравнении GPU общая мощность, необходимая для выполнения одной и той же рабочей нагрузки, является более значимым показателем эффективности — и здесь L40S выделяется.
- Производительность FP32: L40S выдаёт ~91,6 TFLOPS, а A40 — ~37,4 TFLOPS — примерно в 2,4 раза больше.
- TF32 (разреж.): L40S достигает 366 TFLOPS, тогда как A40 — ~149,6 TFLOPS — снова примерно в 2,4 раза.
- Производительность FP8: L40S имеет значительное преимущество благодаря нативной поддержке FP8. A40, построенный на старой архитектуре Ampere, вообще не поддерживает FP8.
Чтобы сравняться с производительностью L40S:
- При использовании L40S: нужна всего 1 карта, потребляющая ~350 Вт.
- При использовании A40: теоретически потребуется ~2,4 карты, потребляющих в сумме ~720 Вт.
В реальных развёртываниях это означает, что L40S может обеспечить более высокую пропускную способность при вдвое меньшей мощности, что делает его гораздо более экономически эффективным и масштабируемым выбором, особенно в средах с ограничениями по мощности или в крупномасштабных средах.
L40S vs A40: Применение
Обучение и инференс ИИ
| Область | L40S | A40 |
|---|---|---|
| Обучение | Отлично подходит для обучения среднего/крупного масштаба (TF32: 366 TFLOPS), низкая стоимость, но нет NVLink. | Лучше подходит для массивных моделей с высокой пропускной способностью (TF32: 149,6 TFLOPS, NVLink). |
| Инференс | Отличная поддержка FP8 (738 PFLOPS), хорошо подходит для LLM и развёртывания. | Нет FP8; силён в FP16, BF16, INT8. |
Графика и визуализация
| Характеристика | L40S | A40 |
|---|---|---|
| CUDA-ядра | 18 176 | 10 752 |
| RT-ядра | 142 | 84 |
| Драйверы | RTX Enterprise, Omniverse, Studio-ready | Ориентированы на вычисления, ограниченный набор графических инструментов |
| Произв. FP32 | 91,6 TFLOPS | 37,4 TFLOPS |
Высокоточные рабочие нагрузки
| Характеристика | L40S | A40 |
|---|---|---|
| Использование FP64 | 1431 | 585 |
| Использование FP32 | 91,6 | 37,4 |
Рекомендация
- Выбирайте L40S, если вам нужно:
- Высокопроизводительный инференс (особенно поддержка FP8)
- Экономически эффективное обучение ИИ среднего масштаба
- Визуальные рабочие нагрузки (рендеринг, Omniverse)
- Универсальное ускорение ИИ с современной архитектурой
- Выбирайте A40, если вам нужно:
- Поддержка NVLink для многокарточного крупномасштабного обучения
- Более традиционная, вычислительно-ориентированная конфигурация без графических зависимостей
Как запустить L40S по очень низкой цене?
Novita AI предоставляет облачную платформу с высокопроизводительными GPU-инстансами. Благодаря мощным GPU, обеспечивается эффективная производительность для сложных задач, расширяется доступность развёртывания на различном оборудовании и предлагается экономичное решение по сравнению с поддержкой локального оборудования для крупномасштабных развёртываний ИИ.
Шаг 1: Зарегистрируйте аккаунт
Создайте свой аккаунт Novita AI на нашем сайте. После регистрации перейдите в раздел “Explore” в левой боковой панели, чтобы ознакомиться с нашими GPU и начать свой путь разработки ИИ.

Шаг 2:Изучение шаблонов и GPU-серверов
Выберите шаблон, например PyTorch, TensorFlow или CUDA, который соответствует потребностям вашего проекта. Затем выберите предпочтительную конфигурацию GPU — доступные варианты включают мощный L40S, RTX 4090 или A100 SXM4, каждый с различными характеристиками VRAM, RAM и хранилища.

Шаг 3: Настройте развёртывание
Настройте среду, выбрав предпочитаемую операционную систему и параметры конфигурации, чтобы обеспечить оптимальную производительность для ваших конкретных рабочих нагрузок ИИ и потребностей разработки.

Шаг 4:Запустите инстанс**
Выберите “Launch Instance”, чтобы начать развёртывание. Ваша высокопроизводительная среда GPU будет готова в течение нескольких минут, позволяя вам сразу приступить к машинному обучению, рендерингу или вычислительным проектам.

NVIDIA L40S представляет собой значительный скачок по сравнению с A40 практически во всех аспектах — от инференса FP8 до графического рендеринга и энергоэффективности. Благодаря архитектуре Ada Lovelace он обеспечивает производительность более чем в 2 раза выше, чем A40, при значительно меньшем энергопотреблении. Для инференса ИИ, обучения среднего масштаба и задач с интенсивной визуализацией L40S является явным победителем. В то же время A40 может оставаться актуальным для устаревших конфигураций, требующих NVLink, или традиционных вычислительных рабочих нагрузок.
Часто задаваемые вопросы
Какой GPU лучше для инференса ИИ — L40S или A40?
L40S. Он поддерживает нативный FP8 и выдаёт до 738 PFLOPS, что делает его гораздо более мощным для задач инференса.
Можно ли использовать L40S для крупномасштабного обучения ИИ?
Да, L40S обеспечивает 366 TFLOPS (TF32 Sparse), что отлично подходит для обучения среднего и крупного масштаба, хотя у него нет поддержки NVLink.
Что делает L40S более энергоэффективным?
Вам нужен всего 1 L40S (~350 Вт), чтобы сравняться с производительностью 2,4 A40 (~720 Вт), что вдвое сокращает затраты на электроэнергию.
Novita AI — это облачная платформа ИИ, которая предлагает разработчикам простой способ развёртывания моделей ИИ с помощью нашего простого API, а также предоставляет доступный и надёжный облачный GPU для создания и масштабирования.
Рекомендуемое чтение



