

النقاط الرئيسية
الأداء: يتفوق L40S على A40 في جميع المقاييس، مع دعم حصري لـ FP8، وأداء أعلى بكثير في FP32/TF32، وعرض نطاق ترددي للذاكرة وكفاءة CUDA/Tensor Core فائقة.
كفاءة الطاقة: يحقق L40S أداءً مكافئًا أو أفضل باستهلاك طاقة أقل بنحو 60% لكل GPU، بينما يفتقر A40 إلى دعم FP8 للمهام منخفضة الدقة في الذكاء الاصطناعي.
التركيز التطبيقي: L40S أكثر ملاءمة لاستدلال الذكاء الاصطناعي، أعباء العمل الدقيقة، ومهام التصور، مستفيدًا من بنية Ada Lovelace المتقدمة.

Novita AI

Runpod
تبلغ تكلفة استخدام L40S على Novita AI حوالي نصف سعر RunPod.
يمثل NVIDIA L40S، المبني على بنية Ada Lovelace، ترقية كبيرة مقارنة بـ A40. يقدم قدرات محسنة لاستدلال الذكاء الاصطناعي مع دعم أصلي لـ FP8، وأداء رسومات فائق بفضل أنوية RT من الجيل الثالث، وكفاءة طاقة محسنة. هذه التطورات تجعل L40S خيارًا متعدد الاستخدامات وفعالًا من حيث التكلفة لأعباء عمل مراكز البيانات الحديثة.
L40S مقابل A40: مقارنة البنية
يمثل NVIDIA L40S، المبني على بنية Ada Lovelace، خطوة كبيرة إلى الأمام مقارنة بسابقه القائم على Ampere، NVIDIA A40. تم تصميم كل من GPU لمجموعة واسعة من أعباء عمل مراكز البيانات، بما في ذلك الذكاء الاصطناعي، الرسومات، والحوسبة عالية الأداء، لكن L40S يجلب تحسينات كبيرة في الأداء وميزات جديدة.
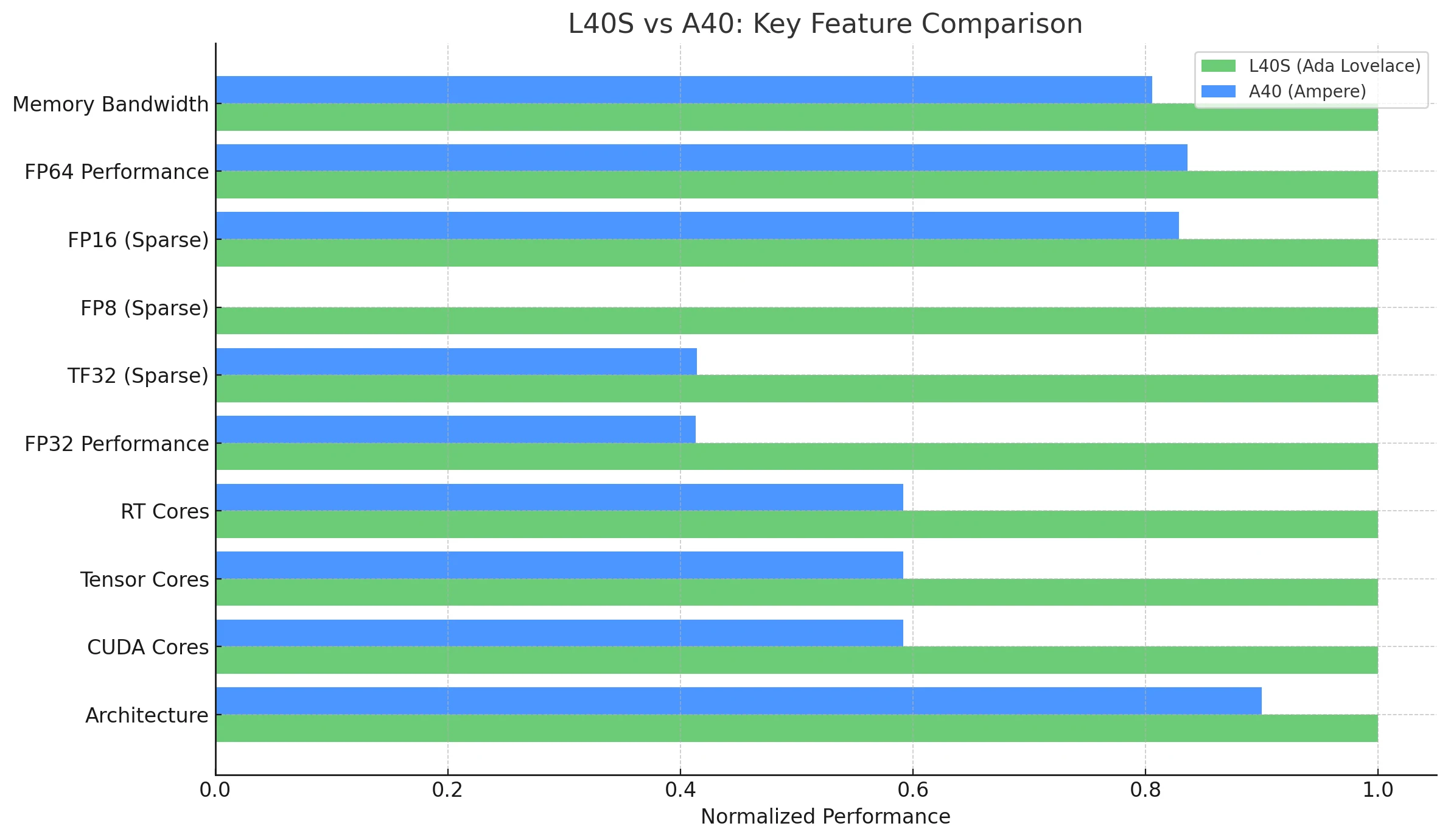
| الميزة / المقياس | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| البنية | Ada Lovelace | Ampere |
| أنوية CUDA | 18,176 | 10,752 |
| أنوية Tensor | 568 (الجيل الرابع) | 336 (الجيل الثالث) |
| أنوية RT | 142 (الجيل الثالث) | 84 (الجيل الثاني) |
| أداء FP32 | 91.6 TFLOPS | 37.4 TFLOPS |
| TF32 Tensor (متناثر) | 183 | 366* | 74.8 | 149.6* |
| FP8 Tensor (متناثر) | 733 PFLOPS | غير مدعوم أصلاً (قيود Ampere) |
| FP16 Tensor (متناثر) | 362.05 TFLOPS | 149.7 | 299.4* |
| ذاكرة GPU | 48GB GDDR6 مع ECC | 48GB GDDR6 مع ECC |
| عرض النطاق الترددي للذاكرة | 864GB/s | 696 GB/s |
| استهلاك الطاقة (TDP) | 350W | 300W |
| GPU متعدد الحالات (MIG) | لا | لا |
| NVLink | لا | نعم (ثنائي، 112.5 GB/s إجمالي النطاق الترددي) |
L40S مقابل A40: كفاءة الطاقة
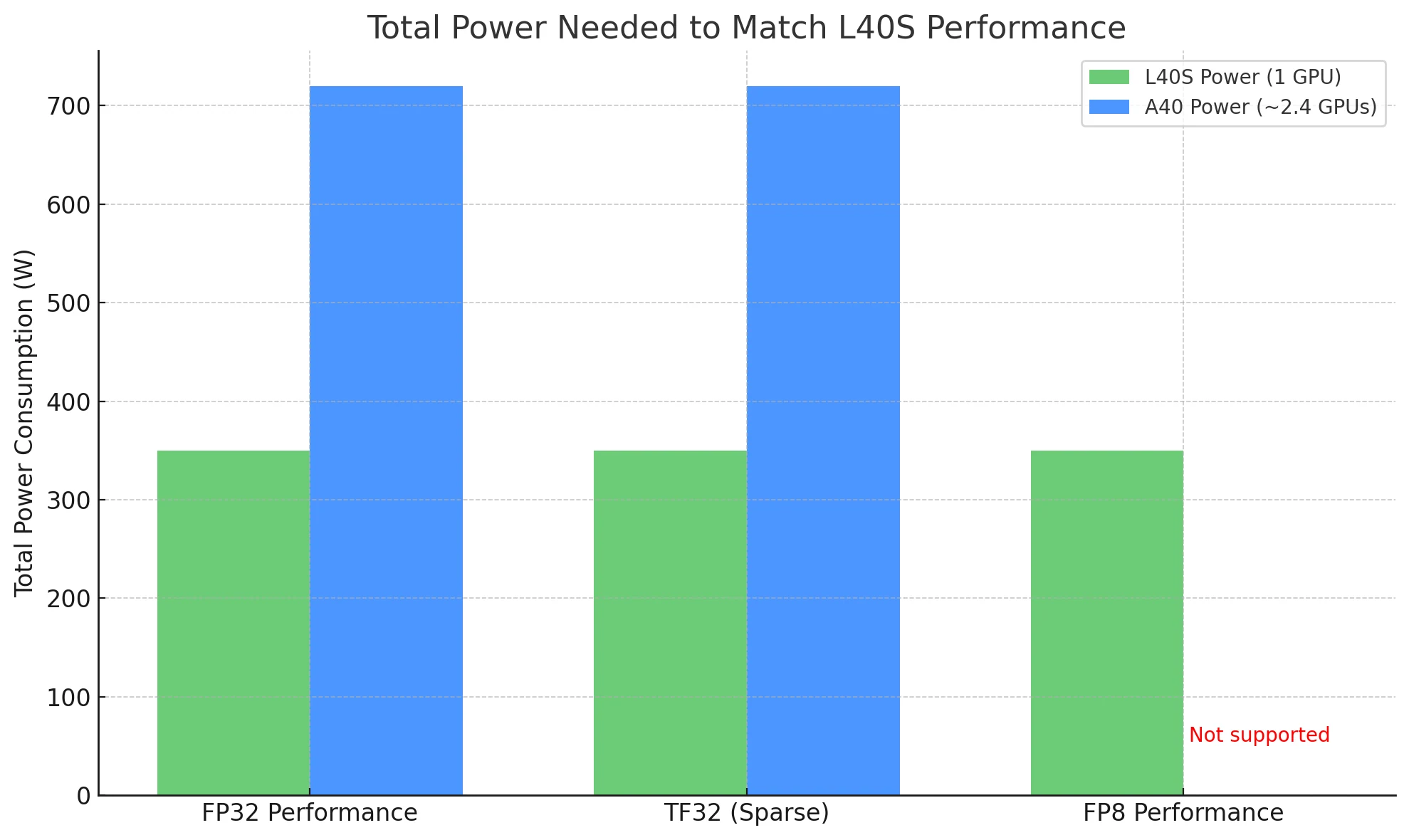
عند مقارنة معالجات GPU، فإن إجمالي الطاقة المطلوبة لإنجاز نفس عبء العمل هو مقياس أكثر دلالة للكفاءة – وهنا يبرز L40S.
- أداء FP32: يقدم L40S ~91.6 TFLOPS، بينما يقدم A40 ~37.4 TFLOPS – أي أداء أعلى بنحو 2.4 مرة.
- TF32 (متناثر): يصل L40S إلى 366 TFLOPS، مقابل ~149.6 TFLOPS لـ A40 – أي حوالي 2.4 مرة من الناتج.
- أداء FP8: يتمتع L40S بميزة كبيرة، حيث يوفر دعمًا أصليًا لـ FP8. أما A40، المبني على بنية Ampere الأقدم، فلا يدعم FP8 على الإطلاق.
لمطابقة أداء L40S:
- باستخدام L40S: تحتاج فقط إلى بطاقة واحدة، تستهلك ~350W.
- باستخدام A40: ستحتاج نظريًا إلى ~2.4 بطاقة، بإجمالي ~720W من الطاقة.
في النشر الفعلي، يعني هذا أن L40S يمكنه تقديم إنتاجية أعلى بنصف الطاقة، مما يجعله خيارًا أكثر فعالية من حيث التكلفة وقابلية للتوسع، خاصة في البيئات الحساسة للطاقة أو واسعة النطاق.
L40S مقابل A40: التطبيقات
تدريب واستدلال الذكاء الاصطناعي
| المجال | L40S | A40 |
|---|---|---|
| التدريب | ممتاز للتدريب متوسط/كبير الحجم (TF32: 366TFLOPS)، تكلفة أقل، لكن يفتقر إلى NVLink. | أفضل للنماذج الضخمة ذات النطاق الترددي العالي (TF32: 149.6TFLOPS، NVLink). |
| الاستدلال | دعم ممتاز لـ FP8 (738 PFLOPS)، قوي لنماذج LLM والنشر. | لا يدعم FP8؛ قوي في FP16، BF16، INT8. |
الرسومات والتصور
| الميزة | L40S | A40 |
|---|---|---|
| أنوية CUDA | 18,176 | 10752 |
| أنوية RT | 142 | 84 |
| برامج التشغيل | جاهز لـ RTX Enterprise، Omniverse، Studio | مركز على الحوسبة، أدوات رسومات محدودة |
| أداء FP32 | 91.6 TFLOPS | 37.4 TFLOPS |
أعباء العمل الدقيقة
| الميزة | L40S | A40 |
|---|---|---|
| استخدام FP64 | 1431 | 585 |
| استخدام FP32 | 91.6 | 37.4 |
التوصية
- اختر L40S إذا كنت بحاجة إلى:
- استدلال عالي الإنتاجية (خاصة دعم FP8)
- تدريب فعال من حيث التكلفة للذكاء الاصطناعي متوسط الحجم
- أعباء عمل بصرية (تصيير، Omniverse)
- تسريع عام للذكاء الاصطناعي ببنية حديثة
- اختر A40 إذا كنت بحاجة إلى:
- دعم NVLink للتدريب متعدد GPU على نطاق واسع
- إعداد تقليدي مركز على الحوسبة دون اعتماد على الرسومات
كيفية تشغيل L40S بسعر منخفض جدًا؟
توفر Novita AI منصة سحابية مع حالات GPU عالية الأداء. بفضل معالجات GPU القوية، تضمن أداءً فعالاً للمهام المعقدة، وتعزز إمكانية الوصول للنشر عبر أجهزة متنوعة، وتقدم حلاً فعالاً من حيث التكلفة مقارنة بصيانة الأجهزة المحلية لنشر الذكاء الاصطناعي على نطاق واسع.
الخطوة 1: تسجيل حساب
أنشئ حساب Novita AI الخاص بك عبر موقعنا الإلكتروني. بعد التسجيل، انتقل إلى قسم “استكشاف” في الشريط الجانبي الأيسر لعرض عروض GPU الخاصة بنا وابدأ رحلة تطوير الذكاء الاصطناعي.

الخطوة 2: استكشاف القوالب وخوادم GPU
اختر من بين القوالب مثل PyTorch أو TensorFlow أو CUDA التي تناسب احتياجات مشروعك. ثم حدد تكوين GPU المفضل لديك—تتضمن الخيارات L40S القوي، RTX 4090 أو A100 SXM4، ولكل منها مواصفات مختلفة من VRAM وRAM والتخزين.

الخطوة 3: تخصيص النشر الخاص بك
خصص بيئتك عن طريق اختيار نظام التشغيل المفضل لديك وخيارات التكوين لضمان الأداء الأمثل لأعباء عمل الذكاء الاصطناعي واحتياجات التطوير الخاصة بك.

الخطوة 4: تشغيل الحالة
اختر “تشغيل الحالة” لبدء النشر الخاص بك. ستكون بيئة GPU عالية الأداء جاهزة في غضون دقائق، مما يسمح لك بالبدء فورًا في مشاريع التعلم الآلي أو التصيير أو الحوسبة.

يمثل NVIDIA L40S قفزة كبيرة مقارنة بـ A40 في كل جانب تقريبًا—من استدلال FP8 إلى تصيير الرسومات وكفاءة الطاقة. مع بنية Ada Lovelace، يقدم أكثر من ضعف أداء A40 مع استهلاك طاقة أقل بكثير. بالنسبة لاستدلال الذكاء الاصطناعي، التدريب متوسط الحجم، وأعباء العمل المكثفة بالتصور، فإن L40S هو الفائز الواضح. في الوقت نفسه، قد يظل A40 ملائمًا للإعدادات القديمة التي تتطلب NVLink أو أعباء العمل الحاسوبية التقليدية.
الأسئلة الشائعة
أي GPU أفضل لاستدلال الذكاء الاصطناعي—L40S أم A40؟
L40S. يدعم FP8 الأصلي ويوفر ما يصل إلى 738 PFLOPS، مما يجعله أكثر قوة لمهام الاستدلال.
هل يمكنني استخدام L40S لتدريب الذكاء الاصطناعي على نطاق واسع؟
نعم، يوفر L40S 366 TFLOPS (TF32 متناثر)، مما يجعله ممتازًا للتدريب متوسط إلى كبير الحجم—على الرغم من افتقاره لدعم NVLink.
ما الذي يجعل L40S أكثر كفاءة في استهلاك الطاقة؟
تحتاج فقط إلى 1 L40S (~350W) لمطابقة أداء 2.4 A40 (~720W)، مما يقلل تكاليف الطاقة إلى النصف.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=NVIDIA A100 GPU Performance: Why It’s Still the Go-to Choice for AI Training) هي منصة سحابية للذكاء الاصطناعي تقدم للمطورين طريقة سهلة لنشر نماذج الذكاء الاصطناعي باستخدام واجهة برمجة التطبيقات البسيطة الخاصة بنا، مع توفير GPU سحابي ميسور التكلفة وموثوق للبناء والتوسع.
قراءة موصى بها



