

Destaques Principais
Desempenho: L40S supera A40 em todas as métricas, com suporte exclusivo a FP8, desempenho FP32/TF32 significativamente maior e largura de banda de memória e eficiência CUDA/Tensor Core superiores.
Eficiência Energética: L40S alcança desempenho equivalente ou melhor com ~60% menos energia por GPU, enquanto A40 carece de suporte FP8 para tarefas de IA de baixa precisão.
Foco de Aplicação: L40S é mais adequado para inferência de IA, cargas de trabalho de precisão e tarefas de visualização, aproveitando a arquitetura Ada Lovelace avançada.

Novita AI

Runpod
O custo de usar L40S na Novita AI é aproximadamente metade do preço do RunPod.
O NVIDIA L40S, construído sobre a arquitetura Ada Lovelace, é uma atualização significativa em relação ao A40. Ele oferece recursos aprimorados de inferência de IA com suporte nativo a FP8, desempenho gráfico superior devido aos RT Cores de terceira geração e eficiência energética melhorada. Esses avanços tornam o L40S uma escolha versátil e econômica para cargas de trabalho modernas em data centers.
L40S vs A40: Comparação de Arquitetura
O NVIDIA L40S, baseado na arquitetura Ada Lovelace, representa um avanço significativo em relação ao seu antecessor baseado em Ampere, o NVIDIA A40. Ambas as GPUs são projetadas para uma ampla gama de cargas de trabalho em data centers, incluindo IA, gráficos e HPC, mas o L40S traz melhorias substanciais de desempenho e novos recursos.
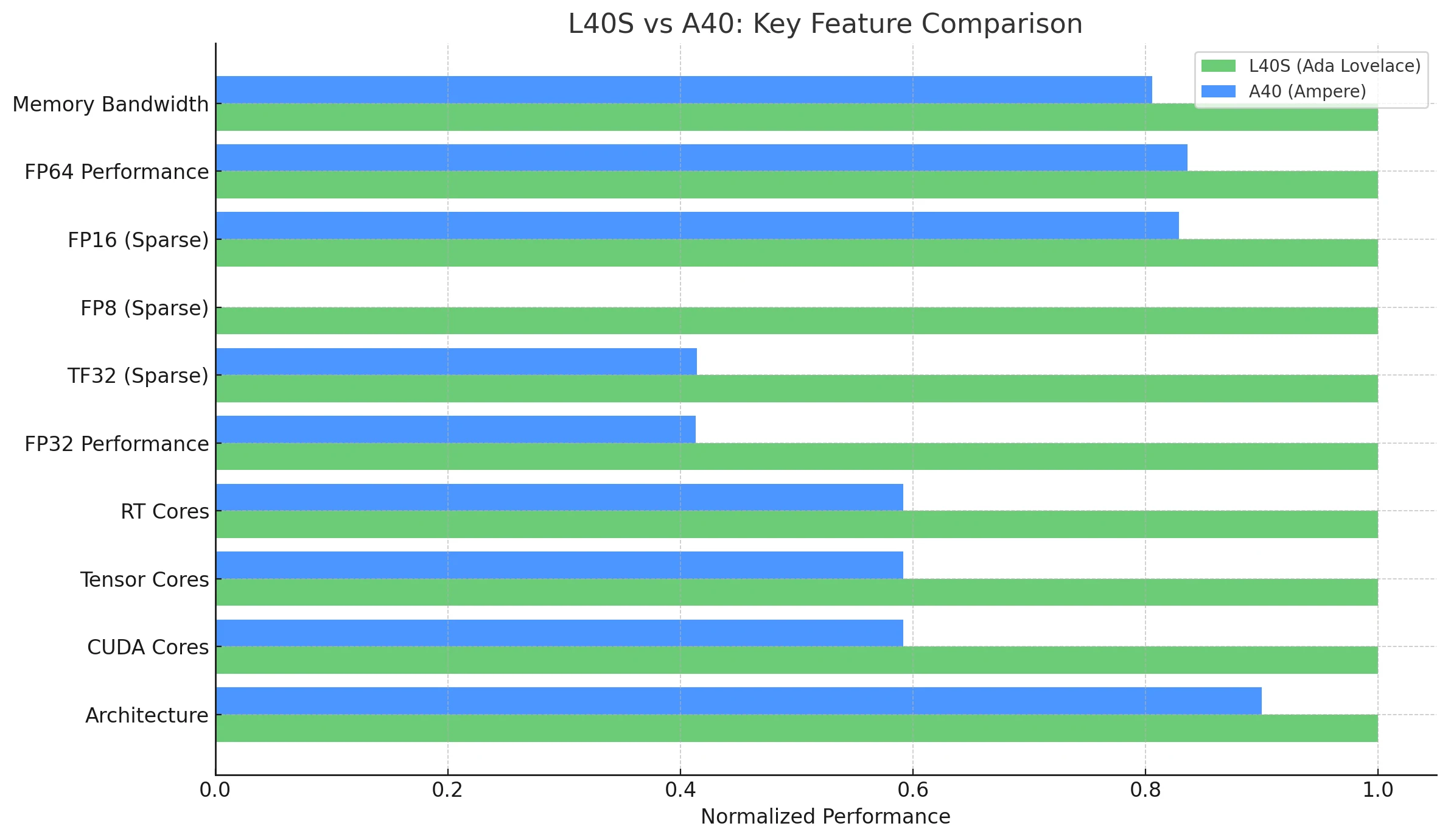
| Recurso / Métrica | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| Arquitetura | Ada Lovelace | Ampere |
| Núcleos CUDA | 18.176 | 10.752 |
| Núcleos Tensor | 568 (Quarta Geração) | 336 (Terceira Geração) |
| Núcleos RT | 142 (Terceira Geração) | 84 (Segunda Geração) |
| Desempenho FP32 | 91,6 TFLOPS | 37,4 TFLOPS |
| Tensor TF32 (Esparso) | 183 | 366* | 74,8 | 149,6* |
| Tensor FP8 (Esparso) | 733 PFLOPS | Sem suporte nativo (limitação Ampere) |
| Tensor FP16 (Esparso) | 362,05 TFLOPS | 149,7 | 299,4* |
| Memória GPU | 48 GB GDDR6 com ECC | 48 GB GDDR6 com ECC |
| Largura de banda da memória | 864 GB/s | 696 GB/s |
| Consumo de Energia (TDP) | 350 W | 300 W |
| GPU Multi-Instância (MIG) | Não | Não |
| NVLink | Não | Sim (bidirecional, 112,5 GB/s de largura de banda total) |
L40S vs A40: Eficiência Energética
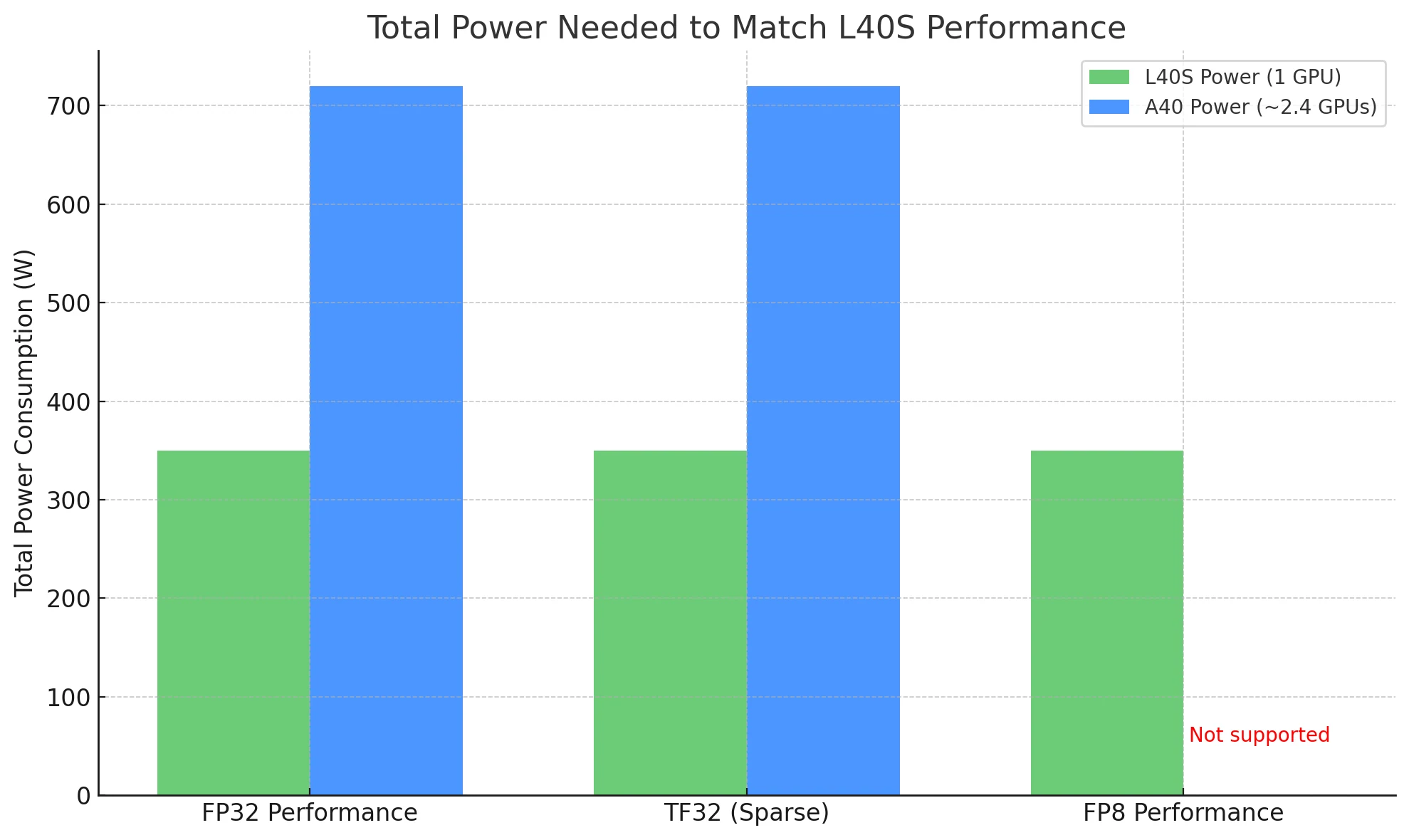
Ao comparar GPUs, a potência total necessária para realizar a mesma carga de trabalho é uma medida mais significativa de eficiência — e é aqui que o L40S se destaca.
- Desempenho FP32: L40S entrega ~91,6 TFLOPS, enquanto A40 oferece ~37,4 TFLOPS — aproximadamente 2,4× mais desempenho.
- TF32 (Esparso): L40S atinge 366 TFLOPS, contra ~149,6 TFLOPS do A40 — novamente, cerca de 2,4× a saída.
- Desempenho FP8: L40S tem uma vantagem significativa, oferecendo suporte nativo a FP8. O A40, construído na arquitetura Ampere mais antiga, não suporta FP8 de forma alguma.
Para igualar o desempenho do L40S:
- Usando L40S: Você precisa apenas de 1 placa, consumindo ~350 W.
- Usando A40: Teoricamente, você precisaria de ~2,4 placas, totalizando ~720 W de potência.
Em implantações do mundo real, isso significa que L40S pode entregar maior throughput com metade da energia, tornando-o uma escolha muito mais econômica e escalável, especialmente em ambientes sensíveis a energia ou de grande escala.
L40S vs A40: Aplicações
Treinamento e Inferência de IA
| Área | L40S | A40 |
|---|---|---|
| Treinamento | Ótimo para treinamento de médio/grande porte (TF32: 366 TFLOPS), menor custo, mas sem NVLink. | Melhor para modelos massivos com alta largura de banda (TF32: 149,6 TFLOPS, NVLink). |
| Inferência | Excelente suporte FP8 (738 PFLOPS), forte para LLMs e implantação. | Sem FP8; forte em FP16, BF16, INT8. |
Gráficos e Visualização
| Recurso | L40S | A40 |
|---|---|---|
| Núcleos CUDA | 18.176 | 10.752 |
| Núcleos RT | 142 | 84 |
| Drivers | RTX Enterprise, Omniverse, Studio ready | Focado em computação, ferramentas gráficas limitadas |
| Desempenho FP32 | 91,6 TFLOPS | 37,4 TFLOPS |
Cargas de Trabalho de Precisão
| Recurso | L40S | A40 |
|---|---|---|
| Uso FP64 | 1431 | 585 |
| Uso FP32 | 91,6 | 37,4 |
Recomendação
- Escolha L40S se precisar de:
- Inferência de alto throughput (especialmente suporte FP8)
- Treinamento de IA de médio porte com boa relação custo-benefício
- Cargas visuais (renderização, Omniverse)
- Aceleração de IA de uso geral com arquitetura moderna
- Escolha A40 se precisar de:
- Suporte NVLink para treinamento multi-GPU em larga escala
- Uma configuração mais tradicional e focada em computação, sem dependências gráficas
Como executar L40S a um preço muito baixo?
A Novita AI fornece uma plataforma baseada em nuvem com instâncias GPU de alto desempenho. Com GPUs poderosas, garante desempenho eficiente para tarefas complexas, melhora a acessibilidade para implantação em vários hardwares e oferece uma solução econômica em comparação com a manutenção de hardware local para implantações de IA em larga escala.
Passo 1: Crie uma conta
Crie sua conta na Novita AI através do nosso site. Após o registro, navegue até a seção “Explorar” na barra lateral esquerda para ver nossas ofertas de GPU e iniciar sua jornada de desenvolvimento de IA.

Passo 2: Explore Modelos e Servidores GPU
Escolha entre modelos como PyTorch, TensorFlow ou CUDA que correspondam às necessidades do seu projeto. Em seguida, selecione sua configuração de GPU preferida — as opções incluem a potente L40S, RTX 4090 ou A100 SXM4, cada uma com diferentes especificações de VRAM, RAM e armazenamento.

Passo 3: Personalize sua Implantação
Personalize seu ambiente selecionando seu sistema operacional preferido e opções de configuração para garantir o desempenho ideal para suas cargas de trabalho específicas de IA e necessidades de desenvolvimento.

Passo 4: Inicie uma instância
Selecione “Iniciar Instância” para começar sua implantação. Seu ambiente GPU de alto desempenho estará pronto em minutos, permitindo que você inicie imediatamente seus projetos de aprendizado de máquina, renderização ou computação.

O NVIDIA L40S representa um grande salto em relação ao A40 em quase todos os aspectos — desde inferência FP8 até renderização gráfica e eficiência energética. Com a arquitetura Ada Lovelace, ele entrega mais de 2x o desempenho do A40 enquanto consome significativamente menos energia. Para inferência de IA, treinamento de médio porte e fluxos de trabalho com muita visualização, o L40S é o vencedor claro. Enquanto isso, o A40 ainda pode ser relevante para configurações legadas que exigem NVLink ou cargas de trabalho tradicionais de computação.
Perguntas Frequentes
Qual GPU é melhor para inferência de IA — L40S ou A40?
L40S. Ele suporta FP8 nativo e oferece até 738 PFLOPS, tornando-o muito mais poderoso para tarefas de inferência.
Posso usar L40S para treinamento de IA em larga escala?
Sim, o L40S oferece 366 TFLOPS (TF32 Esparso), sendo ótimo para treinamento de médio a grande porte — embora não tenha suporte NVLink.
O que torna o L40S mais eficiente em termos energéticos?
Você precisa de apenas 1 L40S (~350 W) para igualar o desempenho de 2,4 A40s (~720 W), reduzindo os custos de energia pela metade.
Novita AI é uma plataforma de nuvem de IA que oferece aos desenvolvedores uma maneira fácil de implantar modelos de IA usando nossa API simples, além de fornecer a nuvem GPU acessível e confiável para construir e escalar.
Leitura Recomendada



