

주요 하이라이트
성능 : L40S는 모든 지표에서 A40를 능가하며, 전용 FP8 지원, 현저히 높은 FP32/TF32 성능, 우수한 메모리 대역폭 및 CUDA/Tensor Core 효율성을 제공합니다.
전력 효율 : L40S는 GPU당 약 60% 적은 전력으로 동등하거나 더 나은 성능을 달성하는 반면, A40는 저정밀 AI 작업을 위한 FP8 지원이 부족합니다.
애플리케이션 초점 : L40S는 고급 Ada Lovelace 아키텍처를 활용하여 AI 추론, 정밀 워크로드, 시각화 작업에 더 적합합니다.

Novita AI

Runpod
Novita AI에서 L40S를 사용하는 비용은 RunPod 가격의 약 절반입니다.
NVIDIA L40S는 Ada Lovelace 아키텍처를 기반으로 제작되어 A40보다 크게 업그레이드되었습니다. 기본 FP8 지원으로 향상된 AI 추론 기능, 3세대 RT Core 덕분에 뛰어난 그래픽 성능, 개선된 전력 효율성을 제공합니다. 이러한 발전으로 L40S는 현대 데이터 센터 워크로드를 위한 다재다능하고 비용 효율적인 선택이 되었습니다.
L40S 대 A40: 아키텍처 비교
NVIDIA L40S는 Ada Lovelace 아키텍처를 기반으로 제작되어 Ampere 기반의 이전 모델인 NVIDIA A40보다 크게 발전했습니다. 두 GPU 모두 AI, 그래픽, HPC를 포함한 다양한 데이터 센터 워크로드를 위해 설계되었지만, L40S는 상당한 성능 향상과 새로운 기능을 제공합니다.
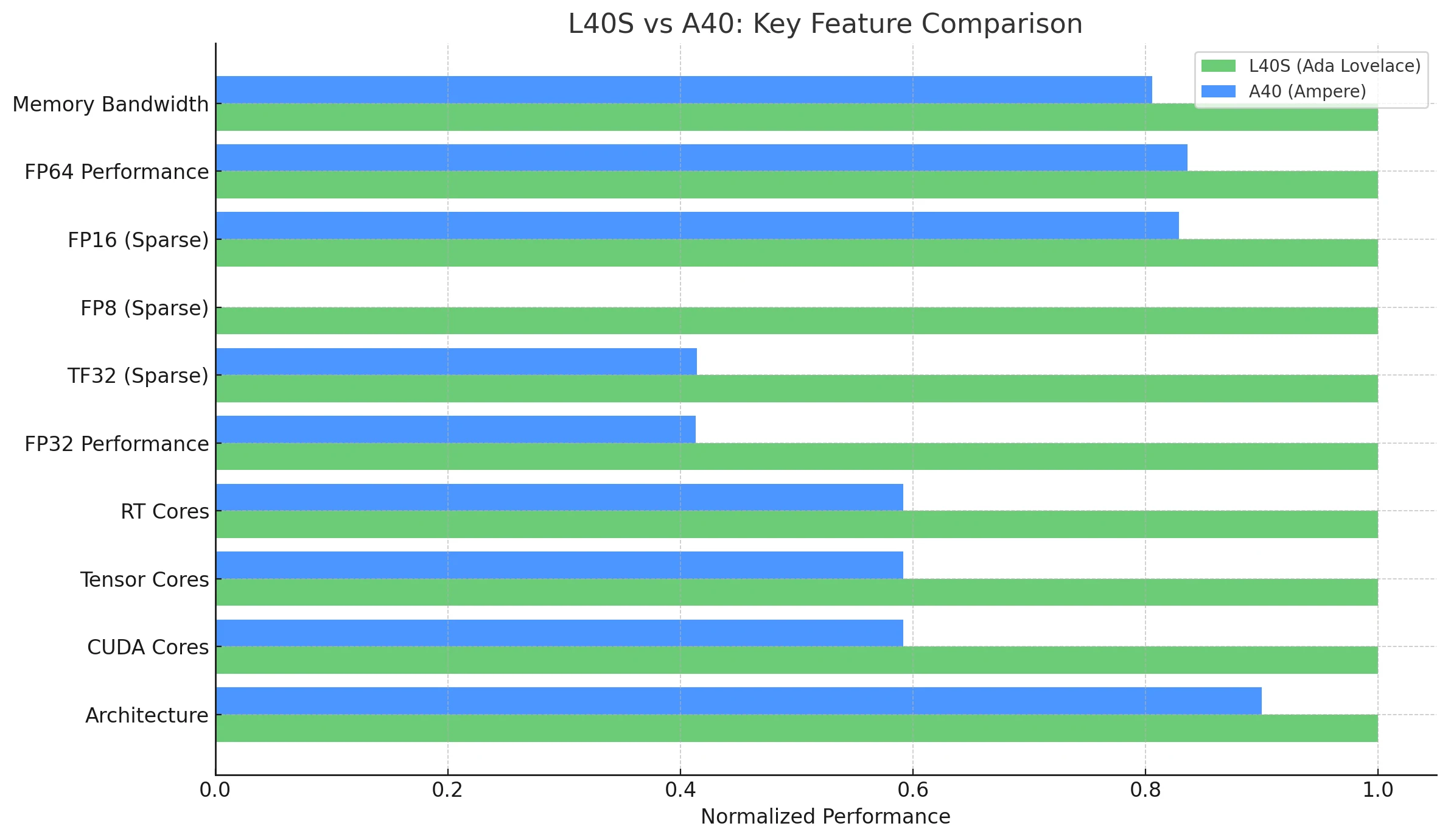
| 기능/지표 | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| **아키텍처 ** | Ada Lovelace | Ampere |
| **CUDA 코어 ** | 18,176 | 10,752 |
| **텐서 코어 ** | 568 (4세대) | 336 (3세대) |
| **RT 코어 ** | 142 (3세대) | 84 (2세대) |
| **FP32 성능 ** | 91.6 TFLOPS | 37.4 TFLOPS |
| TF32 텐서 (희소) | 183 | 366* | 74.8 | 149.6* |
| FP8 텐서 (희소) | 733 PFLOPS | 기본 미지원 (Ampere 한계) |
| FP16 텐서 (희소) | 362.05TFLOPS | 149.7 | 299.4* |
| GPU 메모리 | 48GB GDDR6 (ECC) | 48GB GDDR6 (ECC) |
| **메모리 대역폭 ** | 864GB/s | 696 GB/s |
| 전력 소비 (TDP) | 350W | 300W |
| MIG | 아니요 | 아니요 |
| NVLink | 아니요 | 예 (2-way, 총 112.5 GB/s 대역폭) |
L40S 대 A40: 전력 효율성
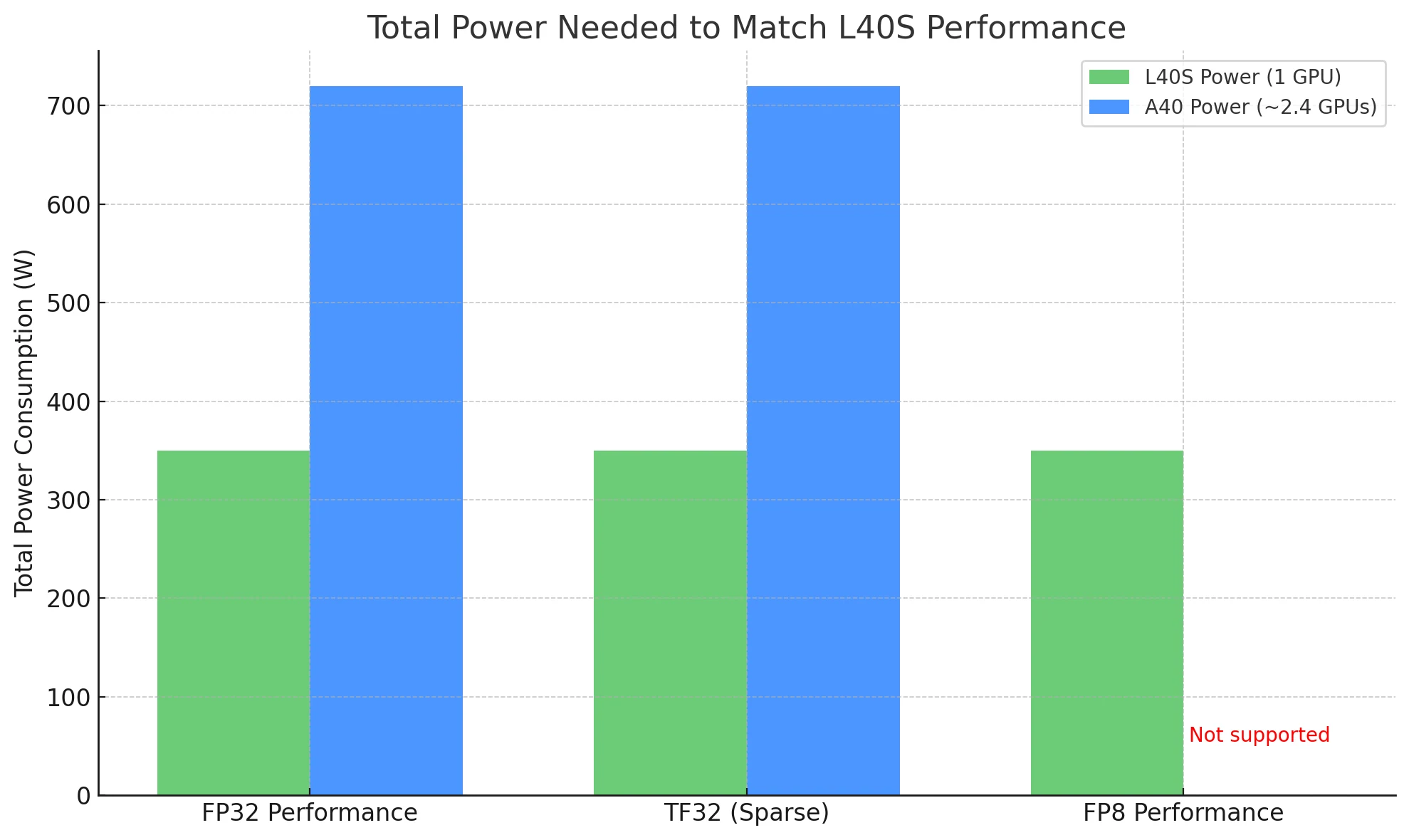
GPU를 비교할 때 동일한 워크로드를 달성하는 데 필요한 총 전력이 효율성을 측정하는 더 의미 있는 지표이며, 바로 이 부분에서 L40S 가 두드러집니다.
- **FP32 성능 **: L40S는 ~91.6 TFLOPS 를 제공하는 반면 A40는 ~37.4 TFLOPS — 약 2.4배 더 높은 성능입니다.
- TF32 (희소): L40S는 366 TFLOPS 에 도달하는 반면 A40는 ~149.6 TFLOPS — 역시 약 2.4배 출력입니다.
- **FP8 성능 **: L40S는 ** 상당한 이점 **을 가지며 ** 기본 FP8 지원 **을 제공합니다. 이전 Ampere 아키텍처를 기반으로 한 A40는 FP8을 전혀 지원하지 않습니다.
L40S 성능에 맞추려면:
- **L40S 사용 **: **1개 카드 ** 만 필요하며, ~350W 를 소비합니다.
- **A40 사용 **: 이론적으로 **~2.4개 카드 ** 가 필요하며, 총 ~720W 의 전력을 소비합니다.
실제 배포에서는 **L40S가 절반 전력으로 더 높은 처리량 ** 을 제공할 수 있으므로, 특히 전력에 민감하거나 대규모 환경에서 훨씬 더 비용 효율적이고 확장 가능한 선택 이 됩니다.
L40S 대 A40: 애플리케이션
AI 훈련 및 추론
| 영역 | L40S | A40 |
|---|---|---|
| 훈련 | 중/대규모 훈련에 적합 (TF32: 366TFLOPS), 비용 낮음, NVLink 부족. | NVLink로 대규모 모델에 더 적합 (TF32: 149.6TFLOPS). |
| 추론 | 뛰어난 FP8 지원 (738 PFLOPS), LLM 및 배포에 강력. | FP8 없음; FP16, BF16, INT8에서 강력. |
그래픽 및 시각화
| 기능 | L40S | A40 |
|---|---|---|
| CUDA 코어 | 18,176 | 10752 |
| RT 코어 | 142 | 84 |
| 드라이버 | RTX Enterprise, Omniverse, Studio 준비 | 컴퓨트 중심, 제한된 그래픽 도구 |
| FP32 성능 | 91.6 TFLOPS | 37.4 TFLOPS |
정밀 워크로드
| 기능 | L40S | A40 |
|---|---|---|
| FP64 사용량 | 1431 | 585 |
| FP32 사용량 | 91.6 | 37.4 |
권장 사항
- L40S 를 선택하세요:
- 높은 처리량의 추론 (특히 FP8 지원)
- 비용 효율적인 중간 규모 AI 훈련
- 시각적 워크로드 (렌더링, Omniverse)
- 현대 아키텍처를 활용한 범용 AI 가속
- A40 를 선택하세요:
- 대규모 다중 GPU 훈련을 위한 NVLink 지원 필요
- 그래픽 의존성 없는 기존의 컴퓨트 중심 설정
L40S를 매우 저렴한 가격에 사용하는 방법?
Novita AI는 고성능 GPU 인스턴스를 제공하는 클라우드 기반 플랫폼입니다. 강력한 GPU를 통해 복잡한 작업에 효율적인 성능을 보장하고, 다양한 하드웨어에서 배포 접근성을 향상시키며, 대규모 AI 배포를 위한 로컬 하드웨어 유지 관리에 비해 비용 효율적인 솔루션을 제공합니다.
1단계: 계정 등록
웹사이트를 통해 Novita AI 계정을 만드세요. 등록 후 왼쪽 사이드바에서 ‘탐색’ 섹션으로 이동하여 GPU 제공 항목을 확인하고 AI 개발 여정을 시작하세요.

2단계: 템플릿 및 GPU 서버 탐색
프로젝트 요구 사항에 맞는 PyTorch, TensorFlow 또는 CUDA와 같은 템플릿을 선택하세요. 그런 다음 원하는 GPU 구성을 선택하세요. 강력한 L40S, RTX 4090 또는 A100 SXM4와 같은 옵션이 있으며, 각각 다른 VRAM, RAM 및 스토리지 사양을 제공합니다.

3단계: 배포 맞춤 설정
원하는 운영 체제 및 구성 옵션을 선택하여 특정 AI 워크로드 및 개발 요구에 최적의 성능을 보장하도록 환경을 사용자 지정하세요.

4단계: 인스턴스 시작
'인스턴스 시작’을 선택하여 배포를 시작하세요. 고성능 GPU 환경이 몇 분 내에 준비되어 머신러닝, 렌더링 또는 계산 프로젝트를 즉시 시작할 수 있습니다.

NVIDIA L40S 는 FP8 추론부터 그래픽 렌더링, 전력 효율성에 이르기까지 거의 모든 측면에서 A40보다 큰 도약을 나타냅니다. Ada Lovelace 아키텍처를 통해 A40보다 **2배 이상의 성능 ** 을 제공하면서도 전력 소비는 크게 낮춥니다. AI 추론, 중간 규모 훈련, 시각화 중심 워크플로우의 경우 L40S가 확실한 승자입니다. 반면 A40는 NVLink 가 필요한 레거시 설정이나 기존 컴퓨트 워크로드에서 여전히 유용할 수 있습니다.
자주 묻는 질문
AI 추론에 더 적합한 GPU는 L40S와 A40 중 무엇인가요?
L40S입니다. 기본 FP8을 지원하며 최대 738 PFLOPS 를 제공하므로 추론 작업에 훨씬 더 강력합니다.
L40S를 대규모 AI 훈련에 사용할 수 있나요?
네, L40S는 366 TFLOPS (TF32 희소) 를 제공하므로 중대규모 훈련에 적합하지만 NVLink 지원은 부족합니다.
L40S가 더 전력 효율적인 이유는 무엇인가요?
L40S 1개 (~350W) 만으로 A40 2.4개 (~720W) 의 성능을 맞출 수 있어 에너지 비용을 절반으로 줄입니다.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=NVIDIA A100 GPU Performance: Why It’s Still the Go-to Choice for AI Training)는 개발자가 간단한 API를 사용하여 AI 모델을 쉽게 배포할 수 있는 AI 클라우드 플랫폼이며, 구축 및 확장을 위한 저렴하고 안정적인 GPU 클라우드를 제공합니다.
추천 자료



