

Aspectos destacados
Rendimiento: L40S supera a A40 en todas las métricas, con soporte exclusivo para FP8, rendimiento significativamente superior en FP32/TF32, y mayor ancho de banda de memoria y eficiencia de CUDA/Tensor Core.
Eficiencia energética: L40S logra un rendimiento equivalente o superior con ~60 % menos de energía por GPU, mientras que A40 carece de soporte FP8 para tareas de IA de baja precisión.
Enfoque de aplicación: L40S es más adecuado para inferencia de IA, cargas de trabajo de precisión y tareas de visualización, aprovechando la arquitectura avanzada Ada Lovelace.

Novita AI

Runpod
El costo de usar L40S en Novita AI es aproximadamente la mitad del precio de RunPod.
La NVIDIA L40S, construida sobre la arquitectura Ada Lovelace, es una mejora significativa respecto a la A40. Ofrece capacidades mejoradas de inferencia de IA con soporte nativo para FP8, rendimiento gráfico superior gracias a los RT Cores de tercera generación y una eficiencia energética mejorada. Estas ventajas hacen de la L40S una opción versátil y rentable para las cargas de trabajo modernas en centros de datos.
L40S vs A40: Comparación de arquitectura
La NVIDIA L40S, basada en la arquitectura Ada Lovelace, representa un avance significativo con respecto a su predecesora basada en Ampere, la NVIDIA A40. Ambas GPU están diseñadas para una amplia gama de cargas de trabajo en centros de datos, incluyendo IA, gráficos y HPC, pero la L40S aporta mejoras sustanciales de rendimiento y nuevas funciones.
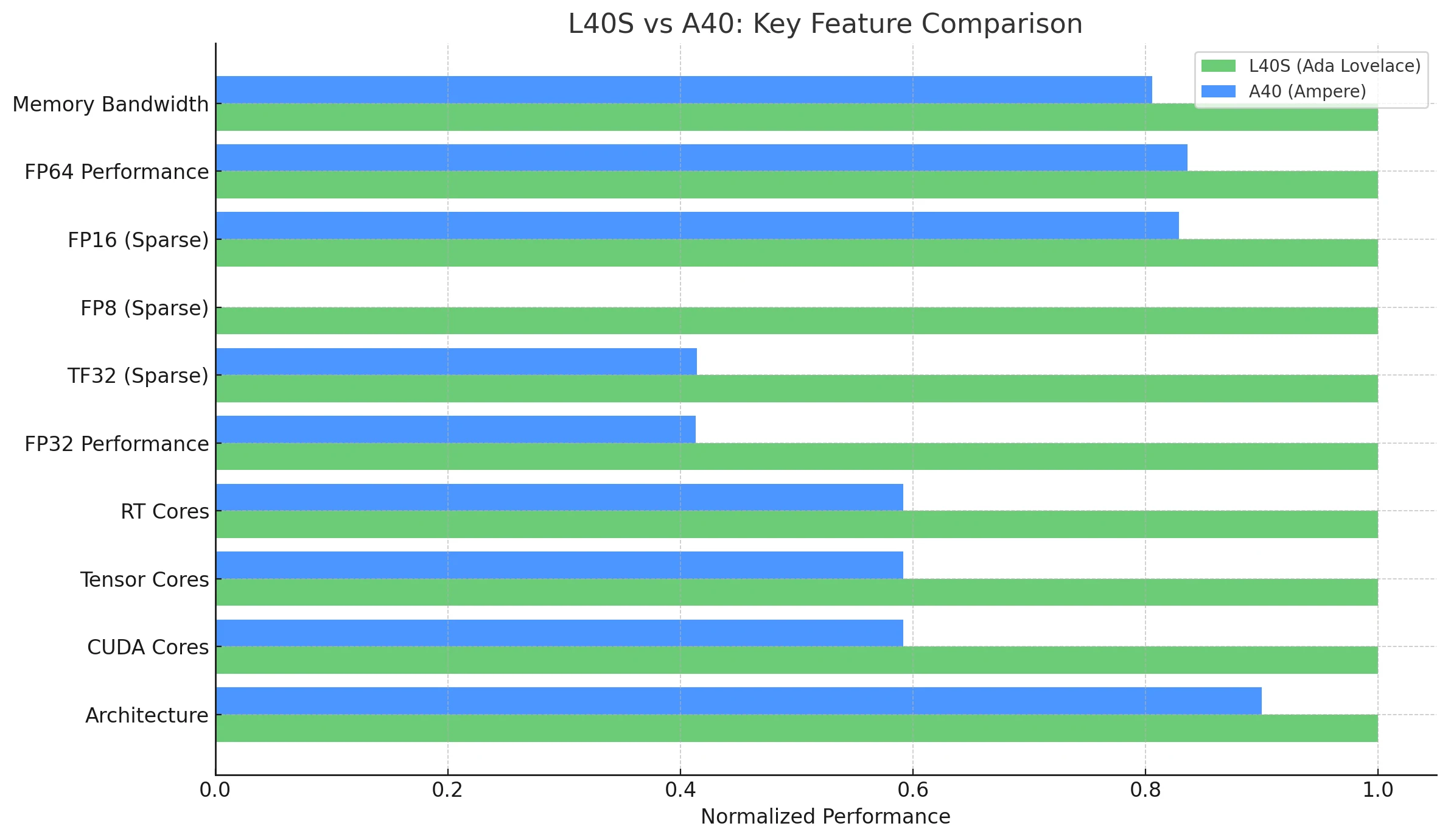
| Característica / Métrica | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| Arquitectura | Ada Lovelace | Ampere |
| CUDA Cores | 18,176 | 10,752 |
| Tensor Cores | 568 (Cuarta generación) | 336 (Tercera generación) |
| RT Cores | 142 (Tercera generación) | 84 (Segunda generación) |
| Rendimiento FP32 | 91.6 TFLOPS | 37.4 TFLOPS |
| TF32 Tensor (Sparse) | 183 | 366* | 74.8 | 149.6* |
| FP8 Tensor (Sparse) | 733 PFLOPS | No compatible de forma nativa (limitación de Ampere) |
| FP16 Tensor (Sparse) | 362.05 TFLOPS | 149.7 | 299.4* |
| Memoria de GPU | 48 GB GDDR6 con ECC | 48 GB GDDR6 con ECC |
| Ancho de banda de memoria | 864 GB/s | 696 GB/s |
| Consumo de energía (TDP) | 350 W | 300 W |
| Multi-Instance GPU (MIG) | No | No |
| NVLink | No | Sí (2 vías, 112.5 GB/s de ancho de banda total) |
L40S vs A40: Eficiencia energética
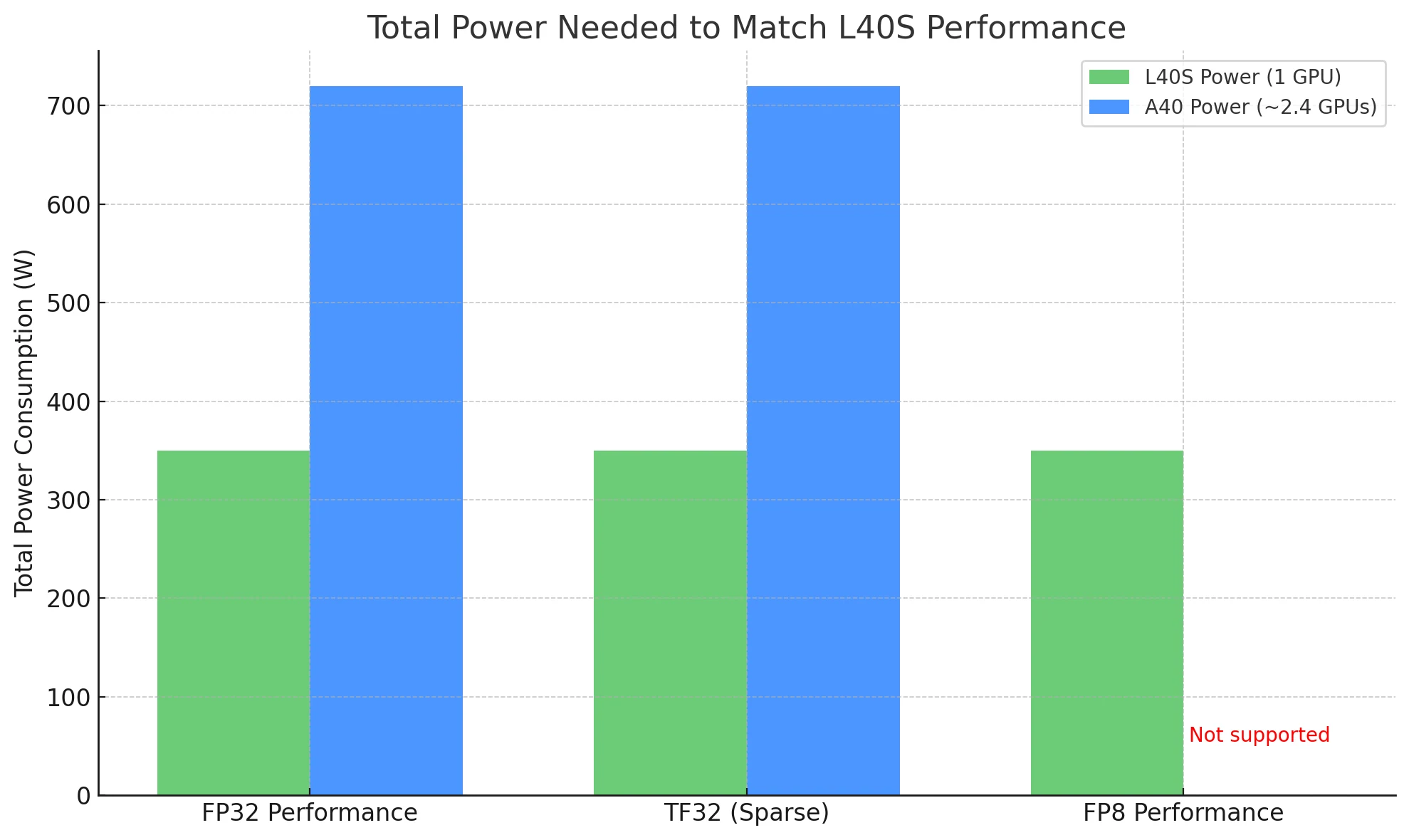
Al comparar GPU, la potencia total necesaria para lograr la misma carga de trabajo es una medida más significativa de eficiencia, y aquí es donde destaca la L40S.
- Rendimiento FP32: L40S ofrece ~91.6 TFLOPS, mientras que A40 ofrece ~37.4 TFLOPS — aproximadamente 2.4× más rendimiento.
- TF32 (Sparse): L40S alcanza 366 TFLOPS, frente a los ~149.6 TFLOPS de A40 — nuevamente, alrededor de 2.4× la salida.
- Rendimiento FP8: L40S tiene una ventaja significativa al ofrecer soporte nativo para FP8. La A40, basada en la arquitectura Ampere más antigua, no admite FP8 en absoluto.
Para igualar el rendimiento de L40S:
- Usando L40S: Solo necesitas 1 tarjeta, que consume ~350 W.
- Usando A40: Teóricamente necesitarías ~2.4 tarjetas, con un total de ~720 W de potencia.
En implementaciones del mundo real, esto significa que L40S puede ofrecer un mayor rendimiento con la mitad de energía, lo que la convierte en una opción mucho más rentable y escalable, especialmente en entornos sensibles al consumo eléctrico o a gran escala.
L40S vs A40: Aplicaciones
Entrenamiento e inferencia de IA
| Área | L40S | A40 |
|---|---|---|
| Entrenamiento | Excelente para entrenamiento mediano/grande (TF32: 366 TFLOPS), menor costo, pero carece de NVLink. | Mejor para modelos masivos con alto ancho de banda (TF32: 149.6 TFLOPS, NVLink). |
| Inferencia | Soporte FP8 excelente (738 PFLOPS), sólido para LLMs e implementación. | Sin FP8; fuerte en FP16, BF16, INT8. |
Gráficos y visualización
| Característica | L40S | A40 |
|---|---|---|
| CUDA Cores | 18,176 | 10,752 |
| RT Cores | 142 | 84 |
| Controladores | RTX Enterprise, Omniverse, Studio ready | Enfocado en cómputo, herramientas gráficas limitadas |
| Rendimiento FP32 | 91.6 TFLOPS | 37.4 TFLOPS |
Cargas de trabajo de precisión
| Característica | L40S | A40 |
|---|---|---|
| Uso FP64 | 1431 | 585 |
| Uso FP32 | 91.6 | 37.4 |
Recomendación
- Elige la L40S si necesitas:
- Inferencia de alto rendimiento (especialmente soporte FP8)
- Entrenamiento de IA de escala media rentable
- Cargas de trabajo visuales (renderizado, Omniverse)
- Aceleración de IA de propósito general con arquitectura moderna
- Elige la A40 si necesitas:
- Soporte NVLink para entrenamiento a gran escala con múltiples GPU
- Una configuración más tradicional centrada en cómputo sin dependencias gráficas
¿Cómo ejecutar L40S a un precio muy bajo?
Novita AI proporciona una plataforma en la nube con instancias de GPU de alto rendimiento. Con potentes GPU, garantiza un rendimiento eficiente para tareas complejas, mejora la accesibilidad para la implementación en diversos hardware y ofrece una solución rentable en comparación con el mantenimiento de hardware local para implementaciones de IA a gran escala.
Paso 1: Crea una cuenta
Crea tu cuenta de Novita AI a través de nuestro sitio web. Después del registro, navega a la sección “Explorar” en la barra lateral izquierda para ver nuestras ofertas de GPU y comenzar tu viaje de desarrollo de IA.

Paso 2:Explora plantillas y servidores GPU
Elige entre plantillas como PyTorch, TensorFlow o CUDA que se ajusten a las necesidades de tu proyecto. Luego, selecciona la configuración de GPU que prefieras; las opciones incluyen la potente L40S, RTX 4090 o A100 SXM4, cada una con diferentes especificaciones de VRAM, RAM y almacenamiento.

Paso 3: Personaliza tu implementación
Personaliza tu entorno seleccionando tu sistema operativo preferido y opciones de configuración para garantizar un rendimiento óptimo para tus cargas de trabajo de IA y necesidades de desarrollo específicas.

Paso 4:Inicia una instancia
Selecciona “Iniciar instancia” para comenzar tu implementación. Tu entorno de GPU de alto rendimiento estará listo en cuestión de minutos, permitiéndote comenzar de inmediato tus proyectos de aprendizaje automático, renderizado o computacionales.

La NVIDIA L40S representa un gran salto respecto a la A40 en casi todos los aspectos: desde inferencia FP8 hasta renderizado gráfico y eficiencia energética. Con la arquitectura Ada Lovelace, ofrece más de 2 veces el rendimiento de la A40 consumiendo significativamente menos energía. Para inferencia de IA, entrenamiento de escala media y flujos de trabajo con gran carga de visualización, la L40S es la clara ganadora. Mientras tanto, la A40 puede seguir siendo relevante para configuraciones heredadas que requieran NVLink o cargas de trabajo de cómputo tradicionales.
Preguntas frecuentes
¿Qué GPU es mejor para inferencia de IA: L40S o A40?
L40S. Admite FP8 nativo y ofrece hasta 738 PFLOPS, lo que la hace mucho más potente para tareas de inferencia.
¿Puedo usar L40S para entrenamiento de IA a gran escala?
Sí, L40S ofrece 366 TFLOPS (TF32 Sparse), siendo excelente para entrenamiento de mediana a gran escala, aunque carece de soporte NVLink.
¿Qué hace que L40S sea más eficiente energéticamente?
Solo necesitas 1 L40S (~350 W) para igualar el rendimiento de 2.4 A40 (~720 W), reduciendo los costos de energía a la mitad.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=NVIDIA A100 GPU Performance: Why It’s Still the Go-to Choice for AI Training) es una plataforma en la nube de IA que ofrece a los desarrolladores una forma sencilla de implementar modelos de IA mediante nuestra API simple, al tiempo que proporciona la nube de GPU asequible y fiable para construir y escalar.
Lectura recomendada



