

Key Highlights
Performance: L40S outperforms A40 in all metrics, with exclusive FP8 support, significantly higher FP32/TF32 performance, and superior memory bandwidth and CUDA/Tensor Core efficiency.
Power Efficiency: L40S achieves equivalent or better performance with ~60% less power per GPU, while A40 lacks FP8 support for low-precision AI tasks.
Application Focus: L40S is better suited for AI inference, precision workloads, and visualization tasks, leveraging advanced Ada Lovelace architecture.

Novita AI

Runpod
The cost of using L40S on Novita AI is approximately half the price of RunPod.
The NVIDIA L40S, built on the Ada Lovelace architecture, is a significant upgrade over the A40. It offers enhanced AI inference capabilities with native FP8 support, superior graphics performance due to third-generation RT Cores, and improved power efficiency. These advancements make the L40S a versatile and cost-effective choice for modern data center workloads.
L40S vs A40: Architecture Comparison
The NVIDIA L40S, built on the Ada Lovelace architecture, represents a significant step forward from its Ampere-based predecessor, the NVIDIA A40. Both GPUs are designed for a broad range of data center workloads, including AI, graphics, and HPC, but the L40S brings substantial performance improvements and new features.
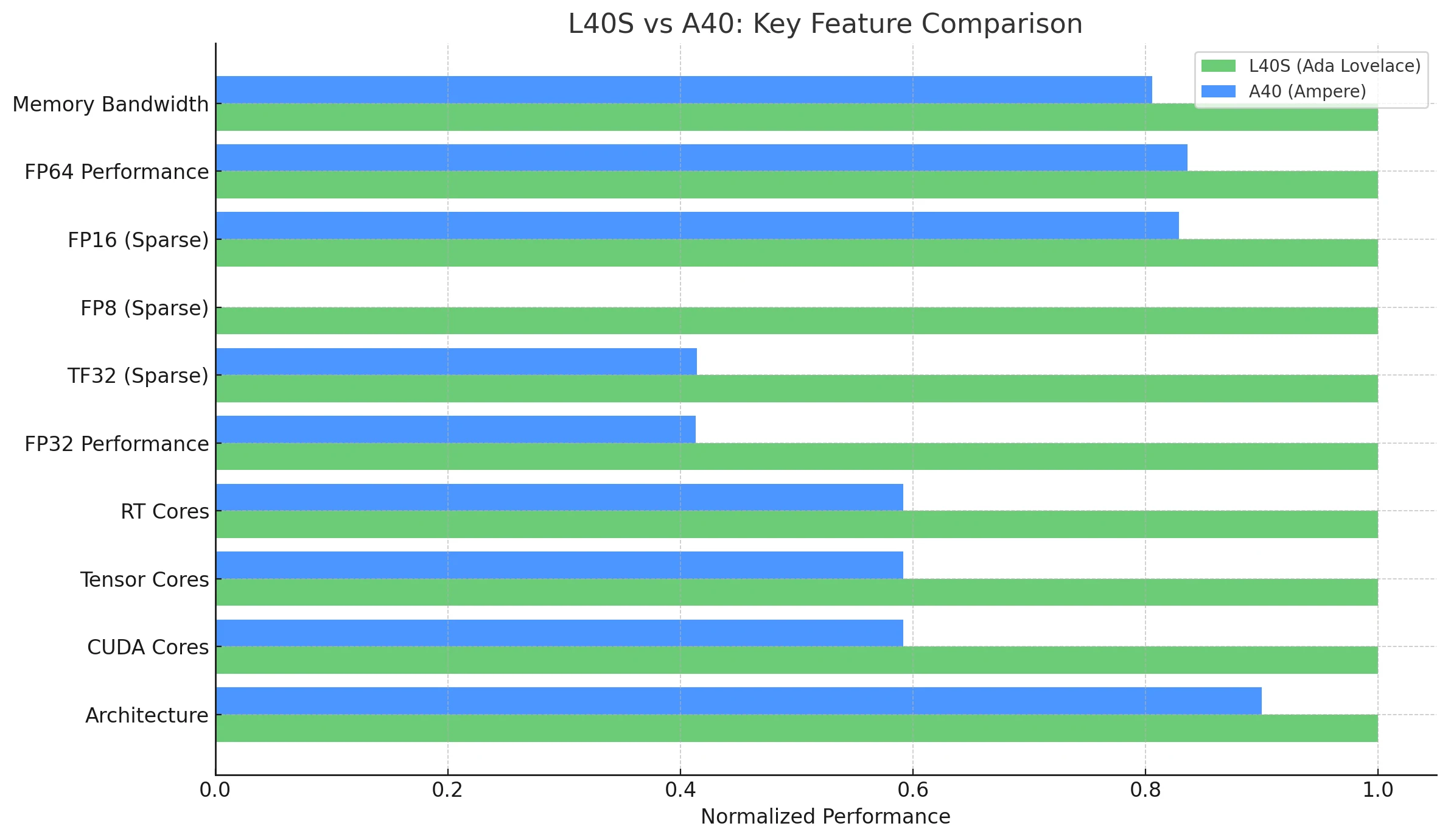
| Feature / Metric | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| Architecture | Ada Lovelace | Ampere |
| CUDA Cores | 18,176 | 10,752 |
| Tensor Cores | 568 (Fourth-Generation) | 336 (Third-Generation) |
| RT Cores | 142 (Third-Generation) | 84 (Second-Generation) |
| FP32 Performance | 91.6 TFLOPS | 37.4 TFLOPS |
| TF32 Tensor (Sparse) | 183 | 366* | 74.8 | 149.6* |
| FP8 Tensor (Sparse) | 733 PFLOPS | Not Natively Supported (Ampere limitation) |
| FP16 Tensor (Sparse) | 362.05TFLOPS | 149.7 | 299.4* |
| GPU memory | 48GB GDDR6 with ECC | 48GB GDDR6 with ECC |
| Memory Bandwidth | 864GB/s | 696 GB/s |
| Power Consumption (TDP) | 350W | 300W |
| Multi-Instance GPU (MIG) | No | No |
| NVLink | No | Yes (2-way, 112.5 GB/s total bandwidth) |
L40S vs A40: Power Efficiency
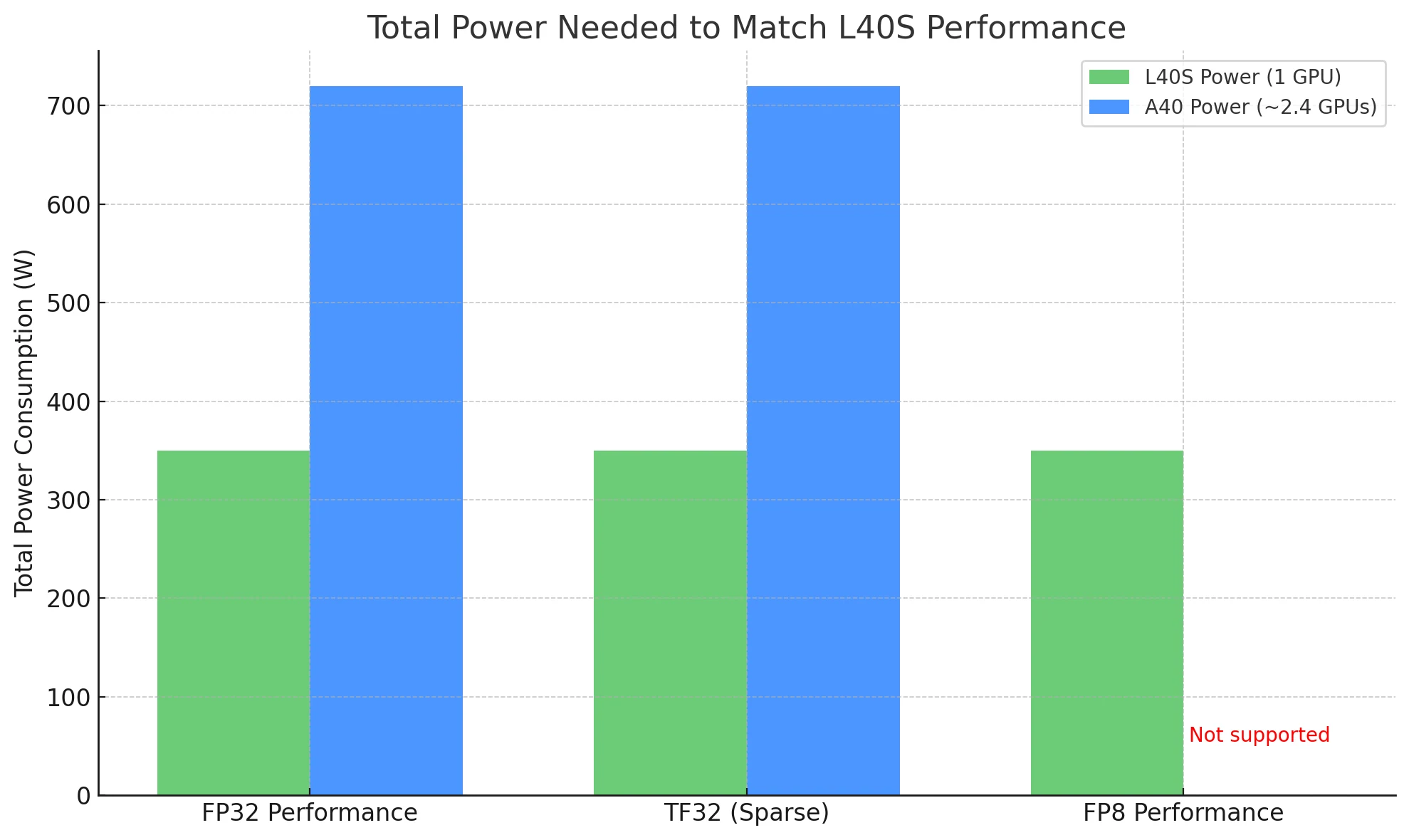
When comparing GPUs, total power required to achieve the same workload is a more meaningful measure of efficiency—and this is where the L40S stands out.
- FP32 Performance: L40S delivers ~91.6 TFLOPS, while A40 offers ~37.4 TFLOPS — roughly 2.4× more performance.
- TF32 (Sparse): L40S reaches 366 TFLOPS, versus A40’s ~149.6 TFLOPS — again, about 2.4× the output.
- FP8 Performance: L40S has a significant advantage, offering native FP8 support. The A40, built on the older Ampere architecture, does not support FP8 at all.
To match L40S performance:
- Using L40S: You only need 1 card, consuming ~350W.
- Using A40: You’d theoretically need ~2.4 cards, totaling ~720W of power.
In real-world deployments, this means L40S can deliver higher throughput with half the power, making it a far more cost-efficient and scalable choice, especially in power-sensitive or large-scale environments.
L40S vs A40: Applications
AI Training & Inference
| Area | L40S | A40 |
|---|---|---|
| Training | Great for mid/large-scale training (TF32: 366TFLOPS), lower cost, but lacks NVLink. | Better for massive models with high bandwidth (TF32: 149.6TFLOPS, NVLink). |
| Inference | Excellent FP8 support (738 PFLOPS), strong for LLMs & deployment. | No FP8; strong in FP16, BF16, INT8. |
Graphics & Visualization
| Feature | L40S | A40 |
|---|---|---|
| CUDA Cores | 18,176 | 10752 |
| RT Cores | 142 | 84 |
| Drivers | RTX Enterprise, Omniverse, Studio ready | Compute-focused, limited graphics tools |
| FP32 Perf | 91.6 TFLOPS | 37.4 TFLOPS |
Precision Workloads
| Feature | L40S | A40 |
|---|---|---|
| FP64 Usage | 1431 | 585 |
| FP32 Usage | 91.6 | 37.4 |
Recommendation
- Choose L40S if you need:
- High-throughput inference (especially FP8 support)
- Cost-effective mid-scale AI training
- Visual workloads (rendering, Omniverse)
- General-purpose AI acceleration with modern architecture
- Choose A40 if you need:
- NVLink support for multi-GPU large-scale training
- A more traditional, compute-focused setup without graphics dependencies
How to run L40S at a very low price?
Novita AI provides a cloud-based platform with high-performance GPU instances. With powerful GPUs, it ensures efficient performance for complex tasks, enhances accessibility for deployment across various hardware, and offers a cost-effective solution compared to maintaining local hardware for large-scale AI deployments.
Step1:Register an account
Create your Novita AI account through our website. After registration, navigate to the “Explore” section in the left sidebar to view our GPU offerings and begin your AI development journey.

Step2:Exploring Templates and GPU Servers
Choose from templates like PyTorch, TensorFlow, or CUDA that match your project needs. Then select your preferred GPU configuration—options include the powerful L40S, RTX 4090 or A100 SXM4, each with different VRAM, RAM, and storage specifications.

Step3:Tailor Your Deployment
Customize your environment by selecting your preferred operating system and configuration options to ensure optimal performance for your specific AI workloads and development needs.

Step4:Launch an instance
Select “Launch Instance” to start your deployment. Your high-performance GPU environment will be ready within minutes, allowing you to immediately begin your machine learning, rendering, or computational projects.

The NVIDIA L40S represents a major leap over the A40 in nearly every aspect—from FP8 inference to graphics rendering and power efficiency. With Ada Lovelace architecture, it delivers over 2x the performance of the A40 while consuming significantly less power. For AI inference, mid-scale training, and visualization-heavy workflows, L40S is the clear winner. Meanwhile, A40 may still be relevant for legacy setups requiring NVLink or traditional compute workloads.
Frequently Asked Questions
Which GPU is better for AI inference—L40S or A40?
L40S. It supports native FP8 and delivers up to 738 PFLOPS, making it far more powerful for inference tasks.
Can I use L40S for large-scale AI training?
Yes, L40S offers 366 TFLOPS (TF32 Sparse), making it great for mid-to-large scale training—though it lacks NVLink support.
What makes L40S more power-efficient?
You need just 1 L40S (~350W) to match the performance of 2.4 A40s (~720W), cutting energy costs in half.
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=NVIDIA A100 GPU Performance: Why It’s Still the Go-to Choice for AI Training) is an AI cloud platform that offers developers an easy way to deploy AI models using our simple API, while also providing the affordable and reliable GPU cloud for building and scaling.
Recommended Reading



