

主なハイライト
パフォーマンス:L40Sは、すべての指標でA40を上回り、専用のFP8サポート、大幅に高いFP32/TF32性能、優れたメモリ帯域幅とCUDA/Tensor Core効率を備えています。
電力効率:L40SはGPUあたり約60%少ない電力で同等以上の性能を実現し、一方A40は低精度AIタスク用のFP8サポートがありません。
アプリケーションの焦点:L40Sは、高度なAda Lovelaceアーキテクチャを活用し、AI推論、精密ワークロード、可視化タスクに適しています。

Novita AI

Runpod
Novita AIでのL40Sの使用コストは、RunPodの約半額です。
NVIDIA L40Sは、Ada Lovelaceアーキテクチャを採用し、A40からの大幅なアップグレードです。ネイティブFP8サポートによるAI推論機能の強化、第3世代RTコアによる優れたグラフィックス性能、そして改善された電力効率を実現しています。これらの進歩により、L40Sは現代のデータセンターのワークロードに対して汎用性が高く、コスト効率の良い選択肢となっています。
L40S vs A40:アーキテクチャ比較
NVIDIA L40SはAda Lovelaceアーキテクチャを採用しており、Ampereベースの前世代NVIDIA A40からの大きな進歩を表しています。どちらのGPUもAI、グラフィックス、HPCなど幅広いデータセンターワークロード向けに設計されていますが、L40Sは大幅なパフォーマンス向上と新機能をもたらします。
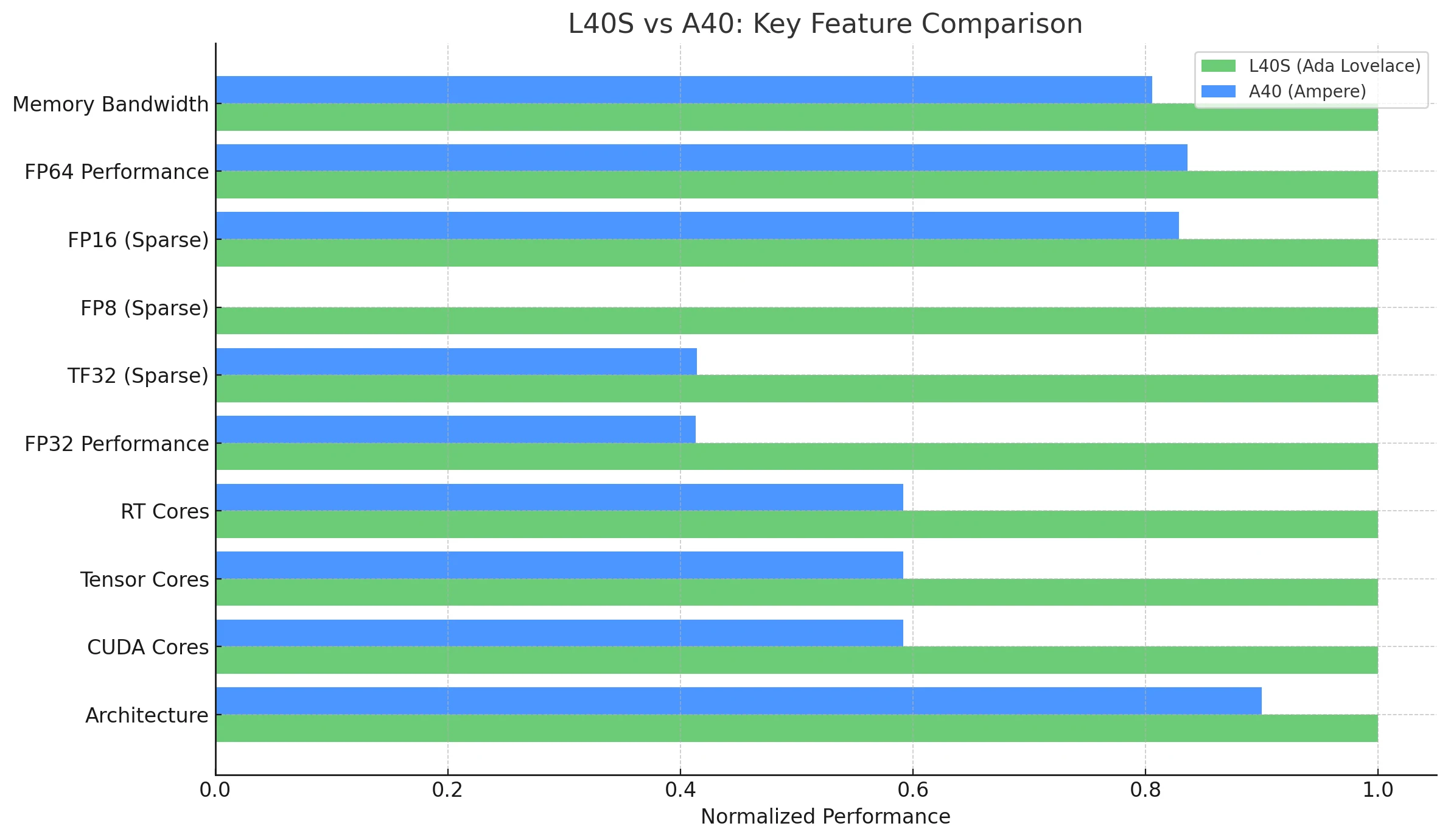
| 機能/指標 | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| **アーキテクチャ ** | Ada Lovelace | Ampere |
| **CUDAコア数 ** | 18,176 | 10,752 |
| **テンソルコア数 ** | 568 (第4世代) | 336 (第3世代) |
| **RTコア数 ** | 142 (第3世代) | 84 (第2世代) |
| **FP32性能 ** | 91.6 TFLOPS | 37.4 TFLOPS |
| TF32テンソル (スパース) | 183 | 366* | 74.8 | 149.6* |
| FP8テンソル (スパース) | 733 PFLOPS | ネイティブ非対応 (Ampereの制限) |
| FP16テンソル (スパース) | 362.05 TFLOPS | 149.7 | 299.4* |
| GPUメモリ | 48GB GDDR6 with ECC | 48GB GDDR6 with ECC |
| **メモリ帯域幅 ** | 864 GB/s | 696 GB/s |
| 消費電力 (TDP) | 350W | 300W |
| マルチインスタンスGPU (MIG) | なし | なし |
| NVLink | なし | あり (2ウェイ、112.5 GB/s 合計帯域幅) |
L40S vs A40:電力効率
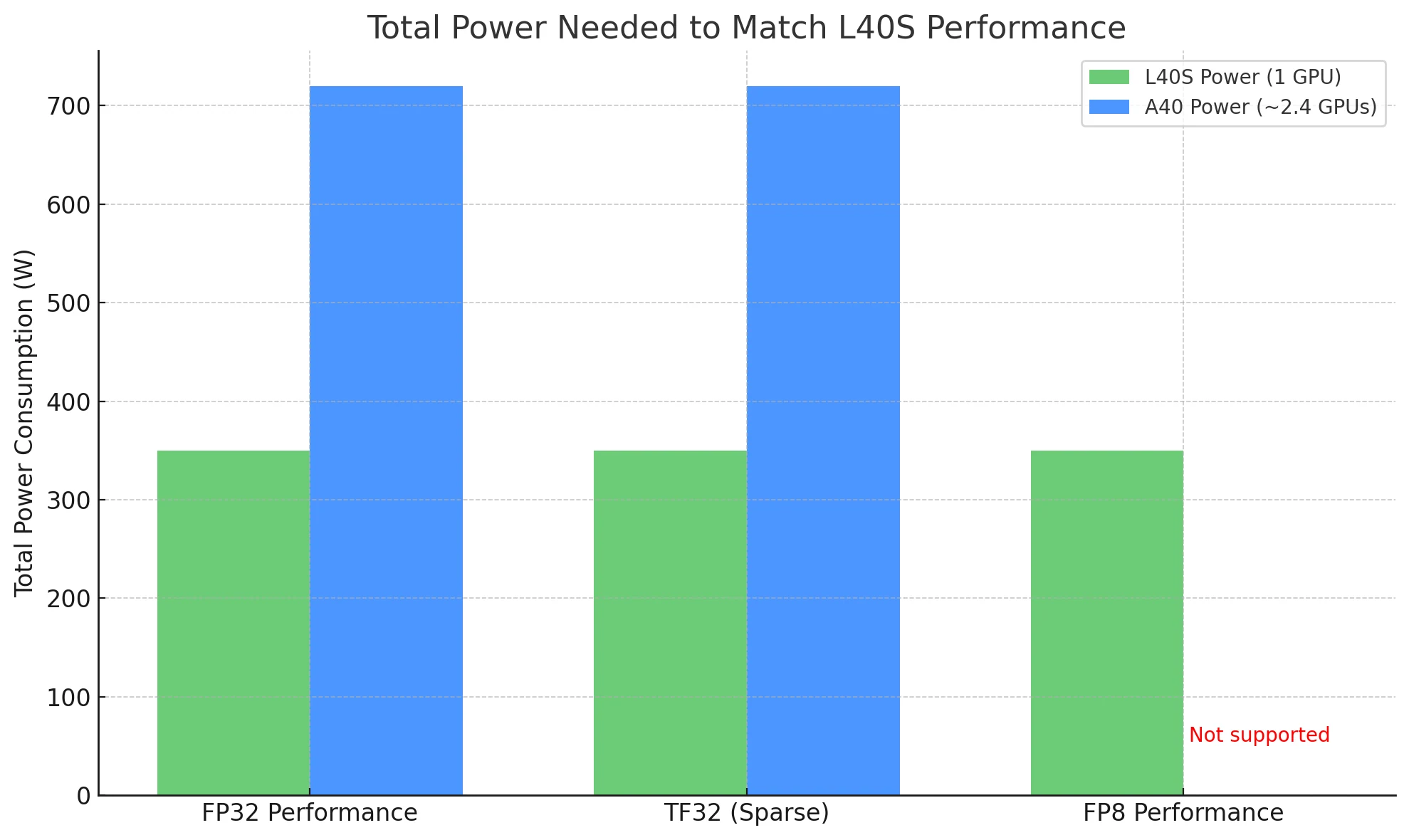
GPUを比較する際、同じワークロードを達成するために必要な総電力はより意味のある効率の尺度であり、この点で L40S が際立っています。
- **FP32性能 **:L40Sは ~91.6 TFLOPS、A40は ~37.4 TFLOPS で、約 2.4倍 の性能です。
- TF32 (スパース):L40Sは 366 TFLOPS、A40は ~149.6 TFLOPS で、こちらも約 2.4倍 の出力です。
- **FP8性能 :L40Sは ** 大きなアドバンテージ ** があり、 ネイティブFP8サポート ** を提供。旧AmpereアーキテクチャのA40は FP8をまったくサポートしていません。
L40Sのパフォーマンスに合わせるには:
- **L40S使用時 **:**1枚のカード ** で済み、消費電力は ~350W。
- **A40使用時 **:理論上 ** 約2.4枚のカード ** が必要で、合計消費電力は ~720W。
実際の導入では、L40Sは半分の電力でより高いスループットを実現 ** できるため、特に電力に制約のある環境や大規模環境でははるかにコスト効率が高くスケーラブルな選択肢** となります。
L40S vs A40:アプリケーション
AIトレーニングと推論
| 分野 | L40S | A40 |
|---|---|---|
| トレーニング | 中規模/大規模トレーニングに最適 (TF32: 366TFLOPS)、低コストだがNVLinkなし。 | 大規模モデル向けに高帯域幅 (TF32: 149.6TFLOPS、NVLink) でより適している。 |
| 推論 | 優れたFP8サポート (738 PFLOPS)、LLMとデプロイメントに強力。 | FP8非対応。FP16、BF16、INT8で強力。 |
グラフィックスと可視化
| 機能 | L40S | A40 |
|---|---|---|
| CUDAコア数 | 18,176 | 10,752 |
| RTコア数 | 142 | 84 |
| ドライバー | RTX Enterprise、Omniverse、Studio対応 | コンピュート重視、グラフィックスツールは限定 |
| FP32性能 | 91.6 TFLOPS | 37.4 TFLOPS |
精密ワークロード
| 機能 | L40S | A40 |
|---|---|---|
| FP64使用率 | 1431 | 585 |
| FP32使用率 | 91.6 | 37.4 |
推奨
- L40S を選ぶべき場合:
- 高スループットの推論 (特にFP8サポート)
- コスト効率の良い中規模AIトレーニング
- ビジュアルワークロード (レンダリング、Omniverse)
- 最新アーキテクチャによる汎用AIアクセラレーション
- A40 を選ぶべき場合:
- マルチGPU大規模トレーニングのためのNVLinkサポートが必要
- グラフィックスに依存しない、より従来的なコンピュート重視の設定
非常に低価格でL40Sを実行する方法
Novita AIは、高性能GPUインスタンスを備えたクラウドベースのプラットフォームを提供しています。強力なGPUにより複雑なタスクの効率的なパフォーマンスを保証し、さまざまなハードウェアへのデプロイのアクセス性を向上させ、大規模なAIデプロイメントにおいてローカルハードウェアを維持するよりもコスト効率の良いソリューションを提供します。
ステップ1:アカウント登録
WebサイトからNovita AIアカウントを作成します。登録後、左サイドバーの「Explore」セクションに移動してGPUオプションを確認し、AI開発の旅を始めましょう。

ステップ2:テンプレートとGPUサーバーを探索
プロジェクトのニーズに合ったPyTorch、TensorFlow、CUDAなどのテンプレートを選択します。次に、希望するGPU構成を選択します。強力なL40S、RTX 4090、A100 SXM4など、異なるVRAM、RAM、ストレージ仕様のオプションがあります。

ステップ3:デプロイメントをカスタマイズ
好みのオペレーティングシステムと構成オプションを選択して環境をカスタマイズし、特定のAIワークロードと開発ニーズに最適なパフォーマンスを確保します。

ステップ4:インスタンスを起動
「Launch Instance」を選択してデプロイを開始します。高性能GPU環境は数分以内に利用可能になり、すぐに機械学習、レンダリング、または計算プロジェクトを開始できます。

NVIDIA L40S は、FP8推論からグラフィックスレンダリング、電力効率に至るまではとんどすべての面でA40を大きく上回ります。Ada Lovelaceアーキテクチャにより、A40の **2倍以上 ** のパフォーマンスを提供しながら、消費電力は大幅に低減されています。AI推論、中規模トレーニング、可視化重視のワークフローにおいて、L40Sが明確な勝者です。一方、A40は NVLink を必要とするレガシーな設定や従来のコンピュートワークロードでは依然として有用かもしれません。
よくある質問
AI推論に適したGPUは、L40SとA40のどちらですか?
L40Sです。ネイティブFP8をサポートし、最大 738 PFLOPS を実現するため、推論タスクではるかに強力です。
L40Sを大規模AIトレーニングに使用できますか?
はい、L40Sは 366 TFLOPS (TF32スパース) を提供し、中規模から大規模のトレーニングに最適ですが、NVLinkサポートはありません。
L40Sの電力効率が高い理由は何ですか?
L40S 1枚 (~350W) で A40 2.4枚 (~720W) のパフォーマンスに匹敵するため、エネルギーコストを半分に削減できます。
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=NVIDIA A100 GPU Performance: Why It’s Still the Go-to Choice for AI Training) は、開発者がシンプルなAPIを使用してAIモデルを簡単にデプロイできるAIクラウドプラットフォームであり、AIの構築とスケーリングのための手頃で信頼性の高いGPUクラウドも提供しています。
おすすめの記事



