

Points clés
Performances : Le L40S surpasse l’A40 dans tous les domaines, avec un support exclusif du FP8, des performances FP32/TF32 nettement supérieures, ainsi qu’une meilleure bande passante mémoire et une efficacité accrue des CUDA Cores et Tensor Cores.
Efficacité énergétique : Le L40S atteint des performances équivalentes ou supérieures avec environ 60 % de puissance en moins par GPU, tandis que l’A40 ne prend pas en charge le FP8 pour les tâches d’IA à faible précision.
Applications : Le L40S est mieux adapté à l’inférence IA, aux charges de travail de précision et aux tâches de visualisation, grâce à l’architecture Ada Lovelace avancée.

Novita AI

Runpod
Le coût d’utilisation du L40S sur Novita AI est environ la moitié du prix de RunPod.
Essayez Novita AI dès maintenant
Le NVIDIA L40S, basé sur l’architecture Ada Lovelace, constitue une mise à niveau significative par rapport à l’A40. Il offre des capacités d’inférence IA améliorées avec un support natif du FP8, des performances graphiques supérieures grâce aux RT Cores de troisième génération, et une meilleure efficacité énergétique. Ces avancées font du L40S un choix polyvalent et économique pour les charges de travail modernes des centres de données.
L40S vs A40 : Comparaison architecturale
Le NVIDIA L40S, basé sur l’architecture Ada Lovelace, représente un progrès considérable par rapport à son prédécesseur basé sur Ampere, le NVIDIA A40. Les deux GPU sont conçus pour une large gamme de charges de travail en centre de données, incluant l’IA, le graphisme et le HPC, mais le L40S apporte des améliorations de performance substantielles et de nouvelles fonctionnalités.
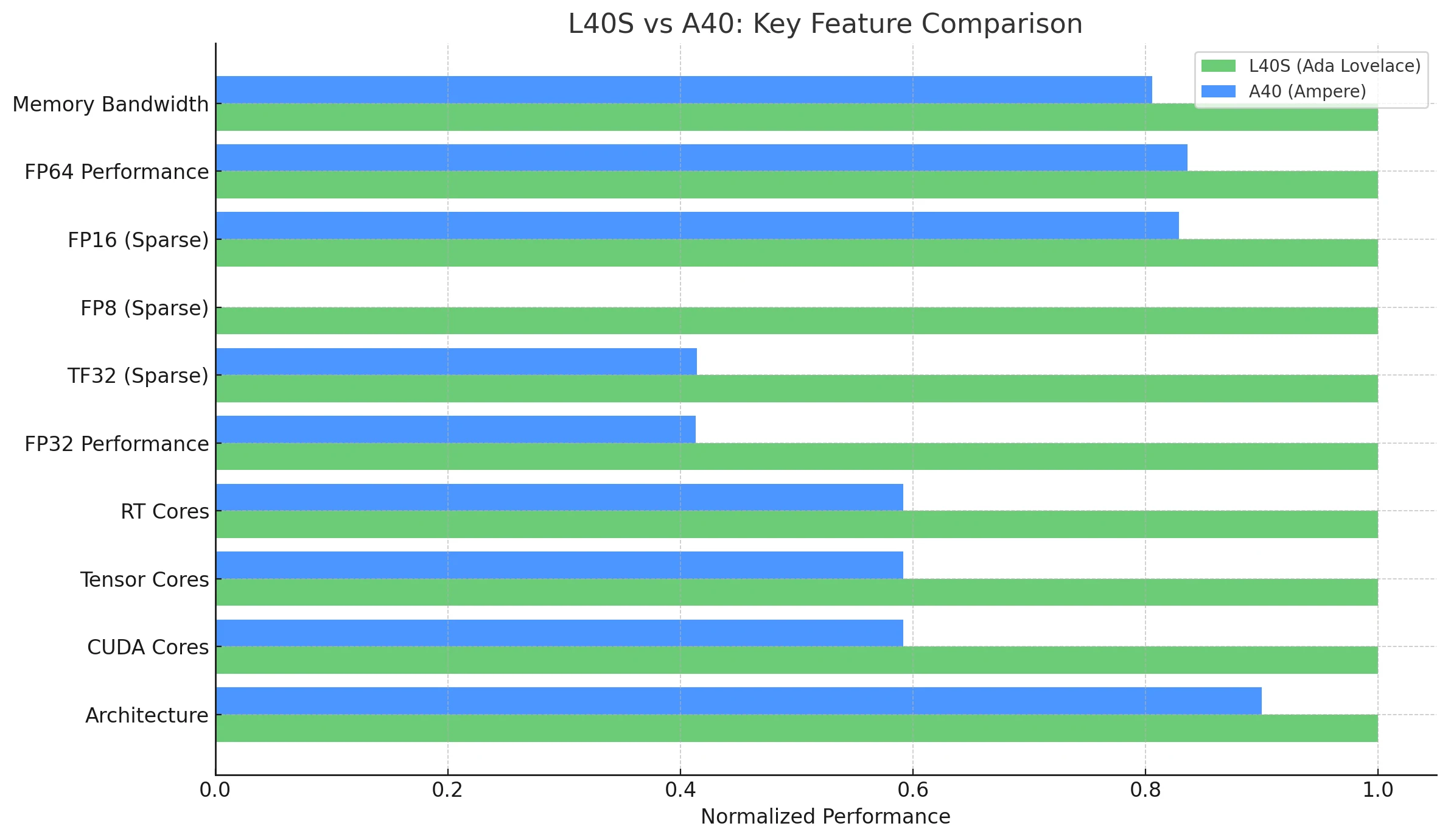
| Caractéristique / Métrique | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| Architecture | Ada Lovelace | Ampere |
| CUDA Cores | 18 176 | 10 752 |
| Tensor Cores | 568 (quatrième génération) | 336 (troisième génération) |
| RT Cores | 142 (troisième génération) | 84 (deuxième génération) |
| Performance FP32 | 91,6 TFLOPS | 37,4 TFLOPS |
| TF32 Tensor (Sparse) | 183 | 366* | 74,8 | 149,6* |
| FP8 Tensor (Sparse) | 733 PFLOPS | Non pris en charge nativement (limitation Ampere) |
| FP16 Tensor (Sparse) | 362,05 TFLOPS | 149,7 | 299,4* |
| Mémoire GPU | 48 Go GDDR6 avec ECC | 48 Go GDDR6 avec ECC |
| Bande passante mémoire | 864 Go/s | 696 Go/s |
| Consommation électrique (TDP) | 350 W | 300 W |
| GPU multi-instance (MIG) | Non | Non |
| NVLink | Non | Oui (2 voies, 112,5 Go/s de bande passante totale) |
L40S vs A40 : Efficacité énergétique
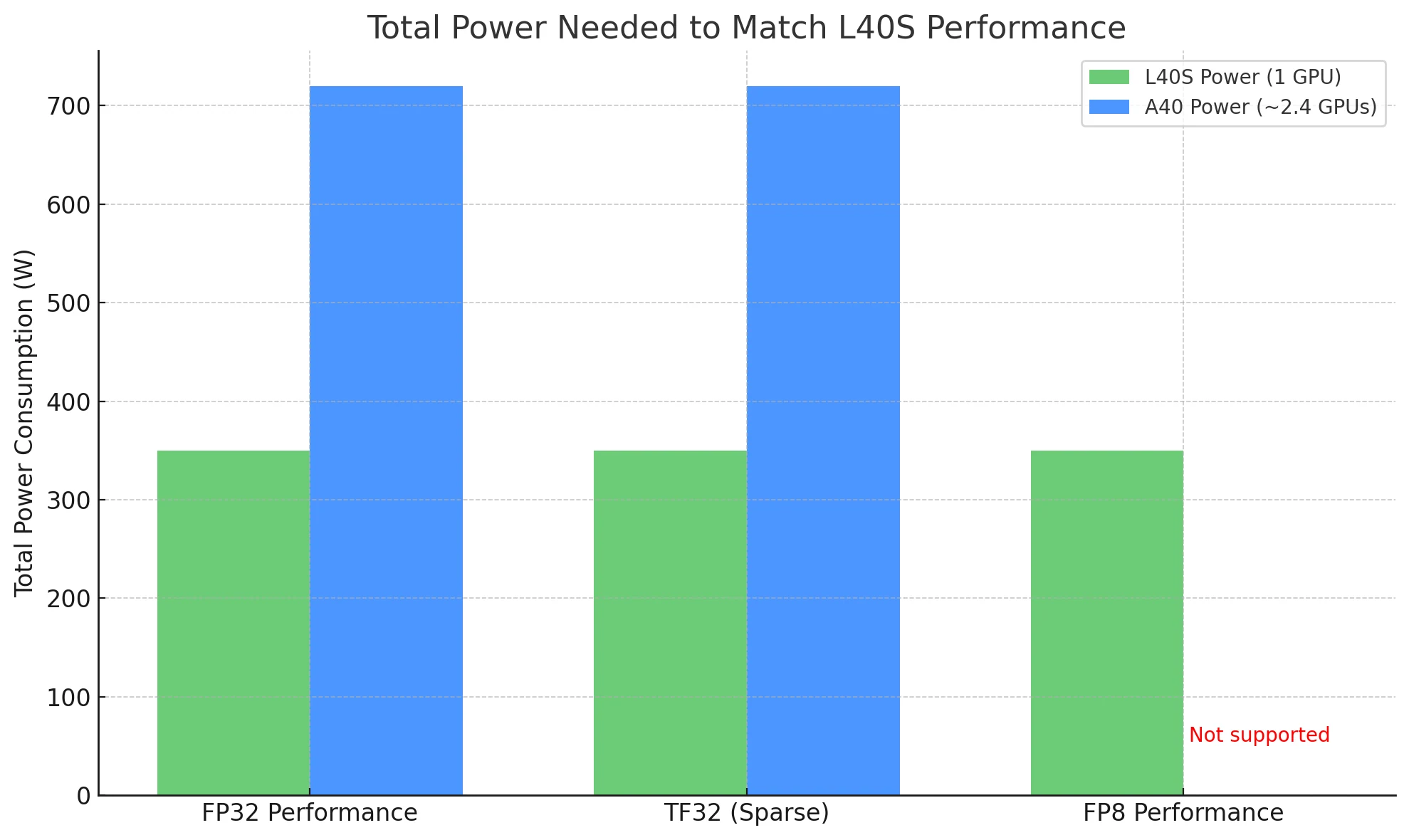
Lorsqu’on compare des GPU, la puissance totale nécessaire pour effectuer la même charge de travail est une mesure d’efficacité plus pertinente – et c’est là que le L40S se distingue.
- Performance FP32 : Le L40S délivre ~91,6 TFLOPS, tandis que l’A40 offre ~37,4 TFLOPS — soit environ 2,4× plus de performances.
- TF32 (Sparse) : Le L40S atteint 366 TFLOPS, contre ~149,6 TFLOPS pour l’A40 — là encore, environ 2,4× le rendement.
- Performance FP8 : Le L40S bénéficie d’un avantage significatif, offrant un support natif du FP8. L’A40, basé sur l’ancienne architecture Ampere, ne prend pas du tout en charge le FP8.
Pour égaler les performances du L40S :
- Avec un L40S : Vous n’avez besoin que d’1 carte, consommant ~350 W.
- Avec des A40 : Il vous faudrait théoriquement ~2,4 cartes, soit un total de ~720 W.
Dans les déploiements réels, cela signifie que le L40S peut offrir un débit plus élevé avec la moitié de la puissance, ce qui en fait un choix bien plus économique et évolutif, en particulier dans les environnements sensibles à la consommation électrique ou à grande échelle.
L40S vs A40 : Applications
Entraînement et inférence IA
| Domaine | L40S | A40 |
|---|---|---|
| Entraînement | Excellent pour l’entraînement à moyenne/grande échelle (TF32 : 366 TFLOPS), coût plus faible, mais pas de NVLink. | Meilleur pour les modèles massifs avec bande passante élevée (TF32 : 149,6 TFLOPS, NVLink). |
| Inférence | Excellent support FP8 (738 PFLOPS), performant pour les LLM et le déploiement. | Pas de FP8 ; performant en FP16, BF16, INT8. |
Graphisme et visualisation
| Fonctionnalité | L40S | A40 |
|---|---|---|
| CUDA Cores | 18 176 | 10 752 |
| RT Cores | 142 | 84 |
| Pilotes | RTX Enterprise, Omniverse, Studio ready | Axés calcul, outils graphiques limités |
| Perf FP32 | 91,6 TFLOPS | 37,4 TFLOPS |
Charges de travail de précision
| Fonctionnalité | L40S | A40 |
|---|---|---|
| Utilisation FP64 | 1 431 | 585 |
| Utilisation FP32 | 91,6 | 37,4 |
Recommandation
- Choisissez le L40S si vous avez besoin de :
- Inférence à haut débit (notamment avec le FP8)
- Entraînement IA à moyenne échelle économique
- Charges de travail visuelles (rendu, Omniverse)
- Accélération IA généraliste avec architecture moderne
- Choisissez l’A40 si vous avez besoin de :
- Support NVLink pour l’entraînement multi-GPU à grande échelle
- Une configuration plus traditionnelle, axée sur le calcul, sans dépendances graphiques
Comment utiliser le L40S à très bas prix ?
Novita AI propose une plateforme cloud avec des instances GPU haute performance. Grâce à des GPU puissants, elle garantit une exécution efficace des tâches complexes, facilite le déploiement sur divers matériels et offre une solution économique par rapport à la maintenance d’un hardware local pour les déploiements IA à grande échelle.
Étape 1 : Créer un compte
Créez votre compte Novita AI via notre site web. Après inscription, naviguez vers la section « Explorer » dans la barre latérale gauche pour voir nos offres GPU et commencer votre développement IA.

Essayez Novita AI dès maintenant
Étape 2 : Explorer les modèles et les serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA qui correspondent aux besoins de votre projet. Sélectionnez ensuite votre configuration GPU préférée – les options incluent le puissant L40S, le RTX 4090 ou l’A100 SXM4, chacun avec différentes spécifications de VRAM, RAM et stockage.

Étape 3 : Personnaliser votre déploiement
Personnalisez votre environnement en choisissant votre système d’exploitation préféré et les options de configuration pour garantir des performances optimales pour vos charges de travail IA spécifiques.

Étape 4 : Lancer une instance
Sélectionnez « Lancer l’instance » pour démarrer votre déploiement. Votre environnement GPU haute performance sera prêt en quelques minutes, vous permettant de commencer immédiatement vos projets de machine learning, de rendu ou de calcul.

Le NVIDIA L40S représente un bond en avant par rapport à l’A40 dans presque tous les aspects – de l’inférence FP8 au rendu graphique en passant par l’efficacité énergétique. Avec l’architecture Ada Lovelace, il offre plus de 2 fois les performances de l’A40 tout en consommant nettement moins d’énergie. Pour l’inférence IA, l’entraînement à moyenne échelle et les charges de travail lourdes en visualisation, le L40S est le choix évident. Quant à l’A40, il peut encore être pertinent pour les configurations existantes nécessitant NVLink ou les charges de travail de calcul traditionnelles.
Questions fréquentes
Quel GPU est le meilleur pour l’inférence IA – L40S ou A40 ?
Le L40S. Il prend en charge le FP8 natif et délivre jusqu’à 738 PFLOPS, ce qui le rend bien plus puissant pour les tâches d’inférence.
Puis-je utiliser le L40S pour l’entraînement IA à grande échelle ?
Oui, le L40S offre 366 TFLOPS (TF32 Sparse), ce qui le rend excellent pour l’entraînement à moyenne ou grande échelle – bien qu’il ne prenne pas en charge NVLink.
Qu’est-ce qui rend le L40S plus économe en énergie ?
Vous avez besoin d’1 L40S (~350 W) pour égaler les performances de 2,4 A40 (~720 W), réduisant de moitié les coûts énergétiques.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API, tout en fournissant un cloud GPU abordable et fiable pour construire et faire évoluer vos projets.
Lectures recommandées



