

重點摘要
效能:L40S 在所有指標上均優於 A40,具備專屬的 FP8 支援、顯著更高的 FP32/TF32 效能,以及更優異的記憶體頻寬與 CUDA/Tensor Core 效率。
**功耗效率 :L40S 以每張 GPU 約 ** 少 60% 的功耗 達成相同或更佳的效能,而 A40 則缺乏低精度 AI 任務所需的 FP8 支援。
應用焦點:L40S 更適合 AI 推論、精確度負載以及視覺化任務,得益於先進的 Ada Lovelace 架構。

Novita AI

Runpod
在 Novita AI 上使用 L40S 的成本約為 RunPod 的一半價格。
採用 Ada Lovelace 架構的 NVIDIA L40S,是 A40 的重大升級。它提供原生的 FP8 支援以強化 AI 推論能力、透過第三代 RT Core 帶來卓越的圖形效能,以及更高的功耗效率。這些進步使 L40S 成為現代資料中心工作負載中多功能且具成本效益的選擇。
L40S vs A40:架構比較
NVIDIA L40S 基於 Ada Lovelace 架構,相較於其前輩 Ampere 架構的 NVIDIA A40,代表了顯著的進步。兩款 GPU 皆專為廣泛的資料中心工作負載(包括 AI、圖形及 HPC)而設計,但 L40S 帶來了實質的效能提升與新功能。
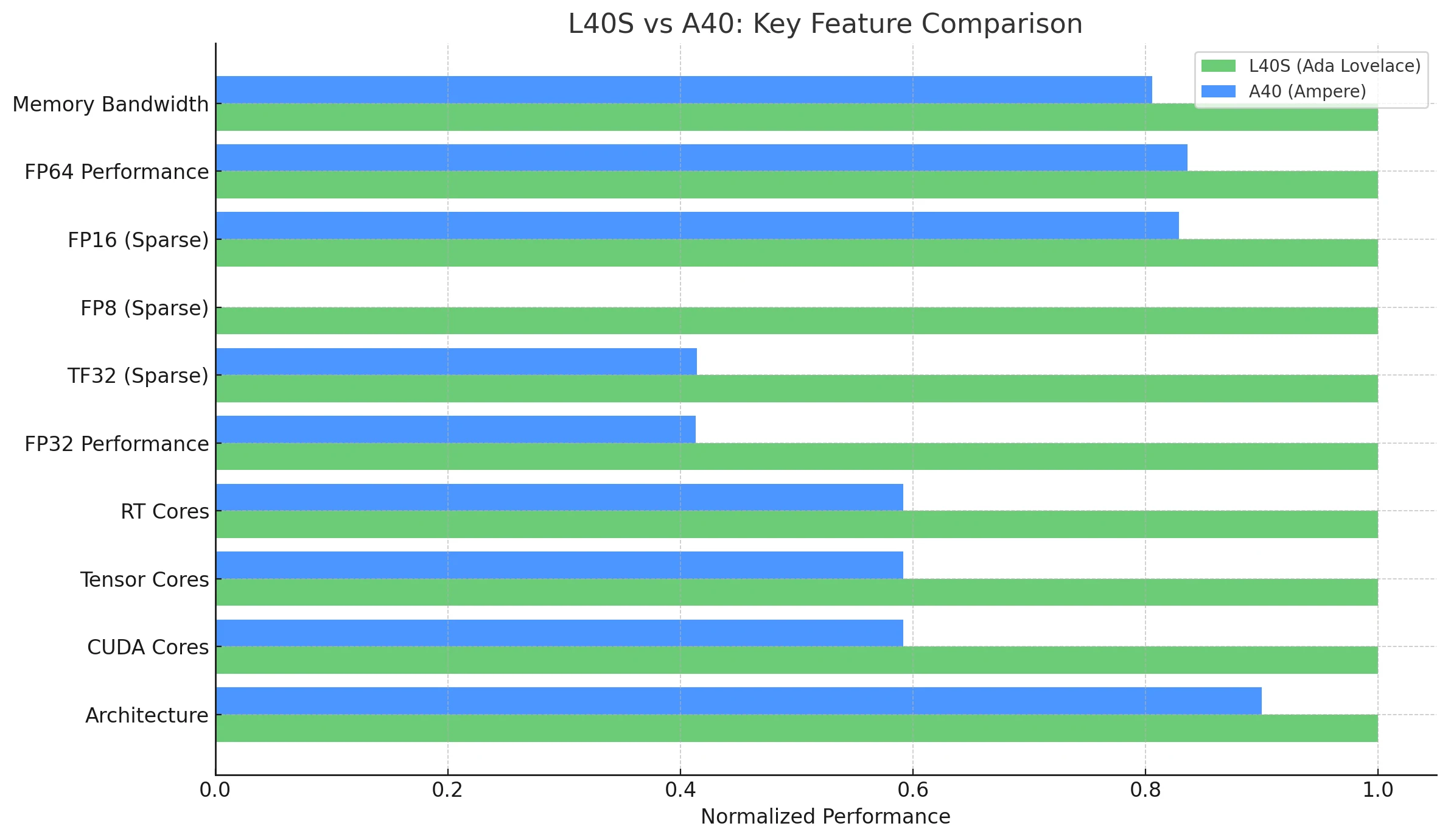
| 功能/指標 | NVIDIA L40S (Ada Lovelace) | NVIDIA A40 (Ampere) |
| **架構 ** | Ada Lovelace | Ampere |
| **CUDA 核心數 ** | 18,176 | 10,752 |
| **Tensor 核心數 ** | 568(第四代) | 336(第三代) |
| **RT 核心數 ** | 142(第三代) | 84(第二代) |
| **FP32 效能 ** | 91.6 TFLOPS | 37.4 TFLOPS |
| TF32 Tensor (稀疏) | 183 | 366* | 74.8 | 149.6* |
| FP8 Tensor (稀疏) | 733 PFLOPS | 不原生支援(Ampere 限制) |
| FP16 Tensor (稀疏) | 362.05 TFLOPS | 149.7 | 299.4* |
| GPU 記憶體 | 48GB GDDR6 含 ECC | 48GB GDDR6 含 ECC |
| **記憶體頻寬 ** | 864GB/s | 696 GB/s |
| 功耗 (TDP) | 350W | 300W |
| 多實例 GPU (MIG) | 否 | 否 |
| NVLink | 否 | 是(2路,總頻寬 112.5 GB/s) |
L40S vs A40:功耗效率
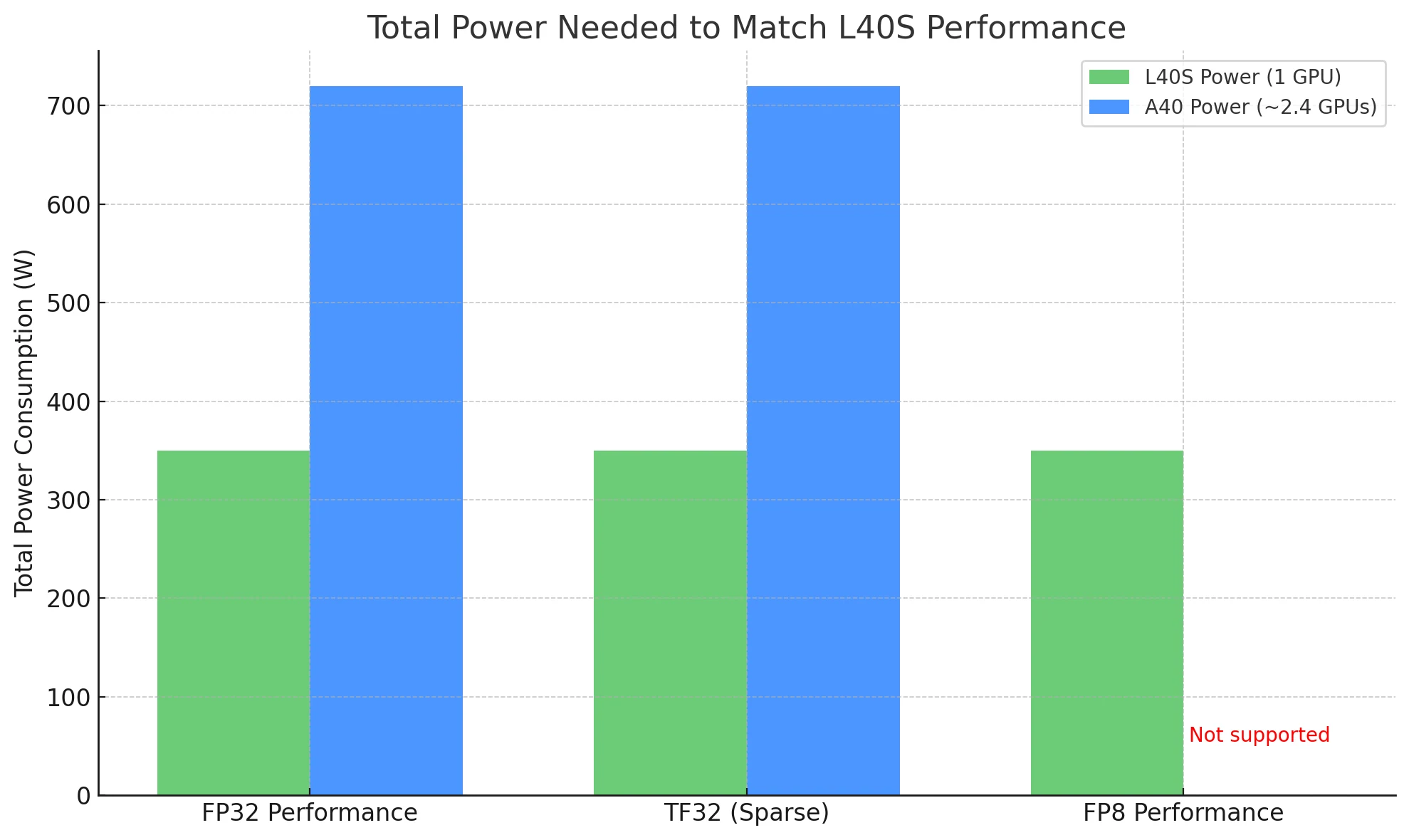
在比較 GPU 時,完成相同工作負載所需的總功耗是更具意義的效率衡量標準——而這正是 L40S 的優勢所在。
- FP32 效能 :L40S 提供 ** 約 91.6 TFLOPS,而 A40 提供 ** 約 37.4 TFLOPS——效能約提升 2.4 倍。
- TF32 (稀疏):L40S 可達 366 TFLOPS,而 A40 約 149.6 TFLOPS——同樣約為 2.4 倍 的輸出。
- **FP8 效能 **:L40S 擁有 ** 顯著優勢 **,提供 ** 原生 FP8 支援 。而基於較舊 Ampere 架構的 A40 ** 完全不支援 FP8。
若要匹配 L40S 的效能:
- 使用 L40S:僅需 **1 張卡 **,功耗約 350W。
- 使用 A40:理論上需要 ** 約 2.4 張卡 **,總功耗約 720W。
在真實部署中,這代表 **L40S 能以一半的功耗提供更高的吞吐量 ,特別是在對功耗敏感或大規模的環境中,使其成為更具 ** 成本效益與可擴展性 的選擇。
L40S vs A40:應用場景
AI 訓練與推論
| 領域 | L40S | A40 |
|---|---|---|
| 訓練 | 非常適合中大型訓練(TF32:366 TFLOPS),成本較低,但缺乏 NVLink。 | 更適合需要高頻寬的大型模型(TF32:149.6 TFLOPS,具 NVLink)。 |
| 推論 | 優秀的 FP8 支援(738 PFLOPS),對大型語言模型及部署強而有力。 | 不支援 FP8;在 FP16、BF16、INT8 上表現強勁。 |
圖形與視覺化
| 功能 | L40S | A40 |
|---|---|---|
| CUDA 核心數 | 18,176 | 10752 |
| RT 核心數 | 142 | 84 |
| 驅動程式 | RTX Enterprise、Omniverse、Studio 就緒 | 以運算為主,圖形工具有限 |
| FP32 效能 | 91.6 TFLOPS | 37.4 TFLOPS |
精確度工作負載
| 功能 | L40S | A40 |
|---|---|---|
| FP64 使用 | 1431 | 585 |
| FP32 使用 | 91.6 | 37.4 |
建議
- 選擇 L40S 如果你需要:
- 高吞吐量推論(特別是 FP8 支援)
- 具成本效益的中型 AI 訓練
- 視覺化工作負載(渲染、Omniverse)
- 採用現代架構的通用 AI 加速
- 選擇 A40 如果你需要:
- 支援 NVLink 的多 GPU 大規模訓練
- 傳統、以運算為主的設定,不依賴圖形功能
如何以極低價格運行 L40S?
Novita AI 提供基於雲端的高效能 GPU 實例平台。憑藉強大的 GPU,它確保複雜任務的高效效能,提升跨各種硬體部署的可及性,並且相比維護本地硬體進行大規模 AI 部署,提供更具成本效益的解決方案。
第1步:註冊帳號
透過我們的網站建立您的新 Novita AI 帳號。註冊後,導覽至左側邊欄的「Explore」區塊,檢視我們提供的 GPU 產品,並開始您的 AI 開發旅程。

第2步:探索模板與 GPU 伺服器
從 PyTorch、TensorFlow 或 CUDA 等模板中選擇符合專案需求的選項。然後選擇您偏好的 GPU 配置——選項包括強大的 L40S、RTX 4090 或 A100 SXM4,各有不同的 VRAM、RAM 與儲存規格。

第3步:自訂您的部署
透過選擇偏好的作業系統與配置選項,自訂您的環境,確保針對特定 AI 工作負載與開發需求達到最佳效能。

第4步:啟動實例
點選「啟動實例」開始部署。您的 GPU 高效能環境將在數分鐘內準備就緒,讓您能立即開始機器學習、渲染或運算專案。

NVIDIA L40S 在幾乎所有方面都相較 A40 有重大飛躍——從 FP8 推論、圖形渲染到功耗效率。憑藉 Ada Lovelace 架構,它提供超過 **2 倍的效能 **,同時功耗顯著降低。對於 AI 推論、中型訓練以及大量視覺化的工作流程,L40S 是明顯的贏家。而 A40 在需要 NVLink 或傳統運算工作負載的舊有設定中,可能仍具相關性。
常見問題
哪款 GPU 更適合 AI 推論——L40S 還是 A40?
L40S。它支援原生 FP8,並提供高達 738 PFLOPS,使其在推論任務上強大得多。
我可以用 L40S 進行大規模 AI 訓練嗎?
可以,L40S 提供 366 TFLOPS (TF32 稀疏),非常適合中大型訓練——但它缺乏 NVLink 支援。
L40S 的功耗效率好在哪裡?
您只需要 1 張 L40S(約 350W) 就能匹配 2.4 張 A40(約 720W) 的效能,能源成本降低一半。
[Novita AI](https://novita.ai/?utm_source=blogs_GPU&utm_medium=article&utm_campaign=NVIDIA A100 GPU Performance: Why It’s Still the Go-to Choice for AI Training) 是一個 AI 雲端平台,為開發者提供透過簡單 API 部署 AI 模型的便捷方式,同時也提供價格合理且可靠的 GPU 雲端,用於建構與擴展應用。
推薦閱讀



