

GLM-5, das neueste Flaggschiff-Modell von Z.AI, hat mit seiner massiven Architektur mit 754 Milliarden Parametern die Grenzen quelloffener Sprachmodelle verschoben. Aber hier ist der Haken: Obwohl es erstklassige Leistung bei Programmier-, Reasoning- und agentischen Aufgaben liefert, erfordert die lokale Ausführung von GLM-5 Hardware auf Unternehmensniveau, die für die meisten Entwickler unerreichbar ist.
Dieser Leitfaden erklärt genau, wie viel VRAM GLM-5 auf verschiedenen Genauigkeitsstufen benötigt, welche GPUs es verarbeiten können, und realistische Bereitstellungsstrategien sowohl für lokale Experimente als auch für Produktionsworkloads. Wir untersuchen außerdem, warum die Größe von GLM-5 für seine vorgesehenen Anwendungsfälle relevant ist: komplexe Systementwicklung und mehrstufige agentische Workflows.
Kurze Antwort: VRAM-Anforderungen für GLM-5
Im Gegensatz zu dichten Modellen, bei denen alle Parameter für jedes Token aktiviert werden, verwendet GLM-5 eine Mixture-of-Experts (MoE)-Architektur mit:
- 754B Gesamtparameter verteilt auf mehrere Expertennetzwerke
- 40B aktive Parameter pro Inferenzdurchlauf (nur ~5,4 % der Gesamtparameter aktiv)
- DeepSeek Sparse Attention (DSA) für effiziente Long-Context-Verarbeitung
- 28,5 Billionen Token vortrainierter Daten (gegenüber 23 Billionen bei GLM-4.5 gestiegen)
| Genauigkeitsstufe | Mindestens erforderlicher VRAM | GPU-Konfiguration |
|---|---|---|
| BF16 (Volle Genauigkeit) | 1,51 TB | 24× NVIDIA H100 80GB |
| FP8 | Ca. 800 GB | 8× NVIDIA H200 141 GB |
| INT4 (Community-Quantisierungen) | 400 GB+ | 8× NVIDIA H100 80GB |
Probieren Sie kostengünstige GPUs aus!
Empfohlene Konfiguration: 8× H100 80GB mit NVLink für INT4. Dies bietet insgesamt 640 GB VRAM mit einer GPU-High-Bandwidth-Verbindung (900 GB/s pro NVLink-Bridge), die für eine effiziente Parameter-Routing in MoE-Modellen unerlässlich ist.
Consumer-Hardware: Nicht realistisch
Machen wir uns nichts vor: GLM-5 ist nicht für Consumer-GPUs ausgelegt. Selbst wenn Sie das Modell unterbringen können, wird die Inferenzgeschwindigkeit ohne NVLink quälend langsam sein. Consumer-Mainboards fehlt die Inter-GPU-Bandbreite, die für eine effiziente Tensor-Parallelisierung erforderlich ist.
GLM-5 Leistung: Ist der VRAM-Aufwand lohnenswert?
GLM-5 lohnt sich, wenn Sie hohe Ausführungszuverlässigkeit und langfristige Tool-Workflows benötigen, insbesondere in Umgebungen im Stil von Claude Code. Der stärkste Beweis dafür ist, dass GLM-5 sich wie ein Engineering-Ausführungsmodell verhält:
- 98% Erfolgsrate bei Frontend-Builds
Dies deutet stark darauf hin, dass GLM-5 Code erzeugt, der kompiliert und ausgeführt wird, nicht nur Code, der „richtig klingt“.
Es liefert außerdem extrem gute Ergebnisse bei agentischen Benchmarks:
- BrowseComp mit Kontextverwaltung: 75,9
- τ²-Bench: 89,7
- MCP-Atlas Public Set: 67,8
Wann GLM-5 sich nicht lohnt
Wenn Ihre Arbeit darin besteht:
- Kleine Skripte
- Einzeldatei-Programmierung
- Kurzes Q&A-Debugging
- Einfache Web-Komponenten
- Aufgaben wie „Code-Snippets generieren“
Dann kommt der Long-Context-Engineering-Vorteil von GLM-5 nicht zum Tragen, und Sie zahlen viel VRAM für minimalen Nutzen. In diesem Fall sind Modelle wie Minimax M2.5 deutlich kostengünstiger.
https://www.youtube.com/watch?v=3XCYruBYr-0
Probieren Sie GLM 5 jetzt aus!
Bereitstellungsoptionen: Cloud vs. Vor-Ort
Option 1: API-Anbieter (Am einfachsten)
Für die meisten Entwickler ist die Nutzung von GLM-5 über API die einzig praktische Option.
Probieren Sie GLM-5 jetzt aus!
| |—| |Verbinden Sie Novita AI einfach mit Partnerplattformen wie Claude Code, Trae, Continue, Codex, OpenCode,AnythingLLM,LangChain, Dify, Langflow und OpenClaw über offizielle Integrationen und Schritt-für-Schritt-Anleitungen.|
Option 2: Cloud-GPU-Miete
Schritt 1:Registrieren Sie ein Konto
Erstellen Sie Ihr Novita AI-Konto über unsere Website. Nach der Registrierung navigieren Sie zum Bereich „Entdecken“ in der linken Seitenleiste, um unsere GPU-Angebote einzusehen und Ihre KI-Entwicklungsreise zu beginnen.

Schritt 2:Vorlagen und GPU-Server erkunden
Wählen Sie aus Vorlagen wie PyTorch, TensorFlow oder CUDA, die zu Ihren Projektanforderungen passen. Wählen Sie dann Ihre bevorzugte GPU-Konfiguration – Optionen umfassen die leistungsstarke H100, jeweils mit unterschiedlichen VRAM-, RAM- und Spezifikationen.
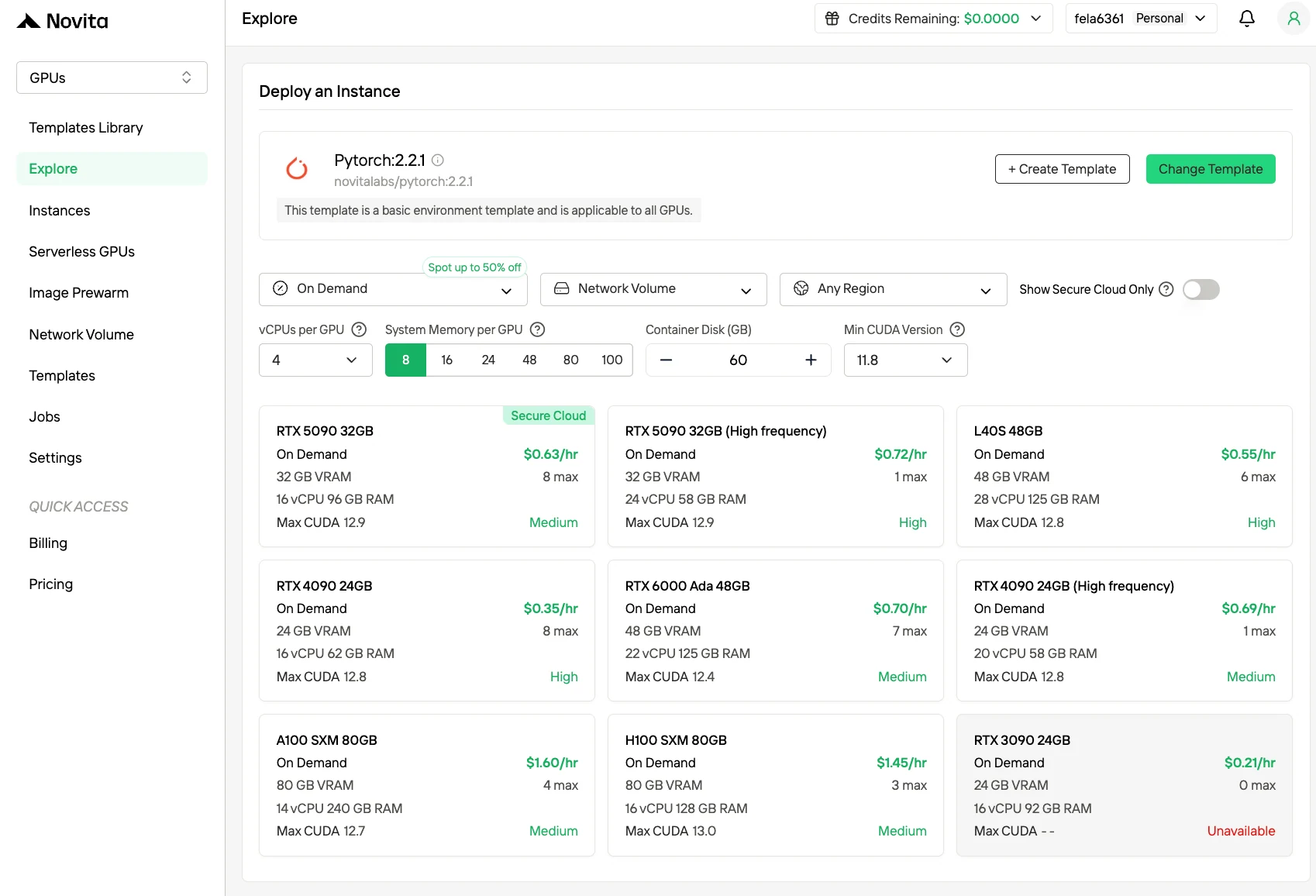
Schritt 3:Passen Sie Ihre Bereitstellung an
Passen Sie Ihre Umgebung an, indem Sie Ihr bevorzugtes Betriebssystem und Konfigurationsoptionen auswählen, um eine optimale Leistung für Ihre spezifischen KI-Workloads und Entwicklungsanforderungen zu gewährleisten.
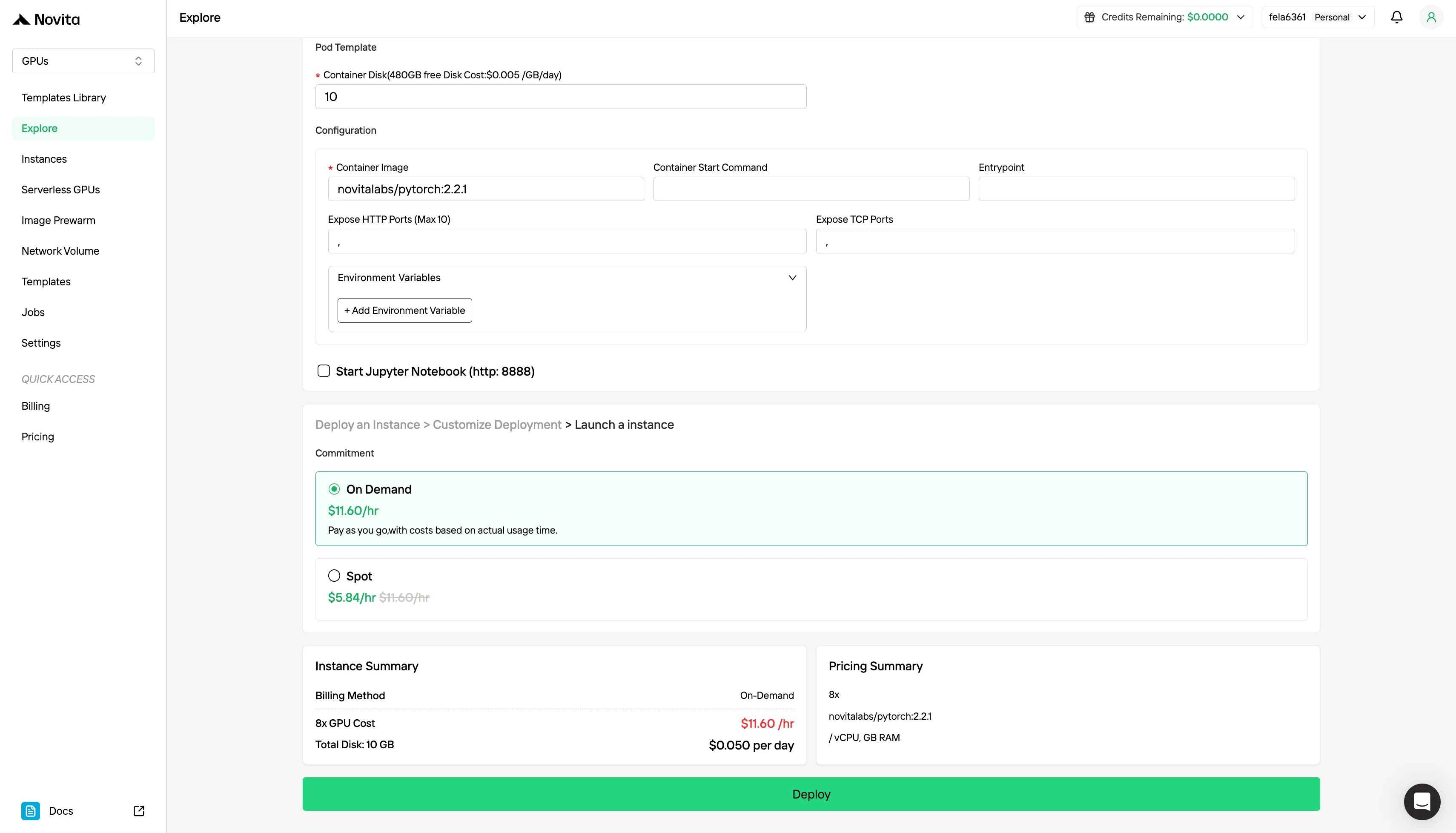
Probieren Sie kostengünstige GPUs aus!
Neben dem Standard-Abrechnungsmodell „On-Demand“ bietet Novita AI auch den Spot-Modus, eine deutlich günstigere GPU-Option, die für kostensensitive Workloads entwickelt wurde.
Der Spot-Modus von Novita AI ist ein kostenoptimiertes GPU-Mietsystem, das die ungenutzte oder freie GPU-Kapazität der Plattform nutzt. Im Gegensatz zu On-Demand-Instanzen, die dedizierte Hardware für stabile, kontinuierliche Nutzung reservieren, sind Spot-Instanzen unterbrechbar – Ihr Job kann pausiert oder beendet werden, wenn die GPU vom System zurückgefordert wird. Da der Spot-Modus ansonsten ungenutzte GPU-Ressourcen neu zuweist, ist er in der Regel 40–60 % günstiger als die On-Demand-Abrechnung.
Option 3: Lokale Bereitstellung (Nur für Forschung)
Wenn Sie Zugriff auf einen High-End-Arbeitsplatz oder einen Laborcluster haben:
- Hardware-Anforderung: 8× H100/A100 für INT4
- Software-Stack: vLLM 0.6+ oder SGLang mit Tensor-Parallelisierungsunterstützung
- Speicher: 2 TB+ NVMe-SSD für Modellgewichte und schnelles Laden
- Arbeitsspeicher: 512 GB+ System-RAM zum Laden von Checkpoints vor der Übertragung auf die GPU

Probieren Sie kostengünstige GPUs aus!
GLM-5 repräsentiert eine neue Klasse von ultra-großen quelloffenen Modellen, die die Grenzen dessen, was in agentischer KI möglich ist, verschieben – aber zu hohen Hardwarekosten. Selbst in INT4 werden 754 GB VRAM benötigt, sodass GLM-5 eindeutig im Unternehmensbereich angesiedelt ist und für eine praktikable Bereitstellung 8+ GPUs der H100-Klasse erfordert. Für einzelne Entwickler und kleine Teams ist die API-Nutzung über Anbieter wie Novita AI die einzig praktische Option.
Häufig gestellte Fragen
Kann ich GLM-5 auf RTX 4090s ausführen? Keine Chance. Acht H100-GPUs sind die Mindestanforderung.
Was ist der Unterschied zwischen den GLM-5 BF16- und FP8-Versionen? Überraschenderweise liegen beide bei ~754 GB aufgrund von Mixed-Precision-Quantisierung bei FP8. FP8 bietet minimalen Qualitätsverlust bei leicht besserer Inferenzgeschwindigkeit auf H100±GPUs.
Kann ich GLM-5 auf Consumer-Hardware feinabstimmen? Nein. Feinabstimmung erfordert das 2- bis 3-fache des VRAMs für die Inferenz (Optimizer-Zustände, Gradienten), was es unmöglich macht.
Novita AI ist eine KI-Cloud-Plattform, die Entwicklern eine einfache Möglichkeit bietet, KI-Modelle über unsere einfache API bereitzustellen, und gleichzeitig eine erschwingliche und zuverlässige GPU-Cloud für die Entwicklung und Skalierung bereitstellt.
Empfohlene Lektüre



