

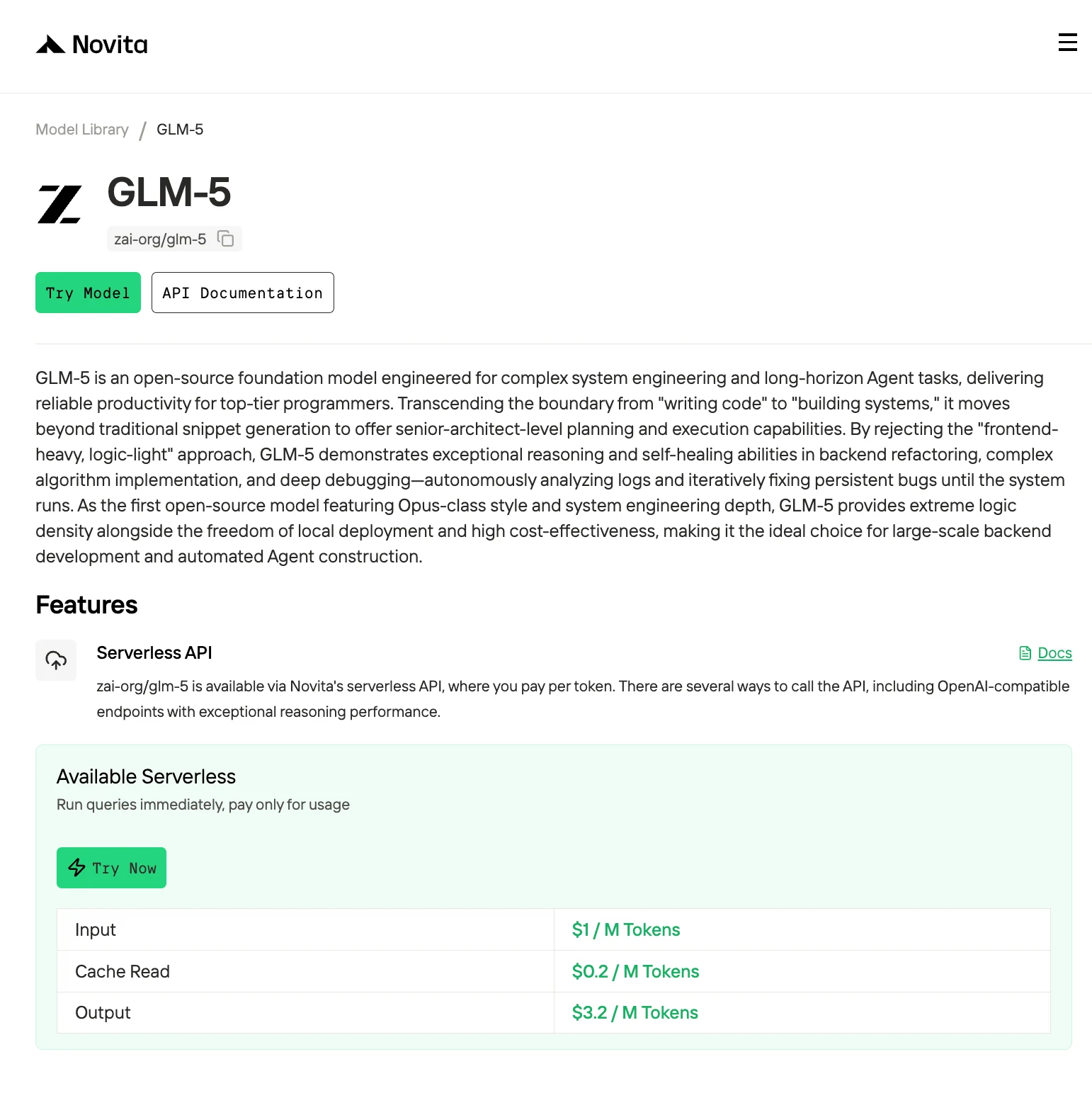
GLM-5, le dernier modèle phare de Z.AI, a repoussé les limites des modèles de langage open source avec son architecture massive de 754 milliards de paramètres. Mais voici le piège : bien qu’il offre des performances de premier ordre sur les tâches de codage, de raisonnement et d’agents, exécuter GLM-5 localement nécessite un matériel de qualité entreprise qui le place bien au-delà de la portée de la plupart des développeurs.
Ce guide décompose exactement la quantité de VRAM dont GLM-5 a besoin à différents niveaux de précision, les GPU capables de le gérer, et les stratégies de déploiement réalistes pour l’expérimentation locale et les charges de travail de production. Nous explorerons également pourquoi la taille de GLM-5 est importante pour ses cas d’utilisation prévus : l’ingénierie de systèmes complexes et les workflows agentiques multi-étapes.
Réponse rapide : besoins en VRAM de GLM-5
Contrairement aux modèles denses où tous les paramètres s’activent pour chaque jeton, GLM-5 utilise une architecture Mixture-of-Experts (MoE) avec :
- 754B paramètres totaux répartis sur plusieurs réseaux d’experts
- 40B paramètres actifs par passage d’inférence (seulement ~5,4 % des paramètres totaux actifs)
- DeepSeek Sparse Attention (DSA) pour un traitement efficace des longs contextes
- 28,5T tokens de données de pré-entraînement (contre 23T pour GLM-4.5)
| Niveau de précision | VRAM minimale | Configuration GPU |
|---|---|---|
| BF16 (pleine précision) | 1,51 To | 24× NVIDIA H100 80 Go |
| FP8 | Environ 800 Go | 8× NVIDIA H200 141 Go |
| INT4 (quantifications communautaires) | 400 Go+ | 8× NVIDIA H100 80 Go |
Configuration recommandée : 8× H100 80 Go avec NVLink pour INT4. Cela fournit 640 Go de VRAM totale avec un interconnexion GPU à haute bande passante (900 Go/s par pont NVLink), essentiel pour un routage efficace des paramètres dans les modèles MoE.
Matériel grand public : pas réaliste
Soyons francs : GLM-5 n’est pas conçu pour les GPU grand public. Même si vous pouvez faire tenir le modèle, la vitesse d’inférence sera désespérément lente sans NVLink. Les cartes mères grand public manquent de la bande passante inter-GPU nécessaire pour un parallélisme tensoriel efficace.
Performance de GLM-5 : le coût en VRAM en vaut-il la peine ?
GLM-5 a du sens lorsque vous avez besoin d’une haute fiabilité d’exécution et de workflows d’outils à long horizon, surtout dans des environnements de type Claude Code. La preuve la plus solide est que GLM-5 se comporte comme un modèle d’exécution technique :
- 98 % de taux de réussite de construction Frontend
Cela suggère fortement que GLM-5 produit du code qui compile et s’exécute, pas seulement du code qui « semble correct ».
Il obtient également d’excellents résultats sur les benchmarks agentiques :
- BrowseComp avec gestion du contexte : 75,9
- τ²-Bench : 89,7
- MCP-Atlas Public Set : 67,8
Quand GLM-5 n’en vaut pas la peine
Si votre travail consiste en :
- petits scripts
- codage de fichier unique
- débogage Q&A court
- composants web simples
- tâches de « génération d’extrait de code »
Alors l’avantage d’ingénierie à long contexte de GLM-5 ne s’active pas, et vous payez une énorme VRAM pour un gain minime. Dans ce cas, des modèles comme Minimax M2.5 sont bien plus rentables.
https://www.youtube.com/watch?v=3XCYruBYr-0
Options de déploiement : Cloud vs Local
Option 1 : Fournisseurs d’API (le plus simple)
Pour la plupart des développeurs, utiliser GLM-5 via une API est la seule option pratique.
Connectez facilement Novita AI avec des plateformes partenaires comme Claude Code, Trae, Continue, Codex, OpenCode, AnythingLLM, LangChain, Dify, Langflow, et OpenClaw grâce aux intégrations officielles et aux guides de configuration étape par étape.
Option 2 : Location de GPU Cloud
Étape 1 : Créez un compte
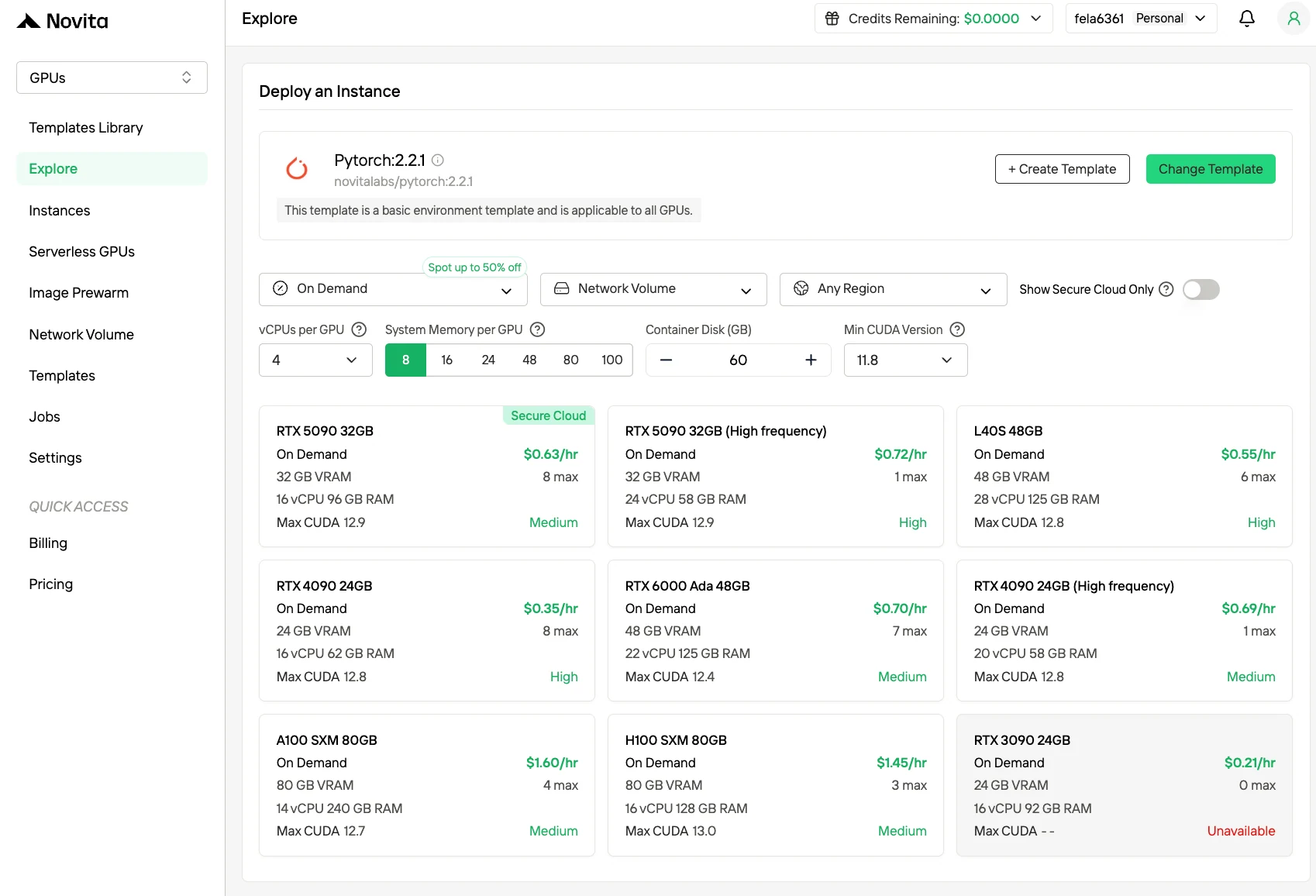
Créez votre compte Novita AI via notre site web. Après l’inscription, naviguez vers la section « Explorer » dans la barre latérale gauche pour voir nos offres GPU et commencez votre parcours de développement IA.

Étape 2 : Explorez les modèles et les serveurs GPU
Choisissez parmi des modèles comme PyTorch, TensorFlow ou CUDA qui correspondent aux besoins de votre projet. Sélectionnez ensuite votre configuration GPU préférée — les options incluent le puissant H100, chacune avec différentes spécifications de VRAM, RAM et stockage.
Étape 3 : Personnalisez votre déploiement
Personnalisez votre environnement en sélectionnant votre système d’exploitation préféré et les options de configuration pour garantir des performances optimales pour vos charges de travail IA spécifiques et vos besoins de développement.
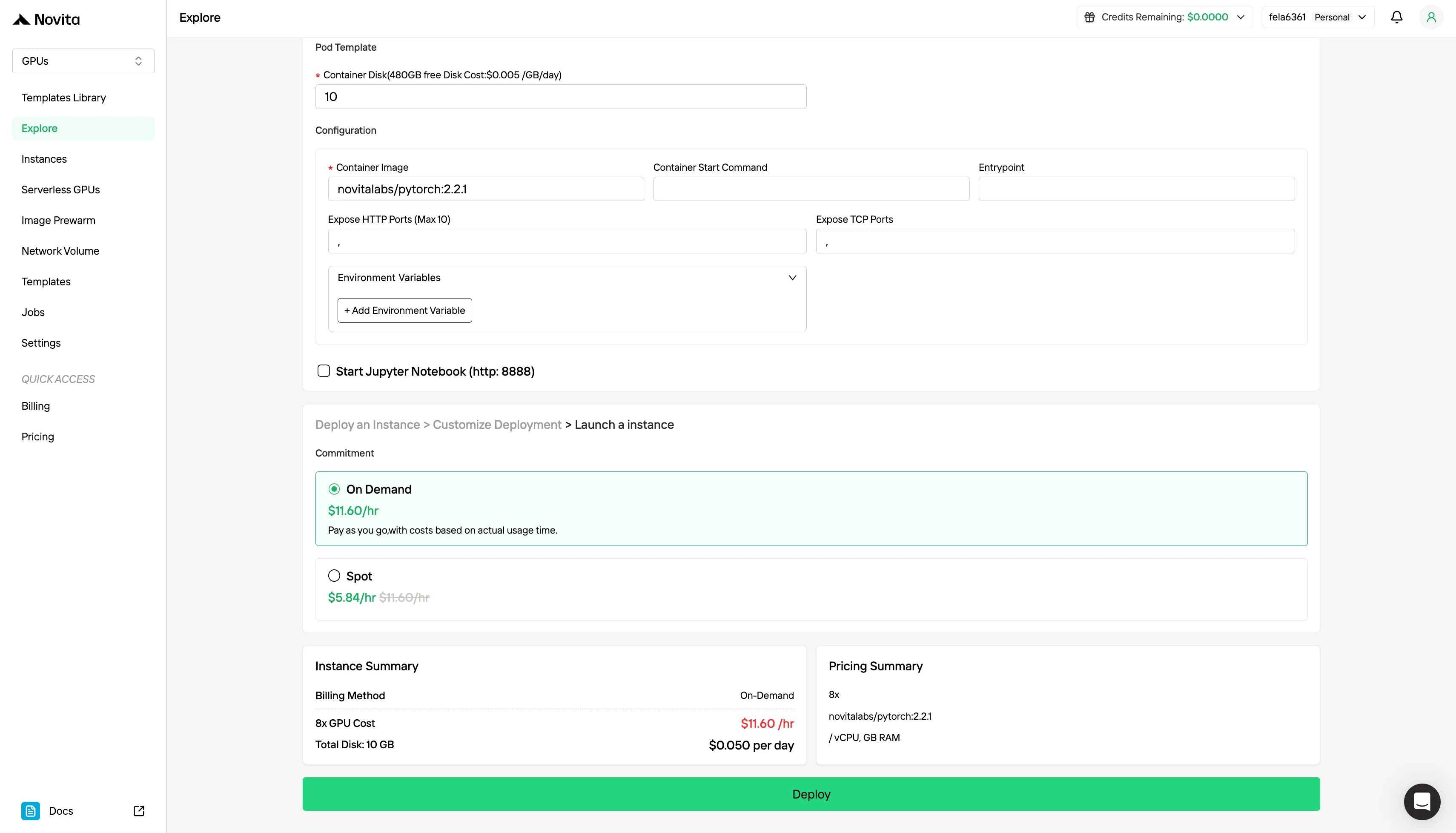
En plus du modèle de tarification standard à la demande, Novita AI propose également le mode Spot, une option GPU nettement moins chère conçue pour les charges de travail sensibles aux coûts.
Le mode Spot de Novita AI est un système de location GPU optimisé pour les coûts qui exploite la capacité GPU inutilisée ou oisive de la plateforme. Contrairement aux instances à la demande qui réservent du matériel dédié pour une utilisation stable et continue, les instances Spot sont interruptibles — votre tâche peut être mise en pause ou interrompue si le GPU est récupéré par le système. Étant donné que le mode Spot réaffecte des ressources GPU autrement inutilisées, il est généralement 40 à 60 % moins cher que la tarification à la demande.
Option 3 : Déploiement local (recherche uniquement)
Si vous avez accès à une station de travail haut de gamme ou à un cluster de laboratoire :
- Configuration matérielle requise : 8× H100/A100 pour INT4
- Pile logicielle : vLLM 0.6+ ou SGLang avec support du parallélisme tensoriel
- Stockage : SSD NVMe de 2 To+ pour les poids du modèle et un chargement rapide
- Mémoire : RAM système de 512 Go+ pour charger les points de contrôle avant le transfert GPU

GLM-5 représente une nouvelle classe de modèles open source ultra-larges qui repoussent les limites du possible en IA agentique — mais à un coût matériel élevé. Avec 754 Go de VRAM requis même en INT4, GLM-5 est fermement dans le territoire des entreprises, nécessitant 8 GPU de classe H100 ou plus pour un déploiement viable. Pour les développeurs individuels et les petites équipes, la voie API via des fournisseurs comme Novita AI est la seule option pratique.
Questions fréquemment posées
Puis-je exécuter GLM-5 sur des RTX 4090 ?
Aucune chance. Huit GPU H100 sont le minimum.
Quelle est la différence entre les versions BF16 et FP8 de GLM-5 ?
Étonnamment, les deux font environ 754 Go en raison de la quantification en précision mixte en FP8. Le FP8 offre une perte de qualité minime avec une vitesse d’inférence légèrement meilleure sur les GPU H100+.
Puis-je affiner GLM-5 sur du matériel grand public ?
Non. L’affinage nécessite 2 à 3 fois la VRAM de l’inférence (états de l’optimiseur, gradients), ce qui le rend impossible.
Novita AI est une plateforme cloud IA qui offre aux développeurs un moyen simple de déployer des modèles IA via notre API simple, tout en fournissant un cloud GPU abordable et fiable pour construire et passer à l’échelle.
Lectures recommandées



